《java并发编程之美》学习笔记-知识盲点记录
文章目录
-
- @[TOC](文章目录)
- 前言
- 一、 InheritableThreadLocal类(第一章1.11节)
- 二、原子操作Adder与Accumulator(第四章)
-
- 1.LongAdder
- 2.LongAccumulator
- 三、StampedLock锁(第六章)
- 四、守护线程、伪共享、虚假唤醒 (第一、二章)
-
- 1.守护线程
- 2.伪共享
- 3.虚假唤醒
- 4.Unsafe类与LockSupport
- 五、ConcurrentLinkedQueue无界非阻塞队列(第七章)
- 六、阅读源码时候产生的一些疑问与答案
- 七、其他底层实现(源码级别)
- 总结
文章目录
-
- @[TOC](文章目录)
- 前言
- 一、 InheritableThreadLocal类(第一章1.11节)
- 二、原子操作Adder与Accumulator(第四章)
-
- 1.LongAdder
- 2.LongAccumulator
- 三、StampedLock锁(第六章)
- 四、守护线程、伪共享、虚假唤醒 (第一、二章)
-
- 1.守护线程
- 2.伪共享
- 3.虚假唤醒
- 4.Unsafe类与LockSupport
- 五、ConcurrentLinkedQueue无界非阻塞队列(第七章)
- 六、阅读源码时候产生的一些疑问与答案
- 七、其他底层实现(源码级别)
- 总结
前言
以前对并发编程的了解更多局限于八股。实习时候碰到了一些并发编程的场景,想着顺便看一下相关书籍,同事推荐了《java并发编程之美》这本书,阅读了8章以后扫描到了很多知识盲区,一些之前没有注意到的点随手记录下来。
一、 InheritableThreadLocal类(第一章1.11节)
ThreadLocal主要是在线程内部存储一份共享变量的副本来进行数据隔离保证安全,解决在并发多线程竞争共享资源的负担,以前对于ThreadLocal的了解局限于其内部存储结构,即其有一个属性命名为ThreadLocals,类型为静态内部类ThreadLocalMap,存储ThreadLocal的弱引用和value值的映射,伴随还有其引起的内存泄漏问题的解决。但是读书的时候发现书中介绍ThreadLocal的不支持继承性,也就是说,同一个ThreadLocal变量在父线程中被设置值后,在子线程中是获取不到的。那么有没有办法让子线程能访问到父线程中的值?答案是有。
为了解决上面提出的问题,InheritableThreadLocal应运而生。InheritableThreadLocal继承自ThreadLocal,其提供了一个特性,就是让子线程可以访问在父线程中设置的本地变量。下面看一下InheritableThreadLocal的代码。
public class InheritableThreadLocal<T> extends ThreadLocal<T> {
//(1)
protected T childValue(T parentValue) {
return parentValue;
}
//(2)
ThreadLocalMap getMap(Thread t) {
return t.inheritableThreadLocals;
}
//(3)
void createMap(Thread t, T firstValue) {
t.inheritableThreadLocals = new ThreadLocalMap(this, firstValue);
}
}
public Thread(Runnable target) {
init(null, target, "Thread-" + nextThreadNum(), 0);
}
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc) {
...
//(4)获取当前线程
Thread parent = currentThread();
...
