从集群数据库到oceanBase架构的演变
因为项目需求,用到了oceanBase数据库,特此一篇文章讲解数据库的演变史
1.集群数据库
商业关系数据库的架构早期都是集中式的,只有主备架构应对高可用和容灾。后来为了应对性能增长,发展出集群数据库。
主备架构
主备架构不是主从架构,只有主库提供读写服务,备库冗余作故障转移用
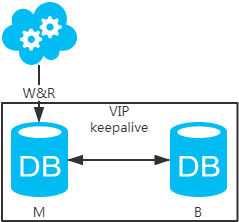
集群数据库
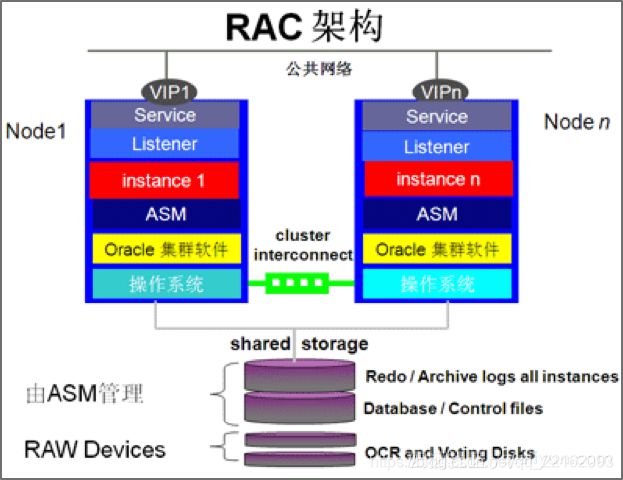
集群数据库的架构是将实例和数据文件分离,数据文件放在一个共享存储上,实例节点水平扩展为多个,彼此共享同一份数据文件。
实例节点是分布式的,在每个实例节点上,配置一个数据库监听服务监听多个VIP(本地的和远程的),监听服务彼此也是一个小集群,会根据各个实例节点负载信息决定将请求转发到何处。当新增实例节点时,会对各个实例节点的请求重新做负载均衡,平衡压力。
集群数据库的问题也是很明显的,就是数据存储不是分布式的。一旦共享存储发生故障,整个数据库集群都不可用。所以这个分布式架构并不完美
2.分布式数据库中间件
随着中间件技术的发展,出现了一类分布式MySQL集群。其原理是将数据水平拆分到多个MySQL实例里,然后在MySQL前端部署一组中间件集群负责响应客户端SQL请求。这个中间件具备解析SQL,路由和数据汇聚计算等逻辑,是分布式的,无状态的。在中间件前端会通过一个负载均衡产品(如SLB或LVS等类似产品)接受客户端请求并分发到各个中间件节点上。
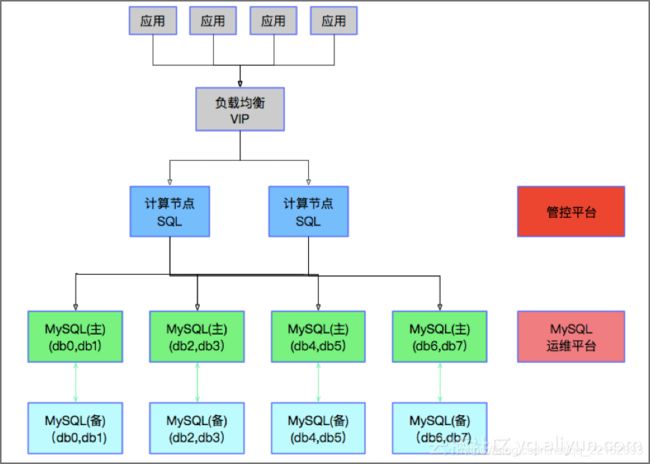
这个是通过分布式数据库中间件去弥补传统集中式数据库的分布式缺陷。它将计算节点做到分布式,可以水平扩展;同时将数据也水平拆分到多个存储上,也实现了分布式。相比集群数据库架构,分布式数据库中间件能提供更高的性能,更好的扩展性,同时成本也更低。
这个分布式架构下,计算节点因为是无状态的,扩展很容易。数据节点就没那么容易。因为涉及到数据的重分布,需要新增实例,以及做数据迁移和拆分动作(分库分表)。这些必须借助数据库外部的工具实现。这种分布式依然不是最完美的。因为它的数据存储是静止的。
分布式数据库的负载均衡设计
Google发布了关于Spanner&F1产品架构和运维的论文,引领了NewSQL技术的发展,具体就是分布式数据库技术。这个是真正的分布式数据库架构。在这种架构下,数据是分片存储在多个节点,并且可以在多个节点之间不借助外部工具自由迁移。
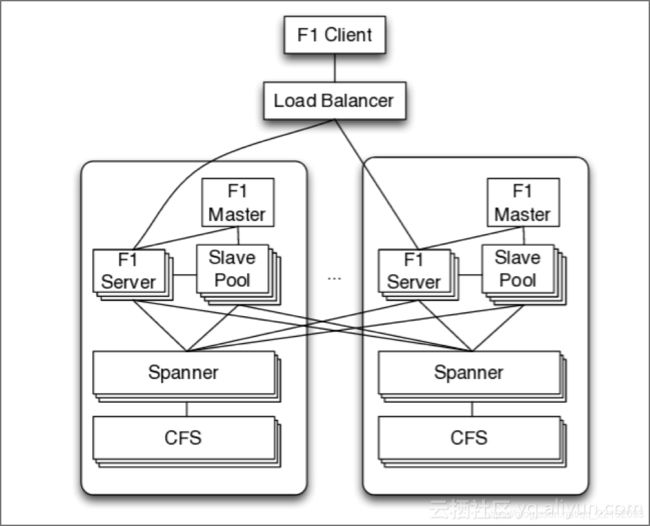
F1是Google开发的分布式关系型数据库,主要服务于Google的广告系统。Google的广告系统以前使用MySQL,广告系统的用户经常需要使用复杂的query和join操作,这就需要设计shard规则时格外注意,尽量将相关数据shard到同一台MySQL上。扩容时对数据reshard时也需要尽量保证这一点,广告系统扩容比较艰难。在可用性方面老的广告系统做的也不够,尤其是整个数据中心挂掉的情况,部分服务将不可用或者丢数据。对于广告系统来说,短暂的宕机服务不可用将带来重大的损失。为了解决扩容/高可用的问题,Google研发了F1,一个基于Spanner的跨数据中心的分布式关系型数据库,支持ACID,支持全局索引。
Spanner数据库
Spanner满足了external consistency:即后开始的事务一定可以看到先提交的事务的修改。所有事务的读写都加锁可以解决这个问题,缺点是性能较差。特别是对于一些workload中只读事务占比较大的系统来说不可接受。为了让只读事务不加任何锁,需要引入多版本。
在单机系统中,维护一个递增的时间戳作为版本号很好办。分布式系统中,机器和机器之间的时钟有误差,并且误差范围不确定,带来的问题就是很难判断事件发生的前后关系。反应在Spanner中,就是很难给事务赋予一个时间戳作为版本号,以满足external consistency。在这样一个误差范围不确定的分布式系统时,通常,获得两个事件发生的先后关系主要通过在节点之间进行通信分析其中的因果关系(casual relationship),经典算法包括Lamport时钟等算法。然而,Spanner采用不同的思路,通过在数据中心配备原子钟和GPS接收器来解决这个误差范围不确定的问题,进而解决分布式事务时序这个问题。基于此,Spanner提供了TrueTime API,返回值实际为一个区间[t-ε,t+ε],ε为时间误差,毫秒级,保证当前的真实时间位于这个区间。
