字节跳动大数据架构面经(超详细答案总结)
字节一面
1 面试官:简单的做个自我介绍吧
面试官,您好!我叫 xxx , xxxx 年 x 月毕业于 xxx 学校,xx 学历,目前就职于 xxx 公司 xxx 部门,职位为:大数据开发工程师,主要从事于 xxx 组件、平台的开发工作。
工作以来,我先后参加了 xxx 项目、xxx 项目以及 xxx 项目,积累了丰富的项目经验,同时,这 x 个项目都得到了领导的一致好评。
我对 Flink 组件有着浓厚的兴趣,工作之余经常钻研技术、例如:Flink 四大基石、Flink 内核应用提交流程、Flink 调度策略等。
入职 x 年,曾荣获优秀员工,以上是我的自我介绍,请面试官提问。
2 面试官:介绍一下你最拿手的项目
好的,那我重点介绍一下 流计算平台。该平台对标 阿里云的实时计算 Flink,是一个 一站式、高性能的大数据计算、分析平台,底层基于 Flink 实现,平台提供多种核心功能,支持多种 source、sink 插件,内置统一的元数据管理,支持 一键提交、应用管理、断点调试、监控告警、Ranger 鉴权等多个核心模块。
我主要负责对该平台的 Flink 版本升级、从原先的 Flink 1.11.0 升级到 1.14.0,同时对平台进行架构重构及代码优化,并参与核心模块应用管理、Ranger 鉴权模块的开发工作。
主要解决了多部门提交 Flink 任务需要大量开关配置问题, 版本升级后的 SQL 语法校验、应用提交报错问题,以及 Ranger 鉴权问题。
3 面试官:ranger 鉴权能介绍一下吗?是对哪方面进行鉴权?
Ranger 鉴权是对表级别的读写进行鉴权。
通过 Flink sql 调用 parser 解析后获得 operation ,然后判断 operation 的表类型是 DDL\DML\DQL 的哪种,通过自研的 flink-ranger 插件获取 operation,从 operation 提取关键信息,组成 ranger 格式的约定进行鉴权,如果鉴权成功,就根据 Flink 原生的执行逻辑,继续往下执行,反之报出鉴权异常。
4 为什么要用 Flink sql 鉴权,而不用 Hive sql 鉴权或者 HDFS 本身的鉴权?
首先该流计算平台底层基于 Flink 实现,在鉴权方面,由于编写的 SQL 在提交过程中需要走 Flink SQL 提交流程,所以在鉴权时直接通过 SQL 解析,校验 拿到 对应的 operation 类型,同时为了和流计算平台更适配,满足更多业务场景需求,才最终选用 Flink SQL 鉴权,其实用 Hive SQL 也是可以鉴权的。
5 面试官:Flink sql operation 之前的解析流程清楚吗?可以详细介绍一下
如下图所示:
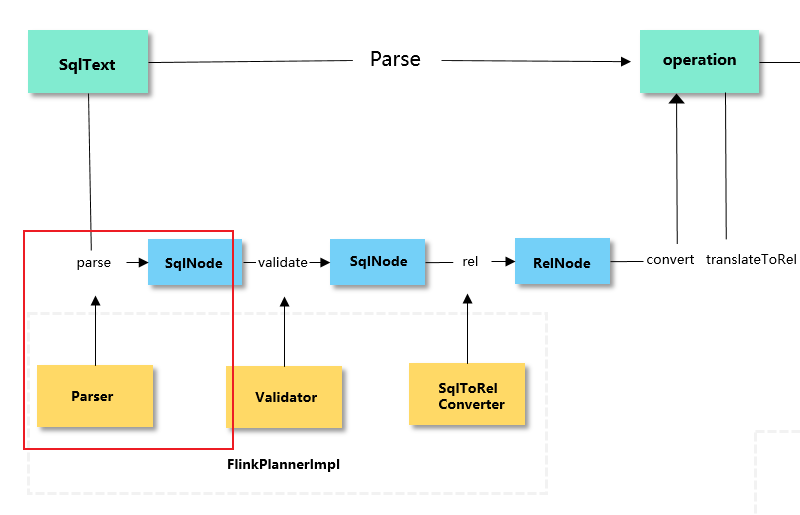
Flink sql 调用 parser() 方法,将 sqlText 转为 Flink 内部的 operation。在这其中主要经历了4大步骤。
(1) 调用 parse() 方法,将 sql 转为 未经校验的 AST 抽象语法树(sqlNode) ,在解析阶段主要用到词法解析和语法解析。
词法解析将 sql 语句转为一组 token,语法解析对 token 进行递归下降语法分析。
(2)调用 validate() 方法,将 AST 抽象语法树转为经过校验的抽象语法树(SqlNode).在校验阶段主要校验 两部分:
-
校验表名、字段名、函数名是否正确,
-
校验特殊的类型是否正确,如 join 操作、groupby 是否有嵌套等。
(3)调用 rel() 方法,将 抽象语法树 SqlNode 转为 关系代数树 RelNode(关系表达式) 和 RexNode(行表达式) ,在这个步骤中,DDL 不执行 rel 方法,因为 DDL 实际是对元数据的修改,不涉及复杂查询。
(4)调用 convert()方法,将 RelNode 转为 operation ,operation 包含多种类型,但最终都会生成根节点 ModifyOperation。
6 面试官:那在 operation 之后又做了哪些操作?
