C++Mysql8.0数据库跨平台编程实战(下)
C++Mysql8.0数据库跨平台编程实战(下)
- 第六章 跨平台中文乱码问题和mysql锁
-
- 1、MySQLAPIC++封装策略和方法说明
- windows上字符集gbk和utf8互转
-
- 开始写代码把测试框架搭起来
- linux上字符集GBK和UTF8互转
- ZPMysql库添加字符集转换函数并测试GBK
-
- 插入utf-8的数据
-
- 我们把代码在linux运行看看
- 插入gbk的数据
- 简易获取数据的接口GetResult实现
- mysql的表锁和行锁代码示例购票竞争
- 第七章 日志审计系统项目实战和课程总结
-
- 日志审计系统项目模块分析
- 日志审计系统Agent模块项目
- 日志审计系统Center模块项目
-
- Center模块安装配置和数据初始化
- Center审计策略表安装和策略添加
- 完成Center的添加设备
- Center主循环获取到Agent发送的最新事件
第六章 跨平台中文乱码问题和mysql锁
1、MySQLAPIC++封装策略和方法说明

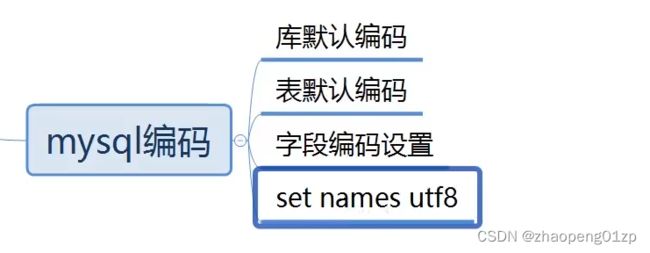

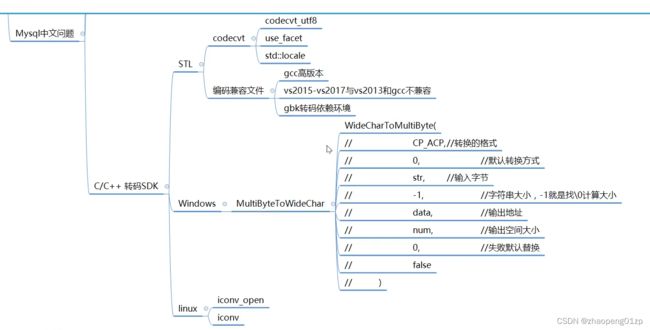

我们希望一套代码到处编译,所以这里我们选择了系统的API,系统API也比较简单:

windows上字符集gbk和utf8互转
我们先说明一下我们怎么测这个案例,就是每次你做一个案例,就要想怎么测。
-
UTF-8到GBK的转换
第一个就是UTF-8转GBK的话,GBK可以直接在控制台显示,这个跟系统有关,我们系统控制台默认是GBK,所以说UTF-8转GBK很简单,我们直接cout打印就行了;
那么UTF-8这种编码的字符串从哪里来呢?我们直接把这个代码字符串前面加一个u8就可以了,但这样呢还是会有问题的,并不是说很兼容;我们直接把代码文件设成utf-8的,但是有的机器上这样设置后,当编译成字符串的时候还是GBK,也就是说它编译的时候做了转换;
所以这个时候,我们比较靠谱的方法就是说,在字符串前面加一个u8,例如u8"我这个是utf-8的字符串",告诉编译器我们要把所标识的这个字符串转成utf-8,就跟你在linux当中编译的时候指定这个代码用什么编译一样。 -
GBK到UTF-8的转换
我们默认的就是GBK,你不加u8,并且把代码转成GBK的,把我们的代码文件转成GBK的,然后再把把转化成UTF-8的;
而UTF-8怎么测呢,打印是输出不了的,在Linux当中可以输出(linux默认输出是utf-8的),在windows当中不行,那怎么办呢?几个方案:
(1)把UTF-8写到文件里面去;
(2)我们前面不是做了UTF-8转GBK么,我们再转一遍把它输出就可以了。
开始写代码把测试框架搭起来


