python入门 - 基础数据类型
文章目录
- 1. 变量和数据类型的介绍
-
- 1.编程和编程语言
- 2.python学习的套路
- 3运行python程序的两种方式
- 4.变量
- 5.字符串类型介绍
- 6.用户与交互
- 7.字符串之格式化输出
- 8.数字类型介绍
- 9.数字类型之运算符
- 10.布尔类型
- 11.复数类型
- 12.列表类型
- 13.字典类型
- 14.元组类型
- 15.集合类型
- 16.总结数据类型规律
- 2.数据类型常用操作和方法
-
- 1.字符串的常用操作和内置方法
- 2.数字类型转换和赋值运算
- 3.布尔类型的特性
- 4.列表的常用操作和内置方法
- 5.元组的常用操作和内置方法
- 6.字典的常用操作和内置方法
- 7.集合的常用操作和内置方法
- 写在最后:
- 小作业
1. 变量和数据类型的介绍
1.编程和编程语言
print('hello world')
# 注释 注释是不会被运行的,只有代码会被运行
'''
1、什么是编程语言
语言是一个事物与另外一个事物沟通的介质
比如人与人交流汉语,英语,日语
编程语言是程序员与计算机沟通的介质
计算机只能读懂二进制,python解释器可以讲python语言转换成计算机理解的二进制
2、什么是编程
编程就是程序按照某种编程语言的语法规范将自己想要让计算机做的事情表达出来
我要让电脑进行记录或者判断一种状态,或者我让电脑循环做一件事情
表达的结果就是程序,程序就是一系列的文件
程序就是代码的结合体,一堆代码代表让电脑做一堆的事情
3、为什么要编程
在编程的过程中,计算机就像是人的奴隶
我们编程的目的就是为了让计算机代替人类去工作,从而解放人力
'''
2.python学习的套路
'''
Python是语言,而学习语言的套路都是一样的
,以英语学习为例,你需要学单词,然后学语法,最后写作文。
英语的单词---------->Python中的关键字,方法
英语的语法---------->Python的语法
英语的作文---------->用Python语言写的程序
当然python比英语好学,单词基本不用记,语法写错也会有提示
'''
3运行python程序的两种方式
'''
运行python程序的两种方式:
方式一:交互式 直接输入代码运行
最好用来测试代码
cmd
使用方法 win + R
输入python启动,要有环境变量添加的情况下才能启动
优点:
输入一行代码立刻就返回
缺点:
无法永久保存代码
方式二: 运行python文件
cmd 运行python文件
1.python python文件的绝对路径
2.python python文件的相对路径(这个是必须切换到python运行文件的文件夹下) tab可以补全
3.pycharm运行python代码,右键代码空白部分run
优点:
pycharm自动保存代码
语法错误pycharm可以自动检查红色波浪线
注意: python文件的后缀名是py
'''
4.变量
'''
什么是变量
量:是衡量/记录现实世界中的某种特征/状态
变:指的是记录的状态是可以发生变化的
'''
'''
为什么要用变量
是为了让计算机能够像人一样去将一个事物的特征/状态记忆下来(存到计算机内存)
以后可以取出来使用
'''
'''
如何使用变量
'''
# 定义变量的语法
name = '大海'
# 变量名:相当于一个门牌号,是访问的唯一方式
# # = :是赋值
# # 值 : 表示状态
# 变量的使用
print('大海')
print(name)
# name = '小红'
# print(name)
# 变量的命名规则
# 1见名知意
# 2变量名的第一个字符不能是数字
# 3变量名只能是字母、数字或下划线的任意组合,(区分大小写)
a1 = '小明'
print(a1)
# 形容一个复杂的变量
# 下划线
age_of_dahai = 18
# 驼峰体
AgeOfDahai = 18
# 常量(全部写大写):就是不变的量 可以改,告诉别人不能改
NAME = '小海'
# 变量的特性
# 1.id相当于在内存中位置或者地址
print(id(name))
print(id(NAME))
# 2.类型
print(type(name))
5.字符串类型介绍
#字符类型:str
#作用:记录描述性质的数据,比如人的名字、性别、家庭地址、公司简介
#定义:在引号内按照从左到右的顺序依次包含一个个字符,引号可以是单引号、双引号、三引号
name = '大海1'
name1 = "大海2"
name2 = '''大海3'''
print(name,name1,name2)
# 字符串里面要有引号
print('my name is "dahai"')
print("my name is 'dahai'")
# 字符串还可以加起来
print('大海'+'dsb')
print('大海'*10)
name4 = 'abcdef'
# 索引从0开始,现实中书本的页码从1开始
# 取出第一个英文字符
print(name4[0])
print(name4[1])
print(name4[-1])
# 取出第一个中文字符
print(name[0])
6.用户与交互
'''
什么是与用户交互
程序等待用户输入一些数据,然后程序执行完毕后为用户反馈信息
为何程序要与用户交互
为了让计算机能够像人一样与用户的交互
如何用
input输入
print输出
'''
## cmd输入和输出不需要input和print 用于测试
# input(提示用户的输入信息) 输入的数据都会变成字符串类型
name = input('>>>')
print(name)
print(type(name))
print(type(1111))
7.字符串之格式化输出
'''
