node.js学习笔记(3)——使用cheerio处理爬取的网页内容
一、简介
node.js本身自带爬取网站网页内容的功能。
var http = require('http');
router.get('/test', function(req, res){
var url = 'http://www.baidu.com';
http.get(url, function(response){
var html = '';
response.on('data', function(data){
html += data;
});
response.on('end', function(){
res.render('test', {
'html':html
});
})
})
})比如如上代码就实现了爬取baidu.com网页代码内容,使用res.render直接将数据渲染到ejs模板中后的内容如下:
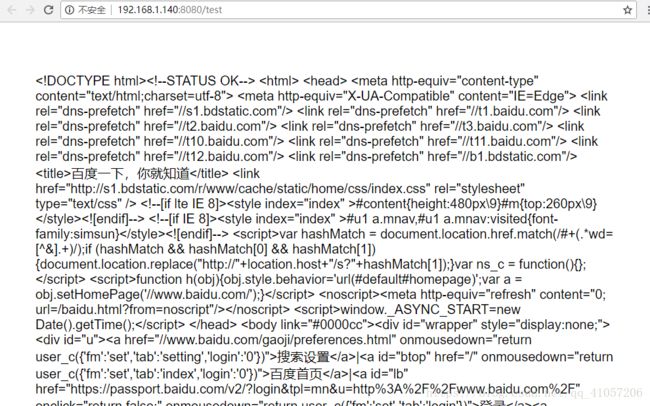
基本和源代码一样,非常难以手工处理。这就是为什么我们需要cheerio模块来对爬取到的内容进行处理
二、cheerio
cheerio模块项目源代码地址:https://github.com/cheeriojs/cheerio
使用方式比较简单:
1. 使用npm install安装cheerio模块并添加到依赖中
2. 在js文件中通过var cheerio = require('cheerio'); 获取模块引用
3. var $ = cheerio.load(html,{decodeEntities:false});
(1)可以创建一个和jQuery选择器用法差不多的选择器 $.
(2)load函数的第一个参数html就是之前http.get方法中所获得的数据;第二个参数可选,主要是用来设置格式,比如decodeEntities:false设置了不会出现中文乱码。
三、简单实战
案例:爬取北京新发地市场的菜价内容。

1. 翻一下源代码,查看所需要的内容的类或者名字

2. 编写代码
router.get('/test', function(req, res){
var url = 'http://www.xinfadi.com.cn/';
http.get(url, function(response){
var html = '';
response.on('data', function(data){
html += data;
});
response.on('end', function(){
var $ = cheerio.load(html,{decodeEntities:false});
var content = $('.conLi').text();
res.render('test', {
'html':content
});
})
})
})然后就会出现如下的内容:

3. cheerio的用法完全可以和写css样式一样,通过多个类、名等方式选择。
比如可以这样写:var content = $('#tab1_div_0 .conLi em').text();
然后就会出现更为细致的效果

4. 一点尝试
看到cheerio提供了toArray方法,对于li, em这样的元素,可以转换为数组。尝试一下后结果

数组是对象类型的,而且由于对象中包含了对自身的引用,使用JSON.stringify方法不能够将对象以字符串形式输出。必须引入util模块,用util.inspect()方法对对象进行转换。随便转换一下后发现内容是这样的:

知道了结构之后按照结构去找数据,最后效果如下:(如果想去掉引号的话使用replace方法加正则表达式即可)

前端表格ejs代码:(使用了前端框架bootstrap)
蔬菜表
<% for(var i=0; i
<%= list[i].toString() %>
<% } %>
<% var counter = 0; %>
<% while(counter < content.length) { %>
<% for(var i=0; i
<%= content[i+counter] %>
<% } %>
<% counter = counter + list.length %>
<% } %>
后端代码:(部分)
response.on('end', function(){
var $ = cheerio.load(html,{decodeEntities:false});
var list = $('.tabLi em').toArray();
var content = $('#tab1_div_0 .conLi em').toArray();
var list2 = new Array();
for(var i=0; i四、总结
爬取网站内容的精髓(不考虑面对反爬取机制的处理)的在于分析,分析它的结构并贴身打造、对症下药。
五、附赠:url中出现中文的问题
在新发地网站进行商品的检索时,发现url中有中文
![]()
但复制下来之后并没有,而是被 %E5%A4%A7%E7%99%BD%E8%8F%9C 编码取代
http://www.xinfadi.com.cn/marketanalysis/0/list/1.shtml?prodname=%E5%A4%A7%E7%99%BD%E8%8F%9C
使用 encodeURI(name) 方法可以实现将中文字符串编码。