Python 爬虫入门详解
Python爬虫入门
- 前言
-
- 对爬虫非常感兴趣但又不知道如何入门的伙伴,本篇文章将带领您走进爬虫的世界
- 看完本篇内容您可以做些什么
- 前置知识要求(您需要对下面的内容有一定了解才能方便您看懂本文)
- 锦上添花(如果还了解一下内容会对您理解底层代码,如何向服务器发送请求,服务器如何响应有所帮助)
- 正文
-
- 模块的导入 Import Module
- 如何选择请求方法 Request Method
- 请求的发送 Send Requests
- 请求头 Request Header
-
- User-Agent
- Cookie
-
- cookie的获取方式
- 其他参数
- 请求参数 Query String Parameters
-
- 以CSDN搜索Python为例
- 搜索结果有多页(下拉显示更多也同理)
- 进阶
- 返回的内容 Response
- 编码
- 获取内容
- 解析方法
- 结束语
- 后续内容
前言
对爬虫非常感兴趣但又不知道如何入门的伙伴,本篇文章将带领您走进爬虫的世界
看完本篇内容您可以做些什么
可以爬取一些简单网页中的内容(如需进行提升,可以看在下的另一篇爬虫进阶的博文)
对请求头,请求参数,请求方法有一定理解
前置知识要求(您需要对下面的内容有一定了解才能方便您看懂本文)
Python模块的基础导入
Python的基础数据类型以及数据的增删改查方法,循环,嵌套
Python的requests模块的基本功能以及方法
锦上添花(如果还了解一下内容会对您理解底层代码,如何向服务器发送请求,服务器如何响应有所帮助)
Python函数
Python面向对象
OSI模型
TCP/IP协议
正文
模块的导入 Import Module
import requests
如何选择请求方法 Request Method
请求方法一般使用 get 和post两种
打开浏览器进入调试面板(F12或右键页面单击‘检查’)
然后切换到Network面板(进行抓包)
在浏览器网址栏输入需要请求的页面然后单击回车键

点击Name栏下的网址
Headers栏中General下拉列表中的Request Method方法即为请求方法
需要注意的是Status Code(状态码) 是否为200,如果是其他的数值则有可能当前界面不是想要请求的页面。
有可能服务器将此Url的请求转移到其他Url上,则需要在调试栏中找出输出数据的Url
Url==网址
请求的发送 Send Requests
url='待请求页面的网址(字符串类型)'
requests.get(url='需要请求地址的网址')
请求头 Request Header
访问网页需要首先与服务器建立一个连接,您可以理解为进入一个游乐园
网址Url就是游乐园的地址
网页中的内容则为游乐园中的娱乐项目
您的请求头就是进入游乐园的门票
(门票不止请求头一种,也有可能有多张门票构成的组合门票,您需要将门票都集齐才能进入)
没有任何验证的网页则就是一个免费的娱乐项目
User-Agent
您的User-Agent 在General下面的Request Headers里
![]()
U-A为您的身份,有些网站只允许特定身份的人进入
具体内容为您访问网页所使用的工具的种类以及型号,用python请求如果不改则默认为python请求
![]()
例如有些网站只允许手机浏览器访问,如果您想要访问则需要将U-A伪装为手机浏览器的U-A
您可以理解为
一个游乐园只允许成年人进入,则U-A就是成年人这个身份
修改U-A
#headers为字典类型
headers={'User-Agent':'能够访问网页的U-A'} #大部分网页使用电脑浏览器U-A即可访问
url='待请求页面的网址(字符串类型)'
requests.get(url='需要请求地址的网址',headers=headers) #将headers传入get方法中的headers参数实现伪装
Cookie
网站为了辨别用户身份,进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息(这样您使用网址中的功能时就不用频繁登陆)
您可以理解为
您一开始只有一张进入园区的门票,待您在售票处买票后(登录)游乐园会将您可游玩的项目写入您的门票里(存储cookie到本地),您进去游玩项目的时候浏览器会自动出示您的门票(浏览器自动解析cookie并将cookie加入请求头),游乐园管理者则会进行验证(服务器验证),验证成功后将会提供服务(服务器返回内容)
cookie一般具有时效性==您的游玩项目的时间有限制,若超过则需要重新购票(登录)
cookie的获取方式
刚入门时建议手动获取
先手动使用浏览器访问您需要获取内容的页面中
然后将cookie复制出来
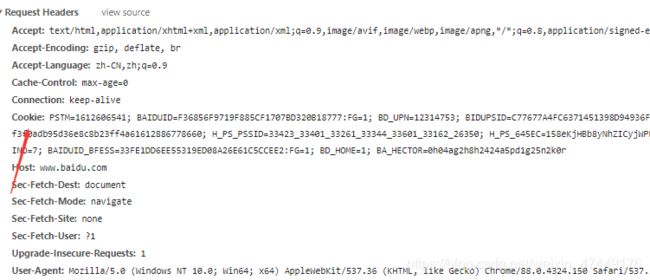
cookie也在Request Headers 请求头中
可以直接 写入headers中
heaedrs={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
,'Cookie':'xxxxxx'
}
其他参数
您有特定使用情形时可以修改
比如: 返回内容的语言 , 返回内容的类型 等
若浏览器不验证则可以忽略
如果需要深入了解,可以看在下的另一篇针对cookie的博文
请求参数 Query String Parameters
您可以理解将请求参数理解的您需要使用游乐项目的名称,您需要将告诉游乐园游乐园才会提供准确的服务(将请求参数添加进请求中发送给服务器)
以CSDN搜索Python为例
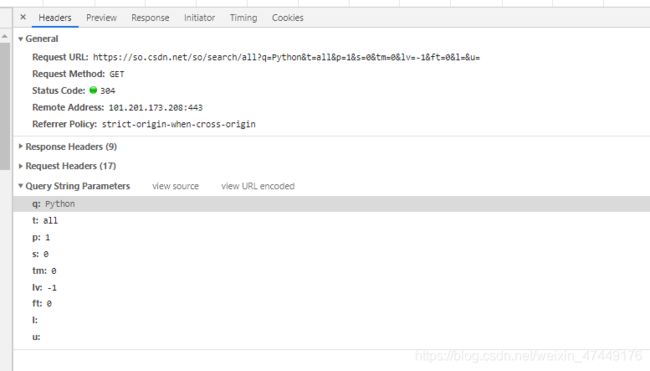
- 简单的网站的请求参数
一眼就可以看出哪个是关键参数例如这里的q:Python
后面的参数您可以进行手动尝试:
将后面的参数去除然后使用浏览器手动输入url进行访问
![]()
如果去除参数能够成功访问,返回的内容是您需要请求的内容,则可以忽略后面的参数直接进行访问
如果多次访问的时候参数在变化(例如时间)
判断是否可以忽略,如果不能忽略则使用其他Python代码进行填入
搜索结果有多页(下拉显示更多也同理)
您需要获取哪一页的内容则需要找到请求参数中控制页数的参数

