webserver整理
项目介绍
Linux下C++轻量级Web服务器
- 使用线程池 + epoll(ET和LT均实现) + 同步模拟Proactor模式的并发模型
- 使用状态机解析HTTP请求报文,支持解析GET和POST请求
- 通过访问服务器数据库实现web端用户注册、登录功能,可以请求服务器图片和视频文件
- 实现定时器定时处理非活动连接
- 实现同步/异步日志系统,记录服务器运行状态
- 经Webbench压力测试可以实现上万的并发连接数据交换
1 线程同步——锁的封装
1.1 互斥量 pthread_mutex_t
1.2 信号量 sem_t
int sem_wait(sem_t *sem);
- 对信号量加锁(多线程并发访问),调用一次对信号量的值-1;如果sem值为0,就阻塞
int sem_post(sem_t *sem);
- 对信号量解锁,调用一次对信号量的值+1
注意:sem_wait()要在上锁之前执行,如果阻塞了,就放弃CPU,让消费者执行。如果在上锁之后执行sem_wait()并阻塞,那么消费者无法获取锁,就形成了死锁
示例:
void * producer(void * arg){
//不断创建新的节点,添加到链表中
while(1){
sem_wait(&psem);
pthread_mutex_lock(&mutex);
struct Node * newNode = (struct Node *)malloc(sizeof(struct Node));
newNode->num = rand() % 100;
newNode->next = head;
head = newNode;
printf("add node, num : %d, tid : %ld\n",newNode->num,pthread_self());
pthread_mutex_unlock(&mutex);
sem_post(&csem);
usleep(1000);
}
return NULL;
}
1.3 条件变量 pthread_cond_t
pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex):
原子操作【阻塞(将线程放入条件变量的请求队列),等待条件变量cond满足;
释放互斥锁mutex;】
当被唤醒,返回当前位置,解除阻塞;
获取互斥锁,然后继续执行
示例:
void *consumer(void *arg)
{
while (1)
{
pthread_mutex_lock(&mutex);//访问共享区域必须加锁
while (head == NULL)//如果共享区域没有数据,则解锁并等待条件变量
{
pthread_cond_wait(&has_product, &mutex);
}
mp = head;
head = mp->next;
pthread_mutex_unlock(&mutex);
printf("------------------consumer--%d\n", mp->num);
free(mp); //释放被删除的节点内存
mp = NULL;//并将删除的节点指针指向NULL,防止野指针
sleep(rand() % 3);
}
return NULL;
}
while(head==NULL)使用whlie而不是if:
因为如果同时有两个或者两个以上的线程正在等待此资源,wait返回后,资源可能已经被使用了。
具体点,有可能多个线程都在等待这个资源可用的信号,信号发出后只有一个资源可用,但是有A,B两个线程都在等待,B比较速度快,获得互斥锁,然后加锁,消耗资源,然后解锁,之后A获得互斥锁,但A回去发现资源已经被使用了,它便有两个选择,一个是继续向下执行,去访问不存在的资源,另一个就是继续等待,那么继续等待下去的条件就是使用while,要不然使用if的话pthread_cond_wait返回后,就会顺序执行下去。所以,在这种情况下,应该使用while而不是if。
使用while,pthread_cond_wait解除阻塞返回当前位置,获得互斥锁后,还会while循环进行判断,如果资源已经被消耗,会继续wait;
使用if,解除阻塞获得互斥锁后,直接向下执行。
1.4 RAII
Resource Acquisition is Initialization,资源获取即初始化。
在构造函数中申请分配资源,在析构函数中释放资源。当一个对象创建的时候,自动调用构造函数,当对象超出作用域的时候会自动调用析构函数。所以,在RAII的指导下,我们应该使用类来管理资源,将资源和对象的生命周期绑定,智能指针是RAII最好的例子
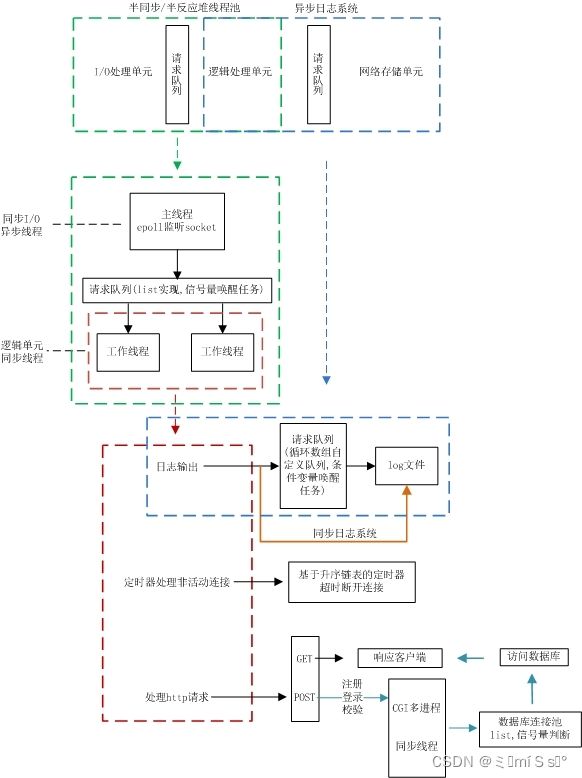