# 程序中经常会有这样场景:要求用户输入信息,然后打印成固定的格式
#
# 比如要求用户输入用户名和年龄,然后打印如下格式:
#
# My name is xxx,my age is xxx.
这就用到了占位符,如:%s、%d
'''
# name = input('输入名字')
# # 一个值的话直接放到%后面
# print('my name is %s'%name)
# %s 占位符 可以接受所有的数据类型 %d只能接受数字 有局限性
# 多个值的话直接放到%后面要有括号
print('My name is %s,my age is %d'%('dahai',18))
8.数字类型介绍
#一:数字类型
# 整型int
#作用:记录年龄,等级,QQ号,各种号码
# 定义:
age = 18
print(type(age))
# 2.浮点型:float
#作用:记录身高、体重weight、薪资
#定义:
weight = 151.2
print(type(weight))
9.数字类型之运算符
# 算术运算
# age = 18
# print(type(age))
# 加 +
# 减 -
# 乘 *
# 除 /
# 地板除 //
# 取余 %
# 乘方 **
# print(2+2)
# print(2-2)
# print(2*3)
# print(int(4/2))
# print(7//3)# 取整
# print(7%3) # 余数是1
# print(4**2)
# 比较运算符
# 等于 ==
# 不等于 !=
# 大于 >
# 小于 <
# 大于或等于 >=
# 小于或等于 <=
print(3 == 4)
print(3 == 3)
# 返回对就是True,False就是错误的
print(3 != 3)
print(3 > 2)
print(3 < 3)
print(3 < 3)
print(4 >= 4)
print(4 <= 5)
print(type('4 <= 5'))
10.布尔类型
'''
#布尔类型:bool
#作用:用来作为判断的条件去用
#布尔值,一个True一个False
#计算机俗称电脑,即我们编写程序让计算机运行时,
应该是让计算机无限接近人脑,或者说人脑能干什么,
计算机就应该能干什么,
# 人脑的主要作用是数据运行与逻辑运算,此处的布尔类型就模拟人的逻辑运行,
即判断一个条件成立时,用True标识,不成立则用False标识
'''
# tag = True
tag = False
print(type(tag))
11.复数类型
# 复数类型complex 是一个线性的参数(了解)
x = 1 - 2j
print(type(x))
12.列表类型
# 字符串,数字,布尔,复数 都是一个值
'''
# 列表类型:list
#作用:记录/存多个值,可以方便地取出来指定位置的值,比如人的多个爱好,一堆学生姓名
#定义:在[]内用逗号分隔开多个任意类型的值
'''
L = ['大海',1,1.2,[1.22,'小海']]
# 0 1 2 3
print(L)
# # 索引从0开始 相当于我们书的页码
print(L[0])
print(L[1])
print(L[1])
print(L[1])
print(L[1])
print(L[-1]) # 反向取
print(L[3]) # 正向取
print(L[3][1])
xiaohai_list=L[3]
print(xiaohai_list)
print(xiaohai_list[1])
L[0]='红海'
print(L)
13.字典类型
'''
#字典类型:dict
#作用:记录多个key:value值,优势是每一个值value都有其对应关系/映射关系key,而key对value有描述性的功能
#定义: 在{}内用逗号分隔开多个key:value元素,其中value可以是任意的数据类型,而key通常应该是字符串类型
'''
info = {'name':'大海','age':18}
# name 相当于新华字典里面的偏旁部首
print(info['name'])
print(info['age'])
print(info)
# 列表和字典的区别
# 列表是依靠索引
# 字典是依靠键值对 # key描述性的信息
14.元组类型
#一:基本使用:tuple
# 1 用途:记录多个值,当多个值没有改的需求,此时用元组更合适
# 2 定义方式:在()内用逗号分隔开多个任意类型的值
t = (1,2,'大海',(2,3),['红海',2,3])
print(t)
print(type(t))
print(t[0])
# t[0]=5
print(t)
print(t[4][0])
15.集合类型
#一:基本使用:set
