python入门基础之网络爬虫框架详解:Scrapy与PySpider
导语:小型爬虫需求,requests库+bs4库就能解决;大型爬虫数据,尤其涉及异步抓取、内容管理及后续扩展等功能时,就需要用到爬虫框架了。网络爬虫是一种重要的数据采集技术,而Python提供了多种强大的网络爬虫框架。本文将详细介绍两个知名的Python网络爬虫框架:Scrapy和PySpider。我们将分别探讨它们的特点、用法以及示例代码,帮助你选择适合的框架来开发高效的网络爬虫。
获取更多相关资源公众号:每日推荐系列!
Pyspider与Scrapy的优缺点
Pyspider具有以下特性(好与坏):
1. python脚本控制, 可以用任何你喜欢的html解析包
2. WEB 界面编写调试脚本, 起停脚本, 监控执行状态, 查看活动历史, 获取结果产出
3. 支持MySQL, MongoDB, SQlite
4. 支持抓取JavaScript的页面
5. 组件可替换, 支持单机/分布式部署, 支持Docker部署
6. 强大的调度控制
7. 可以在线提供爬虫服务, 也就是所说的SaaS
8. 做简单的爬虫框架推荐使用, 立刻就能上手, 但自定义程度相对Scrapy低, 社区人数和文档都没有Scrapy强
......
Scrapy具有以下特性(好与坏):
1. 不支持js渲染, 需要单独下载scrapy-splash(或者使用selenium)
2. 全部命令行操作
3. 对千万级URL去重支持很好, 采用布隆过滤
4. scrapy默认的debug模式信息量太大, 不容易调试, 可读性略差
5. 自定义程度高, 适合学习研究爬虫计数, 要学习的相关知识也较多, 故而完成一个爬虫的时间较长.
6. 是一个成熟的框架
......
一、Scrapy框架简介
Scrapy是一个成熟而强大的Python网络爬虫框架,具有以下几个重要特点:
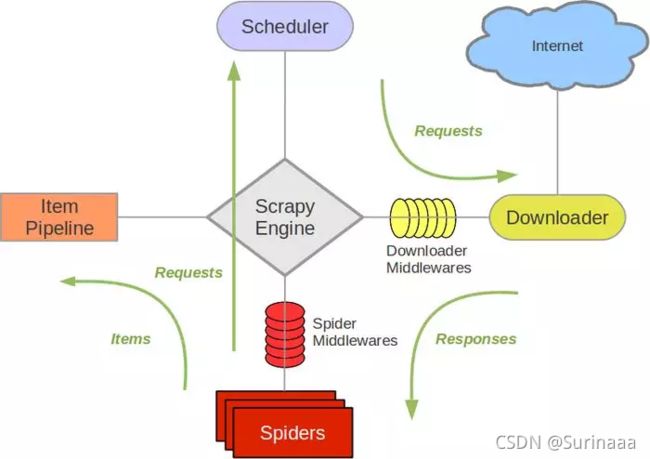
1,异步处理:
Scrapy采用异步处理方式,可以高效地处理大规模爬取任务。
import scrapy
class MySpider(scrapy.Spider):
name = 'example'
start_urls = ['http://www.example.com']
def parse(self, response):
# 网页响应处理逻辑
pass
2,数据提取:
Scrapy提供强大的数据提取功能,支持XPath和CSS选择器等方式进行数据的定位和提取。
import scrapy
class MySpider(scrapy.Spider):
name = 'example'
start_urls = ['http://www.example.com']
def parse(self, response):
data = response.xpath('//div[@class="example"]/text()').get()
yield {'data': data}
3,中间件支持:
Scrapy框架提供多种中间件机制,可以自定义处理请求和响应,如代理、User-Agent的设置等。
import scrapy
class MySpider(scrapy.Spider):
name = 'example'
start_urls = ['http://www.example.com']
custom_settings = {
'DOWNLOADER_MIDDLEWARES': {
'myproject.middlewares.ProxyMiddleware': 543,
'myproject.middlewares.UserAgentMiddleware': 544,
},
}
def parse(self, response):
# 网页响应处理逻辑
pass