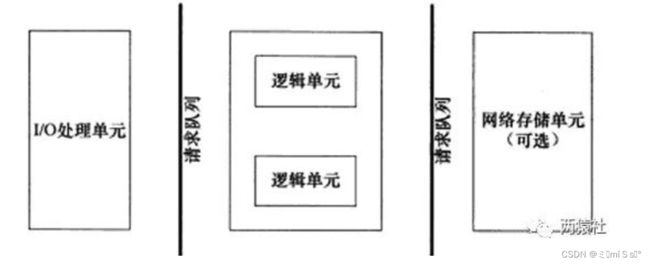
2 服务器编程基本框架
- 主要由I/O单元,逻辑单元和网络存储单元组成
- 其中每个单元之间通过请求队列进行通信
其中I/O单元用于处理客户端连接,读写网络数据;逻辑单元用于处理业务逻辑的线程;网络存储单元指本地数据库和文件等。
3 I/O模型
3.1五种I/O模型
-
阻塞IO:调用了某个函数,等待这个函数返回,期间什么也不做,不停的去检查这个函数有没有返回,必须等这个函数返回才能进行下一步动作
-
非阻塞IO:非阻塞等待,每隔一段时间就去检测IO事件是否就绪,没有就绪就可以做其他事。非阻塞I/O执行系统调用总是立即返回,不管事件是否已经发生,若没有发生,则返回-1,此时可以根据errno区分这两种情况,对于accept,recv和send,事件未发生时,errno通常被设置成eagain
-
IO复用:linux用select/poll函数实现IO复用模型,这两个函数也会使进程阻塞,但是和阻塞IO所不同的是这两个函数可以同时阻塞多个IO操作。而且可以同时对多个读操作、写操作的IO函数进行检测。知道有数据可读或可写时,才真正调用IO操作函数
-
信号驱动IO:linux用套接口进行信号驱动IO,安装一个信号处理函数,进程继续运行并不阻塞,当IO时间就绪,进程收到SIGIO信号。然后处理IO事件。
-
异步IO:linux中,可以调用aio_read函数告诉内核描述字缓冲区指针和缓冲区的大小、文件偏移及通知的方式,然后立即返回,当内核将数据拷贝到缓冲区后,再通知应用程序。
注意:
阻塞I/O,非阻塞I/O,信号驱动I/O和I/O复用都是同步I/O。
同步I/O指内核向应用程序通知的是就绪事件,比如只通知有客户端连接,要求用户自行执行I/O操作;
异步I/O是指内核向应用程序通知的是完成事件,比如读取客户端的数据后才通知应用程序,由内核完成I/O操作。
3.2 服务器的I/O模型
最基础的 TCP 的 Socket 编程,是阻塞 I/O 模型,基本上只能一对一通信,那了服务更多的客户端,我们需要改进网络 I/O 模型。
可使用多进程/线程模型,每来一个客户端连接,就分配一个进程/线程,然后后续的读写都在对应的进程/线程,但进程/线程的调度、上下文切换以及它们占用的内存,都会成为瓶颈。
为了解决这个问题,就出现了 I/O 的多路复用,可以只在一个进程里处理多个文件的 I/O,Linux 下有三种提供 I/O 多路复用的 API,分别是:select、poll、epoll。
3.2.1 select
select 流程:
- 将已连接的 Socket 都放到一个文件描述符集合,然后调用 select 函数将文件描述符集合拷贝到内核里;
- 内核遍历文件描述符集合,当检查到有事件产生后,将此 Socket 标记为可读或可写, 接着再把整个文件描述符集合拷贝回用户态里;
- 用户态还需要再通过遍历的方法找到可读或可写的 Socket,然后再对其处理。
select 缺点:
- 需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里 ;
- 需要2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中;
-
单进程监听的文件描述符数量存在限制(FD_SETSIZE ),默认1024
-
每次调用,文件描述符列表都需要重置
3.2.2 poll
poll 用链表来存储文件描述符集合,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。
但是 poll 和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的损耗会呈指数级增长。
3.2.3 epoll
epoll流程:
1)调用 epoll_create,内核会分配一块内存空间,创建一个 epoll,最后将 epoll 的 fd 返回,我们后续可以通过这个 fd 来操作 epoll 对象
2)调用 epoll_ctl 将我们要监听的 fd 维护到 epoll,内核通过红黑树的结构来高效的维护我们传入的 fd 集合,红黑树增删改一般时间复杂度是 O(logn)
3)应用程序调用 epoll_wait 来获取就绪事件,内核检查 epoll 的就绪列表,如果就绪列表为空则会进入阻塞,否则直接返回就绪的事件。
4)应用程序根据内核返回的就绪事件,进行相应的事件处理
优点:
- 不用每次都拷贝文件描述符集合
- 内核使用红黑树维护文件描述符集合,高效,红黑树增删改一般时间复杂度是 O(logn)
- 使用事件驱动机制,内核里维护了一个链表来记录就绪事件,当用户调用
epoll_wait()函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合