//(5)如果父线程的inheritableThreadLocals变量不为null
if (parent.inheritableThreadLocals ! = null)
//(6)设置子线程中的inheritableThreadLocals变量
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
this.stackSize = stackSize;
tid = nextThreadID();
}
由如上代码可知,InheritableThreadLocal继承了ThreadLocal,并重写了三个方法。由代码(3)可知,InheritableThreadLocal重写了createMap方法,那么现在当第一次调用set方法时,创建的是当前线程的inheritableThreadLocals变量的实例而不再是threadLocals。由代码(2)可知,当调用get方法获取当前线程内部的map变量时,获取的是inheritableThreadLocals而不再是threadLocals。综上可知,在InheritableThreadLocal的世界里,变量inheritableThreadLocals替代了threadLocals。
static ThreadLocalMap createInheritedMap(ThreadLocalMap parentMap) {
return new ThreadLocalMap(parentMap);
}
private ThreadLocalMap(ThreadLocalMap parentMap) {
Entry[] parentTable = parentMap.table;
int len = parentTable.length;
setThreshold(len);
table = new Entry[len];
for (int j = 0; j < len; j++) {
Entry e = parentTable[j];
if (e ! = null) {
@SuppressWarnings("unchecked")
ThreadLocal<Object> key = (ThreadLocal<Object>) e.get();
if (key ! = null) {
//(7)调用重写的方法
Object value = key.childValue(e.value); //返回e.value
Entry c = new Entry(key, value);
int h = key.threadLocalHashCode & (len -1);
while (table[h] ! = null)
h = nextIndex(h, len);
table[h] = c;
size++;
}
}
}
}
可以看到,在createInheritedMap内部使用父线程的inheritableThreadLocals变量作为构造函数创建了一个新的ThreadLocalMap变量,然后赋值给了子线程的inheritableThreadLocals变量。在该构造函数内部把父线程的inheritableThreadLocals成员变量的值复制到新的ThreadLocalMap对象中,其中代码(7)调用了InheritableThreadLocal类重写的代码(1)。
总结:InheritableThreadLocal类通过重写代码(2)和(3)让本地变量保存到了具体线程的inheritableThreadLocals变量里面,那么线程在通过InheritableThreadLocal类实例的set或者get方法设置变量时,就会创建当前线程的inheritableThreadLocals变量。当父线程创建子线程时,构造函数会把父线程中inheritableThreadLocals变量里面的本地变量复制一份保存到子线程的inheritableThreadLocals变量里面。
那么在什么情况下需要子线程可以获取父线程的threadlocal变量呢?情况还是蛮多的,比如子线程需要使用存放在threadlocal变量中的用户登录信息,再比如一些中间件需要把统一的id追踪的整个调用链路记录下来。其实子线程使用父线程中的threadlocal方法有多种方式,比如创建线程时传入父线程中的变量,并将其复制到子线程中,或者在父线程中构造一个map作为参数传递给子线程,但是这些都改变了我们的使用习惯,所以在这些情况下InheritableThreadLocal就显得比较有用。
二、原子操作Adder与Accumulator(第四章)
1.LongAdder
Atomic原子类大家应该都不陌生,比如AtomicLong通过CAS提供了非阻塞的原子性操作,相比使用阻塞算法的同步器来说它的性能已经很好了,但是JDK开发组并不满足于此。使用AtomicLong时,在高并发下大量线程会同时去竞争更新同一个原子变量,但是由于同时只有一个线程的CAS操作会成功,这就造成了大量线程竞争失败后,会通过无限循环不断进行自旋尝试CAS的操作,而这会白白浪费CPU资源。