Spanner是一个支持分布式读写事务,只读事务的分布式存储系统,只读事务不加任何锁。和其他分布式存储系统一样,通过维护多副本来提高系统的可用性。一份数据的多个副本组成一个paxos group,通过paxos协议维护副本之间的一致性。对于涉及到跨机的分布式事务,涉及到的每个paxos group中都会选出一个leader,来参与分布式事务的协调。这些个leader又会选出一个大leader,称为coordinator leader,作为两阶段提交的coordinator,记作coordinator leader。其他leader作为participant。
数据库事务系统的核心挑战之一是并发控制协议。Spanner的读写事务使用两阶段锁来处理。详细流程下图所示。
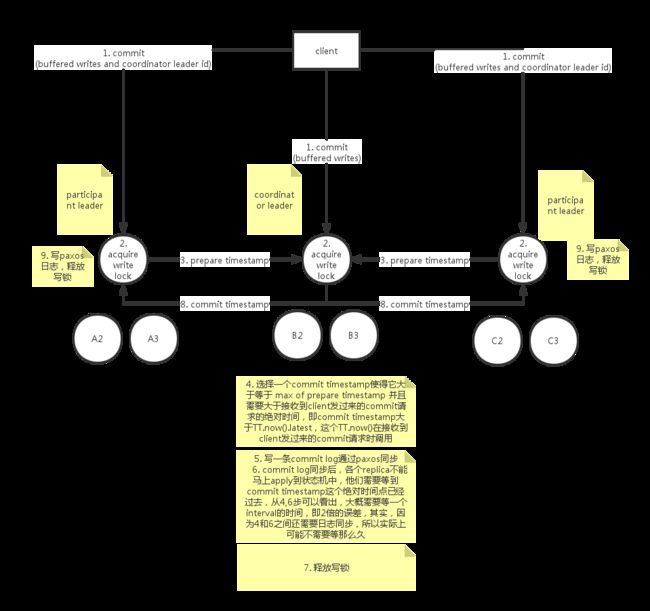
关于更多spanner的请看这篇博客,不再赘述分布式事务实现-Spanner
F1的几个特性
1、高可用
可以说,几乎都是Spanner搞定的,Spanner通过原子钟和GPS接收器实现的TrueTime API搞定了跨数据中心时钟误差问题,进而搞定了分布式事务的时序问题,从而搞定了对外部的一致性。多个副本的一致通过Paxos搞定。
2、全局索引
基于Spanner提供的分布式读写事务(严格的两阶段锁+两阶段提交),F1实现了全局索引。索引表和数据表实际上是两张表,这两张表一般来说存在不同的Spanner机器上,两张表的一致性通过Spanner的分布式读写事务解决。在这里,同一个事务中涉及的全局索引不宜过多,因为每多一个全局索引,相当于多一个两阶段提交中的participant,对于分布式事务来说,participant越多,性能越差,并且事务成功的概率越小。
3、级联Schema
思想和MegaStore类似,表和表之间有层次关系。将相关表中的相关数据存储在一台机器上。比如对于广告系统来说,就是将一个广告客户以及他的compaign等存储在一起,广告客户作为一张表,compaign作为另外一张表,广告客户表中每行代表一个广告客户,广告客户表叫做root表,compaign表叫做子表,广告客户表中的每行叫做root记录,compaign表中行叫做子记录,那么同一个广告客户下所有的compaign和这个广告客户都存储在同一台Spanner机器上。这样做的好处就是一个操作就可以取到所有的相关数据,join很快,不用跨机。
4、三种事务
快照读。 直接利用Spanner提供的快照读事务
悲观事务。 直接利用Spanner提供的读写事务,加两阶段锁
乐观事务。 基于Spanner的悲观事务实现的。这样的事务分为两个阶段,第一个阶段是读阶段,持续时间不限,不加任何锁,第二个阶段是写阶段,即commit事务阶段。基本思想是在读阶段将访问的所有行的最后一次修改时间保存在F1客户端,写阶段将所有的时间发到F1,F1开启一个Spanner的读写事务,这个读写事务会重新读取这些行的最后一次修改时间进行check,如果已经变了,说明检测到了写写冲突,事务abort。
F1默认使用乐观事务,主要考虑了如下几个方面:
(1)、由于读阶段不加锁,能容忍一些客户端的误用导致的错误
(2)、同样,读阶段不加锁,适合F1中一些需要和终端交互的场景。
(3)、对于一些出错场景,可以直接在F1 Server进行重试,不需要F1 Client参与。
由于所有的状态都在F1 Client端维护的,故某个F1 Server挂掉后,这个请求可以发给 其他的F1 Server继续处理。
当然,这会带来两个问题:
对于不存在的行,没有最后一次修改时间,那么在其他读事务执行期间,同一条语句执行多次返回的行数可能不一样,这种情况在repeatable read这种隔离级别下是不允许的,这个问题典型的解决方案是gap锁,即范围锁,在F1中,这个锁可以是root表中root记录的一列,这个列代表一把gap锁,只有拿到这把锁,才能往child表中某个范围插入行。
对同一行高并发修改性能低。显然,乐观协议不适合这种场景。
OceanBase 架构
在看OceanBase的负载均衡设计之前,先看看OceanBase 1.0版本的架构。在1.x版本里,一个observer进程囊括了计算和存储两项功能。每个节点之间地位都是平等的(有总控服务rootservice的三个节点稍有特殊),每个zone里每个节点的数据都是全部数据的一部分,每份数据在其他几个zone里也存在,通常至少有三份。所以从架构图上看OceanBase的计算和存储都是分布式的。跟Google的区别是1.x版本里,计算和存储还没有分离。但不影响作为分布式数据库的功能。
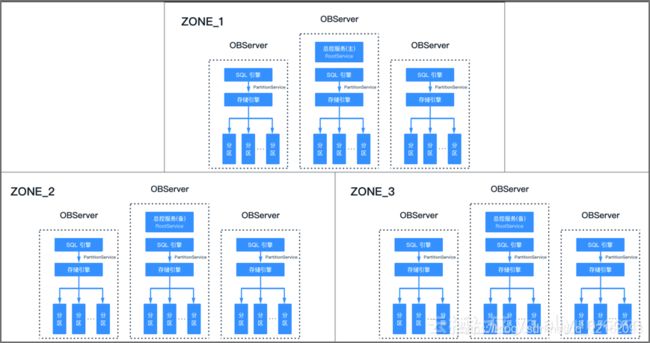
分区、副本和OBProxy
OceanBase的数据分布的最小粒度是分区(Partition),分区就是分区表的一个分区或者二级分区,或者非分区表本身就是一个分区。OceanBase的负载均衡的原理就跟分区有关。每个分区(Partition)在整个集群里数据会至少有三份,即通常说的三副本(Replica)。三副本角色为1个leader副本2个follower副本。通常默认读写的是leader副本。leader副本的默认分布在哪个机房(zone),受表的默认primary zone属性和locality属性影响。在异地多活架构里,充分发挥了这个locality属性的作用。
由于Leader副本分布位置是OceanBase内部信息,对客户端是透明的,所以需要一个反向代理OBProxy给客户端请求用。这个OBProxy只有路由的功能,它只会把sql请求发到一个表的leader副本所在的节点。跟HAProxy不同,它没有负载均衡功能,也不需要。不过OBProxy是无状态的,可以部署多个,然后在前面再加一个负载均衡产品,用于OBProxy自身的负载均衡和高可用。

3. 负载均衡的衡量标准
OceanBase的各个节点(OBServer)的地位都是平等的(总控服务rootservice所在的节点作用稍微特殊一些),当前版本每个OBServer还是集计算与存储能力于一个进程中(2.x后期版本会发布计算与存储分离)。OceanBase会维持每个节点的资源利用率和负载尽可能的均衡。这个效果就是当一个大的OceanBase集群里,有若干个资源规格大小不等的租户运行时,OceanBase会避免某些节点资源利用率很高而某些节点上却没有访问或者资源利用率很低等。这个衡量标准比较复杂,还在不断探索完善中。所以目前没有确定的直白的公式可以直接描述。但可以介绍一下会跟下列因素有关:
1、空间:每个节点上Partition总的使用空间以及占用其配额的比例;每个租户的Unit在该节点上的总空间以及占用其配额的比例
2、内存:每个节点的OB的内存里已分配的内存以及占用其配额的比例
3、CPU:每个节点里的Unit的已分配的CPU总额以及占用其总配额的比例
4、其他:最大连接数、IOPS等。目前定义了这些规格,但还没有用于均衡策略
5、分区组个数(PartitionGroup):每个节点里的分区组个数。同一个表分组的同号分区是一个分区组。如A表和B表都是分区表,分区方法一样,则它们的0号分区是一个分区组,1号分区是一个分区组。如此类推。
4.负载均衡逻辑演进
OceanBase负载均衡的原理就是通过内部调整各个observer节点里的leader副本数量来间接改变各个节点的请求量,从而改变节点里某些用于负载均衡衡量标准的值。调整过程中的数据迁移是内部自动做的,不依赖外部工具,不需要DBA介入,对业务影响可以控制。
在分布式下,跨节点请求延时对性能会有损耗。尤其是当集群是跨多个机房部署的时候。所以,不受控制的负载均衡对业务来说并不是好事。在业务层面,有些表之间是有业务联系的,在读取的时候,相应的Partition最好是在一个节点内部。此外,加上OceanBase的架构还支持多租户特性。不同租户下的数据存储是会在一个或多个Unit里分配。Partition并不是毫无规则的自由分布。对业务来说,能对负载均衡策略进行控制是很有意义的。它方便了应用整体架构设计时能保持上层应用流量分发规则和底层数据拆分规则保持一致,这是做异地多活的前提,同时也定义了负载均衡能力的边界。