tips
- 当所有的fd都是活跃连接,使用epoll,需要建立文件系统,效率反而不高,不如selece和poll。
- 当监测的fd数目较小(拷贝消耗小),且各个fd都比较活跃(遍历浪费的时间少),建议使用select或者poll;
- 当监测的fd数目非常大,成千上万,且单位时间只有其中的一部分fd处于就绪状态,这个时候使用epoll能够明显提升性能
3.2.4 边缘触发和水平触发
- 边缘触发模式(ET):当被监控的文件描述符上有可读事件发生时,服务器端只会从 epoll_wait 中苏醒一次,即使进程没有调用 read 函数从内核读取数据,也依然只苏醒一次,因此我们程序要保证一次性将内核缓冲区的数据读取完;
- 水平触发模式(LT):当被监控的文件描述符上有可读事件发生时,服务器端不断地从 epoll_wait 中苏醒,直到内核缓冲区数据被 read 函数读完才结束,目的是告诉我们有数据需要读取;
select/poll只支持水平触发,epoll默认水平触发,支持边缘触发。
如果使用边缘触发模式,I/O 事件发生时只会通知一次,为避免数据没有读完,我们会循环从文件描述符读写数据,那么如果文件描述符是阻塞的,没有数据可读写时,进程会阻塞在读写函数那里,程序就没办法继续往下执行。所以,边缘触发模式一般和非阻塞 I/O 搭配使用,程序会一直执行 I/O 操作,直到系统调用(如 read 和 write)返回错误,错误类型为 EAGAIN 或 EWOULDBLOCK(表明读取完毕)。
一般来说,边缘触发的效率较高,因为边缘触发可以减少 epoll_wait 的系统调用次数;使用 I/O 多路复用时,最好搭配非阻塞 I/O 一起使用
3.2.5 EPOLLONESHOT
-
一个线程读取某个socket上的数据后开始处理数据,在处理过程中该socket上又有新数据可读,此时另一个线程被唤醒读取,此时出现两个线程处理同一个socket
-
我们期望的是一个socket连接在任一时刻都只被一个线程处理,通过epoll_ctl对该文件描述符注册epolloneshot事件,一个线程处理socket时,其他线程将无法处理,当该线程处理完后,需要通过epoll_ctl重置epolloneshot事件
4 事件处理模式
4.1 Reactor模式
主线程只负责监听文件描述符上是否有事件发生,有的话立即通知工作线程,读写数据、接受新连接及处理客户请求均在工作线程中完成(多Reactor多线程模式)。通常由非阻塞同步I/O实现。
4.2 Proactor模式
主线程和内核负责处理读写数据、接受新连接等操作,工作线程仅负责业务逻辑,如处理客户请求。通常由异步I/O实现。
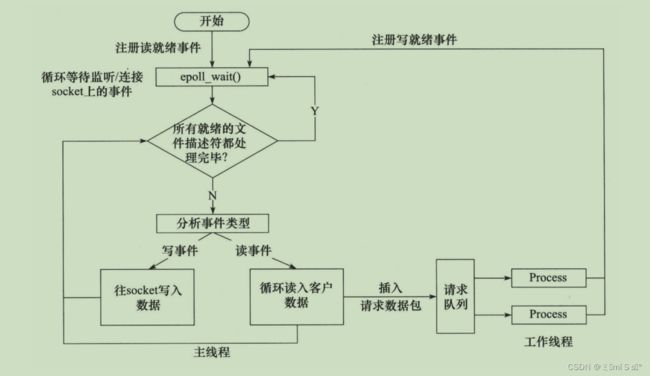
4.3 同步I/O模拟proactor模式
主线程往epoll内核事件表注册socket上的读就绪事件。
主线程调用epoll_wait等待socket上有数据可读
当socket上有数据可读,epoll_wait通知主线程,主线程从socket循环读取数据,直到没有更多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列。
睡眠在请求队列上某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往epoll内核事件表中注册该socket上的写就绪事件
主线程调用epoll_wait等待socket可写。
当socket上有数据可写,epoll_wait通知主线程。主线程往socket上写入服务器处理客户请求的结果。
演进
1.服务器处理多个客户端,最直接的方式——为每一条连接创建一个线程/进程。
但不停的创建和销毁,会消耗大量性能,浪费大量资源,并且也不可能创建几万个线程来处理客户端连接。
2.所以,出现了一种资源复用的方式——线程池:将连接分配给线程,然后一个线程可以处理多个连接的业务。
不过,这样又引来一个新的问题,线程怎样才能高效地处理多个连接的业务?
当一个连接对应一个线程时,线程一般采用「read -> 业务处理 -> send」的处理流程,如果当前连接没有数据可读,那么线程会阻塞在 read 操作上;要解决这一个问题,最简单的方式就是将socket 改成非阻塞,然后线程不断地轮询调用 read 操作来判断是否有数据。但轮询是要消耗 CPU 的。
3.上面的问题在于,线程并不知道当前连接是否有数据可读,从而需要每次通过 read 去试探。那有没有办法在只有当连接上有数据的时候,线程才去发起读请求呢?答案是有的,实现这一技术的就是 I/O 多路复用,在一个监控线程里面监控很多的连接。
select/poll/epoll 是如何获取网络事件的呢?