如下图所示:
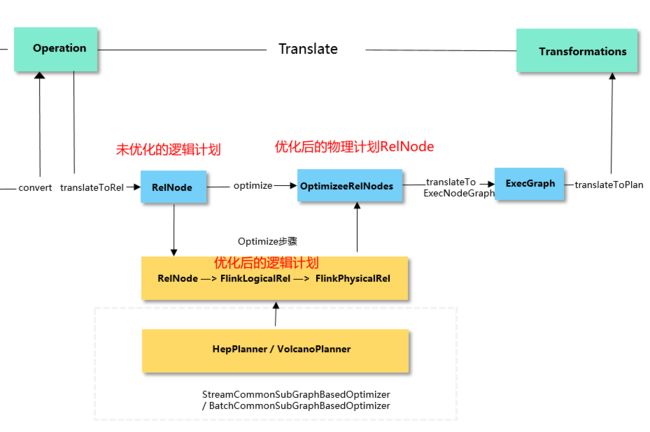
在 Flink 内部的 operation 之后,会调用 translate 方法将 operation 转为 transformation。在这中间也经历了四大步骤:
(1) 调用 translateToRel() 方法 先将 ModifyOperation 转换成 Calcite RelNode 逻辑计划树,再对应转换成 FlinkLogicalRel( RelNode 逻辑计划树);
(2) 调用 optimize() 方法 将 FlinkLogicalRel 优化成 FlinkPhysicalRel。在这中间的优化规则包含 基于规则优化 RBO 和 基于代价优化 CBO 。
(3) 调用 TranslateToExecNodeGraph() 方法 将物理计划转为 execGraph。
(4) 调用 TranslateToPlan() 方法 将 execGraph 转为 transformation。
7 面试官:ROB 里面都了解哪些规则优化?
RBO 规则优化中 包含 谓词下推、Join 优化、列裁剪,分区裁剪等等。
8 面试官:分区裁剪主要解决什么问题?
分区剪裁就是对于分区表或者分区索引来说,优化器可以自动从 from 和 where 中根据分区键直接提取出需要访问的分区,从而避免扫描所有的分区,降低了 IO 请求。
分区剪裁可以细分为静态分区剪裁和动态分区剪裁,其中静态分区剪裁发生在 sql 语句编译阶段,而动态分区剪裁则发生在 sql 语句执行阶段,对于分区键是常量值优化器在会走静态分区剪裁的,如果分区键是变量形式优化器只会走动态分区剪裁。
9 面试官:那在 flink sql 中, join 都包含哪些类型?(引擎层的实现)
在 join 中 包含 Regular join、Interval join、Temporal join、 lookup join
Regular join 包含 left join、right join、 inner join、 full join
Interval join 时间区间 join, 表示两条流之间 一段时间的join.
10 面试官:Spark 3.0 优化特性了解不?
了解 Spark 3.0 AQE 自适应查询优化。
Spark3.0 AQE 自适应查询 里面包含 3 种优化,如 动态合并 shuffle 分区、动态调整 join 策略、动态优化数据倾斜 join 等.
(1) 动态合并 shuffle 分区
在 spark 中,shuffle 前后的分区不同,如果分区数太少,那么每个分区处理的数据大小可能非常大,导致大分区处理时需要落盘,查询效率太低,如果分区过多,导致每个分区处理数据较少,这也会导致 IO 请求增多降低查询效率。
动态合并 shuffle 的含义就是 当 map 端的两个分区 经过 shuffle 操作后,本来产生五个分区的,但因为有两个分区数据过小,所以直接对其进行合并,最终输出 3 个分区。
(2) 动态调整 join 策略。
总共包含 3 种 join 策略:broadcast hash join、hash join、sortmergejoin.
(3) 动态优化数据倾斜 join
11 面试官:假如两张表 join ,但目前达不到 Broadcast hash Join 的要求, Spark3.0 是怎么处理的可以让其达到要求?
在 Spark3.0 AQE 中通过动态调整 join 策略,其中 broadcast hash join 性能是最好的,前提是参加 join 的一张表的数据能够装入内存。由于这个原因,当 Spark 估计参加 join 的表数据量小于广播大小的阈值时,其会将 Join 策略调整为 broadcast hash join。
所以当 两张表 join 时,如果 A 表的数据量大于 广播大小的阈值,此时不能选择 broadcast hash join ,但恰好可以通过 filter 条件 将 A 表无用数据过滤掉,且 B 表不包含 无用数据,这时候 过滤掉后的 A 表数据量小于 广播大小的阈值,此时就可以选择 broadcast hash join。
12 面试官:checkpoint 失败有遇到过吗,什么原因导致的?