# 1 用途: 关系运算
# 2 定义方式: 在{}内用逗号分开个的多个值
# 3. 1.元素不能重复(定义不能这样写相同的)
# 2.集合里面的元素是无序
# s = {1,2,'大海'}
# print(s)
# print(type(s))
s1 = {'a','b','c'}
s2 = {'a','c','d'}
print(s1 & s2) # # 拿2个集合相同的元素 shift + 7交集符合 交集
print(s1 | s2)# 拿2个集合所有的元素 并集
print(s1 - s2)# s1 去 抵消它们的交集 差集
16.总结数据类型规律
# 一个值 字符串,数字,布尔,复数
# 多个值容器 有序的有列表和 元组(不能存和修改)
# 无序的有字典 集合(关系运算,不是为了取)
# 字符串,数字,布尔,列表,字典,元组,集合,复数
# 什么是数值类型?
# 表示数字类的一个数据:
# 整型 int 代表一个整数 作用 表示 年龄 分数
# 浮点型 float 代表一个小数 表示 身高 体重
# 布尔类型 bool 计算机的真假代表一个数字类的数据 0 和 1 True False 首字母大写 判断真假
# 复数:complex(了解)
# # z = 4 - 4j # 表示坐标 实部,虚部 表示一个线性的参数
# 序列类型
# 按照一定顺序排序的数据类型
# 列表: list 多个数据 存储数据:可以放任任意的数据类型
# 元组: tuple 多个数据 存储数据:可以放任任意的数据类型 不能修改和添加里面的值 私密的数据
# 字符串 str 一个数据 描述性质:表示名字
# 散列类型
# # 什么是散列类型? 不可以进行索引取值
# # 没有顺序,一盘散沙
# # 集合 set 多个数据
# 存储数据:可以放任任意的数据类型, 可变类型,无序,
# # 字典 dict 多个数据
# 存储数据:key里面只能放入不可变类型,最好字符串类型,value里面可以放任任意的数据类型
2.数据类型常用操作和方法
1.字符串的常用操作和内置方法
#字符类型:str
#作用:记录描述性质的数据,比如人的名字、性别、家庭地址、公司简介
#定义:在引号内按照从左到右的顺序依次包含一个个字符,引号可以是单引号、双引号、三引号
# name = '大海1'
# name1 = "大海2"
# name2 = '''大海3'''
# print(name,name1,name2)
# # 字符串里面要有引号
# print('my name is "dahai"')
# print("my name is 'dahai'")
#
# # 字符串还可以加起来
# print('大海'+'dsb')
# print('大海'*10)
# name4 = 'abcdef'
# 索引从0开始,现实中书本的页码从1开始
# 取出第一个英文字符
# print(name4[0])
# print(name4[1])
# print(name4[-1])
# # 取出第一个中文字符
# print(name[0])
#字符串不能通过索引修改
# name4[0] = 'g'
# print(name4)
msg = 'hello world'
# 012345
print(msg[0])
print(msg[-1])
#2、切片(顾头不顾尾,步长)查找字符串当中的一段值 [起始值:终止值:步长]
# 相当于切黄瓜 一节一节
print(msg[0:5])
print(msg[0:5:1])
# 提取不会改变原值
print(msg)
print(msg[0:5:2])
# 了解
print(msg[::])
print(msg[0::])
print(msg[0::2])
# 步长是负数
print(msg[::-1])
print(msg[10::-1])
print(msg[10:5:-1])
#3、长度len方法 可以计算长度
print(len(msg))
#4、成员运算in和not in: 判断一个子字符串是否存在于一个大的字符串中
# 返回布尔类型 True False
print('dahai' in 'dahai is dsb')
print('xialuo' not in 'dahai is dsb')
# 字符串的方法
# 增
# 字符串拼接
print('dahai'+'dsb')
# format
print('my name is {}'.format('dahai'))
print('my name is {1} my age is {0}'.format(18,'dahai'))
print('my name is {name} my age is {age}'.format(age=18,name='dahai'))
# join
str1 = '真正的勇士'
str2 = '敢于直面惨淡的人生'
