java线程池的实现原理与应用
一、老生常谈
1.1、什么是线程池?
线程池是一种基于池化思想管理的线程工具;
1.2、为什么要使用线程池?
线程的创建与销毁会占用系统资源;降低系统整体的性能;线程池管理多个线程,线程等待分配任务,避免了处理任务时线程的创建和销毁;
优点:
a、降低资源消耗;
b、提高响应速度,任务到达时无需等待线程重新创建;
c、提高线程的可管理型;
d、提供更强大的功能,比如演示定时线程池,可以延迟执行任务;
缺点:
线程池中的核心线程会在空闲时期占用系统资源(测试结果显示每个线程占用内存不多,本人自己测试显示空闲时刻线程占用内存大小在10k左右);
二、线程池的总体设计

ThreadPoolExecutor实现的顶层接口是Exector,顶层接口提供了一种思想:任务体检与任务执行解耦;用户无需关注线程的创建,只需要提供Runnable对象;
三、基础使用
1、核心参数

线程池的构造函数中有起个参数:
a、corePoolSize(核心线程大小):线程池核心的线程数量,空闲状态也不会被销毁,除非设置了allowCoreThreadTimeOut为true;
b、maximumPoolSize(线程池最大线程数量):线程池中最大的线程数量,主要是为了防止创建过多的线程;
c、keepAliveTime(空闲线程存活时间)unit(空闲线程存活时间单位);
d、workQueue (工作队列):用于存储等待任务的队列;
e、threadFactory (线程工厂):创建一个新的线程使用的工厂;
f、handler(拒绝策略):当工作队列以及所有线程均被使用时,新任务提交进来的处理策略;
2、队列类型
a、ArrayBlockingQueue
基于数组的有界阻塞队列,按FIFO排序。新任务进来后,会放到该队列的队尾,有界的数组可以防止资源耗尽问题。当线程池中线程数量达到corePoolSize后,再有新任务进来,则会将任务放入该队列的队尾,等待被调度。如果队列已经是满的,则创建一个新线程,如果线程数量已经达到maxPoolSize,则会执行拒绝策略。
b、LinkedBlockingQuene
基于链表的无界阻塞队列(其实最大容量为Interger.MAX),按照FIFO排序。由于该队列的近似无界性,当线程池中线程数量达到corePoolSize后,再有新任务进来,会一直存入该队列,而基本不会去创建新线程直到maxPoolSize(很难达到Interger.MAX这个数),因此使用该工作队列时,参数maxPoolSize其实是不起作用的。
c、SynchronousQuene
一个不缓存任务的阻塞队列,生产者放入一个任务必须等到消费者取出这个任务。也就是说新任务进来时,不会缓存,而是直接被调度执行该任务,如果没有可用线程,则创建新线程,如果线程数量达到maxPoolSize,则执行拒绝策略。
d、PriorityBlockingQueue
具有优先级的无界阻塞队列,优先级通过参数Comparator实现。
3、四种拒绝策略
a、CallerRunsPolicy
直接拒绝任务,由调用方执行;
b、AbortPolicy
直接丢弃任务,抛出异常;
c、DiscardPolicy
直接丢弃任务,什么都不做;
d、DiscardOldestPolicy
抛弃队列最早的任务;
四、任务调度机制(核心重点)
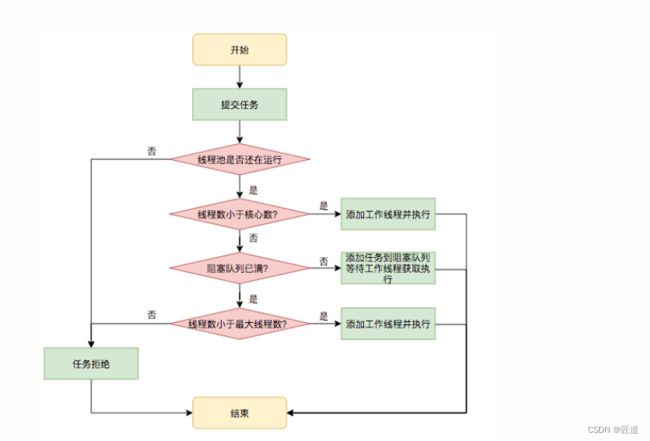
1 向线程池中提交任务,判断线程池是否是运行状态
2 如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。
3 如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。
4 如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。
5 如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
五、核心参数的配置
搞明白上述流程以及参数含义以后,我们来简单聊下核心参数的配置;
1、 核心线程数大小
关于线程池中核心线程大小的设置,可以分为两大类处理方式;
a、cpu密集型:先说结论,(多核cpu)核心线程数量大小=cpu核心数+1;
cpu密集型指的是任务需要大量使用cpu进行计算操作,例如累加、计算圆周率等计算操作;此时我们要让没一核cpu都单独操作一个线程去执行任务,为什么要多一个线程呢?因为万一有线程出现故障导致暂停,这个额外的线程可以填充这部分空缺;
b、io密集型:先说结论,没有特定计算公式,只有根据经验得出的通用计算公式;
核心线程数大小 = cpu核心数*2+1
(注:网上讨论的出自java并发编程的计算公式过于偏理论化;根据tps计算的工时是讲定流量平均分布得出的,不符合真实场景)
个人观点:io密集型要依据业务场景以及流量分布动态调整cpu核心线程数大小;
当我们需要进行io交互时,线程会让出cpu资源,此时可以cpu会通过中断去调度别的线程执行任务;我们要通过对程序的不断测试,看多少线程会使得cpu的资源被充分利用(当然,前提是内存不会溢出的情况);
测试结论,io阻塞时间越长,所需要的线程数量越大,可依据此结论进行压测,得出最符合业务场景的线程数量;
2、队列大小
queueCapacity = (coreSizePool/taskcost)*responsetime
coreSizePool:核心线程数
taskcost:任务执行时间
responsetime:系统响应时间