在获取事件时,先把我们要关心的连接传给内核,再由内核检测:
- 如果没有事件发生,线程只需阻塞在这个系统调用,而无需像前面的线程池方案那样轮训调用 read 操作来判断是否有数据。
- 如果有事件发生,内核会返回产生了事件的连接,线程就会从阻塞状态返回,然后在用户态中再处理这些连接对应的业务即可。
基于面向对象的思想,对 I/O 多路复用作了一层封装,让使用者不用考虑底层网络 API 的细节,只需要关注应用代码的编写,即Reactor 模式。
Reactor 模式主要由 Reactor 和处理资源池这两个核心部分组成,它俩负责的事情如下:
- Reactor 负责监听和分发事件,事件类型包含连接事件、读写事件;
- 处理资源池负责处理事件,如 read -> 业务逻辑 -> send;
Reactor
单 Reactor 单进程 / 线程

- Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
- 如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
- 如果不是连接建立事件, 则交由当前连接对应的 Handler 对象来进行响应( read -> 业务处理 -> send );
全部工作都在同一个进程内完成,所以实现起来比较简单,不需要考虑进程间通信,也不用担心多进程竞争。
但是,这种方案存在 2 个缺点:
- 第一个缺点,因为只有一个进程,无法充分利用 多核 CPU 的性能;
- 第二个缺点,Handler 对象在业务处理时,整个进程是无法处理其他连接的事件的,如果业务处理耗时比较长,那么就造成响应的延迟;
所以,单 Reactor 单进程的方案不适用计算机密集型的场景,只适用于业务处理非常快速的场景。
单 Reactor 多线程 / 多进程
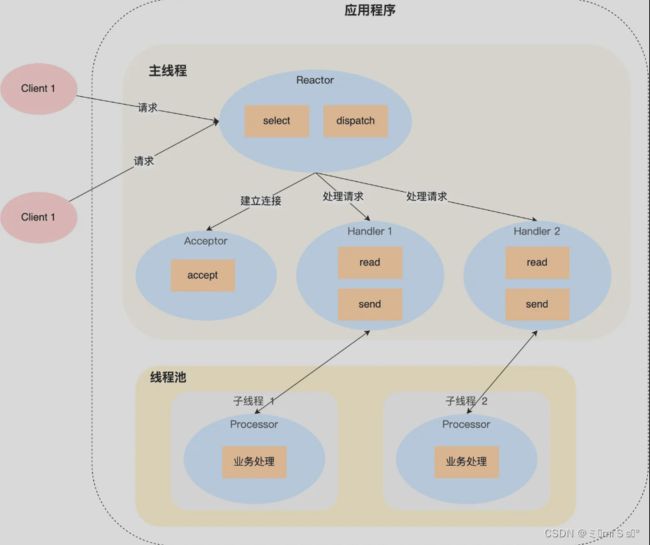
详细说一下这个方案:
- Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
- 如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
- 如果不是连接建立事件, 则交由当前连接对应的 Handler 对象来进行响应;
上面的三个步骤和单 Reactor 单线程方案是一样的,接下来的步骤就开始不一样了:
- Handler 对象不再负责业务处理,只负责数据的接收和发送,Handler 对象通过 read 读取到数据后,会将数据发给子线程里的 Processor 对象进行业务处理;
- 子线程里的 Processor 对象就进行业务处理,处理完后,将结果发给主线程中的 Handler 对象,接着由 Handler 通过 send 方法将响应结果发送给 client;
单 Reator 多线程的方案优势在于能够充分利用多核 CPU 的能,那既然引入多线程,那么自然就带来了多线程竞争资源的问题。要避免多线程由于竞争共享资源而导致数据错乱的问题,就需要在操作共享资源前加上互斥锁。
多 Reactor 多进程 / 线程

方案详细说明如下:
- 主线程中的 MainReactor 对象通过 select 监控连接建立事件,收到事件后通过 Acceptor 对象中的 accept 获取连接,将新的连接分配给某个子线程;
- 子线程中的 SubReactor 对象将 MainReactor 对象分配的连接加入 select 继续进行监听,并创建一个 Handler 用于处理连接的响应事件。
- 如果有新的事件发生时,SubReactor 对象会调用当前连接对应的 Handler 对象来进行响应。
- Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。
多 Reactor 多线程的方案虽然看起来复杂的,但是实际实现时比单 Reactor 多线程的方案要简单的多,原因如下:
- 主线程和子线程分工明确,主线程只负责接收新连接,子线程负责完成后续的业务处理。
- 主线程和子线程的交互很简单,主线程只需要把新连接传给子线程,子线程无须返回数据,直接就可以在子线程将处理结果发送给客户端。
区别
单Reactor单线程 主线程中Acceptor负责连接建立,Handler负责【read-处理-write】,全部工作都在同一个进程内完成
单Reactor多线程 Handler对象只负责IO【read-write】,不负责逻辑处理,具体交给子线程处理
多Reactor多线程 主线程的MainReactor 只负责连接建立,建立的连接交给子线程的SubReactor进行监听,子线程创建一个Handler负责处理【read-处理-write】
5 线程池

-
空间换时间,浪费服务器的硬件资源,换取运行效率.
-
池是一组资源的集合,这组资源在服务器启动之初就被完全创建好并初始化,这称为静态资源.
-
当服务器进入正式运行阶段,开始处理客户请求的时候,如果它需要相关的资源,可以直接从池中获取,无需动态分配.
-
当服务器处理完一个客户连接后,可以把相关的资源放回池中,无需执行系统调用释放资源.
5.1 线程函数
线程创建函数:
int pthread_create (pthread_t *thread_tid, //返回新生成的线程的id
const pthread_attr_t *attr, //指向线程属性的指针,通常设置为NULL
void * (*start_routine) (void *), //处理线程函数的地址
void *arg); //线程函数的参数第三个参数指向线程函数,线程函数的参数要求为(void*)。
如果线程函数是类的成员函数,那么要求为静态成员函数。若线程函数是非静态的成员函数,那么this指针会隐式传递,无法匹配函数指针。