所以,Partition的分布实际还受几点规则限制。第一,每个租户下的所有Partition都在一组或多组Unit里。Partition的迁移不能跳出Unit的范围。一个OceanBase集群里有很多租户,也就有很多Unit。OceanBase首先会调整Unit在节点间的分布。这个称为“Unit均衡”。只是Unit的迁移具体过程还是逐个Partition进行迁移。第二,同一个分区组的分区必须在同一个节点里。分区的迁移的终态是同一个PartitionGroup的Partition必须在同一个OBServer节点里。
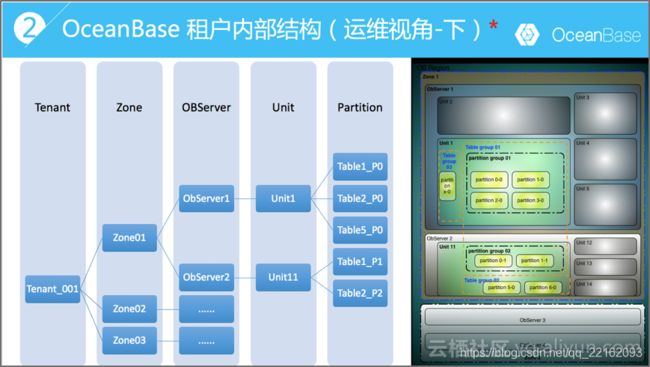
由前面知负载均衡策略其实就是对Partition的行为添加规则,设置边界。随着业务规模的增大,业务会把整体数据按模块拆分到多个租户里。所以就存在有些租户之间的数据在业务层面是有关联关系的。这就是租户组的概念(TenantGroup)。在负载均衡的时候会考虑同一个TenantGroup的租户下的Unit里的Partition会分配在同一个节点上。这样做的目的是为了避免应用一个业务逻辑多次数据库调用出现跨机房。
最后总结一下,OceanBase的多种负载均衡策略的目标就是既尽可能的做到资源利用率均衡,又将其对性能的影响控制在一定的范围。随着业务规模的扩大和使用的深入,负载均衡策略和规则还会进一步完善。
5. 负载均衡的风险和实践
负载均衡的效果在不同的业务场景下可能不完全一致。还需要具体问题具体分析。
如果集群结构频繁变动,比如说经常性的有机器变更和增减等,或者有租户的新增和删减,可能会导致频繁的负载均衡操作。这个内部数据迁移过程会占用节点一定的CPU和IO资源。某些对数据库性能非常敏感的业务可能会受影响。所以需要运维人员适当的运用负载均衡的一些硬性规则限制等。如设置租户、表的locality属性,将leader分区限制在某几个可以接受的zone内。又如对相关业务联系紧密的表设置相同的表分组进行约束等。如果采取这些措施还是经常发现有均衡操作带来影响时,还可以关闭自动负载均衡操作。所有Unit和Partition的分配可以通过命令具体指定,即手动均衡。
6.计算与存储分离
在2.x 版本里,OceanBase将实现一个分布式存储,从而实现计算和存储分离架构。此时计算节点弹性伸缩时通过迁移Partition实现负载均衡,存储节点弹性伸缩通过迁移Block数据实现分布均衡。同样所有操作都是后台异步的,不借助于外部同步工具,不需要运维人员介入,不影响现有高可用,对性能影响可控。
OceanBase的数据可靠性
在传统数据库中,有以下几种常用的手段来保证数据可靠性:
1) Redo Log;2) 主从热备;3) 备份/恢复;4) 存储层数据校验
这些技术从很大程度上提高数据的可靠性,但似乎都无法做到完美(即RPO=0)。OceanBase分布式数据库更多的是在软件层面引入保障机制,OceanBase充分利用了Paxos协议,并将Paxos协议和传统的WAL机制结合起来,每一次Redo Log落盘时,都会以强一致方式同步到Paxos组中多数派(leader+若干follower)副本的磁盘中,这样做有两个好处:
1)在Paxos组中任意少数派副本发生故障的情况下,剩下的多数派副本都能保证有最新的Redo Log,因此就能避免个别硬件故障带来的数据损失,保证RPO=0。
2)Paxos协议中的数据强一致是针对“多数派”副本而言,如果Paxos组中有少数派follower副本发生故障,剩下的多数派副本(leader+若干follower)之间的数据强一致完全不受影响,这就解决了主从热备模式下备副本故障拖累主副本的可用性。
综合以上两点,OceanBase利用Paxos协议可以保证RPO=0,且不必担心应用的性能会受到影响,这也是OceanBase和传统数据库在数据可靠性方面最显著的不同点。
