第十周周报
文章目录
- 摘要
- ResNet
- 深度学习硬件:CPU 和 GPU
- 深度学习硬件TPU和其他
- 单机多卡并行
- 多GPU训练
- 总结
摘要
本周学习了ResNet网络设计思想的由来,解决了对应的梯度爆炸或消失的问题,并基于梯度计算的层面理解ResNet的作用。还学习了CPU和GPU、TPU有关深度学习硬件方面的知识,主要是了解了
AI ASIC中systolic array实现矩阵乘法的算法。它是通过计算单元PE来实现的。
This week, I learned about the origin of the design philosophy behind the ResNet network, addressing the issues of gradient explosion or vanishing. I also gained a conceptual understanding of ResNet’s role based on gradient computation at the layer level. Additionally, I delved into knowledge related to deep learning hardware, specifically CPU, GPU, and TPU. The focus was on understanding the implementation of matrix multiplication algorithms in AI ASIC, particularly through the systolic array in which computation units (PE) play a key role.
ResNet
既要把层数堆叠起来,还不能让后面的层数(学习比较差的层数)影响之前的效果。
ResNet的核心思想是,如果某一层训练表现的不好,就把它参数学习成零就好了。至少有一个保底的网络,实现的方法就是将这层的输入的数据与这层输出的数据堆叠起来,共同作为输出,传到下一层去。ResNet的学习完的网络,至少不比原来的差。
ResNet梯度计算
ResNet梯度计算,用加法取代乘法,在传统计算梯度时,都是各层梯度相乘(链式法则),因此如果有一层的梯度特别小时,就会使整个梯度非常小,累乘的情况就会出现梯度爆炸或者梯度消失的情况。而ResNet的函数是经过一些卷积层处理的结果f(x)再加上输入的值g(x),对其求梯度时,如果f(x)的梯度出了问题,也不会影响x,保证f=f(x)+g(x)始终有值存在。

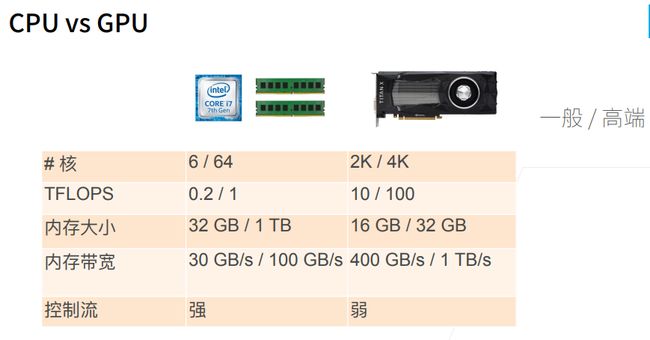
深度学习硬件:CPU 和 GPU
提高cpu利用率I
提升空间和时间的内存本地性,使其需要使用的数据接近目前在缓存里的数据,这样就能加快数据的提取,从而加快速度。
CPU比GPU慢的原因,就是在CPU计算需要从内存经过3级缓存来得到数据。

访问数组元素时,CPU不会每次只从内存中读取一个元素,而是读取一个区域的元素。 假设二维数组的大小为(10 x 10),访问第一个元素时,CPU也会读取它的相邻元素,因为这个数组比较小,CPU一次就可以把所有元素缓存,因此无论是按行访问数组还是按列访问数组,CPU访问主存的数量都相同。 随着数组元素越来越多,CPU缓存一次只能读取数组不到一行的数据,因此按列访问元素时每访问一个元素都要访问内存,因此速度就会慢很多。
提升CPU利用率2:
因为CPU是多核,因此使用并行运算能极大减少运算时间。

如上图所示,python实现左边的速度比右边慢很多。是因为左边是串行执行的,右边是并行执行。
GPU通常具有大量的小型处理单元,称为CUDA核心(NVIDIA GPU)或流处理单元(AMD GPU)。这些核心可以同时执行不同的指令,从而使GPU能够在相同时间内处理多个任务。相比之下,CPU通常有较少的核心,但这些核心更强大。
PU的架构设计更注重并行性。GPU被设计用于处理图形渲染,这是一个高度并行的任务,涉及对图像的许多像素进行相同类型的计算。因此,GPU的硬件架构被优化为同时处理大量相似的任务,这使其在执行许多相似操作时更加高效。
CPU的内存带宽也低于GPU内存带宽,这也是计算速度慢的原因之一。
CPU是一个通用计算,不是纯粹用于计算矩阵乘法,还要实现各种控制流计算(if else)。
提升GPU利用率
并行:使用上千个线程
内存本地性:缓存较小,架构更加简单
少使用控制语句:支持有限,同步开销很大
不要频繁在CPU和GPU之间传数据。