5.2 线程池类
具体参考代码
6 http连接处理
6.1 HTTP报文格式
HTTP报文分为请求报文和响应报文两种,浏览器端向服务器发送的为请求报文,服务器处理后返回给浏览器端的为响应报文。
6.1.1 请求报文
HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。
其中,请求分为两种,GET和POST,具体的:
GET

POST
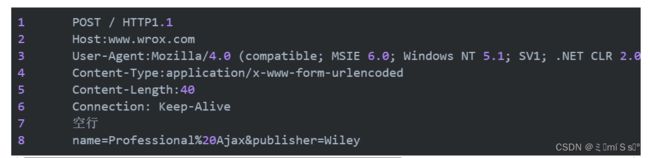
请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本。
请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息。
HOST,给出请求资源所在服务器的域名。 IP + PORT
User-Agent,HTTP客户端程序的信息,该信息由你发出请求使用的浏览器来定义,并且在每个请求中自动发送等。
Accept,说明用户代理可处理的媒体类型。
Accept-Encoding,说明用户代理支持的内容编码。
Accept-Language,说明用户代理能够处理的自然语言集。
Content-Type,说明实现主体的媒体类型。
Content-Length,说明实现主体的大小。
Connection,连接管理,可以是Keep-Alive或close。
空行,请求头部后面的空行是必须的即使第四部分的请求数据为空,也必须有空行。
请求数据也叫主体,可以添加任意的其他数据。
GET和POST的区别
- GET把参数包含在URL中,POST通过request body传递参数。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求在URL中传送的参数是有长度限制。(大多数)浏览器通常都会限制url长度在2K个字节,而(大多数)服务器最多处理64K大小的url。
- GET产生一个TCP数据包;POST产生两个TCP数据包。对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);而对于POST,浏览器先发送header,服务器响应100(指示信息—表示请求已接收,继续处理)continue,浏览器再发送data,服务器响应200 ok(返回数据)。
6.1.2 响应报文
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
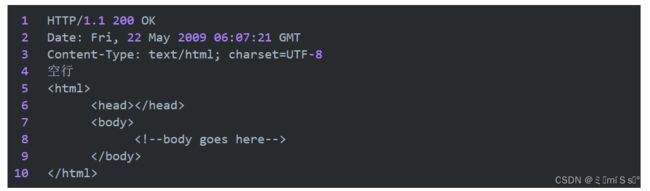
状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为OK。消息报头,用来说明客户端要使用的一些附加信息。
第二行和第三行为消息报头,Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8。空行,消息报头后面的空行是必须的。
响应正文,服务器返回给客户端的文本信息。空行后面的html部分为响应正文。
6.1.3 HTTP请求方法
6.1.4 HTTP状态码
HTTP有5种类型的状态码,具体的:
-
1xx:指示信息--表示请求已接收,继续处理。
-
2xx:成功--表示请求正常处理完毕。
-
200 OK:客户端请求被正常处理。
-
206 Partial content:客户端进行了范围请求。
-
-
3xx:重定向--要完成请求必须进行更进一步的操作。
-
301 Moved Permanently:永久重定向,该资源已被永久移动到新位置,将来任何对该资源的访问都要使用本响应返回的若干个URI之一。
-
302 Found:临时重定向,请求的资源现在临时从不同的URI中获得。
-
-
4xx:客户端错误--请求有语法错误,服务器无法处理请求。
-
400 Bad Request:请求报文存在语法错误。
-
403 Forbidden:请求被服务器拒绝。
-
404 Not Found:请求不存在,服务器上找不到请求的资源。
-
-
5xx:服务器端错误--服务器处理请求出错。
-
500 Internal Server Error:服务器在执行请求时出现错误。
-
6.2 处理流程
主线程检测到客户端连接,初始化http_conn对象,并向epoll内核事件表注册socket上的读就绪事件。
主线程调用epoll_wait等待socket上有数据可读
当socket上有数据可读,epoll_wait监测到EPOLLIN事件, 主线程调用read_once()从socket循环读取数据,直到没有更多数据可读(一次性读完,存储在http_conn对象的读缓冲区中),然后调用append(),将http_conn对象插入任务队列
睡眠在请求队列上某个工作线程被唤醒,它获得http_conn对象并调用process()处理客户请求
process()调用process_read()解析HTTP请求;解析成功后,跳转do_request函数生成响应报文;然后调用process_write()将响应报文头部写入写缓冲中;然后往epoll内核事件表中注册该socket上的写就绪事件
主线程调用epoll_wait等待socket可写。
当socket上有数据可写,epoll_wait监测到EPOLLOUT事件,主线程调用write()将 响应报文头部+响应报文数据 发送给客户端
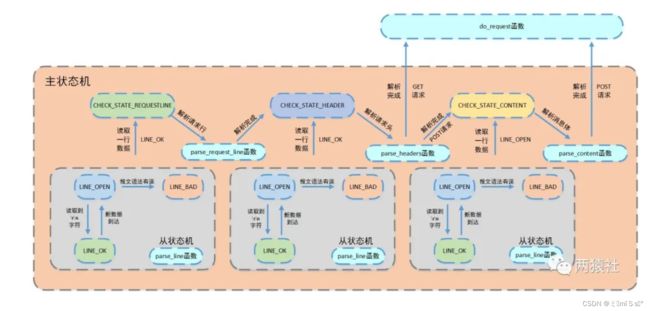
6.3 报文解析
6.4 生成响应报文

7 定时器处理非活动连接
该模块主要分为两部分,其一为定时方法与信号通知流程,其二为定时器及其容器设计与定时任务的处理。
- 利用