OceanBase除了在存储层引入了数据校验机制,还加入了更多的技术手段来预防或者解决错误,大致包含以下内容:
1)Redo Log的数据校验:Redo Log在落盘的时候会加上数据校验信息,用来应对可能发生的磁盘静默错误。此外,为了保证一个Paxos组中多个副本之间Redo Log的一致性,Redo Log在leader发送和follower接受时都会检查数据校验信息,避免网络传输问题导致的数据错误。
2)数据盘上的校验信息:和Redo Log类似,数据盘上的数据也会有校验信息以应对磁盘静默错误。但由于OceanBase是通过Redo Log实现Paxos组中多个副本之间的数据同步,数据盘上的数据并不会通过网络传输在多个副本间同步,因此不需要副本间的实时校验。
3)副本间的检查点一致性校验:OceanBase会在一些特定的检查点,对多个副本之间的数据盘做一致性检查。这个检查点选在了OceanBase的“每日合并”点,主要的原因是每日合并动作本身就要对大量数据做归并和重新写入,刚好可以利用这个时机做数据的一致性检查。通过这个检查,进一步在存储层确保了多个副本之间的数据一致性,提高了数据可靠性。
4)数据表和索引表之间的数据一致性校验:对于有关联关系的数据对象,OceanBase会做额外的检查以保证它们之间的数据一致性。比较典型的例子就是索引和它的数据表,OceanBase会在一些特定的检查点(如每日合并点)做索引和数据表之间的一致性检查,进一步提高数据可靠性。
5)定期做数据校验信息检查:OceanBase定期检查任务,在不影响在线业务的前提下,利用数据校验信息主动检查磁盘静默错误,一旦发现错误会及时通知用户,尽快采取补救措施。
最后,OceanBase也和传统数据库一样提供完善的备份/恢复机制,包括全量备份功能和增量备份功能。而且OceanBase的增量备份是以不间断的后台daemon任务形式持续进行,完全不影响在线业务,降低了运维操作的复杂度。不过从分布式数据库的运行实践来看,在实际系统中极少发生Paxos组中多数派副本同时毁坏的情况,因此基本不会真正用到备份来恢复数据。
oceanBase全局数据一致性
什么是“全局一致性快照”?它在OceanBase数据库里起什么作用?为什么OceanBase数据库要在2.0版本中引入这个东西?
实际上,故事起源于数据库中的两个传统概念:“快照隔离级别(Snapshot Isolation)”和“多版本并发控制(Multi-VersionConcurrency Control,简称MVCC)”。这两种技术的大致含义是:为数据库中的数据维护多个版本号(即多个快照),当数据被修改的时候,可以利用不同的版本号区分出正在被修改的内容和修改之前的内容,以此实现对同一份数据的多个版本做并发访问,避免了经典实现中“锁”机制引发的读写冲突问题。
因此,这两种技术被很多数据库产品(如Oracle、SQL Server、MySQL、PostgreSQL)所采用,而OceanBase数据库也同样采用了这两种技术以提高并发场景下的执行效率。但和传统的数据库的单点全共享(即Shared-Everything)架构不同,OceanBase是一个原生的分布式架构,采用了多点无共享(即Shared-Nothing)的架构,在实现全局(跨机器)一致的快照隔离级别和多版本并发控制时会面临分布式架构所带来的技术挑战(后文会有详述)。
为了应对这些挑战,OceanBase数据库在2.0版本中引入了“全局一致性快照”技术。接下来介绍和OceanBase“全局一致性快照”技术相关的概念以及基本实现原理。
首先,我们来看一下传统数据库中是如何实现“快照隔离级别”和“多版本并发控制”的。
以经典的Oracle数据库为例,当数据的更改在数据库中被提交的时候,Oracle会为它分配一个“System Change Number(SCN)”作为版本号。SCN是一个和系统时钟强相关的值,可以简单理解为等同于系统时间戳,不同的SCN代表了数据在不同时间点的“已提交版本(Committed Version)”,由此实现了数据的快照隔离级别。