因此JDK 8新增了一个原子性递增或者递减类LongAdder用来克服在高并发下使用AtomicLong的缺点。既然AtomicLong的性能瓶颈是由于过多线程同时去竞争一个变量的更新而产生的,那么如果把一个变量分解为多个变量,让同样多的线程去竞争多个资源,是不是就解决了性能问题?是的,LongAdder就是这个思路。下面通过图来理解两者设计的不同之处。

使用AtomicLong时,是多个线程同时竞争同一个原子变量。
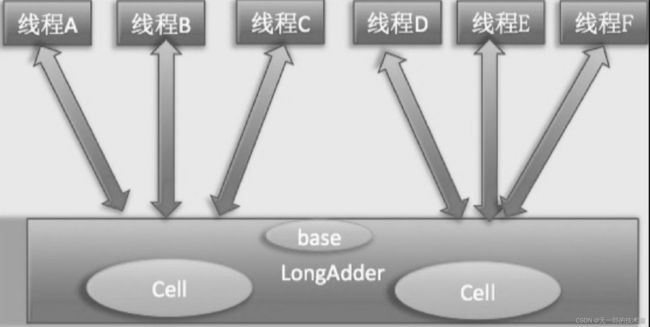
使用LongAdder时,则是在内部维护多个Cell变量,每个Cell里面有一个初始值为0的long型变量,这样,在同等并发量的情况下,争夺单个变量更新操作的线程量会减少,这变相地减少了争夺共享资源的并发量。另外,多个线程在争夺同一个Cell原子变量时如果失败了,它并不是在当前Cell变量上一直自旋CAS重试,而是尝试在其他Cell的变量上进行CAS尝试,这个改变增加了当前线程重试CAS成功的可能性。最后,在获取LongAdder当前值时,是把所有Cell变量的value值累加后再加上base返回的。
LongAdder维护了一个延迟初始化的原子性更新数组(默认情况下Cell数组是null)和一个基值变量base。由于Cells占用的内存是相对比较大的,所以一开始并不创建它,而是在需要时创建,也就是惰性加载。当一开始判断Cell数组是null并且并发线程较少时,所有的累加操作都是对base变量进行的。保持Cell数组的大小为2的N次方,在初始化时Cell数组中的Cell元素个数为2,数组里面的变量实体是Cell类型。Cell类型是AtomicLong的一个改进,用来减少缓存的争用,也就是解决伪共享问题。对于大多数孤立的多个原子操作进行字节填充是浪费的,因为原子性操作都是无规律地分散在内存中的(也就是说多个原子性变量的内存地址是不连续的),多个原子变量被放入同一个缓存行的可能性很小。但是原子性数组元素的内存地址是连续的,所以数组内的多个元素能经常共享缓存行,因此这里使用@sun.misc.Contended注解对Cell类进行字节填充,这防止了数组中多个元素共享一个缓存行,在性能上是一个提升。
2.LongAccumulator
其实LongAdder类是LongAccumulator的一个特例,LongAccumulator比LongAdder的功能更强大。例如下面的构造函数,其中accumulatorFunction是一个双目运算器接口,其根据输入的两个参数返回一个计算值,identity则是LongAccumulator累加器的初始值。
public LongAccumulator(LongBinaryOperator accumulatorFunction,
long identity) {
this.function = accumulatorFunction;
base = this.identity = identity;
}
public interface LongBinaryOperator {
//根据两个参数计算并返回一个值
long applyAsLong(long left, long right);
}
上面提到,LongAdder其实是LongAccumulator的一个特例,调用LongAdder就相当于使用下面的方式调用LongAccumulator:
LongAdder adder = new LongAdder();
LongAccumulator accumulator = new LongAccumulator(new LongBinaryOperator() {
@Override
public long applyAsLong(long left, long right) {
return left + right;
}
}, 0);
所以我们可以知道LongAdder类是LongAccumulator的一个特例,只是后者提供了更加强大的功能,能够让用户自定义累加规则。
三、StampedLock锁(第六章)
StampedLock是并发包里面JDK8版本新增的一个锁,该锁提供了三种模式的读写控制,当调用获取锁的系列函数时,会返回一个long型的变量,我们称之为戳记(stamp),这个戳记代表了锁的状态。其中try系列获取锁的函数,当获取锁失败后会返回为0的stamp值。当调用释放锁和转换锁的方法时需要传入获取锁时返回的stamp值。
StampedLock提供的三种读写模式的锁:
(1)写锁writeLock:是一个排它锁或者独占锁,某时只有一个线程可以获取该锁,当一个线程获取该锁后,其他请求读锁和写锁的线程必须等待,这类似于ReentrantReadWriteLock的写锁(不同的是这里的写锁是不可重入锁)。
(2)悲观读锁readLock:是一个共享锁,在没有线程获取独占写锁的情况下,多个线程可以同时获取该锁。如果已经有线程持有写锁,则其他线程请求获取该读锁会被阻塞,这类似于ReentrantReadWriteLock的读锁(不同的是这里的读锁是不可重入锁)。
(3)乐观读锁tryOptimisticRead:它是相对于悲观锁来说的,在操作数据前并没有通过CAS设置锁的状态,仅仅通过位运算测试。如果当前没有线程持有写锁,则简单地返回一个非0的stamp版本信息。不涉及CAS操作,所没有使用真正的锁,在保证数据一致性上需要复制一份要操作的变量到方法栈,并且在操作数据时可能其他写线程已经修改了数据,而我们操作的是方法栈里面的数据,也就是一个快照,所以最多返回的不是最新的数据,但是一致性还是得到保障的。