alarm函数周期性地触发SIGALRM信号(定时方法),信号处理函数利用管道通知主循环 - 主循环接收到该信号后对升序链表上所有定时器进行处理,若该段时间内没有交换数据,则将该连接关闭,释放所占用的资源。
7.1 信号通知流程
信号基础知识:http://t.csdnimg.cn/a5sHW
7.1.1 主要关注的信号
#define SIGALRM 14 //由alarm系统调用产生timer时钟信号
#define SIGTERM 15 //终端发送的终止信号7.1.2 信号处理机制
Linux下的信号采用的异步处理机制,信号处理函数和当前进程是两条不同的执行路线。具体的,当进程收到信号时,操作系统会中断进程当前的正常流程,转而进入信号处理函数执行操作,完成后再返回中断的地方继续执行。
为避免信号竞态现象发生,信号处理期间系统不会再次触发它。所以,为确保该信号不被屏蔽太久,信号处理函数需要尽可能快地执行完毕。信号处理函数仅仅发送信号通知程序主循环,将信号对应的处理逻辑放在程序主循环中,由主循环执行信号对应的逻辑代码。
统一事件源
统一事件源,是指将信号事件与其他事件一样被处理。
具体的,信号处理函数使用管道将信号传递给主循环,信号处理函数往管道的写端写入信号值,主循环则从管道的读端读出信号值。主线程将管道的读端注册到epoll中,监听管道读端的可读事件。
流程图解
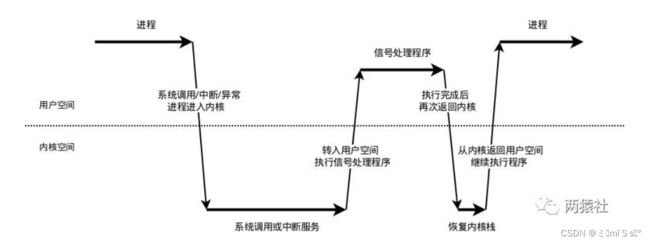
信号接收
接收信号的任务是由内核代理的,当内核接收到信号后,会将其放到对应进程的信号队列中,同时向进程发送一个中断,使其陷入内核态。注意,此时信号还只是在队列中,对进程来说暂时是不知道有信号到来的。
信号检测
进程陷入内核态后,有两种场景会对信号进行检测:
进程从内核态返回到用户态前进行信号检测
进程在内核态中,从睡眠状态被唤醒的时候进行信号检测
当发现有新信号时,便会进入下一步,信号的处理。
信号处理
( 内核 )调用处理函数前,内核会将当前内核栈的内容备份拷贝到用户栈上,并且修改指令寄存器(eip)将其指向信号处理函数。
( 用户 )接下来进程返回到用户态中,执行相应的信号处理函数。
( 内核 )信号处理函数执行完成后,还需要返回内核态,检查是否还有其它信号未处理。
( 用户 )如果所有信号都处理完成,就会将内核栈恢复(从用户栈的备份拷贝回来),同时恢复指令寄存器(eip)将其指向中断前的运行位置,最后回到用户态继续执行进程。
至此,一个完整的信号处理流程便结束了,如果同时有多个信号到达,上面的处理流程会在第2步和第3步骤间重复进行。
7.1.3 问题
- 为什么管道写端要非阻塞?
send是将信息发送给套接字缓冲区,如果缓冲区满了,则会阻塞,这时候会进一步增加信号处理函数的执行时间,而信号处理期间不会再次触发(要确保信号不被屏蔽太久),为此,将其修改为非阻塞。
- 管道传递的是什么类型?switch-case的变量冲突?
信号本身是整型数值,管道中传递的是整型数值对应的ASCII码(字符)。
switch的变量一般为字符或整型,当switch的变量为字符时,case中可以是字符,也可以是字符对应的整型。
7.2 定时器的设计与使用
7.2.1 定时器类
将连接资源、定时事件(定时器回调函数)和超时时间封装为定时器类,具体的,
-
连接资源包括客户端套接字地址、文件描述符和定时器
-
定时事件为回调函数,这里是内核事件表删除事件,关闭文件描述符,释放连接资源
-
定时器超时时间 = 浏览器和服务器连接时刻 + 固定时间(TIMESLOT),定时器使用绝对时间作为超时值
7.2.2 定时器容器类
项目中的定时器容器为带头尾结点的升序双向链表,具体的为每个连接创建一个定时器,将其添加到链表中,并按照超时时间升序排列。执行定时任务时,将到期的定时器从链表中删除。
升序双向链表主要逻辑如下,具体的,
-
add_timer函数,将目标定时器添加到链表中,添加时按照升序添
-
adjust_timer函数,当超时时间内对应fd发生事件,调整对应定时器在链表中的位置
-
del_timer函数将超时的定时器从链表中删除
定时任务处理函数
使用统一事件源,SIGALRM信号每次被触发,主循环中调用一次定时任务处理函数,处理链表容器中到期的定时器。
7.2.3 定时器的使用
具体的,
-
浏览器与服务器连接时,创建该连接对应的定时器,并将该定时器添加到链表上
-
处理异常事件时,执行定时器回调函数,服务器关闭连接,从链表上移除对应定时器
-
处理定时信号时,将定时标志timeout设置为true,执行定时任务处理函数
-
处理读事件时,若某连接上发生读事件,读取成功,将对应定时器向后移动,否则,执行定时器回调函数,并移除定时器
-
处理写事件时,若服务器通过某连接给浏览器发送数据,写成功,将对应定时器向后移动,否则,执行定时器回调函数,并移除定时器
8 单例模式
8.1 定义
单例模式(Singleon),是一种常用的软件设计模式。在应用这个模式时,单例对象的类必须保证只有一个实例存在。
- 懒汉式:指全局的单例实例在第一次被使用时构建。
- 饿汉式:全局的单例实例在类装载(ClassLoader)时构建。(饿汉式单例性能优于懒汉式单例)
8.2 区别
- 懒汉式默认不会实例化,外部什么时候调用什么时候new。饿汉式在类加载的时候就实例化,并且创建单例对象。
- 懒汉式是延时加载,在需要的时候才创建对象,而饿汉式是在代码运行之初就会创建。
- 懒汉式在多线程中是线程不安全的,而饿汉式是不存在多线程安全问题的。
8.3 懒汉模式
8.3.1 经典的线程安全懒汉模式
实现思路:
私有化它的构造函数、拷贝构造函数、拷贝赋值运算符,以防止外界创建单例类的对象;
使用类的私有静态指针变量指向类的唯一实例,并用一个公有的静态方法获取该实例
#include
class single {
private:
//私有静态指针指向类的唯一实例,避免通过对象访问
static single* p;
//静态成员函数只能访问静态成员
static pthread_mutex_t lock;
single(){ }
~single(){ }
single(const single& single2);
const single& operator=(const single& single2);
public:
//公有的静态方法获取实例
static single* getInstance();
};
//初始化静态成员变量
single* single::p = nullptr;
pthread_mutex_t single::lock;
//双检测模式,第一次检测p存在后,就不用加锁了,提高效率
single* single::getInstance() {
if (!p) {
pthread_mutex_lock(&lock);
if (!p) {
p = new single;
}
pthread_mutex_unlock(&lock);
}
return p;
} 8.3.2 局部静态变量之线程安全懒汉模式
#include
class single {
private:
single(){ }
~single(){ }
single(const single& single2);
const single& operator=(const single& single2);
public:
static single* getInstance();
};
//c++11之后保证局部静态变量的线程安全
single* single::getInstance() {
//静态局部变量,第一次访问的时候初始化,直到程序结束才销毁
static single p;
return &p;
}
8.4 饿汉模式
饿汉模式不需要用锁,就可以实现线程安全。原因在于,在程序运行时就定义了对象,并对其初始化。之后,不管哪个线程调用成员函数getinstance(),都只不过是返回一个对象的指针而已。
饿汉模式虽好,但其存在隐藏的问题,在于非静态对象(函数外的static对象)在不同编译单元中的初始化顺序是未定义的。如果在初始化完成之前调用 getInstance() 方法会返回一个未定义的实例。
#include
class single {
private:
static single* p;
single() { }
~single() { }
single(const single& single2);
const single& operator=(const single& single2);
public:
//公有的静态方法获取实例
static single* getInstance();
};
// 代码一运行就初始化创建实例 ,本身就线程安全
single* single::p = new single;
single* single::getInstance() {
return p;
}
8.5 单例模式优缺点
优点:
1、在内存里只有一个实例,减少了内存的开销,避免频繁的创建和销毁实例。
2、避免对资源的多重占用(比如写文件操作),提升了性能。
3、提供了对唯一实例的受控访问。
缺点:
1、不适用于变化的对象,如果同一类型的对象总是要在不同的用例场景发生变化,单例就会引起数据的错误,不能保存彼此的状态。
2、由于单利模式中没有抽象层,因此单例类的扩展有很大的困难。
3、从设计原则方面说,单例类的职责过重,在一定程度上违背了“单一职责原则”。
4、滥用单例将带来一些负面问题,如为了节省资源将数据库连接池对象设计为的单例类,可能会导致共享连接池对象的程序过多而出现连接池溢出;如果实例化的对象长时间不被利用,系统会认为是垃圾而被回收,这将导致对象状态的丢失(java)。
8.6 使用场景
1、WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。
2、创建的一个对象需要消耗的资源过多,比如 I/O(日志系统:日志类)与数据库的连接(数据库连接池:连接池类)等。
9 日志系统
本项目中,使用单例模式创建日志系统,对服务器运行状态、错误信息和访问数据进行记录,该系统可以实现按天分类,超行分类功能,可以根据实际情况分别使用同步和异步写入两种方式。
其中异步写入方式,将生产者-消费者模型封装为阻塞队列,创建一个写线程,工作线程将要写的内容push进队列,写线程从队列中取出内容,写入日志文件。
日志系统大致可以分成两部分,其一是单例模式与阻塞队列的定义,其二是日志类的定义与使用。
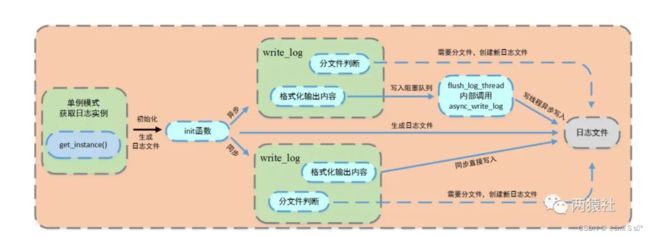
9.1 工作流程
-
日志文件Log类
-
局部变量的懒汉模式获取实例
-
init() 生成日志文件,并判断同步和异步写入方式
-
-
同步 write_log()函数
-
判断是否要重新创建日志文件
-
直接格式化输出内容,将信息写入日志文件
-
-
异步 write_log()函数
-
判断是否要重新创建日志文件
-
格式化输出内容,将内容写入阻塞队列,创建一个写线程,循环从阻塞队列取出内容写入日志文件
-
9.2 阻塞队列
将生产者-消费者模型封装为阻塞队列,用循环数组实现;
线程安全,每个操作前都要先加互斥锁,操作完后,再解锁;
当队列为空时,从队列中获取元素的线程将会被挂起;当队列是满时,往队列里添加元素的线程将会挂起。
9.3 日志类
日志类中的方法都不会被其他程序直接调用,四个可变参数宏提供了其他程序的调用方法。
日志分级:
-
Debug,调试代码时的输出,在系统实际运行时,一般不使用。
-
Warn,这种警告与调试时终端的warning类似,同样是调试代码时使用。
-