假设一条记录最初插入时对应的版本号为SCN0,当事务T1正在更改此记录但还未提交的时候(注意:此时T1对应的SCN1尚未生成,需要等到T1的commit阶段),Oracle会将数据更改之前的已提交版本SCN0放到“回滚段(Undo Segments)”中保存起来,此时如果有另外一个并发事务T2要读取这条记录,Oracle会根据当前系统时间戳分配一个SCN2给T2,并按照两个条件去寻找数据:
1)必须是已提交(Committed)的数据;
2)数据的已提交版本(Committed Version)是小于等于SCN2的最大值。
根据上面的条件,事务T2会从回滚段中获取到SCN0版本所对应的数据,并不理会正在同一条记录上进行修改的事务T1。利用这种方法,既避免了“脏读(Dirty Read)”的发生,也不会导致并发的读/写操作之间产生锁冲突,实现了数据的多版本并发控制。整个过程如下图所示:
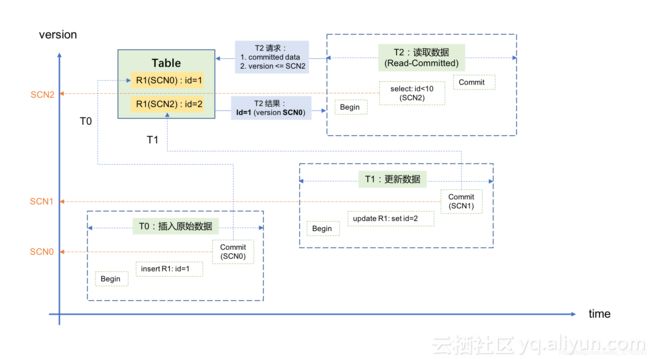
关于“快照隔离级别”和“多版本并发控制”,不同数据库产品的实现机制会有差异,但大多遵循以下原则:
1、每次数据的更改被提交时,都会为数据分配一个新的版本号。
2、版本号的变化必须保证“单调向前”。
3、版本号取自系统时钟里的当前时间戳,或者是一个和当前时间戳强相关的值。
4、查询数据时,也需要一个最新版本号(同理,为当前时间戳或者和当前时间戳强相关的值),并查找小于等于这个版本号的最近已提交数据。
分布式数据库面临的挑战
前面关于“多版本并发控制”的描述看上去很完美,但是这里面却有一个隐含的前提条件:数据库中版本号的变化顺序必须和真实世界中事务发生的时间顺序保持一致,即:
— 真实世界中较早发生的事务必然获取更小(或者相等)的版本号;
— 真实世界中较晚发生的事务必然获取更大(或者相等)的版本号。
如果不能满足这个一致性,会导致什么结果呢?以下面的场景为例:
1)记录R1首先在事务T1里被插入并提交,对应的SCN1是10010;
2)随后,记录R2在事务T2里被插入并提交,对应的SCN2是10030;
3)随后,事务T3要读取这两条数据,它获取的SCN3为10020,因此它只获取到记录R1(SCN1SCN3,不满足条件)。示意图如下:
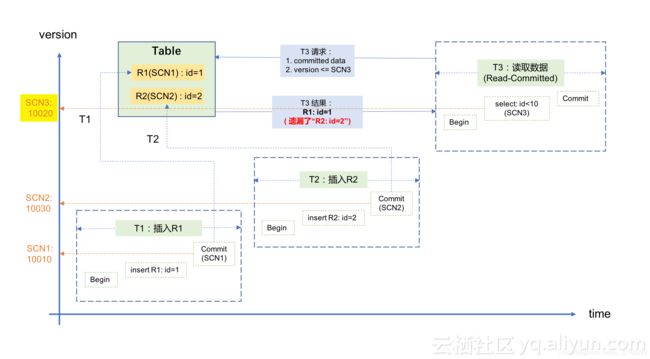
这对应用来说就是一个逻辑错误:我明明向数据库中插入了两条记录并且都提成功提交了,但却只能读到其中的一条记录。导致这个问题的原因,就是这个场景违反了上面所说的一致性,即SCN(版本号)的变化顺序没有和真实世界中事务发生的时间顺序保持一致。
其实,违反了这种一致性还可能引发更极端的情况,考虑下面的场景:
1)记录R1首先在事务T1里被插入并提交,对应的SCN1是10030;
2)随后,记录R2在事务T2里被插入并提交,对应的SCN2是10010;
3)随后,事务T3要读取这两条数据,它获取的SCN3为10020,因此它只能获取到记录R2(SCN2SCN3,不满足条件)。示意图如下:
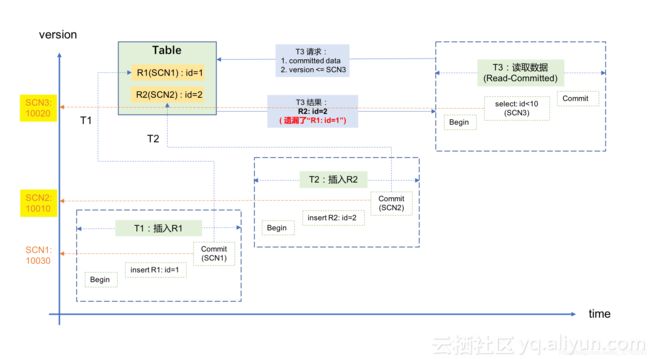
对于应用来说,这种结果从逻辑上讲更加难以理解:先插入的数据查不到,后插入的数据反而能查到,完全不合理。
有的朋友可能会说:上面这些情况在实际中是不会发生的,因为系统时间戳永远是单调向前的,因此真实世界中先提交的事务一定有更小的版本号。是的,对于传统数据库来说,由于采用单点全共享(Shared-Everything)架构,数据库只有一个系统时钟来源,因此时间戳(即版本号)的变化的确能做到单调向前,并且一定和真实世界的时间顺序保持一致。
但对于OceanBase这样的分布式数据库来说,由于采用无共享(Shared-Nothing)架构,数据分布和事务处理会涉及不同的物理机器,而多台物理机器之间的系统时钟不可避免存在差异,如果以本地系统时间戳作为版本号,则无法保证不同机器上获取的版本号和真实世界的时间序保持一致。还是以上面的两个场景为例,如果T1、T2和T3分别在不同的物理机器上执行,并且它们都分别以本地的系统时间戳作为版本号,那么由于机器间的时钟差异,完全可能发生上面所说的两种异常。