4,运行爬虫:
在命令行中执行以下命令,运行爬虫。
scrapy crawl example
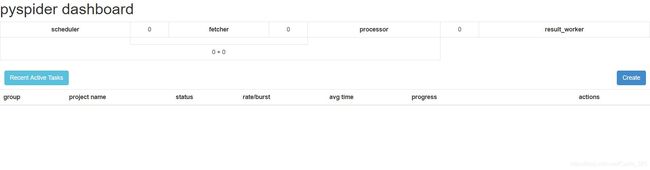
二、PySpider框架简介
PySpider是一个轻量级的Python网络爬虫框架,具有简单易用的特点,适合快速开发和部署爬虫。以下是PySpider框架的几个重要特点:
1,分布式支持:
PySpider支持分布式部署,可以将任务分配给多个爬虫节点,提高爬取效率和容错性。
from pyspider.libs.base_handler import *
class MyHandler(BaseHandler):
def crawl(self):
# 爬虫逻辑
pass
2,交互式界面:
PySpider提供了基于Web的交互式界面,可以方便地查看爬虫状态、监控任务执行情况。
from pyspider import webui
def crawl():
# 爬虫逻辑
pass
webui.run(crawl)
3,数据清洗和预处理:
PySpider支持自定义处理函数,可以对爬取到的数据进行清洗、去重、格式转换等操作。
from pyspider.libs.base_handler import *
class MyHandler(BaseHandler):
def crawl(self):
# 爬虫逻辑
pass
def on_result(self, result):
# 数据清洗和预处理逻辑
pass
4,定时任务调度:
PySpider支持设置定时任务,可以定期执行爬虫任务,自动更新数据。
from pyspider import every
@every(minutes=60)
def crawl():
# 爬虫逻辑
pass
三、pyspider和scrapy的区别
- pyspider提供 了 WebUI,爬虫的编写、调试都是在 WebUI 中进行的 。 而 Scrapy原生是不具备这个功能的,它采用的是代码和命令行操作,但可以通过对接 Portia实现可视化配置。
- pyspider调试非常方便 , WebUI操作便捷直观。 Scrapy则是使用 parse命令进行调试,方便程度不及pyspider。
- pyspider支持 PhantomJS来进行 JavaScript谊染页面的采集 。 Scrapy可以对接Scrapy-Splash组件,这需要额外配置 。
- pyspider中内置了 pyquery作为选择器。 Scrapy对接了 XPath、 css选择器和正则匹配。
- pyspider 的可扩展程度不足,可配制化程度不高 。 Scrapy 可以 通过对接 Middleware、Pipeline、Extension等组件实现非常强大 的功能, 模块之间的稠合程度低,可扩展程度极高 。
四、选择合适的框架 根据实际需求,选择合适的网络爬虫框架非常重要。如果你需要处理大规模的爬取任务、具备异步处理需求并且需要高度定制化,Scrapy是一个不错的选择。如果你希望快速开发和部署爬虫、需要简单的交互式界面和分布式支持,PySpider则更适合你。
总结: Python网络爬虫是获取互联网数据的重要工具,Scrapy和PySpider是两个优秀的网络爬虫框架。Scrapy框架强大而成熟,适用于大规模爬取和高度定制化;而PySpider框架简单易用,适合快速开发和部署。根据实际需求选择合适的框架,可以提高爬虫的效率和开发效率,实现对互联网数据的高效提取和利用。
个人经过实践感觉,pyspider更加简单,但是网上资料少,只要好好读官方文档基本能解决90%的问题,因此对我这种抄代码为主的用户来说不够灵活,例如想用phantomjs实现模拟点击。scrapy相对复杂,而且网络上代码多,因此相对灵活。希望本文对你在选择Python网络爬虫框架时有所帮助,欢迎在下方留言与我们分享你的经验和观点。