str3 = '敢于正视淋漓的鲜血'
# 可以把列表里面的元素组合成字符串
print(''.join([str1,str2,str3]))
print(','.join([str1,str2,str3]))
print('哇塞'.join([str1,str2,str3]))
# 空格也属于字符
print(' '.join([str1,str2,str3]))
# 删
# name1 = 'dahai'
#
# del name1
# print(name1)
# 改
#1、 字符串字母变大写和变小写 lower,upper
msg1 = 'abc'
msg2=msg1.upper()
# 原值
print(msg1)
print(id(msg1))
# 修改后的值
print(msg2)
print(id(msg2))
# 注意字符串进行改变需要重新赋值,所以它也是不可变类型,它的原值的变量不会变,
# 只是做了一个方法改变了它的值,重新赋值给一个新的变量
# 2把第一个字母转换成大写 capitalize
letter = 'abcd'
print(letter.capitalize())
#3 每个单词的首字母进行大写转换 title
letter_msg = 'hello world'
print(letter_msg.title())
# 4把字符串切分成列表 split 默认空格字符切分
msgg = 'hello world python'
# 默认以空格切分
print(msgg.split())
# 可以切分你想要的字符 比如*
msgg1 = 'hello*world*python'
print(msgg1.split('*'))
#切分split的作用:针对按照某种分隔符组织的字符串,可以用split将其切分成列表,进而进行取值
msggg = 'root:123456'
print(msggg[0:4])
print(msggg.split(':')[0])
print(msggg.split(':')[1])
#5、去掉字符串左右两边的字符strip不写默认是空格字符,不管中间的其他的字符
user = ' dahai '
print(user)
print(user.strip())
# name = input('请输入用户名').strip()
# print(name)
# 了解
# center,ljust,rjust 多余添加自己想要的字符
print('dahai'.center(11,'*'))
print('dahai'.ljust(11,'*'))
print('dahai'.rjust(11,'*'))
# 查
#1、find,index
# 查找子字符串在大字符串的那个位置(起始索引)
msga = 'hello dahai is dsb dahai'
print(msga.find('dahai'))
# 没找到会返回-1
print(msga.find('ddddd'))
print(msga.index('dahai'))
# 没找到会报错
# print(msga.index('ddddd'))
# 统计一个子字符串在大字符串中出现的次数 count
print(msga.count('dahai'))
# 判断一个字符串里的数据是不是都是数字 isdigit # 返回布尔值
num = '1818'
num1 = '18aaa18'
aaaa = 'aaa'
print(num.isdigit())
print(num1.isdigit())
# print(type(input('>>>')))
# 判断每个元素是不是都是字母 isalpha
print(aaaa.isalpha())
print(num.isalpha())
print(num1.isalpha())
# 比较开头的元素是否相同 startswith
# 比较结尾的元素是否相同 endswith
# 返回布尔类型
mm = 'dahai xialuo'
print(mm.startswith('dahai'))
print(mm.endswith('uo'))
# 判断字符串中的值是否全是小写的 islower
# 判断字符串中的值是否全是大写的 isupper
letter2 = 'ABC'
letter3 = 'abc'
letter4 = 'aAbc'
print(letter2.isupper())
print(letter3.isupper())
print(letter4.isupper())
print(letter2.islower())
print(letter3.islower())
print(letter4.islower())