有遇到过,checkpoint 失败一般都和反压相结合。导致 checkpoint 失败的原因有两个:
1. 数据流动缓慢,checckpoint 执行时间过长。
我们知道, Flink checkpoint 机制是基于 barrier 的, 在数据处理过程中, barrier 也需要像普通数据一样,在 buffer 中排队,等待被处理。当 buffer 较大或者数据处理较慢时,barrier 需要很久才能够到达算子,触发 checkpoint。尤其是当存在反压时,barrier 需要在 buffer 中流动数个小时,从而导致 checkpoint 执行时间过长,超过了 timeout 还没有完成,从而导致失败。
当算子需要 barrier 对齐时,如果一个输入的 barrier 已经到达,那么该输入的 barrier 后面的数据会被阻塞住,不能被处理,需要等到其他输入 barrier 到达之后,才能继续处理。在 barrier 对齐过程中,其他输入数据处理都要暂停,将严重导致应用实时性,从而让 checkpoint 执行时间过长,超过了 timeout 还没有完成, 导致执行失败。
2. 状态数据过大。
当状态数据过大,会影响每次 checkpoint 的时间,并且在 chackpoint 时 IO 压力也会很大,执行时间过长,导致超时还没有执行成功,从而导致执行失败。
13 面试官:怎么解决的上述问题?
对于数据流动缓慢 解决思路是:
-
让 buffer 中的数据变少
-
让 barrier 能跳过 buffer 中存储的数据。
这对应社区提出的 FLIP-183 Dynamic buffer size adjustment ,其解决思路是只缓存配置时间内可以处理的数据量,这可以很好的控制 checkpoint。
对于 barrier 对齐问题。社区提出 FLIP-76 Unaligned Checkpoint。其解决思路是 对于实时性要求很好,但数据重复性要求低的,可采用 barrier 不对齐模式,当还有其他流的 barrier 还没到达时,为了不影响性能,不用理会,直接处理 barrier 之后的数据。等到所有流的 barrier 的都到达后,就可以对该 Operator 做 CheckPoint 了。
对于 状态数据过大问题:
FLIP-158 提出通用的增量快照方案,其核心思想是基于 state changelog, changelog 能够细粒度地记录状态数据的变化。具体描述如下:
-
有状态算子除了将状态变化写入状态后端外,再写一份到预写日志中。
-
预写日志上传到持久化存储后,operator 确认 checkpoint 完成。
-
独立于 checkpoint 之外,state table 周期性上传,这些上传到持久存储中的数据被成为物化状态。
-
state stable 上传后,之前部分预写日志就没用了,可以被裁剪。
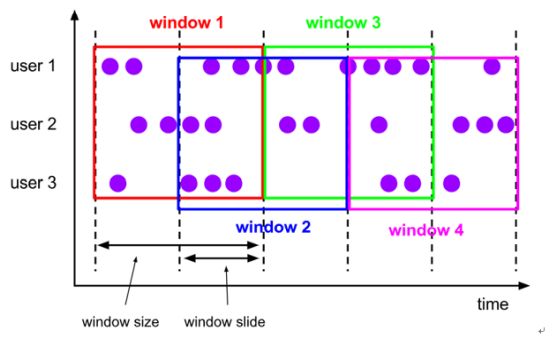
14 面试官:滑动窗口有啥特点?
Flink 支持的窗口包含两个重要属性(窗口长度 size 和滑动间隔 interval),通过窗口长度和滑动间隔来区分滚动窗口和滑动窗口。
滑动窗口(Sliding window ) 数据有重叠,即 size(1min)>interval(30s)
timeWindow(Time.seconds(10), Time.seconds(5))---基于时间的滑动窗口
countWindow(10,5)---基于数量的滑动窗口
算法题
15 面试官:我们写两道算法吧,先看看第一道
给定一个有序数组,前 n 位往后移,例如{1,2,3,4,5}->{3,4,5,1,2},求其中的最小值
该题其实就是让你用最优解找一个数组中的最小值, 可以使用二分查找法.
时间复杂度 O(log n),空间复杂度O(1)
public class Main {
public static void main(String[] args) {
int[] nums = {4,5,6,7,1,2,3};
System.out.println(test(nums));
}
public static int test(int[] nums){
int low = 0;
int high = nums.length-1;
while (low16 面试官:LRU 算法,先说一下原理,然后介绍一下实现思路
LRU 被称作最近最少使用算法,是一种页面置换算法。其核心思想是将最近最久未使用的页面予以淘汰。就是一种缓存淘汰算法。
实现思路:
LRU 缓存机制可以通过哈希表 + 双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。
双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
哈希表即为普通的哈希映射(HashMap),通过缓存数据的键映射到其在双向链表中的位置。
这样以来,我们首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在 O(1) 的时间内完成 get 或者 put 操作。
public class LRUCache {
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {}
public DLinkedNode(int _key, int _value) {key = _key; value = _value;}
}
private Map cache = new HashMap();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
}
时间复杂度 O(1)
空间复杂度 O(capacity)
最后免费分享给大家一份Python全套学习资料,包含视频、源码,课件,希望能帮到那些不满现状,想提升自己却又没有方向的朋友。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具
三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。 

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。 
五、Python练习题
检查学习结果。 
六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。 

这份完整版的Python全套学习资料已经打包好,需要的小伙伴可以戳下方链接免费领取
