Python全栈开发-Python爬虫-12 图片验证码
图片验证码处理
目前,很多网站为了防止爬虫爬取,登录时需要用户输入验证码。下面我们学习如何在爬虫程序中识别验证码。
其中包含验证码。
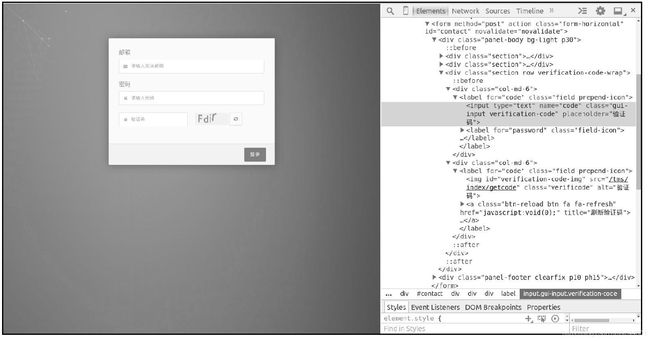
页面中的验证码图片对应一个元素,即一张图片,浏览器加载完登录页面后,会携带之前访问获取的Cookie信息,继续发送一个HTTP请求加载验证码图片。和账号密码输入框一样,验证码输入框也对应一个元素,因此用户输入的验证码会成为表单数据的一部分,表单提交后由网站服务器程序验证。
为何有验证码
什么是图片验证码?
- 验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自动区分计算机和人类的图灵测试)的缩写,是一种区分用户是计算机还是人的公共全自动程序。
验证码的作用
- 防止恶意破解密码、刷票、论坛灌水、刷页。有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登录尝试,实际上使用验证码是现在很多网站通行的方式(比如招商银行的网上个人银行,百度社区),我们利用比较简易的方式实现了这个功能。虽然登录麻烦一点,但是对网友的密码安全来说这个功能还是很有必要,也很重要。
图片验证码使用场景
- 注册
- 登录
- 频繁发送请求时,服务器弹出验证码进行验证
图片验证码的处理方案
- 手动输入(input) 这种方法仅限于登录一次就可持续使用的情况
- 图像识别引擎解析 使用光学识别引擎处理图片中的数据,目前常用于图片数据提取,较少用于验证码处理
- 打码平台 爬虫常用的验证码解决方案
1. OCR识别
OCR(Optical Character Recognition)是指使用扫描仪或数码相机对文本资料进行扫描成图像文件,然后对图像文件进行分析处理,自动识别获取文字信息及版面信息的软件。
在读取和处理图像、图像相关的机器学习以及创建图像等任务中,Python 一直都是非常出色的语言。虽然有很多库可以进行图像处理,但在这里我们只重点介绍:Tesseract
Tesseract 是一个 OCR 库,目前由 Google 赞助(Google 也是一家以 OCR 和机器学习技术闻名于世的公司)。Tesseract 是目前公认最优秀、最精确的开源 OCR 系统,除了极高的精确度,Tesseract 也具有很高的灵活性。它可以通过训练识别出任何字体,也可以识别出任何 Unicode 字符。
2.1 Tesseract
2.1.1 引擎的安装
-
mac环境
brew install --with-training-tools tesseract
-
windows环境
下的安装可以通过exe安装包安装,下载地址可以从GitHub项目中的wiki找到。安装完成后记得将Tesseract 执行文件的目录加入到PATH中,方便后续调用。
- 下载可执行安装文件 https://github.com/UB-Mannheim/tesseract/wiki
-
linux环境下的安装
sudo apt-get install tesseract-ocr
2.1.2 Python库的安装
# PIL用于打开图片文件
pip install pillow==5.1.0
# pytesseract模块用于从图片中解析数据
pip install pytesseract
2.2 引擎的使用
通过pytesseract模块的 image_to_string 方法就能将打开的图片文件中的数据提取成字符串数据,具体方法如下
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe' # 指定安装软件的位置
im = Image.open()
result = pytesseract.image_to_string(im)
print(result)
二值化:
def binarizing(img, threshold):
"""传入image对象进行灰度、二值处理"""
img = img.convert("L") # 转灰度
pixdata = img.load()
w, h = img.size
# 遍历所有像素,大于阈值的为黑色
for y in range(h):
for x in range(w):
if pixdata[x, y] < threshold:
pixdata[x, y] = 0
else:
pixdata[x, y] = 255
return img
降噪:
def depoint(img):
"""传入二值化后的图片进行降噪"""
pixdata = img.load()
w, h = img.size
for y in range(1, h - 1):
for x in range(1, w - 1):
count = 0
if pixdata[x, y - 1] > 245: # 上
count = count + 1
if pixdata[x, y + 1] > 245: # 下
count = count + 1
if pixdata[x - 1, y] > 245: # 左
count = count + 1
