Relation-Aware Graph Transformer for SQL-to-Text Generation
Relation-Aware Graph Transformer for SQL-to-Text Generation
Abstract
SQL2Text 是一项将 SQL 查询映射到相应的自然语言问题的任务。之前的工作将 SQL 表示为稀疏图,并利用 graph-to-sequence 模型来生成问题,其中每个节点只能与 k 跳节点通信。由于无法捕获长期且缺乏特定于 SQL 的关系,这样的模型在适应更复杂的 SQL 查询时将会退化。为了解决这个问题,我们提出了一种 Relation-Aware Graph Transformer(RGT)来同时考虑 SQL 结构和各种关系。具体来说,为每个SQL构建一个抽象的SQL语法树来提供底层关系。我们还定制了自注意力和交叉注意力策略来编码 SQL 树中的关系。基准 WikiSQL 和 Spider 上的实验表明,我们的方法比强基准有所改进。
1. Introduction
SQL-to-Text:
- SQL(结构化查询语言)是访问数据库的重要工具。然而,SQL对于普通人来说并不容易理解。
- SQL2Text 旨在将结构化SQL程序转换为自然语言描述。
- SQL2Text 可以帮助自动生成 SQL 注释,并构建一个交互式问答系统,用于关系数据库的自然语言接口。
- SQL2Text 对于搜索 Internet 上可用的 SQL 程序很有用。
- SQL2Text 可以通过使用 SQL-to-Text 作为数据增强来协助 Text-to-SQL 任务。
- 在现实世界中,SQL2Text 可以帮助人们通过阅读相应的文本来快速理解复杂的SQL。
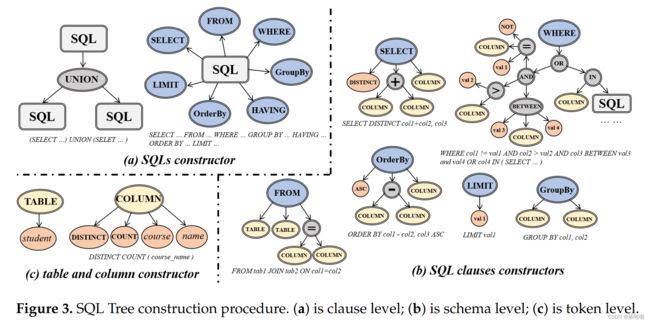
SQL 是结构化的,可以转换为抽象语法树,如图 1 所示。一般来说,树是一种特殊的图,因此 SQL-to-text 可以建模为 Graph-to-Sequence 任务。
- xu 等人考虑了 SQL 查询的内在图结构。他们通过将 SQL 中的每个标记表示为图中的节点,并通过 SQL 关键字节点(例如 SELECT、AND)连接不同的单元(例如列名、运算符、值)来构建 SQL 图。
- 通过图神经网络(GNN)聚合来自 K 跳邻居的信息,每个节点获得其上下文嵌入,该嵌入将在自然语言解码阶段访问。
- 虽然简单有效,但它有两个主要缺点:
- 由于构造的 SQL 图的稀疏性,泛化能力较差;
- 忽略不同节点对之间的关系,特别是列节点之间的相关性。
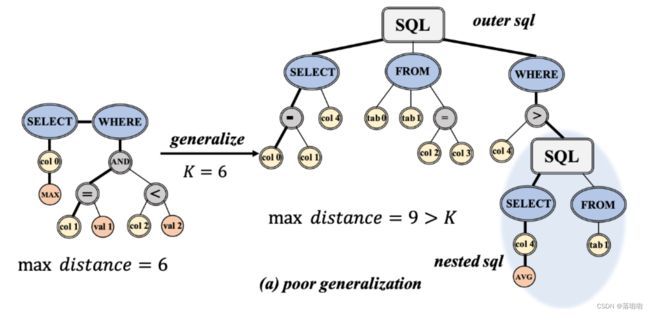
特别是,Xu 等人仅处理简单的 SQL 模式 SELECT AGG COLUMN WHERE COLUMN OP VALUE (AND COLUMN OP VALUE)。这些模式中只提到了一个列单元和一个表,所有约束都是通过 WHERE 子句中的条件交集来组织的。该模型通过 K 步迭代更新每个节点的上下文嵌入。每个节点在一次迭代中只会与其 1 跳邻居进行通信,因此每个节点在迭代结束时只能 “看到” K 距离内的节点。当我们转移到由多个表、GroupBy/HAVING/OrderBy/LIMIT 子句和嵌套 SQL 组成的更复杂的 SQL 模式时,性能很容易恶化。如图 1 所示的示例,K = 6 的 Graph2Seq 模型可能在简单 SQL(如左图所示)上运行良好,但在依赖距离较长的复杂 SQL(如右图所示)上泛化效果较差。