StampedLock还支持这三种锁在一定条件下进行相互转换。另外,StampedLock的读写锁都是不可重入锁,所以在获取锁后释放锁前不应该再调用会获取锁的操作,以避免造成调用线程被阻塞。当多个线程同时尝试获取读锁和写锁时,谁先获取锁没有一定的规则,完全都是尽力而为,是随机的。并且该锁不是直接实现Lock或ReadWriteLock接口,而是其在内部自己维护了一个双向阻塞队列。
四、守护线程、伪共享、虚假唤醒 (第一、二章)
1.守护线程
Java中的线程分为两类,分别为daemon线程(守护线程)和user线程(用户线程)。在JVM启动时会调用main函数,main函数所在的线程就是一个用户线程,其实在JVM内部同时还启动了好多守护线程,比如垃圾回收线程。
守护线程和用户线程有什么区别呢?区别之一是当最后一个非守护线程结束时,JVM会正常退出,而不管当前是否有守护线程,也就是说守护线程是否结束并不影响JVM的退出。言外之意,只要有一个用户线程还没结束,正常情况下JVM就不会退出。
Java中如何创建一个守护线程?代码如下:
public static void main(String[] args) {
Thread daemonThread = new Thread(new Runnable() {
public void run() {
}
});
//设置为守护线程
daemonThread.setDaemon(true);
daemonThread.start();
}
也就是只需要设置线程的daemon参数为true即可。
如果你希望在主线程结束后JVM进程马上结束,那么在创建线程时可以将其设置为守护线程,如果你希望在主线程结束后子线程继续工作,等子线程结束后再让JVM进程结束,那么就将子线程设置为用户线程。
2.伪共享
为了解决计算机系统中主内存与CPU之间运行速度差问题,会在CPU与主内存之间添加一级或者多级高速缓冲存储器(Cache)。这个Cache一般是被集成到CPU内部的,所以也叫CPU Cache。在Cache内部是按行存储的,其中每一行称为一个Cache行。Cache行是Cache与主内存进行数据交换的单位,Cache行的大小一般为2的幂次数字节。
当CPU访问某个变量时,首先会去看CPU Cache内是否有该变量,如果有则直接从中获取,否则就去主内存里面获取该变量,然后把该变量所在内存区域的一个Cache行大小的内存复制到Cache中。由于存放到Cache行的是内存块而不是单个变量,所以可能会把多个变量存放到一个Cache行中。当多个线程同时修改一个缓存行里面的多个变量时,由于同时只能有一个线程操作缓存行,所以相比将每个变量放到一个缓存行,性能会有所下降,这就是伪共享。
伪共享的产生是因为多个变量被放入了一个缓存行中,并且多个线程同时去写入缓存行中不同的变量。那么为何多个变量会被放入一个缓存行呢?其实是因为缓存与内存交换数据的单位就是缓存行,当CPU要访问的变量没有在缓存中找到时,根据程序运行的局部性原理,会把该变量所在内存中大小为缓存行的内存放入缓存行。所以在单个线程下顺序修改一个缓存行中的多个变量,会充分利用程序运行的局部性原则,从而加速了程序的运行。而在多线程下并发修改一个缓存行中的多个变量时就会竞争缓存行,从而降低程序运行性能。
在JDK 8之前一般都是通过字节填充的方式来避免该问题,也就是创建一个变量时使用填充字段填充该变量所在的缓存行,这样就避免了将多个变量存放在同一个缓存行中。JDK 8提供了一个sun.misc.Contended注解,用来解决伪共享问题。在这里注解用来修饰类,当然也可以修饰变量,比如下面的例子在Thread类中。
/** The current seed for a ThreadLocalRandom */
@sun.misc.Contended("tlr")
long threadLocalRandomSeed;
/** Probe hash value; nonzero if threadLocalRandomSeed initialized */
@sun.misc.Contended("tlr")
int threadLocalRandomProbe;
/** Secondary seed isolated from public ThreadLocalRandom sequence */
@sun.misc.Contended("tlr")
int threadLocalRandomSecondarySeed;
Thread类里面这三个变量默认被初始化为0,这三个变量会在ThreadLocalRandom类中使用,后面章节也讲解了ThreadLocalRandom的实现原理。需要注意的是,在默认情况下,@Contended注解只用于Java核心类,比如rt包下的类。如果用户类路径下的类需要使用这个注解,则需要添加JVM参数:-XX:-RestrictContended。填充的宽度默认为128,要自定义宽度则可以设置-XX:ContendedPaddingWidth参数。
3.虚假唤醒