为了解决上面所说的问题,在分布式领域引入了两个概念: “外部一致性(External Consistency)” 和 “因果一致性(Causal Consistency)”。还是以上面的两个场景为例,真实世界中事务的发生顺序为T1 -> T2-> T3,如果SCN的变化能保证SCN1 < SCN2 < SCN3的顺序,并且可以完全不关心事务发生时所在的物理机器,则认为SCN的变化满足了“外部一致性”。
而“因果一致性”则是“外部一致性”的一种特殊情况:事务的发生不仅有前后顺序,还要有前后关联的因果关系。因此“外部一致性”的覆盖范围更广,“因果一致性”只是其中的一种情况,如果满足了“外部一致性”则一定能满足“因果一致性”。OceanBase在实现中满足了“外部一致性”,同时也就满足了“因果一致性”,本文后半段的内容也主要针对“外部一致性”来展开。
业内常用的解决方案
那么,分布式数据库应如何在全局(跨机器)范围内保证外部一致性,进而实现全局一致的快照隔离级别和多版本并发控制呢?大体来说,业界有两种实现方式:
1)利用特殊的硬件设备,如GPS和原子钟(Atomic Clock),使多台机器间的系统时钟保持高度一致,误差小到应用完全无法感知的程度。在这种情况下,就可以继续利用本地系统时间戳作为版本号,同时也能满足全局范围内的外部一致性。
2)版本号不再依赖各个机器自己的本地系统时钟,所有的数据库事务通过集中式的服务获取全局一致的版本号,由这个服务来保证版本号的单调向前。这样一来,分布式架构下获取版本号的逻辑模型和单点架构下的逻辑模型就一样了,彻底消除了机器之间时钟差异的因素。
第一种方式的典型代表是Google的Spanner数据库。它使用GPS系统在全球的多个机房之间保持时间同步,并使用原子钟确保本地系统时钟的误差一直维持在很小的范围内,这样就能保证全球多个机房的系统时钟能够在一个很高的精度内保持一致,这种技术在Spanner数据库内被称为TrueTime。在此基础上,Spanner数据库就可以沿用传统的方式,以本地系统时间戳作为版本号,而不用担心破坏全局范围内的外部一致性。
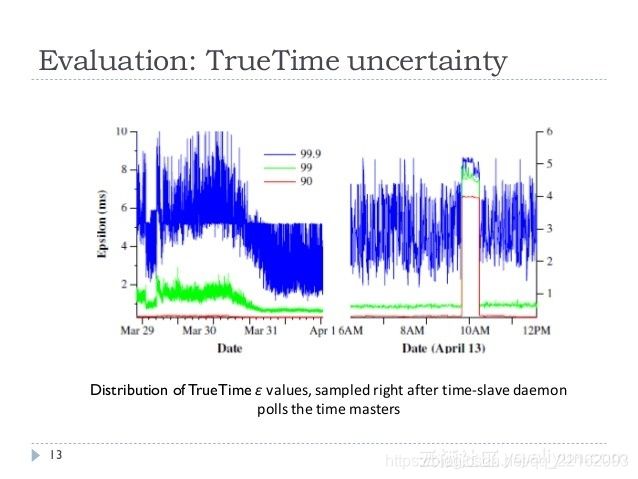
这种方式的好处,是软件的实现比较简单,并且避免了采用集中式的服务可能会导致的性能瓶颈。但这种方式也有它的缺点,首先对机房的硬件要求明显提高,其次“GPS+原子钟”的方式也不能100%保证多个机器之间的系统时钟完全一致,如果GPS或者原子钟的硬件偏差导致时间误差过大,还是会出现外部一致性被破坏的问题。根据GoogleSpanner论文中的描述,发生时钟偏差(clock drift)的概率极小,但并不为0。下图是Google Spanner论文中对上千台机器所做的关于时钟误差范围的统计:
OceanBase则选用了第二种实现方式,即用集中式的服务来提供全局统一的版本号。做这个选择主要是基于以下考虑:
可以从逻辑上消除机器间的时钟差异因素,从而彻底避免这个问题。
避免了对特殊硬件的强依赖。这对于一个通用数据库产品来说尤其重要,我们不能假设所有使用OceanBase数据库的用户都在机房里部署了“GPS+原子钟”的设备。
OceanBase的“全局一致性快照”技术
如前文所述, OceanBase数据库是利用一个集中式服务来提供全局一致的版本号。事务在修改数据或者查询数据的时候,无论请求源自哪台物理机器,都会从这个集中式的服务处获取版本号,OceanBase则保证所有的版本号单调向前并且和真实世界的时间顺序保持一致。
有了这样全局一致的版本号,OceanBase就能根据版本号对全局(跨机器)范围内的数据做一致性快照,因此我们把这个技术命名为“全局一致性快照”。有了全局一致性快照技术,就能实现全局范围内一致的快照隔离级别和多版本并发控制,而不用担心发生外部一致性被破坏的情况。
但是,相信有些朋友看到这里就会产生疑问了,比如:
这个集中式服务里是如何生成统一版本号的?怎么能保证单调向前?
这个集中式服务的服务范围有多大?整个OceanBase集群里的事务都使用同一个服务吗?
这个集中式服务的性能如何?尤其在高并发访问的情况下,是否会成为性能瓶颈?
如果这个集中式服务发生中断怎么办?
如果在事务获取全局版本号的过程中,发生了网络异常(比如瞬时网络抖动),是否会破坏“外部一致性”?