# 字符串的转义
# 字符串的转义 加了 \ 字符不再表示它本身的含义
# 常用的 \n \t
# \n 换行符
print('hello \n python')
# \n 横向换行符 相当于一个tab
print('hello \t python')
print(r'hello \n python \t')
print('hello \\n python \\t')
2.数字类型转换和赋值运算
#一:数字类型
# 整型int
#作用:记录年龄,等级,QQ号,各种号码
# 定义:
age = 18
print(type(age))
# 2.浮点型:float
#作用:记录身高、体重weight、薪资
#定义:
weight = 151.2
print(type(weight))
# 赋值运算
# 普通赋值 =
# 加法赋值 +=
# 减法赋值 -=
# 乘法赋值 *=
# 除法赋值 /=
# 取余赋值 %=
# 乘方赋值 **=
# 地板除赋值 //=
# 语法 n = n + XXX 相等于 n += XXX
n = 2
# n = n + 3
# 等价于
# n += 3
# print(n)
n -= 1 # n = n - 1
print(n)
3.布尔类型的特性
'''
#布尔类型:bool
#作用:用来作为判断的条件去用
#布尔值,一个True一个False
#计算机俗称电脑,即我们编写程序让计算机运行时,
应该是让计算机无限接近人脑,或者说人脑能干什么,
计算机就应该能干什么,
# 人脑的主要作用是数据运行与逻辑运算,此处的布尔类型就模拟人的逻辑运行,
即判断一个条件成立时,用True标识,不成立则用False标识
'''
# tag = True
# tag = False
# print(type(tag))
# 重点知识
# 不仅仅是真假 还是有无
# 所有的数据类型都自带布尔值
# 1.None,0,空(空字符串,空列表,空字典,)三种情况下布尔值为False,
# 2.其余均为真
# if
tag1 = {'name':'dahai'}
# print(bool(tag1))
if tag1:
print('数据类型自带True')
else:
print('数据类型自带False')
4.列表的常用操作和内置方法
# 字符串,数字,布尔,复数 都是一个值
'''
# 列表类型:list
#作用:记录/存多个值,可以方便地取出来指定位置的值,比如人的多个爱好,一堆学生姓名
#定义:在[]内用逗号分隔开多个任意类型的值
'''
L = ['大海',1,1.2,[1.22,'小海']]
# 0 1 2 3
# print(L)
# # # 索引从0开始 相当于我们书的页码
# print(L[0])
# print(L[1])
# print(L[1])
# print(L[1])
# print(L[1])
# print(L[-1]) # 反向取
# print(L[3]) # 正向取
# print(L[3][1])
# xiaohai_list=L[3]
# print(xiaohai_list)
# print(xiaohai_list[1])
print(L)
print(id(L))
# 把原值改了
L[0]='红海'
print(L)
print(id(L))
# 2、切片(顾头不顾尾,步长)
# 查找列表当中的一段值 [起始值:终止值:步长]
# 和字符串提取字符一样,只不过字符串取的是字符,列表取的是一个数据类型/元素
# 但是字符串不能索引改值
# 默认步长为1
print(L[0:3])
print(L[0:3:1])
print(L[0:3:2])
# 3.len长度 列表元素的多少
print(len(L))
# 4.成员运算in和not in
print('红海' in L)
print('红海'not in L)
# 查看列表某个元素的个数 count
print(L.count('红海'))
# 在列表中从左至右查找指定元素,找到了放回该值的下标/索引
print(L.index('红海'))
# print(L.index('海'))
#增
# append(元素) 往列表末尾追加一个元素
L.append('蓝海')
print(L)
# 规律列表的修改和增加都不需要重新复制,直接改变了原值,所以是可变类型
# 字符串,数字,布尔,复数 都是一个值,改变需要重新赋值,都是不可变类型
L.append('蓝海')
print(L)
# extend() 往列表当中添加多个元素 括号里放列表 也是末尾追加
L.extend(['绿海','紫海'])
# L.extend(['绿海','紫海'])
print(L)
# insert(索引,元素) 往指定索引位置前插入一个元素
L.insert(1,'黄海')
print(L)
