机器学习算法实战案例:时间序列数据最全的预处理方法总结
文章目录
-
-
- 1 缺失值处理
-
- 1.1 统计缺失值
- 1.2 删除缺失值
- 1.3 指定值填充
- 1.4 均值/中位数/众数填充
- 1.5 前后项填充
- 2 异常值处理
-
- 2.1 3σ原则分析
- 2.2 箱型图分析
- 3 重复值处理
-
- 3.1 重复值计数
- 3.2 drop_duplicates重复值处理
- 3 数据归一化/标准化
-
- 3.1 0-1标准化
- 3.2 Z-score标准化
- 技术交流
-
1 缺失值处理
数据缺失主要包括记录缺失和字段信息缺失等情况,其对数据分析会有较大影响,导致结果不确定性更加显著,缺失值的处理:
- 删除记录
- 数据插补
- 不处理
首先导入相应的库文件,处理缺失值的库主要是pandas。
import matplotlib.pyplot as plt
首先参加示例数据用于分析:
df = pd.DataFrame({'time':['2023-12-11 00:00','2023-12-11 01:00','2023-12-11 02:00','2023-12-11 03:00','2023-12-11 04:00','2023-12-11 05:00','2023-12-11 06:00','2023-12-11 07:00','2023-12-11 08:00','2023-12-11 09:00','2023-12-11 010:00'],
'feature1':[12,33,45,23,np.nan,np.nan,66,54,np.nan,99,190],
'feature2':[np.nan,3.3,4.5,np.nan,5.2,np.nan,6.6,5.4,np.nan,9.9,1.0]})

1.1 统计缺失值
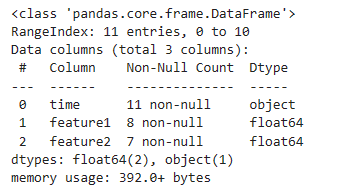
(1) df.info()和df.describe()函数
可以通过df.info()函数大概查看缺失值情况,df.info()可以查看列的数据类型,数据数量信息,df.describe()函数用于查看数据的统计信息。
- info: info方法返回DataFrame中的行数,列数,DataFrame中每一列的名称以及该列的非空值的数目以及每一列的数据类型。
- describe: describe方法返回有关DataFrame中数字数据的一些有用统计信息,例如均值,标准偏差,最大值和最小值以及一些百分位数。
df.info()
(2) isnull,notnull判断是否是缺失值
- isnull:缺失值为True,非缺失值为False
- notnull:缺失值为False,非缺失值为True
df[df['feature2'].notnull()]
df["column_name"].isnull().sum(axis=0)
1.2 删除缺失值
当数据存在缺失值,可以通过不同的方式删除缺失值
df.dropna()#只要某个数据行中有缺失值,则此操作就会将该行删除
df.dropna(subset=['column_1', 'column_2'])#如果column_1和column_2两列数据中存在缺失值,则将缺失值所在的行删除,而不需要考虑其他列是否为缺失值
df.dropna(axis=1,how="all")
df.dropna(axis=0,subset=["Name","Age"])#将会删除"Name"和“Age"中有缺失值的行
1.3 指定值填充
缺失值插补有多种方法,可以通过df.fillna()函数实现:
- 均值/中位数/众数插补
- 临近值插补
- 插值法
df.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None,
- value 参数表示要填充的值
- method 参数表示填充的方法
- axis 参数表示要填充的轴(0 表示行,1 表示列)
- inplace 参数表示是否在原数据框上进行修改
- limit 参数表示最多填充多少个空值
- downcast 参数表示在填充完成后对数据进行类型转换。
指定值填充可以通过df.fillna和df.replace实现
df1.fillna(0,inplace = True)
# df.replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad', axis=None)
df2['feature1'].replace(np.nan,'0',inplace = True)
1.4 均值/中位数/众数填充
均值/中位数/众数可以通过 mean()、median()、mode()实现
df4['feature1'].fillna(df4['feature1'].mean(),inplace = True)
df4['feature1'].fillna(df4['feature1'].median(),inplace = True)
df4['feature1'].fillna(df4['feature1'].mode(),inplace = True)
1.5 前后项填充
前后项填充用前面和后面的值进行填充,一般两个一起用,避免最前面和最后面一行的值填充不到。
# pad / ffill → 用之前的数据填充
# backfill / bfill → 用之后的数据填充
df4['feature2'].fillna(method = 'pad',inplace = True)