下面针对这些疑问逐一为大家解答。
首先,这个集中式服务所产生的版本号就是本地的系统时间戳,只不过它的服务对象不再只是本地事务,而是全局范围内的所有事务,因此在OceanBase中这个服务被称作“全局时间戳服务(Global Timestamp Service,简称GTS)”。由于GTS服务是集中式的,只从一个系统时钟里获取时间戳,因此能保证获取的时间戳(即版本号)一定是单调向前的,并且一定和真实世界的时间顺序保持一致。
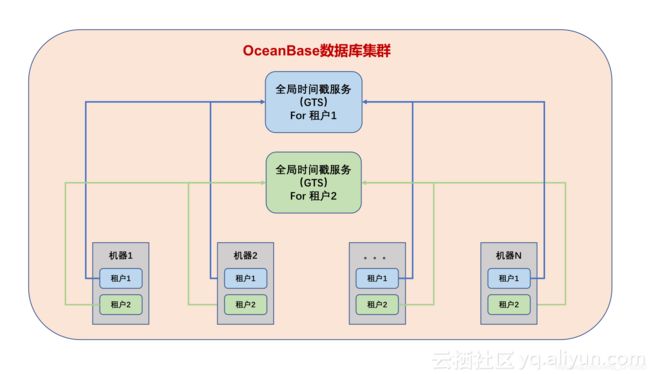
那么,是否一个OceanBase数据库集群中只有一个GTS服务,集群中所有的事务都从这里获取时间戳呢?对OceanBase数据库有了解的朋友都知道,“租户”是OceanBase中实现资源隔离的一个基本单元,比较类似传统数据库中“实例”的概念,不同租户之间的数据完全隔离,没有一致性要求,也无需实现跨租户的全局一致性版本号,因此OceanBase数据库集群中的每一个“租户”都有一个单独的GTS服务。这样做不但使GTS服务的管理更加灵活(以租户为单位),而且也将集群内的版本号请求分流到了多个GTS服务中,大大减少了因单点服务导致性能瓶颈的可能。下面是OceanBase数据库集群中GTS服务的简单示意图:
说到性能,经过实测,单个GTS服务能够在1秒钟内响应2百万次申请时间戳(即版本号)的请求,因此只要租户内的QPS不超过2百万,就不会遇到GTS的性能瓶颈,实际业务则很难触及这个上限。虽然GTS的性能不是一个问题,但从GTS获取时间戳毕竟比获取本地时间戳有更多的开销,至少网络的时延是无法避免的,对此我们也做过实测,在满负荷压测并且网络正常的情况下,和采用本地时间戳做版本号相比,采用GTS对性能所带来的影响不超过5%,绝大多数应用对此都不会有感知。
除了保证GTS的正常处理性能之外,OceanBase数据库还在不影响外部一致性的前提下,对事务获取GTS的流程做了优化,比如:
1、将某些GTS请求转化为本地请求,从本地控制文件中获取版本号,避免了网络传输的开销;
2、将多个GTS请求合并为一个批量请求,以提高GTS的全局吞吐量;
3、利用“本地GTS缓存技术”,减少GTS请求的次数。
这些优化措施进一步提高了GTS的处理效率,因此,使用者完全不用担心GTS的性能。
前面所说的都是正常情况,但对于集中式服务来说一定要考虑异常情况。首先就是高可用的问题,GTS服务也像OceanBase中基本的数据服务一样,以Paxos协议实现了高可用,如果GTS服务由于异常情况(比如宕机)而中断,那么OceanBase会根据Paxos协议自动选出一个新的服务节点,整个过程自动而且迅速(1~15秒),无需人工干预。
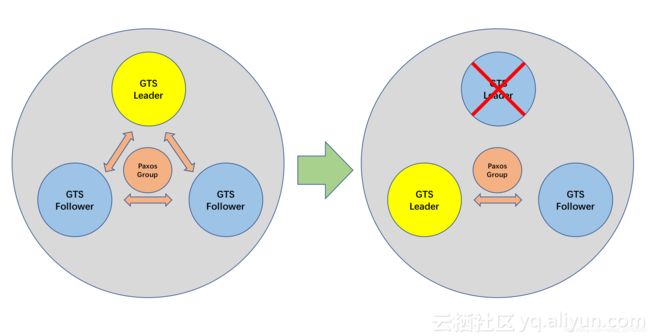
那如果发生网络异常怎么办?比如网络抖动了10秒钟,会不会影响版本号的全局一致性,并进而影响外部一致性?对数据库来说,外部一致性反映的是真实世界中“完整事务”之间的前后顺序,比如前面说到的T1 -> T2-> T3,其实准确来说是T1’s Begin-> T1’s End -> T2’s Begin -> T2’s End -> T3’s Begin -> T3’s End,即任意两个完整的事务窗口之间没有任何重叠。如果发生了重叠,则事务之间并不具备真正的“先后顺序”,外部一致性也就无从谈起。
因此,不管网络如何异常,只要真实世界中的“完整事务”满足这种前后顺序,全局版本号就一定会满足外部一致性。
最后,如果事务发现GTS响应过慢,会重新发送GTS请求,以避免由于特殊情况(如网络丢包)而导致事务的处理被GTS请求卡住。
总之,GTS在设计和开发的过程中已经考虑到了诸多异常情况的处理,确保可以提供稳定可靠的服务。
关于Oceanbase就说道这,更多详细可以查看这篇文章【干货集锦】OceanBase 2.0 技术解析系列—核心技术原理深入解读