【CVPR 2020】伪装目标检测算法SINET-训练并推理
CVPR 2023-SINET-伪装目标检测 代码调试记录
- 一、论文以及开源代码
- 二、代码准备
- 三、环境配置
- 四、COD10k数据集准备
- 五、训练环节
-
- 注意点1:
- 注意点2:
- 超参设置
- 六、测试及推理环节
-
- 推理部分
- 推理结果展示:
- 七、☀️将pth转成onnx,并使用onnxruntime推理☀️
-
- pth转onnx
- 使用onnxruntime推理
- Tips
一、论文以及开源代码
最近了解并学习了一下伪装目标检测,其中SINET是一篇2020年发表与CVPR的关于伪装目标检测算法的一篇论文,下面附上论文和代码链接:
论文链接:SINET论文
代码链接:SINET代码
二、代码准备
直接在第一部分中,点击代码链接进入github,然后按照常规步骤进行git clone即可,不多赘述。
三、环境配置
根据requirement.txt中可以看到,该项目主要用到的是torch,torchvision,scipy,opencv-python这几个库,至于版本的话,我并没有用requirement.txt中指定的版本。这里贴出我的环境版本:
torch-------------------1.10.0+cu113
torchvision-------------0.11.0+cu113
scikit-image------------0.19.3
scikit-learn------------1.0.2
scipy-------------------1.7.3
opencv-python-----------4.6.0.66
四、COD10k数据集准备
进入README.md中,找到2.2部分,直接点击百度网盘链接下载即可:

下载完之后,解压,然后在项目的主目录下创建Dataset文件夹,然后将解压好的训练和测试数据集分别命名为TrainDataset以及TestDataset,放入Dataset路径下:
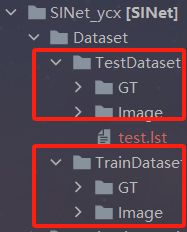
五、训练环节
注意点1:
在MyTrain.py中的 from apex import amp,如果直接使用pip install apex的话,我们下好的apex是不会带amp.initialize的,新版本中已经没有了这个api,这里我先尝试了使用torch.cuda自带的amp,发现amp并没有initialize这个api。amp.initialize()主要是用来实现在混合精度训练的,目的就是提高训练的效率,加速训练过程,如果有同学找到比较好的平替可以告诉我一下,我这边直接把这行注释掉了。
注意点2:
根据注意点1我所描述的,现在版本的apex中的amp已经没有了很多api,因此我直接把MyTrain.py中的 from apex import amp注释掉了,干脆不使用这个库,同样的,在trainer.py中也将from apex import amp注释掉,既然不好用,那咱直接不用了哈哈!这里需要变动的是,在代码的71行,调用了amp.scale_loss来进行损失的反向传播。我们这里导入from torch.cuda import amp来实现一样的功能:
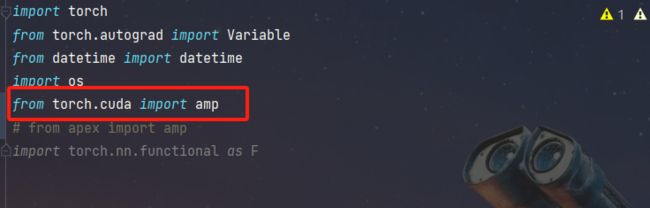
代码变动为:
def trainer(train_loader, model, optimizer, epoch, opt, loss_func, total_step):
"""
Training iteration
:param train_loader:
:param model:
:param optimizer:
:param epoch:
:param opt:
:param loss_func:
:param total_step:
:return:
"""
model.train()
cuda = torch.device('cuda')
scaler = amp.GradScaler(enabled=cuda)
for step, data_pack in enumerate(train_loader):
optimizer.zero_grad()
images, gts = data_pack
images = Variable(images).cuda()
gts = Variable(gts).cuda()
with amp.autocast():
cam_sm, cam_im = model(images)
loss_sm = loss_func(cam_sm, gts)
loss_im = loss_func(cam_im, gts)
loss_total = loss_sm + loss_im
scaler.scale(loss_total).backward()
scaler.step(optimizer)
scaler.update()
if step % 10 == 0 or step == total_step:
print('[{}] => [Epoch Num: {:03d}/{:03d}] => [Global Step: {:04d}/{:04d}] => [Loss_s: {:.4f} Loss_i: {:0.4f}]'.