例如上图的q:就为csdn搜索Python后的页数控制参数
如果参数过多无法分辨,则进行手动抓包
打开F12 进入Network然后手动点击第二页
查看第二页的请求参数和第一页的请求参数有什么不同
找到后将参数修改然后进行验证:
例如将p:1 改成p:20然后进行访问
然后查看p:20 页面是否为第20页即可
如果页数参数比较复杂 例如某宝搜索宝贝返回的详情页
1,2,3,4…页顺序访问
然后将页面的请求参数记下来,将相同的参数放在一起
寻找等差数列然后修改参数进行验证即可
进阶
- 有些网站的参数是由网站的Js代码生成
这样就得去解析这个参数是由哪段js代码生成
然后将js代码放入python代码中执行
此内容需要对Html以及JavaScript有一定了解,所以本文不过多阐述
返回的内容 Response
如何确认您需要获取的数据在哪里 以CSDN搜索Python为例
简单的网页返回内容是没有加密和添加其他内容的,直接在搜索栏里搜索

这里的内容中间是加了一个Html标签的,所以全局搜索不到
编码
在网络上传输的所有内容都是unicode编码后的
网页请求参数中的中文也是进行编码后的才参数的,Python中requests模块自动进行
Urlencode的,所以不需要自己再写代码进行编码
有些网页返回的内容是进行编码后的字符串,所以需要手动进行解码
获取内容
找到包含您需要获取的数据的url后
接下来就是用requests.get去获取数据了
获取下来就可以开始解析
解析就是将返回数据中不需要的内容进行剔除
解析之后就将可以输出到本地或者数据库中
解析方法
1.re模块(正则)
2.bs4模块
3.xpath模块
以上模块为非常容易理解和实用的模块,具体方法本文就不进行阐述了
结束语
了解以上内容之后基本上就可以自己独立手写一个程序去爬取简单的页面了
以上内容是在下的一些拙见,如果有内容表达不清,用词不恰当,请各位海涵并提出
祝各位小伙伴在学习的路上一帆风顺
后续内容
Ip反爬
cookie的生成,以及自动获取cookie实现全自动爬取内容
找到JavaScript生成参数的函数并自己实现
css字体反爬
svg映射
实战项目:全自动根据关键字获取某一城市或全国的大众点评店铺详细信息
实战项目:利用爬虫程序实现全自动每日健康申报
实战项目:Python基于http协议的多线程、ip代理、多账号、自动通过验证码,自动下单的全自动抢购软件,非Webdriver