2 异常值处理
异常值是指样本中的个别值,其数值明显偏离其余的观测值,异常值也称离群点,异常值的分析也称为离群点的分析
- 异常值分析 → 3σ原则 / 箱型图分析
- 异常值处理方法 → 删除 / 修正填补
首先创建一组数据用于分析:
data = pd.Series(np.random.randn(10000)*100)
2.1 3σ原则分析
首先计算均值和标准差,然后绘制密度曲线,发现数据服从正态分布。
mean = data.mean() # 计算均值
std = data.std() # 计算标准差
print('均值为:%.3f,标准差为:%.3f' % (mean, std))
stats.kstest(data, 'norm', (mean, std))
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 6))
data.plot(kind='kde', grid=True, style='-k', title='密度曲线', ax=ax1)
然后根据计算的均值和标准差通过3σ原则可视化异常值。
error = data[np.abs(data - mean) > 3 * std]
data_c = data[np.abs(data - mean) <= 3 * std]
print('异常值共%i条' % len(error))
# 筛选出异常值error、剔除异常值之后的数据data_c
ax2.scatter(data_c.index, data_c, color='b', marker='.', alpha=0.3, label='正常值')
ax2.scatter(error.index, error, color='r', marker='.', alpha=0.5, label='异常值')
ax2.set_xlim([-10, 10010])

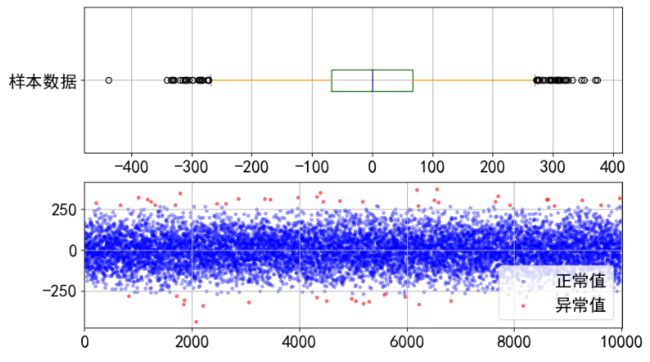
2.2 箱型图分析
与上面3σ原则分析类似,知识检测的标准笔筒,箱型图分析采用四分位数进行统计。首先计算基本的统计量,然后绘值箱型图。
data = pd.Series(np.random.randn(10000) * 100)
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 6))
print('分位差为:%.3f,下限为:%.3f,上限为:%.3f' % (iqr, mi, ma))
color = dict(boxes='DarkGreen', whiskers='DarkOrange', medians='DarkBlue', caps='Gray')
data.plot.box(vert=False, grid=True, color=color, ax=ax1, label='样本数据')
然后根据计算的统计量通过四分位数可视化异常值。
# 筛选出异常值error、剔除异常值之后的数据data_c
error = data[(data < mi) | (data > ma)]
data_c = data[(data >= mi) & (data <= ma)]
print('异常值共%i条' % len(error))
ax2.scatter(data_c.index, data_c, color='b', marker='.', alpha=0.3, label='正常值')
ax2.scatter(error.index, error, color='r', marker='.', alpha=0.5, label='异常值')
ax2.set_xlim([-10, 10010])
3 重复值处理
3.1 重复值计数
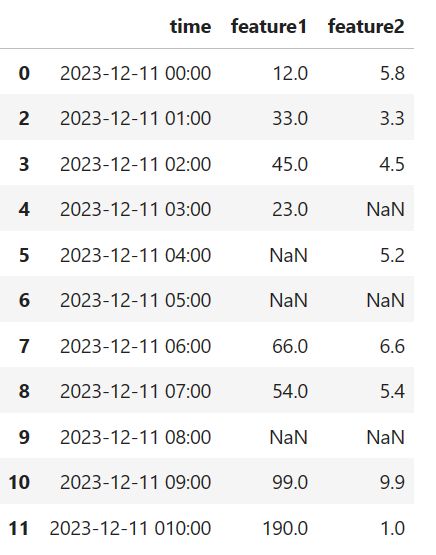
同样创建一组数据用于分析,数据的1和2行是重复数据:
df = pd.DataFrame({'time':['2023-12-11 00:00','2023-12-11 00:00','2023-12-11 01:00','2023-12-11 02:00','2023-12-11 03:00','2023-12-11 04:00','2023-12-11 05:00','2023-12-11 06:00','2023-12-11 07:00','2023-12-11 08:00','2023-12-11 09:00','2023-12-11 010:00'],
'feature1':[12,12,33,45,23,np.nan,np.nan,66,54,np.nan,99,190],
'feature2':[5.8,5.8,3.3,4.5,np.nan,5.2,np.nan,6.6,5.4,np.nan,9.9,1.0]})