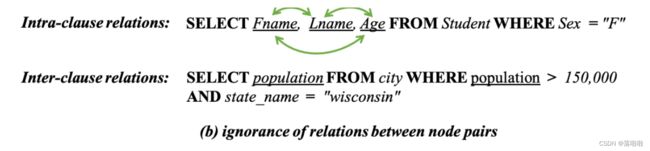
我们发现,即使两个节点在序列化 SQL 查询和解析的抽象语法树中相距较远,它们也可能具有较高的相关性。例如,同一子句(子句内)中提到的列紧密相关。参见下图中的示例。用户总是不仅需要特定候选人的姓氏,还需要名字。同样,在 WHERE 子句中充当条件之一的列也很有可能在 SELECT 子句(子句间)中被精确请求。以往的工作更多地关注SQL的语法结构,而忽略了语义层面上的这些潜在关系。
为此,我们提出了一种 Relation-aware Graph Transformer(RGT)来考虑 sql 查询的抽象语法树和不同节点对之间的相关性。整个节点集分为两部分:中间节点和叶子节点。
- 叶节点通常是原始表名或列字,加上一些一元修饰符,例如 DISTINCT 和 MAX。通常,这些叶节点传达查询中的重要语义信息。
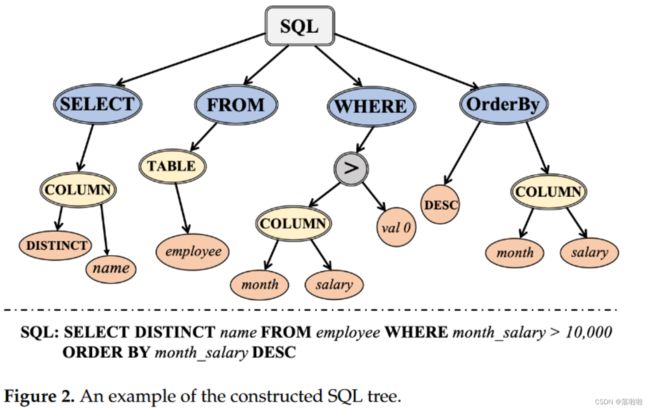
- SELECT 和 AND 等中间节点本质上捕获底层 SQL 查询的树结构,并将分散的叶节点连接起来。构建的 SQL 树的示例如图 2 所示。
我们在 SQL 树中引入了四种类型的关系,并提出了两种交叉注意力的变体来捕获结构信息。所有关系均由我们提出的 RGT 模型进行编码。
- 由于SQL查询可能涉及多个表,因此我们首先考虑抽象概念TABLE和COLUMN之间的关系,称为数据库模式(DBS)。给定两个表示 TABLE 或 COLUMN 的节点,它们可能是同一个表中的两列,也可能是通过外键连接的两个表。我们定义了 11 种不同类型的 DBS 来描述这种关系。
- 此外,节点的深度反映了信息量:更深的节点包含更多语义信息,而较浅的节点包含更多语法信息。我们引入定向相对深度(DRD)来捕获中间节点之间的相对深度。
- 对于叶节点来说,最重要的关系是从属关系。例如,在图2中,叶子节点month和salary连接到COLUMN节点,而COLUMN和另一个叶子节点val0属于中间节点>。这三个叶节点是高度相关的。
- 我们使用最低共同祖先(LCA)来衡量两个叶节点的紧密程度。我们可以看到,节点month和val0的LCA就是图2中的节点>。
此外,为了利用 SQL 的树结构,我们使用两种交叉注意力策略,即 attention over ancestors(AOA)和 attention over descendants(AOD)。AOA仅允许叶节点关注其祖先,AOD仅允许中间节点仅关注其后代。
我们使用各种基线模型对基准 WikiSQL 和 Spider 进行了广泛的实验。据我们所知,我们是第一个在涉及多个表和复杂条件的 SQL 模式上执行 SQL-to-Text 任务的人。结果表明,与其他替代方案相比,我们的模型具有良好的泛化能力。
主要贡献:
- 我们提出了一种 relation-aware graph transformer来考虑 SQL 图中节点对之间的各种关系。
- 我们是第一个在数据集Spider 上使用更复杂的SQL 模式执行SQL 到文本任务的人。
- 大量实验表明,我们的模型优于各种Seq2Seq 和Graph2Seq 模型。
2. Model
2.1 SQL Tree Construction