总结:CPU可以处理通用计算,性能优化考虑数据读写效率和多线程。
GPU使用更多的小核和更好的内存带宽,适合能大规模并行的计算任务。
深度学习硬件TPU和其他

上图是一个集成了GPU和CPU等诸多功能的手机芯片。
DSP芯片:数字信号处理。
主要是给点积、卷积、傅里叶信号处理使用的。
核少、频率也低,因此功耗低。

FPGA:可编程阵列
是一块硬件,里面有大量可以编程逻辑单元和可配置的连接。

AI ASIC
针对某个领域做出的特定的芯片。
大公司都在造自己深度学习领域的芯片。其中最著名的是Google TPU。

systolic array 是专门用于做特别大矩阵的乘法模块。为什么要做AI ASIC是因为便宜。ASIC芯片是给特定应用用的,因此不需要考虑其他的东西,研发的成本较低。通常是在FPGA上模拟ASIC。
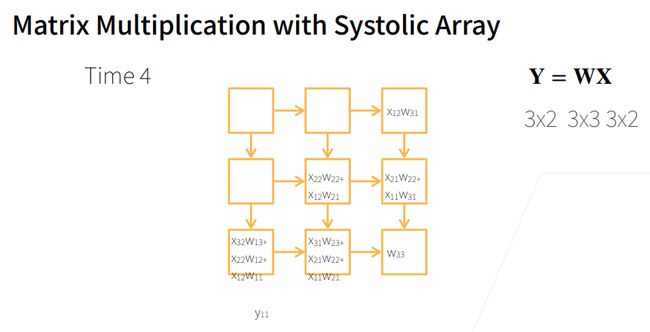
systolic array(脉动阵列)

他是由计算单元PE构成的,特别适合做矩阵乘法。设计和制作相对简单。他做矩阵乘法时候,比如Y=WX,w为权重矩阵,那么w对应的各个元素就按下标放入对应的计算单元PE中,然后被乘的X矩阵,各列先反过来做对称(列如原来是123列,变成321列),行与行之间分别间隔一列的形式放上去。


然后再时刻1,整个变形后的X矩阵往右移动,那么首先X11就与w11相交了,然后就进行乘法运算,而x11所在列的其他元素都为0,0与相交的w矩阵里面的元素不做运算。

接着在Time2,X矩阵继续向右移动1个单位,而进过Time1计算的结果(w11x11)就往下移动,此时x21又与w12相遇,它们两做乘法,并与w11x11的结果相加。

接下来的每个Time都是执行输入矩阵往右,结果往下移动的过程。(结果只会往下移动,输入的矩阵的元素只往右移动),最后就输出了一个交错的Y矩阵,经过变换就形成了最后的结果矩阵。



单机多卡并行
数据并行:将小批量分成n块,每个GPU拿到完整参数计算一块的数据的梯度。通常性能更好
模型并行:将模型分成N块,每个GPU拿到一块模型计算它的前向和方向的结果。
通常用于模型大到单GPU放不下的情况。
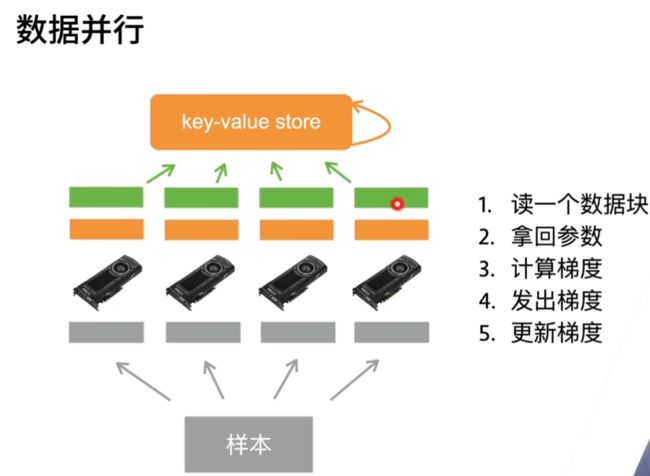
当一个模型能用单卡计算时,通常使用数据并行拓展到多卡上,模型并行则用在超大模型上。
多GPU训练

