transbigdata 笔记: 官方文档示例3:车辆轨迹数据处理
1 读取数据+ 轨迹数据质量分析
这一部分和
transbigdata笔记:data_summary 轨迹数据质量/采样间隔分析-CSDN博客 的举例是一样的
import pandas as pd
import geopandas as gpd
import transbigdata as tbd
data = pd.read_csv('Downloads/TaxiData-Sample.csv',
names=['VehicleNum', 'Time', 'Lng', 'Lat', 'OpenStatus', 'Speed'])
data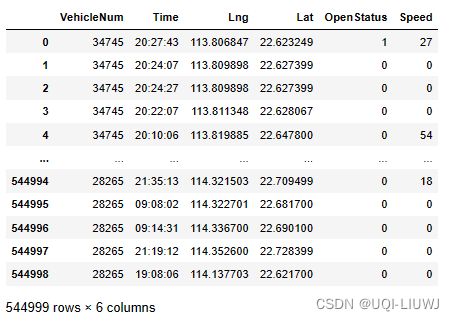
data['Time'] = pd.to_datetime(data['Time'])
data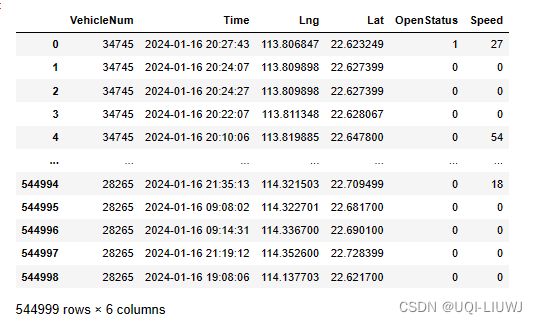
tbd.data_summary(data,
col=['VehicleNum','Time'],
show_sample_duration=True)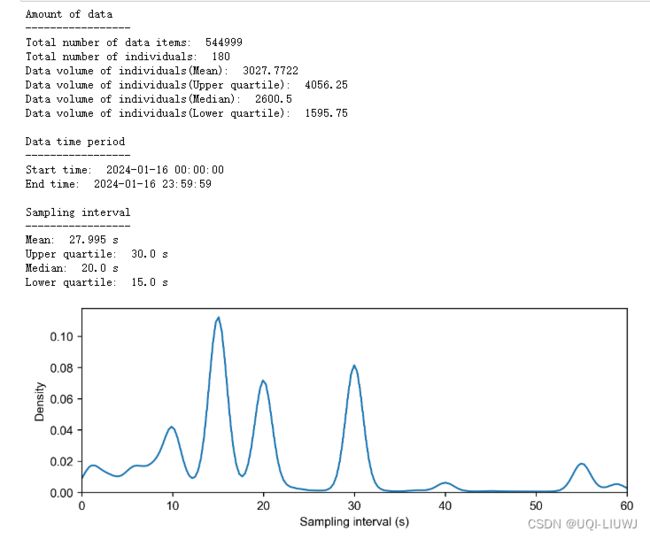
2 清除冗余点
这一个函数的详细用法可见:transbigdata笔记:数据预处理-CSDN博客
data=tbd.traj_clean_redundant(data,col=['VehicleNum','Time','Lng','Lat'])
data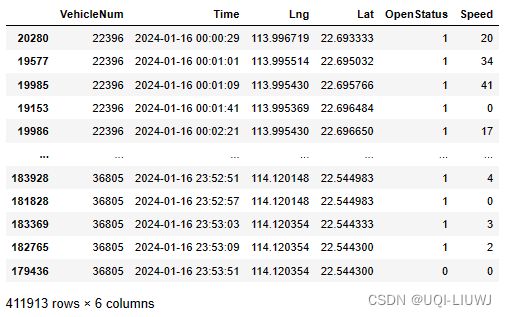
3 清理不在研究区域的记录
transbigdata 笔记:官方文档案例1(出租车GPS数据处理)-CSDN博客 和这边的是一样的
sz = gpd.read_file('Downloads/sz.json')
sz.plot();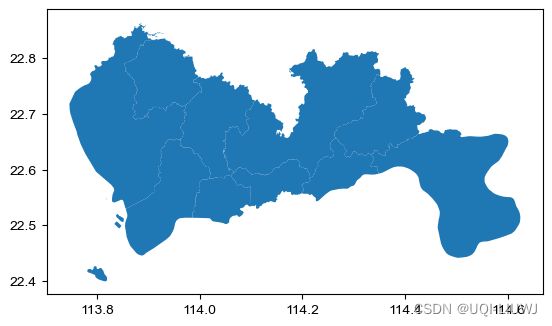
data=tbd.clean_outofshape(data,sz,col=['Lng','Lat'],accuracy=500)
data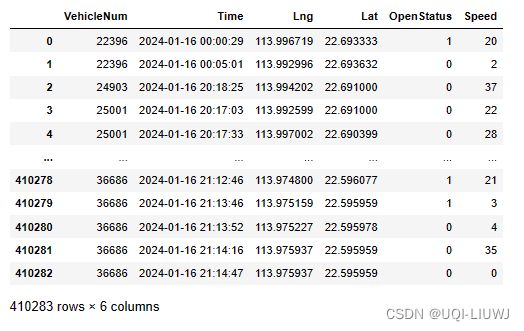
4 清理研究区域内的轨迹漂移
transbigdata笔记:清理研究区域内的轨迹漂移-CSDN博客
data=tbd.traj_clean_drift(data,
col=['VehicleNum','Time','Lng','Lat'])
data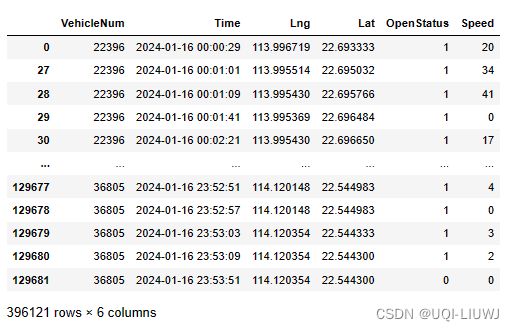
5 轨迹停止点和行程提取
transbigdata笔记:轨迹停止点和行程提取-CSDN博客
stay,move=tbd.traj_stay_move(data,
params,
col=['VehicleNum','Time','Lng','Lat'])
stay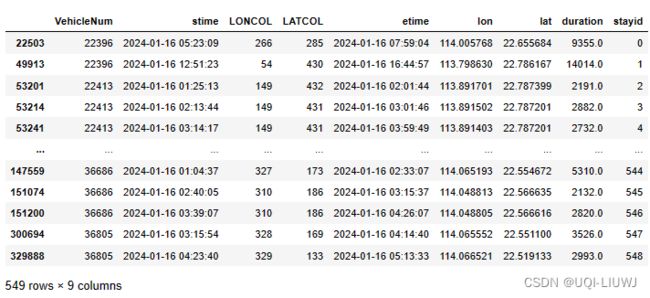
停留状态开始时间、对应栅格编号、停留状态结束时间、轨迹所在位置、持续时间