Info,报告系统当前的状态,当前执行的流程或接收的信息等。
-
Error和Fatal,输出系统的错误信息。
超行、按天分文件:
-
日志写入前会判断当前day是否为创建日志的时间,行数是否超过最大行限制
-
若为创建日志时间,写入日志,否则按当前时间创建新log,更新创建时间和行数
-
若行数超过最大行限制,在当前日志的末尾加count/max_lines为后缀创建新log
-
10 数据库连接池
10.1 基础知识
数据库连接池
池是一组资源的集合,这组资源在服务器启动之初就被完全创建好并初始化。通俗来说,池是资源的容器,本质上是对资源的复用。
当系统开始处理客户请求的时候,如果它需要相关的资源,可以直接从池中获取,无需动态分配;当服务器处理完一个客户连接后,可以把相关的资源放回池中,无需执行系统调用释放资源。
数据库访问的一般流程
当系统需要访问数据库时,先系统创建数据库连接,完成数据库操作,然后系统断开数据库连接。
为什么要创建连接池
若系统需要频繁访问数据库,则需要频繁创建和断开数据库连接,而创建数据库连接是一个很耗时的操作,也容易对数据库造成安全隐患。
在程序初始化的时候,集中创建多个数据库连接,并把他们集中管理,供程序使用,可以保证较快的数据库读写速度,更加安全可靠。
10.2 整体概述
使用单例模式和链表创建数据库连接池,实现对数据库连接资源的复用。
流程:工作线程从数据库连接池取得一个连接,访问数据库中的数据,访问完毕后将连接交还连接池。
10.3 单例模式创建连接池
懒汉模式
![]()
10.4 连接池对外实现接口
GetInstance(): 返回连接池实例
init(): 初始化数据库连接池,并创建MaxConn条数据库连接
GetConnection(): 数据库连接池中返回一个可用连接,更新使已用和空闲连接数
ReleaseConnection(): 释放当前使用的连接,将当前使用的连接放入数据库连接池
DestroyPool(): 销毁数据库连接池,关闭所有连接
10.5 RAII机制释放数据库连接
不直接调用获取和释放连接的接口,将其封装起来,通过RAII机制进行获取和释放。
将数据库连接和数据库连接池封装在一起,
使用时构造函数通过数据库连接池实例获取一条连接,
用完后析构函数中将使用的数据库连接放回连接池
class connectionRAII
{
public:
connectionRAII(MYSQL **con, connection_pool *connPool);
~connectionRAII();
private:
MYSQL *conRAII; // 数据库连接
connection_pool *poolRAII; // 数据库连接池
};
// 数据库连接SQL本身是指针类型(MYSQL *),要对其进行修改,所以需要使用二阶指针
// connPool是拷贝传参(拷贝的是数据库连接池的指针),poolRAII指向程序本身的数据库连接池
connectionRAII::connectionRAII(MYSQL **SQL, connection_pool *connPool)
{
*SQL = connPool->GetConnection(); // 数据库连接
conRAII = *SQL; // 指向从数据库中获取的一条连接
poolRAII = connPool; // 指向程序本身的数据库连接池
}
connectionRAII::~connectionRAII()
{
// 析构函数执行完,conRAII和poolRAII失效,不能再通过他们访问所指向的连接和连接池,
//但不影响其指向的连接和连接池本身;连接被放回连接池
poolRAII->ReleaseConnection(conRAII); // 释放当前使用的连接,将当前使用的连接放入数据库连接池
}11 注册与登录
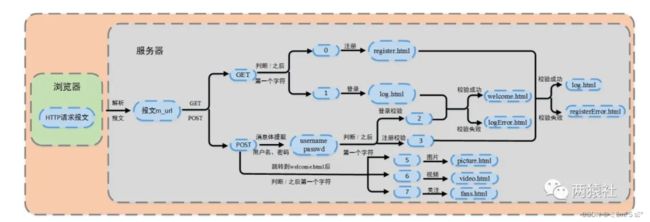
11.1 流程
载入数据库
将数据库中的用户名和密码载入到服务器的map中来,map中的key为用户名,value为密码。
提取用户名和密码
服务器端解析浏览器的请求报文,当解析为POST请求时,cgi标志位设置为1,并将请求报文的消息体赋值给m_string,进而提取出用户名和密码
同步线程登录注册
通过m_url定位/所在位置,根据/后的第一个字符判断是登录还是注册校验。
-
2 登录校验
-
3 注册校验
根据校验结果,跳转对应页面。另外,对数据库进行操作时,需要通过锁来同步。
页面跳转
通过m_url定位/所在位置,根据/后的第一个字符,使用分支语句实现页面跳转。具体的,
-
0 跳转注册页面,GET
-
1 跳转登录页面,GET
-
5 显示图片页面,POST
-
6 显示视频页面,POST
-
7 显示关注页面,POST
12 抓包
12.1 初始访问
浏览器输入:192.168.253.137:8888, m_url = "/", 返回默认的欢迎窗口

请求报文:
响应报文:
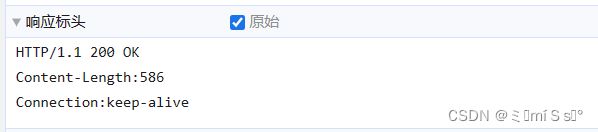
12.2 点击 新用户 按钮



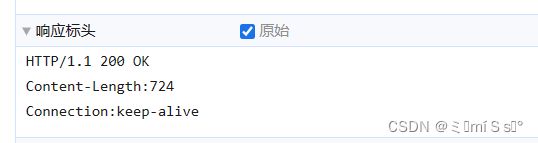
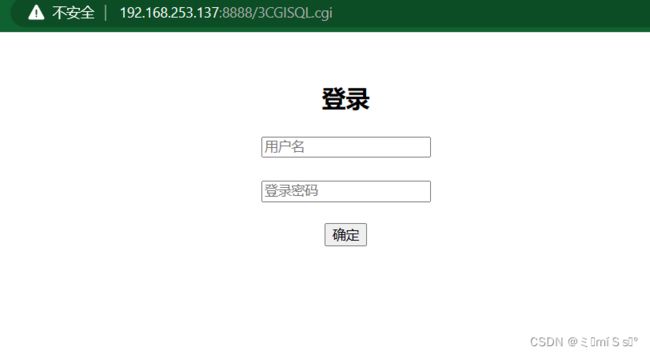
12.3 注册
输入用户、密码,点击注册,返回登陆界面

13 压测
Webbench在主进程中 fork 出多个⼦进程,每个⼦进程都循环做 web 访问测试。⼦进程把访问的结果通过pipe告诉⽗进程,⽗进程做最终的统计结果。webbench 最多可以模拟3万个并发连
接去测试⽹站的负载能⼒
./webbench -c 5000 -t 5 http://192.168.253.137:8888/

补充:Reactor模式、优化、面试问题