可以通过下面的的语句查看重复值,可以看到有1个重复项:
df.duplicated().value_counts()

3.2 drop_duplicates重复值处理
用df.drop_duplicates的方法对某几列下面的重复行删除。
df.drop_duplicates(subset=None, keep='first', inplace=False)
-
subset:是用来指定特定的列,默认为所有列
-
keep:
当keep='first'时,就是保留第一次出现的重复行,其余删除 当keep='last'时,就是保留最后一次出现的重复行,其余删除 当keep=False时,就是删除所有重复行 -
inplace是指是否直接在原数据上进行修改,默认为否
df.drop_duplicates(keep='first',inplace=True)
3 数据归一化/标准化
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上
- 0-1标准化
- Z-score标准化
3.1 0-1标准化
将数据的最大最小值记录下来,并通过Max-Min作为基数(即Min=0,Max=1)进行数据的归一化处理,计算公式
- x = (x - Min) / (Max - Min)
同样创建一组数据用于分析:
df = pd.DataFrame({"feature1": np.random.rand(10) * 20, 'feature2': np.random.rand(10) * 100})

使用公式进行标准化:
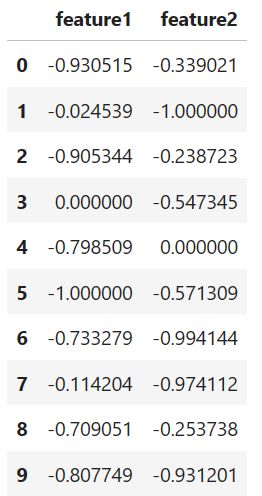
def data_norm(df, *cols):
max_val = df_n[col].max()
min_val = df_n[col].min()
df_n[col] = (df_n[col] - max_val) / (max_val - min_val)
df_n = data_norm(df, 'feature1', 'feature2')
使用库函数实现0-1标准化:
from sklearn.preprocessing import MinMaxScaler
X_scaled = scaler.fit_transform(df['feature1'].values.reshape(-1, 1))
3.2 Z-score标准化
Z分数(z-score),是一个分数与平均数的差再除以标准差的过程 → z=(x-μ)/σ,其中x为某一具体分数,μ为平均数,σ为标准差,Z值的量代表着原始分数和母体平均值之间的距离,是以标准差为单位计算。在原始分数低于平均值时Z则为负数,反之则为正数。
同样创建一组数据用于分析:
df = pd.DataFrame({"feature1":np.random.rand(10) * 100,
'feature2':np.random.rand(10) * 100})
使用公式进行标准化,归一化后可以检测数据的均值和标准差:
def data_Znorm(df, *cols):
u = df_n[col].mean()
std = df_n[col].std()
df_n[col] = (df_n[col] - u) / std
# 使用功能函数实现Z-score标准化并替换原始数据
df = data_Znorm(df, 'feature1', 'feature2')
使用库函数实现z-score标准化:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(df['feature1'].values.reshape(-1, 1))
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
本文相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
方式②、添加微信号:dkl88194,备注:来自CSDN + 技术交流
我们打造了《机器学习算法实战案例宝典》,特点:从0到1轻松学习,方法论及原理、代码、案例应有尽有,所有案例都按照这样的节奏进行的整理。