我们可以看到控制台默认是GBK的。


有的vs版本(例如vs2017)的默认编码是UTF-8的,可以从上图看到,我们这里的vs2019默认编码是GBK的。
当然你可以基于其他的工具(例如notepad++、UltraEdit推荐):
我们把代码换成ANSI编码的话,代码里面的中文注释都成乱码了:

我们可以点击下面的菜单:转为ANSI编码,就可以把代码转为ANSI编码格式了。
// test_gbk_utf8.cpp
//
#include linux上字符集GBK和UTF8互转

我们用UE把代码转成UTF-8格式:

在windows下要选择utf-8(有BOM)。
// test_gbk_utf8_linux makefile
test:test_gbk_utf8_linux.cpp
g++ $^ -o $@
// test_gbk_utf8.cpp
//
#include ZPMysql库添加字符集转换函数并测试GBK
我们这边字符集转换主要涉及两方面的内容:插入和读取。
插入utf-8的数据

我们把代码在linux运行看看
// ZPMysql makefile
testZPMysql:test_ZPMysql.cpp libZPMysql.so
g++ test_ZPMysql.cpp -L./ -lZPMysql -o $@ -g
libZPMysql.so:ZPData.cpp ZPMysql.cpp ZPData.h ZPMysql.h
g++ -fPIC -shared -g $^ -I/usr/include/mysql/ -lmysqlclient -o $@
run:
./testZPMysql
install:
@cp libZPMysql.so /usr/lib/
@echo "install libZPMysql.so success!"
uninstall:
@rm -rf /usr/lib/libZPMysql.so
@echo "uninstall libZPMysql.so success!"
clean:clear
@echo "clear project success!"
clear:
@rm -rf *.o *.so testZPMysql
@echo "clear project success!"
上述makefile执行输出:
g++ -fPIC -shared ZPData.cpp ZPMysql.cpp ZPMysql.h ZPData.h -o libZPMysql.so -I/usr/include/mysql -lmysqlclient
g++ ./test_ZPMysql/test_ZPMysql.cpp -o test_ZPMysql -I./ -lZPMysql -L./
cp libZPMysql.so /usr/lib
install libZPMysql.so success!
./test_ZPMysql
在linux当中我们也测试成功,这样的话,我们同一份代码在两个系统都已经插入成功。
插入gbk的数据
utf8在各个平台通用,但是gbk数据在linux当中就没有了(无法正常显示);
这里我们先插入,等有问题了再来解决。
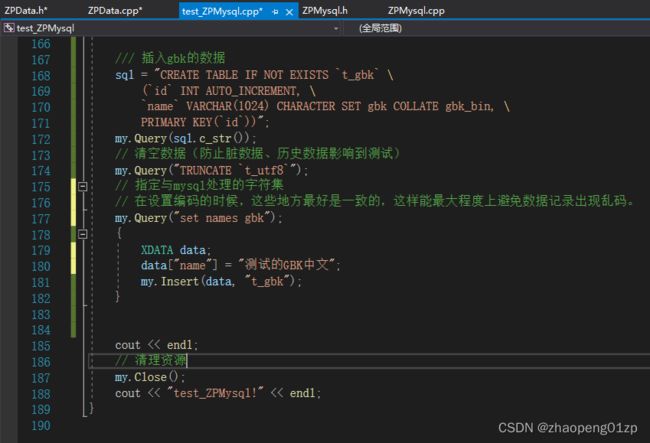
在linux当中我们测试发现是乱码,因为linux这边是当做utf-8的,要插入的字段name是gbk的,你把utf-8插进去肯定是乱码;
所以在linux当中我们要做个转换,把utf-8转换成gbk。

在ZPData.cpp中,把前面我们写的UTF8ToGBK和GBKToUTF8这两个函数的代码粘贴过来:



我们查询数据库发现显示没问题。
我们来编写从数据库中获取数据的代码:
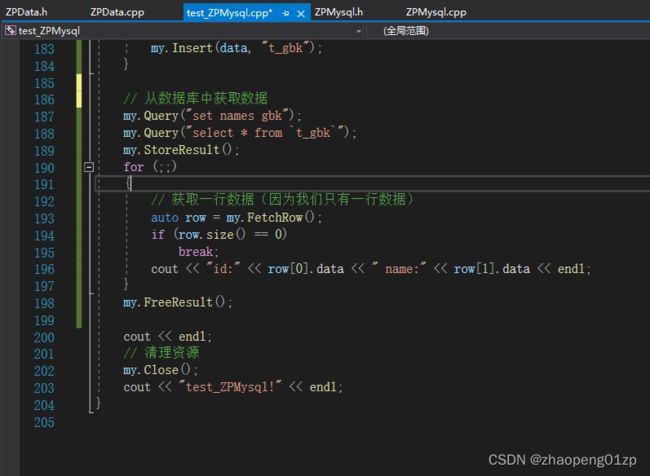
在linux当中因为name字段存的是gbk的,所以获取后不能正常显示。
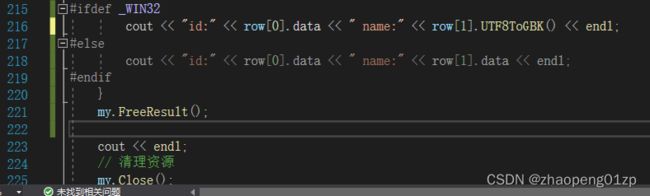
我们修改代码,可以判断是否是在linux当中,如果在linux当中我们要做个转换才能正常输出:

这样在windows和linux当中测试都没有问题。

我们可以看到在控制台中的utf8输出是乱码,这是因为控制台的编码是GBK的,所以我们在windows当中的时候需要转换,而在linux当中就不需要转换了,因为linux是直接支持utf-8显示的。
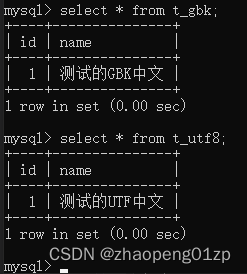
这样我们就完成了对于中文字符的UTF-8和GBK之间的互相转换,插入和读取功能就做完了。
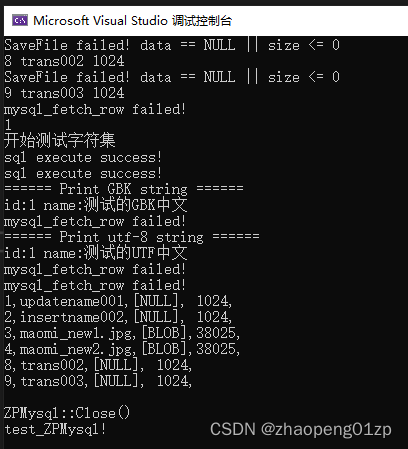
简易获取数据的接口GetResult实现




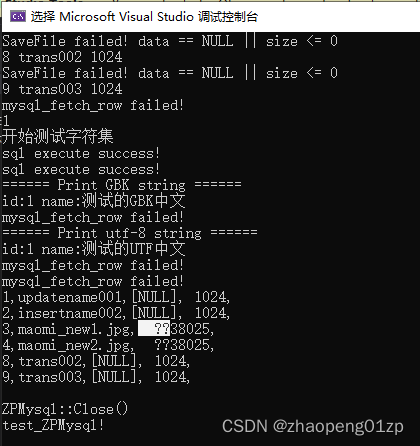
经测试我们发现没有输出BLOG,说明我们FetchRow的时候没有把类型保存起来(为了性能的话可以在StoreResult里面保存)。

mysql的表锁和行锁代码示例购票竞争
mysql的锁一般只是针对我们做事务的时候才会用到,最常见的用法,比方说订票,就是你不能保证你这次操作是原子操作,因为订票是两个操作的,第一步先查这个票有没有售完,第二步把这张票标识为已售完。