一般来说, k k k个GPU并行训练过程如下:
- 在任何一次训练迭代中,给定的随机的小批量样本都将被分成 k k k个部分,并均匀地分配到GPU上;
- 每个GPU根据分配给它的小批量子集,计算模型参数的损失和梯度;
- 将 k k k个GPU中的局部梯度聚合,以获得当前小批量的随机梯度;
- 聚合梯度被重新分发到每个GPU中;
- 每个GPU使用这个小批量随机梯度,来更新它所维护的完整的模型参数集。
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# 初始化模型参数
scale = 0.01
W1 = torch.randn(size=(20, 1, 3, 3)) * scale
b1 = torch.zeros(20)
W2 = torch.randn(size=(50, 20, 5, 5)) * scale
b2 = torch.zeros(50)
W3 = torch.randn(size=(800, 128)) * scale
b3 = torch.zeros(128)
W4 = torch.randn(size=(128, 10)) * scale
b4 = torch.zeros(10)
params = [W1, b1, W2, b2, W3, b3, W4, b4]
# 定义模型
def lenet(X, params):
h1_conv = F.conv2d(input=X, weight=params[0], bias=params[1])
h1_activation = F.relu(h1_conv)
h1 = F.avg_pool2d(input=h1_activation, kernel_size=(2, 2), stride=(2, 2))
h2_conv = F.conv2d(input=h1, weight=params[2], bias=params[3])
h2_activation = F.relu(h2_conv)
h2 = F.avg_pool2d(input=h2_activation, kernel_size=(2, 2), stride=(2, 2))
h2 = h2.reshape(h2.shape[0], -1)
h3_linear = torch.mm(h2, params[4]) + params[5]
h3 = F.relu(h3_linear)
y_hat = torch.mm(h3, params[6]) + params[7]
return y_hat
# 交叉熵损失函数
loss = nn.CrossEntropyLoss(reduction='none')
对于高效的多GPU训练,我们需要两个基本操作。首先,我们需要向多个设备分发参数并附加梯度。如果没有参数,就不可能在GPU上评估网络。第二,需要跨多个设备对参数求和,也就是说,需要一个allreduce函数。
def get_params(params, device):
new_params = [p.to(device) for p in params]
for p in new_params:
p.requires_grad_()
return new_params
new_params = get_params(params, d2l.try_gpu(0))
print('b1 权重:', new_params[1])
print('b1 梯度:', new_params[1].grad)
def allreduce(data):
for i in range(1, len(data)):
data[0][:] += data[i].to(data[0].device)
for i in range(1, len(data)):
data[i][:] = data[0].to(data[i].device)
数据并发:将一个小批量数据均匀地分布在多个GPU上
现在我们可以[在一个小批量上实现多GPU训练。 在多个GPU之间同步数据将使用刚才讨论的辅助函数allreduce和split_and_load。 不需要编写任何特定的代码来实现并行性。 因为计算图在小批量内的设备之间没有任何依赖关系,因此它是“自动地”并行执行。
def train_batch(X, y, device_params, devices, lr):
X_shards, y_shards = split_batch(X, y, devices)
# 在每个GPU上分别计算损失
ls = [loss(lenet(X_shard, device_W), y_shard).sum()
for X_shard, y_shard, device_W in zip(
X_shards, y_shards, device_params)]
for l in ls: # 反向传播在每个GPU上分别执行
l.backward()
# 将每个GPU的所有梯度相加,并将其广播到所有GPU
with torch.no_grad():
for i in range(len(device_params[0])):
allreduce(
[device_params[c][i].grad for c in range(len(devices))])
# 在每个GPU上分别更新模型参数
for param in device_params:
d2l.sgd(param, lr, X.shape[0]) # 在这里,我们使用全尺寸的小批量
data = torch.arange(20).reshape(4, 5)
devices = [torch.device('cuda:0'), torch.device('cuda:1')]
split = nn.parallel.scatter(data, devices)
print('input :', data)
print('load into', devices)
print('output:', split)
为了方便以后复用,我们定义了可以同时拆分数据和标签的split_batch函数。
#@save
def split_batch(X, y, devices):
"""将X和y拆分到多个设备上"""
assert X.shape[0] == y.shape[0]
return (nn.parallel.scatter(X, devices),
nn.parallel.scatter(y, devices))
def train(num_gpus, batch_size, lr):
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
devices = [d2l.try_gpu(i) for i in range(num_gpus)]
# 将模型参数复制到num_gpus个GPU
device_params = [get_params(params, d) for d in devices]
num_epochs = 10
animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])
timer = d2l.Timer()
for epoch in range(num_epochs):
timer.start()
for X, y in train_iter:
# 为单个小批量执行多GPU训练
train_batch(X, y, device_params, devices, lr)
torch.cuda.synchronize()
timer.stop()
# 在GPU0上评估模型
animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(
lambda x: lenet(x, device_params[0]), test_iter, devices[0]),))
print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,'
f'在{str(devices)}')
总结
本周学习时间较少,进行了组合数学的考试,剩下的时间也放在下周需要考试的科目上。