move

开始栅格、开始位置、结束位置、结束栅格
6 轨迹切片
transbigdata笔记:轨迹切片-CSDN博客
stay_points=tbd.traj_slice(data,
stay,
traj_col=['VehicleNum','Time'],
slice_col=['VehicleNum','stime', 'etime', 'stayid'])
stay_points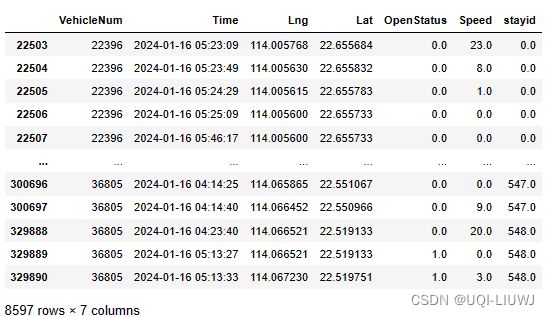
move_points=tbd.traj_slice(data,
move,
traj_col=['VehicleNum','Time'],
slice_col=['VehicleNum','stime', 'etime', 'moveid'])
move_points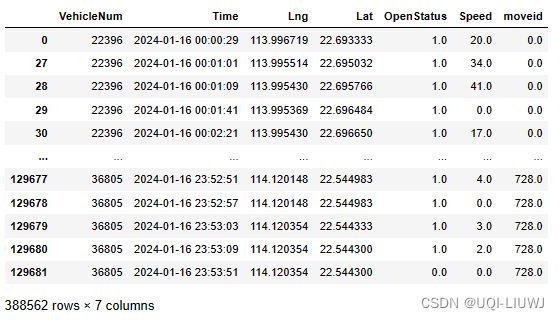
7 轨迹密集化
transbigdata 笔记: 轨迹密集化/稀疏化 & 轨迹平滑-CSDN博客
move_points_d2=tbd.traj_densify(move_points,
col=['moveid','Time','Lng','Lat'],
timegap=29)每timegap秒有一个记录,用pandas的interpolate(method为index)实现
原来采样频率不是timegap的倍数,怎么办呢
move_points_d[move_points_d['moveid']==0.0].head(30)
通过结果(包括源码)可以发现,从move_points的最早的时刻开始,每timegap时刻就会有一条记录,和原先的记录一并存在【换句话说,至多每隔timegap秒都有一个轨迹点】
8 轨迹 稀疏化
transbigdata 笔记: 轨迹密集化/稀疏化 & 轨迹平滑-CSDN博客
move_points_s=tbd.traj_sparsify(move_points,
col=['moveid','Time','Lng','Lat'],
timegap=30,
method='subsample')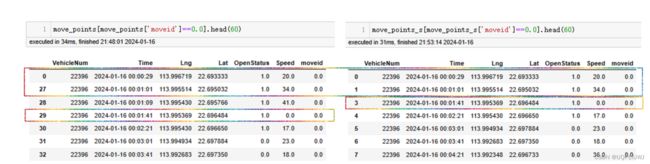
如果method是subsample,那么选取[t,t+subsample)这个时间段内第一次出现的记录,丢弃其他记录,如果某一个[t,t+subsample)时间段内没有数据,不用补值
如果method是interpolate的,那么就是从最开始的位置开始,每subsample秒 用pandas的interpolate方法插一个值,舍弃所有不在整subsample秒的原始记录

9 轨迹平滑
transbigdata 笔记: 轨迹密集化/稀疏化 & 轨迹平滑-CSDN博客
move_points_smooth=tbd.traj_smooth(move_points,
col=['VehicleNum','Time','Lng','Lat'],
process_noise_std=0.1,
measurement_noise_std=0.1)