构建的SQL树 V V V 的整个节点集被分为两类:中间节点 V I = { v i I } i = 1 ∣ V I ∣ V^I = \{v^I_i\}^{|V_I|}_{i=1} VI={viI}i=1∣VI∣ 和叶节点 V L = { v i L } i = 1 ∣ V L ∣ V^L = \{v^L_i\}^{|V_L|}_{i=1} VL={viL}i=1∣VL∣。
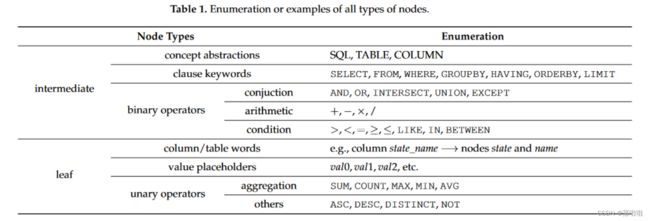
- 中间节点包含三个抽象概念(SQL、TABLE 和 COLUMN)、七个 SQL 子句关键字(SELECT、WHERE 等)和二元运算符(>、<、= 等)
- 叶节点包含一元运算符、原始表名称、列词以及实体值的占位符(诸如“new york”之类的实体,在预处理过程中被替换为一种特殊标记 v a l 0 val_0 val0,称为去词法化)。
通过这种分类方法,可以使用不同的关系信息来更新这两种类型的节点嵌入。
从根节点 SQL 开始:
- 我们首先添加子句关键字作为其子节点。
- SQL被分为一些子句,例如SELECT子句、WHERE子句、嵌套SQL子句等(见图3a)。
- 然后概念抽象节点TABLE和COLUMN以及相关的操作符节点相应地附加到它们的父节点。
- 每个子句由多个表、列和一些其他二元运算符组成。考虑到一些表名和列名有多个标记,我们设计了两个抽象节点(TABLE和COLUMN)来解决这个问题(见图3c)。通过这两个抽象节点,子句节点可以表示为如图 3b 所示。注意到二元运算符可以被视为多个节点之间的关系,我们将它们设置为中间节点(一些子节点的父节点)。
- 接下来,对于节点 COLUMN 和 TABLE,我们将所有原始单词、aggregators 和不同 标记 附加为叶节点。
我们的 SQL 树由三个级别组成(参见图 3):子句级别、模式级别和标记级别。表 1 显示了所有类型的节点。
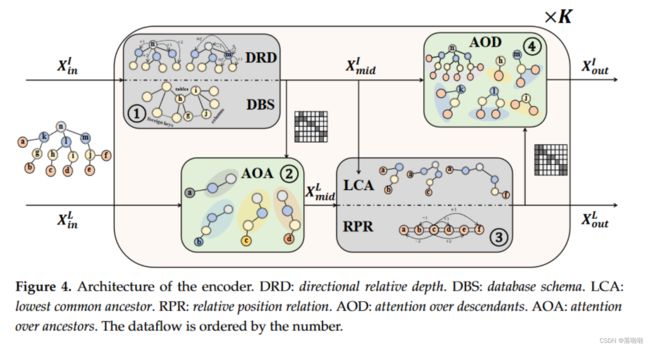
2.2 Encoder Overview
输入特征包括所有节点和关系的可训练嵌入。我们使用 X L ∈ R ∣ V L ∣ × d x X^L ∈ R^{|V_L|×d_x} XL∈R∣VL∣×dx 和 R L = [ r i j L ] ∣ V L ∣ × ∣ V L ∣ R^L = [r^L_{ij}]_{|V^L|×|V^L|} RL=[rijL]∣VL∣×∣VL∣表示叶节点嵌入和叶节点之间的关系矩阵的集合。相应地, X I ∈ R ∣ V I ∣ × d x X^I ∈ R^{|V_I|×d_x} XI∈R∣VI∣×dx 和 R I = [ r i j I ] ∣ V I ∣ × ∣ V I ∣ R^I = [r^I_{ij}]_{|V^I|×|V^I|} RI=[rijI]∣VI∣×∣VI∣ 对应于中间节点。
编码器由 K 个堆叠块组成,如图 4 所示。主要组件是关系感知图 Transformer (RGT),它将节点嵌入矩阵 X X X、关系矩阵 R R R 和 从 R R R 中提取关系嵌入的关系函数 E E E 作为输入,并输出更新的节点矩阵。每个块包含四个模块:一个用于中间节点的 RGT,一个用于叶节点的 RGT,以及两个交叉注意力模块。在每个块中,节点嵌入 X I X^I XI 和 X L X^L XL 通过自注意力和交叉注意力顺序更新。根据图 4 中的数据流,中间节点首先更新为:
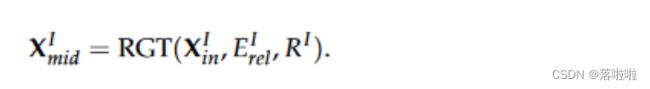
然后,叶节点参与中间节点并使用 RGT 进行更新:
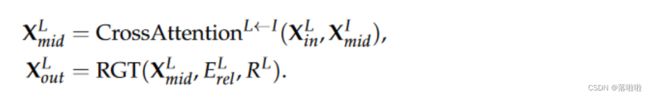
最后,中间节点也参与叶节点:
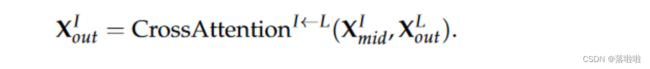
下标 in、mid、out 用于区分输入和输出。关系嵌入函数 E r e l I E^I_{rel} ErelI 和 E r e l L E^L_{rel} ErelL、关系矩阵 R I R^I RI和 R L R^L RL以及模块 C r o s s A t t e n t i o n I ← L ( ⋅ , ⋅ ) CrossAttention^{I←L}(·,·) CrossAttentionI←L(⋅,⋅) 和 C r o s s A t t e n t i o n L ← I ( ⋅ , ⋅ ) CrossAttention^{L←I}(·,·) CrossAttentionL←I(⋅,⋅) 的定义将在后面详细阐述。
2.3 Relation-Aware Graph Transformer
我们利用 Transformer 作为我们模型的骨干,它可以被视为图注意力网络的一个实例(GAT),其中每个节点的感受野是整个节点集。我们将 SQL 树视为一种特殊的图。假设输入图为 G = ( V , R ) , V = { v i } i = 1 ∣ V ∣ , R = [ r i j ] ∣ V ∣ × ∣ V ∣ G = (V, R), V = \{v_i\}^{|V|}_{ i=1},R = [r_{ij}]_{|V|×|V|} G=(V,R),V={vi}i=1∣V∣,R=[rij]∣V∣×∣V∣,其中 V V V是顶点集, R R R是关系矩阵。每个节点 v i ∈ V v_i ∈ V vi∈V 都有一个随机初始化的嵌入 x i ∈ R d x x_i ∈ R^{d_x} xi∈Rdx 。之前的工作将节点 v i v_i vi 和 v j v_j vj 之间的相对位置纳入相关性得分计算和上下文聚合步骤中。类似地,我们通过引入额外的关系向量来使这项技术适应我们的框架。从数学上讲,给定关系矩阵 R R R,我们构造一个关系嵌入函数 E r e l E_{rel} Erel 来检索关系 r i j r_{ij} rij 的特征向量 e i j = E r e l ( r i j ) ∈ R d x / H e_{ij} = E_{rel}(r_{ij}) ∈ R^{d_x/H} eij=Erel(rij)∈Rdx/H。然后,经过一层迭代后节点 v i v_i vi 的输出嵌入 y i y_i yi 计算如下:
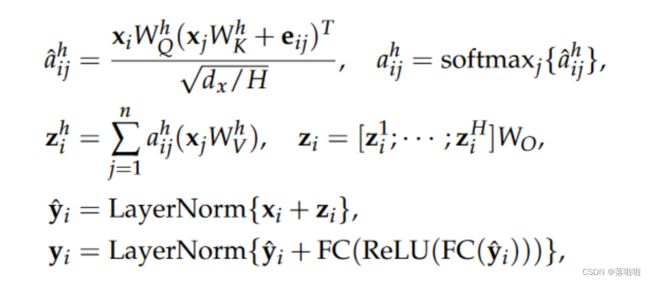
除非另有说明,关系嵌入函数 E r e l E_{rel} Erel 在不同头和多层之间共享。为了方便讨论,我们将 RGT 编码模块的表示法简化为:
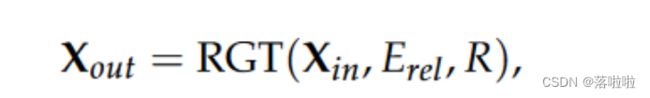
其中 X i n = [ x 1 ; ⋅ ⋅ ⋅ ; x ∣ V ∣ ] X_{in} = [x_1; · · · ; x_{|V|}] Xin=[x1;⋅⋅⋅;x∣V∣] 表示所有节点的输入嵌入矩阵。