# 删除
# del L[0]
# print(L)
# 指定删除
# L.remove('紫海')
# print(L)
# pop # 从列表里面拿走一个值
# # 按照索引删除值
# # 默认是删除最后一个
# L.pop()
# print(L)
# res=L.pop(0)
# # 返回值指定的索引元素
# print(res)
# print(L)
# 清空列表clear
# L.clear()
# print(L)
# 改
# L[0]='白海'
# print(L)
# 反序
# L.reverse()
# print(L)
# sort 排序 对数字
list_num = [1,3,2,5]
# 不写默认是正序
# reverse=True参数是倒序
list_num.sort(reverse=True)
print(list_num)
# reverse=False参数是正序
list_num.sort(reverse=False)
print(list_num)
5.元组的常用操作和内置方法
#一:基本使用:tuple
# 1 用途:记录多个值,当多个值没有改的需求,此时用元组更合适
# 2 定义方式:在()内用逗号分隔开多个任意类型的值
t = (1,2,'大海',(2,3),['红海',2,3])
# 0 1 2 3 4
print(t)
print(type(t))
print(t[0])
# 不能索引修改,
# t[0]=5
print(t)
print(t[4][0])
# t[3][0]=1
# 但是元组里面的列表是可以改的
t[4][0]='小海'
print(t)
# 元组是不能修改和添加所以元组是不可变类型
# 如果想修改可以转换成列表
t1=list(t)
print(t1)
t1[0]=8
t= tuple(t1)
print(t)
# 查
# 与列表一样索引,切片,长度len,count个数,index查找元素所在索引,成员运算
# del t[0]
6.字典的常用操作和内置方法
'''
#字典类型:dict
#作用:记录多个key:value值,优势是每一个值value都有其对应关系/映射关系key,而key对value有描述性的功能
#定义: 在{}内用逗号分隔开多个key:value元素,其中value可以是任意的数据类型,而key通常应该是字符串类型
'''
info = {'name':'大海','age':18}
# name 相当于新华字典里面的偏旁部首
# print(info['name'])
# print(info['age'])
# print(info)
# 列表和字典的区别
# 列表是依靠索引
# 字典是依靠键值对 # key描述性的信息
# 生成字典的方式2
# dic = dict(x=1,y=2)
# print(dic)
# 字典的增加操作
print(info)
# 直接赋值一个不存在的key和value
info['addr']='changsha'
print(info)
# 字典我在添加的时候也没有进行重新赋值,所以字典是可变类型
# 列表却不行,添加和修改必须是操作存在的索引
# 字典 len 查看的是键值对的个数
print(len(info))
# 成员运算in和not in:字典的成员运算判断的是key 返回值是布尔类型
print('name'in info)
print('大海' in info)
# 删
# clear 清空字典
# info.clear()
# print(info)
# del
# del info['name']
# print(info)
# 不存在的key会报错
# del info['xxx']
# print(info)
# # pop 删除 返回值是value 实际上就是拿走了字典的value
# res = info.pop('addr')
# print(info)
# print(res)
# # 不存在的key会报错
# info.pop('xxx')
# # popitem 最后一对键值对删除 字典无序 返回的是一个元组
# res1=info.popitem()
# print(res1)
# print(info)
# # 改
print(info)
info['name']='红海'
print(info)
info.update({'name':'xiaohai'})
print(info)
# setdefault
# 有则不动/返回原值,无则添加/返回新值
# 字典中已经存在key则不修改,返回已经存在的key对应的value
res=info.setdefault('name','xxx')
print(info)
print(res)
# 字典不存在key则添加"sex":"male",返回新的value
res2 = info.setdefault('sex','male')