if pixdata[x + 1, y] > 245: # 右
count = count + 1
if pixdata[x - 1, y - 1] > 245: # 左上
count = count + 1
if pixdata[x - 1, y + 1] > 245: # 左下
count = count + 1
if pixdata[x + 1, y - 1] > 245: # 右上
count = count + 1
if pixdata[x + 1, y + 1] > 245: # 右下
count = count + 1
if count > 4:
pixdata[x, y] = 255
return img
二值化:http://www.imcta.cn/zhuce_gerenhuiyuan_userzhuce.jsp
二值化+降噪: http://i.djye.com/user?a=register
参考:https://mlog.club/article/26903
2. 百度开发者平台
https://ai.baidu.com/ai-doc/OCR/Ek3h7xypm
在爬取网站的时候都遇到过验证码,那么我们有什么方法让程序自动的识别验证码呢?其实网上已有很多打码平台,但是这些都是需要money。但对于仅仅爬取点数据而接入打码平台实属浪费。所以百度免费ocr正好可以利用。(每天500次免费)
1、注册百度账号、百度云管理中心创建应用、生成AppKey、SecretKey(程序调用接口是要生成access_token)
2、利用AppKey、SecretKey生成access_token
向授权服务地址https://aip.baidubce.com/oauth/2.0/token发送请求(推荐使用POST)并在URL中带上以下参数:
grant_type: 必须参数,固定为client_credentials;
client_id: 必须参数,应用的API Key;
client_secret: 必须参数,应用的Secret Key
from aip import AipOcr
# 你的 APPID AK SK
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# 读取图片
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 测试文件也可以写路径
image = get_file_content('images/depoint.jpg')
# 定义参数变量
options = {
# 定义图像方向
'detect_direction': 'true',
# 识别语言类型,'CHN_ENG' 中英文混合
'language_type': 'CHN_ENG',
}
# 调用通用文字识别接口
results = client.basicGeneral(image, options)
print(results)
# 遍历取出图片解析的内容
# for word in result['words_result']:
# print(word['words'])
try:
code = results['words_result'][0]['words']
except:
code = '验证码匹配失败'
print(code)
3. 打码平台
现在很多网站都会使用验证码来进行反爬,所以为了能够更好的获取数据,需要了解如何使用打码平台爬虫中的验证码
斐斐打码:http://www.fateadm.com/
4. 人工识别
最后讲解的方法听起来似乎很笨:人工识别。通常网站只需登录一次便可爬取,在其他识别方式不管用时,人工识别一次验证码也是可行的,其实现也非常简单——在下载完验证码图片后,调用Image.show方法将图片显示出来,然后调用Python内置的input函数,等待用户肉眼识别后输入识别结果。
附录:
tesseract 问题处理
错误: pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it’s not in your path
解决方法
找到源码中 tesseract_cmd = 'tesseract' 修改为 tesseract_cmd = r'D:\Program Files (x86)\Tesseract-OCR\tesseract.exe'
参考
Python 利用百度文字识别 API 识别并提取图片中文字:https://blog.csdn.net/XnCSD/article/details/80786793
利用百度API实现文字识别:https://blog.csdn.net/JBlock/article/details/79317878
训练好的字体模型: https://github.com/tesseract-ocr/tessdata
登录案例:https://so.gushiwen.org
百度api使用教程:https://blog.csdn.net/zico_a/article/details/103063330
百度api官方文档: https://cloud.baidu.com/doc/OCR/s/zk3h7xz52