2.4 Relations among Intermediate Nodes
对于中间节点,我们考虑两种类型的关系:数据库模式(DBS)和定向相对深度(DRD)。 DBS考虑抽象概念TABLE和COLUMN之间的关系。我们总共定义了 11 种关系。例如,如果节点 v i I v^I_i viI 和 v j I v^I_j vjI 是 COLUMN 类型的节点,并且根据数据库模式它们属于同一个表,则关系 r i j D B S r^{DBS}_{ij} rijDBS 是 SAME-TABLE。表 2 显示了 DBS 关系的完整版本。从数学上来说,

其中关系嵌入函数 E r e l D B S E^{DBS}_{rel} ErelDBS 将关系类别 r i j D B S r^{DBS}_{ij} rijDBS 映射到可训练向量 e i j D B S e^{DBS}_{ij} eijDBS 。

借助底层有向 SQL 树,我们可以构建另一个关系矩阵来表示两个中间节点 v i I v^I_i viI 和 v j I v^I_j vjI 之间的可达性和相对深度差异。设 d ( v i I ) d(v^I_i ) d(viI) 表示节点 v i I v^I_i viI 的深度,例如根 SQL 节点的深度为 1(见图 4)。给定最大深度差 D,
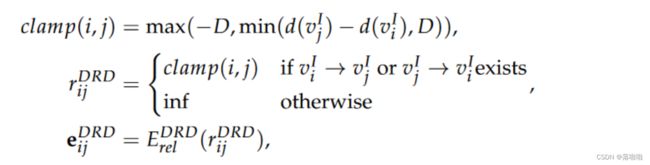
其中 E D R D E^{DRD} EDRD 是具有 2 D + 2 2D + 2 2D+2 个条目的关系嵌入模块。一项特殊条目代表不可访问性 inf。
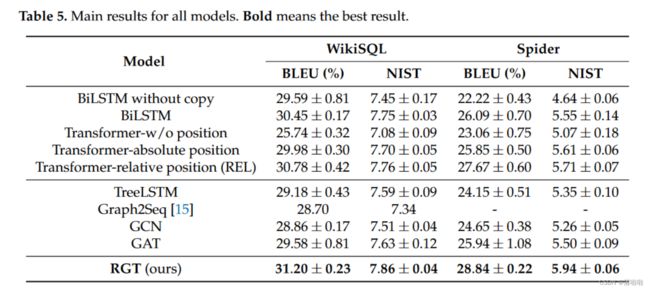
3. Experiments
3.1 Dataset
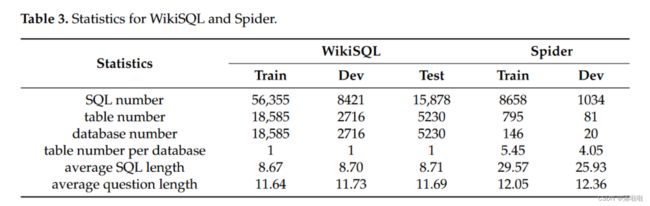
WikiSQL 我们使用最新版本的 WikiSQL 进行实验。 WikiSQL 中的 SQL 仅包含长度较短的 SELECT 和 WHERE 子句。我们利用官方的训练/开发/测试拆分,确保每个表仅出现在单个拆分中。此设置要求模型在推理过程中泛化到看不见的表。
Spider 我们还使用 Spider,一个更复杂的数据集。与 WikiSQL 相比,Spider 中的 SQL 更长,数据量小得多。此外,Spider中还涉及到一些其他复杂的语法,例如JOIN、HAVING和嵌套SQL。
因此,Spider上的任务要困难得多。考虑到测试分割不公开,我们只使用训练分割和开发分割。
3.2 Experiment Setup
Metric 我们使用 BLEU-4 和 NIST 作为自动指标。每个 SQL 在 WikiSQL 中都有一个参考。在Spider中,大多数SQL都有双重引用,因为很多 SQLs 分别对应两种不同的自然语言表达。然而,该指标存在两个威胁:(1)结果可能会严重波动。 (2)BLUE-4无法全面评估生成文本的质量。为了减轻结果的波动,我们使用不同的随机种子运行所有实验 5 次。此外,我们对 Spider 进行了人类评估,以将我们的模型与最强的基线进行比较。
Data preprocessing 对于 WikiSQL,我们省略了 FROM 子句,因为所有 SQL 只与单个表相关。对于Spider,我们将表别名替换为其原始名称,并删除AS语法。此外,如前所述,问题被去词汇化了。
3.3 Main Results