print(info)
print(res2)
# 查
# print(info['name'])
# # 查一个不存在的key会报错
# print(info['xxx'])
# print(info.get('name'))
# # 没有key就返回None,不会报错
# print(info.get('xxxx'))
# 取出所有的key
print(list(info.keys()))
# 取出所有的值
print(list(info.values()))
# 取出所有的键值对
print(list(info.items()))
7.集合的常用操作和内置方法
#一:基本使用:set
# 1 用途: 关系运算
# 2 定义方式: 在{}内用逗号分开个的多个值
# 3. 1.元素不能重复(定义不能这样写相同的)
# 2.集合里面的元素是无序
# s = {1,2,'大海'}
# # print(s)
# # print(type(s))
# # s1 = {'a','b','c'}
# # s2 = {'a','c','d'}
# #
# # print(s1 & s2) # # 拿2个集合相同的元素 shift + 7交集符合 交集
# # print(s1 | s2)# 拿2个集合所有的元素 并集
# # print(s1 - s2)# s1 去 抵消它们的交集 差集
#
# # 补充
# # 3 每一个值都必须是不可变类型
# # 错误示范
# # sss = {'aa',1,{'name':'dahai'}}
# # 增 add
# s.add('小海')
# # 集合是可变类型
# print(s)
# # 删 pop 看你的pycharm是怎样无序排列的,从第一个元素删除
# s.pop()
# print(s)
# # 指定删除remove
# # s.remove('大海')
# print(s)
# # 改
# # update
# s.update(['蓝海','紫海'])
# print(s)
#
# s1=list(s)
# s1[0]=8
# s=set(list(s1))
# print(type(s))
# print(s)
# 集合去重
# 局限性
#1、无法保证原数据类型的顺序
#2、当某一个数据中包含的多个值全部为不可变的类型时才能用集合去重
names =['dahai','xialuo','xishi','dahai','dahai','dahai']
s = set(names)
print(s)
l=list(s)
print(l)
# 要用for循环和if判断去重就可以保证顺序和对可变类型去重
# 总结
# 字符串,数字,布尔,复数 都是一个值,改变需要重新赋值,都是不可变类型
# 容器元组是不可变类型,字典,列表,集合都是可变类型
写在最后:
感觉和java差不多,python中的集合指的是Java中的Set,用 { } 表示,List是用 [ ]表示。但是没有严格的属性之分,集合中相当于都是Object,存啥都可以。
有个步长的概念,例 msg[0:8:2] ,即查询 msg的0到7索引的值,每次跳2格。
通用的关键字:

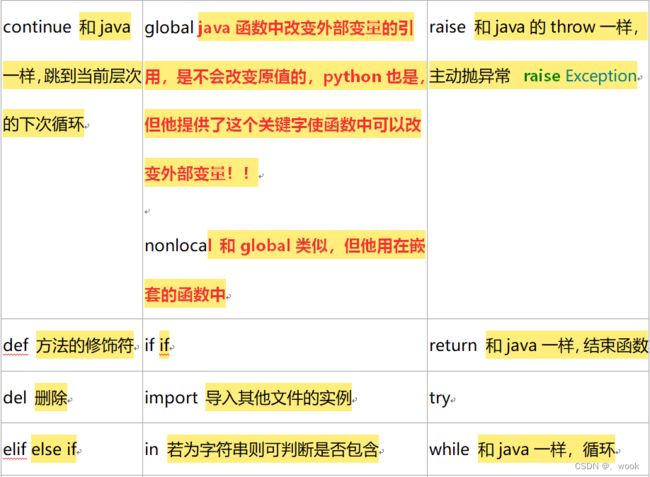

#字符串,数字,布尔,复数 都是一个值,改变需要重新赋值,都是不可变类型
#容器元组是不可变类型,字典,列表,集合都是可变类型
小作业
定义一个列表,列表中的元素有’安琪拉’,‘妲己’,‘韩信’,‘典韦’,‘吕布’五个元素,然后进行以下操作:
1.增加两个元素,‘小乔’,‘貂蝉’
2.查找’妲己’的索引(下标)
3.删除’韩信’
4.将最后一个元素修改为’白起’
5.通过切片输出下标为偶数的元素
heroList = ['安琪拉','妲己','韩信','典韦','吕布']
heroList.append('小乔');
heroList.append('貂蝉');
print(heroList.index('妲己'))
heroList.remove('韩信')
print(heroList)
heroList[len(heroList)-1] = '白起'
print(heroList)
print(heroList[::2])
用户有这样的一条信息,姓名为翠花,年龄18岁,性别女,请定义一个字典包含了这些信息,然后进行一下操作
1.增加一个元素,地址为北京
2.将性别改为男
3.删除年龄
4.输出此字典
mapUser = {"name":"翠花","age":18,"sex":"女"}
mapUser["address"] = '北京'
mapUser["sex"] = '男'
mapUser.pop('age')
print(mapUser)