虚假唤醒是一种现象,它只会出现在多线程环境中,指的是在多线程环境下,多个线程等待在同一个条件上,等到条件满足时,所有等待的线程都被唤醒,但由于多个线程执行的顺序不同,后面竞争到锁、获得运行权的线程在运行时条件已经不再满足,线程应该睡眠但是却继续往下运行的一种现象。比如一般而言线程调用wait()方法后,需要其他线程调用notify,notifyAll方法后,线程才会从wait方法中返回, 而虚假唤醒(spurious wakeup)情况下线程可以通过其他方式,从wait方法中返回。所以一般我们写并发编程的线程等待时候,会用while循环判断来进行wait()或者await(),下面是一种常见形式:
//防止虚假唤醒
while(!conditionCheck()){
xxx.await();//xxx.wait();
}
4.Unsafe类与LockSupport
Unsafe类:JDK的rt.jar包中的Unsafe类提供了硬件级别的原子性操作,Unsafe类中的方法都是native方法,它们使用JNI的方式访问本地C++ 实现库。一些方法比如park()和unpark()在其他地方(比如AQS里面)还是能够遇到的。
LockSupport:JDK中的rt.jar包里面的LockSupport是个工具类,它的主要作用是挂起和唤醒线程,该工具类是创建锁和其他同步类的基础。LockSupport类与每个使用它的线程都会关联一个许可证,在默认情况下调用LockSupport类的方法的线程是不持有许可证的。LockSupport是使用Unsafe类实现的,一些方法比如LockSupport.park(thread)、LockSupport.unpark(thread)、void parkNanos(long nanos)方法等。
五、ConcurrentLinkedQueue无界非阻塞队列(第七章)
以前常用的是阻塞队列,比如线程池七大参数里面经常用的队列,还有生产者消费者模型也可以用阻塞队列实现。读书发现还有一种ConcurrentLinkedQueue,它是线程安全的无界非阻塞队列,其底层数据结构使用单向链表实现,对于入队和出队操作使用CAS来实现线程安全。
ConcurrentLinkedQueue内部的队列使用单向链表方式实现,其中有两个volatile类型的Node节点分别用来存放队列的首、尾节点。从下面的无参构造函数可知,默认头、尾节点都是指向item为null的哨兵节点。新元素会被插入队列末尾,出队时从队列头部获取一个元素。
在Node节点内部则维护一个使用volatile修饰的变量item,用来存放节点的值;next用来存放链表的下一个节点,从而链接为一个单向无界链表。其内部则使用UNSafe工具类提供的CAS算法来保证出入队时操作链表的原子性,其UML类图关系如下。
六、阅读源码时候产生的一些疑问与答案
阅读源码时候产生的一些疑问,思考了一下合理性,并且问了GPT,现进行补充:
问题1:关于某些jdk锁为什么要实现Serializable序列化接口:

问题2:java读写锁ReadWriteLock源码,其中firstReader用来记录第一个获取到读锁的线程,firstReaderHoldCount则记录第一个获取到读锁的线程获取读锁的可重入次数。为什么要这样设计 firstReaderHoldCount 和 cachedHoldCounter?

问题3:线程池的execute方法和submit方法区别:

问题4:CountDownLatch和join区别对比:
一个区别是,调用一个子线程的join()方法后,该线程会一直被阻塞直到子线程运行完毕,而CountDownLatch则使用计数器来允许子线程运行完毕或者在运行中递减计数,也就是CountDownLatch可以在子线程运行的任何时候让await方法返回而不一定必须等到线程结束。另外,使用线程池来管理线程时一般都是直接添加Runable到线程池,这时候就没有办法再调用线程的join方法了,就是说countDownLatch相比join方法让我们对线程同步有更灵活的控制。
七、其他底层实现(源码级别)
前面有些知识点可能有点偏冷门,其他还有一些额外的零散的知识点CopyOnWriteArrayList 、ThreadLocalRandom、阻塞队列、原子类、AQS、线程池、锁、线程同步器(单轮减计数的CountDownLatch、回环屏障CyclicBarrier、增计数的信号量Semaphore)等,书中也有相关源码介绍,可以去参考学习一下源码的巧妙设计,比如看到一些合并减少额外代码行数的操作:
//使用 && || 的前后判断关系 && 前面校验通过了才执行后面的函数 ||前面不通过 然后继续执行
if( xxx!=null && compareAndSet(***))
if( size==xxx || function(***))
// 使用多重的=赋值 减少局部变量赋值操作的额外代码
if( c = (val = xxx)) != null)
总之,我们可以深入理解java并发编程中涉及到的一些框架与JUC的工具包,搞清楚它们设计的目的、内部原理和应用场景,以便工作中遇到并发编程需求的时候能够用的上。
总结
本文总结了近期自己阅读《java并发编程之美》这本书完成8章以后扫描到的很多知识盲区,一些之前没有注意到的点随手记录下来,可以去参考学习一下源码的巧妙设计,深入理解目的、原理和应用场景,以便工作中遇到并发编程需求的时候能够用的上。