行锁,我们用事务来演示,开两个线程来演示,或者让我们程序运行两遍。
// 订票模拟(事务) t_tickets(id int, sold int)
sql = "CREATE TABLE IF NOT EXISTS `t_tickets` \
(`id` INT AUTO_INCREMENT, \
`sold` INT, \
PRIMARY KEY(`id`))";
my.Query(sql.c_str());
// 这里不能清空数据(因为我们模拟行锁,要运行两遍程序,两个程序共享这张表)
//my.Query("TRUNCATE `t_tickets`");
{
XDATA data;
data["sold"] = "0"; // 0是未售出
my.Insert(data, "t_tickets"); // id=1
// 取这张票,并且把这张票的标识添加进来
my.StartTransaction();
// 我们先看不锁的情况
XROWS rows = my.GetResult("select * from t_tickets where sold=0 order by id");
string id = rows[0][0].data;
cout << "Buy ticket id is " << id << endl;
// 模拟冲突(10秒钟之后我们更新这张票)
this_thread::sleep_for(10s);
data["sold"] = "1";
string where = "where id = ";
where += id;
cout << my.Update(data, "t_tickets", where) << endl;
cout << "Buy ticket id " << id << "success!" << endl;
//my.GetResult("select * from t_tickets where sold=0 for updata");
my.Commit();
my.StopTransaction();
}
cout << endl;
// 清理资源
my.Close();
cout << "test_ZPMysql!" << endl;
getchar();

我们可以看到,两个人买同一张票都成功了!这就很有问题了,而且第二个人执行Update修改票的状态的时候是失败的(Update输出是0)。


我们可以看到第二个人阻塞在那里,就在那里等着,无法查询。

第一个人购买2号票成功后,第二个人查询的票号是3,第二个人购票成功。
这样的话就使得两者不冲突(判断资源和申请资源不冲突),我们就做了这样一个行锁,锁住这张票,
第七章 日志审计系统项目实战和课程总结
日志审计系统项目模块分析




日志审计系统Agent模块项目
// agent makefile
agent:agent.cpp XAgent.cpp XAgent.h
g++ $^ -o $@ -I ../ZPMysql -lZPMysql
./$@ 127.0.0.1
// ZPMysql makefile
all:libZPMysql.so test_ZPMysql install
#./test_ZPMysql
libZPMysql.so:ZPData.cpp ZPMysql.cpp ZPData.h ZPMysql.h
g++ -fPIC -shared $^ -o $@ -I/usr/include/mysql/ -lmysqlclient
test_ZPMysql:../test_ZPMysql/test_ZPMysql.cpp
g++ $^ -o $@ -I./ -lZPMysql -L./
install:
cp libZPMysql.so /usr/lib/
@echo "install libZPMysql.so success!"
uninstall:
rm -rf /usr/lib/libZPMysql.so
@echo "uninstall libZPMysql.so success!"
clean:
rm -rf *.o *.so test_ZPMysql
rm -rf /usr/lib/libZPMysql.so
@echo "clear project success!"
日志审计系统Center模块项目
Center模块安装配置和数据初始化
// center makefile
center:center.cpp XCenter.cpp XCenter.h
g++ $^ -o $@ -I ../ZPMysql -lZPMysql
./$@ install 127.0.0.1
clean:
rm -rf *.o
rm -rf center
在linux下用makefile的时候,如果你的程序某个函数返回-1的话,make就会认为你的程序出错了,makefile可能会停止,所以我们这里测试的时候还是返回0吧。
Center审计策略表安装和策略添加

完成Center的添加设备
// center makefile
center:center.cpp XCenter.cpp XCenter.h
g++ $^ -o $@ -I ../ZPMysql -lZPMysql
./$@ install 127.0.0.1
./$@ add 192.168.0.202 fileserver1
./$@ add 192.168.0.201 fileserver2
clean:
rm -rf *.o
rm -rf center
Center主循环获取到Agent发送的最新事件
// center makefile
center:center.cpp XCenter.cpp XCenter.h
g++ $^ -o $@ -I ../ZPMysql -lZPMysql
#./$@ install 127.0.0.1
#./$@ add 192.168.0.202 fileserver1
#./$@ add 192.168.0.201 fileserver2
./$@
clean:
rm -rf *.o
rm -rf center