format(datetime.now(), epoch, opt.epoch, step, total_step, loss_sm.data, loss_im.data))
save_path = opt.save_model
os.makedirs(save_path, exist_ok=True)
if (epoch+1) % opt.save_epoch == 0:
torch.save(model.state_dict(), save_path + 'SINet_%d.pth' % (epoch+1))
做完这一步之后,如果我们的训练集路径没有问题,那就可以正常训练起来了。
超参设置
if __name__ == "__main__":
parser = argparse.ArgumentParser()
#训练轮次
parser.add_argument('--epoch', type=int, default=40,
help='epoch number, default=30')
#学习率
parser.add_argument('--lr', type=float, default=1e-4,
help='init learning rate, try `lr=1e-4`')
#batch大小,根据自己的gpu内存大小灵活设置
parser.add_argument('--batchsize', type=int, default=16,
help='training batch size (Note: ~500MB per img in GPU)')
#输入图像resize的尺寸
parser.add_argument('--trainsize', type=int, default=352,
help='the size of training image, try small resolutions for speed (like 256)')
#梯度裁剪余量
parser.add_argument('--clip', type=float, default=0.5,
help='gradient clipping margin')
#学习率衰减系数
parser.add_argument('--decay_rate', type=float, default=0.1,
help='decay rate of learning rate per decay step')
#学习率衰减周期
parser.add_argument('--decay_epoch', type=int, default=30,
help='every N epochs decay lr')
#gpu idx
parser.add_argument('--gpu', type=int, default=0,
help='choose which gpu you use')
#权重保存周期
parser.add_argument('--save_epoch', type=int, default=10,
help='every N epochs save your trained snapshot')
#权重保存路径
parser.add_argument('--save_model', type=str, default='./Snapshot/2020-CVPR-SINet/')
#训练图像路径
parser.add_argument('--train_img_dir', type=str, default='./Dataset/TrainDataset/Image/')
#训练图像gt路径
parser.add_argument('--train_gt_dir', type=str, default='./Dataset/TrainDataset/GT/')
opt = parser.parse_args()
六、测试及推理环节
根据我在第五部分的超参数设置,训练完之后会生成四个模型权重文件,我们在MyTest.py中通过读取最后一轮保存的权重来进行测试和推理:
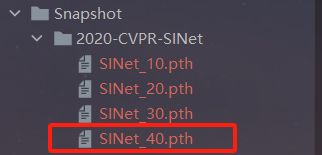
parser = argparse.ArgumentParser()
parser.add_argument('--testsize', type=int, default=352, help='the snapshot input size')
parser.add_argument('--model_path', type=str,
default='./Snapshot/2020-CVPR-SINet/SINet_40.pth')
parser.add_argument('--test_save', type=str,
default='./Result/2020-CVPR-SINet-New/')
opt = parser.parse_args()
推理部分
下面贴出我的推理部分的改动,以及结果展示:
这段代码有一个要注意的地方,就是#load data处,这里我将load_data()的返回值进行了些许的改动,多了一个原图的返回,为了方便在显示的时候能够在对应的原图上进行标记,在这段代码的下方,我也贴出了在Dataloader.py中的test_dataset类里load_data()方法的改动:
import torch
import torch.nn.functional as F
import numpy as np
import os
import argparse
from scipy import misc # NOTES: pip install scipy == 1.2.2 (prerequisite!)
from Src.SINet import SINet_ResNet50
from Src.utils.Dataloader import test_dataset
from Src.utils.trainer import eval_mae, numpy2tensor
import imageio
from pathlib import Path
import shutil
import cv2
parser = argparse.ArgumentParser()
parser.add_argument('--testsize', type=int, default=352, help='the snapshot input size')
parser.add_argument('--model_path', type=str,
default='./Snapshot/2020-CVPR-SINet/SINet_40.pth')
parser.add_argument('--test_save', type=str,
default='./Result/2020-CVPR-SINet-New/')
opt = parser.parse_args()
model = SINet_ResNet50().cuda()
model.load_state_dict(torch.load(opt.model_path))
model.eval()
for dataset in ['COD10K']:
save_path = opt.test_save + dataset + '/'
if Path(save_path).exists():
shutil.rmtree(save_path)
os.makedirs(save_path, exist_ok=True)
# NOTES:
# if you plan to inference on your customized dataset without grouth-truth,
# you just modify the params (i.e., `image_root=your_test_img_path` and `gt_root=your_test_img_path`)
# with the same filepath. We recover the original size according to the shape of grouth-truth, and thus,
# the grouth-truth map is unnecessary actually.
# test_loader = test_dataset(image_root='./Dataset/TestDataset/{}/Image/'.format(dataset),
# gt_root='./Dataset/TestDataset/{}/GT/'.format(dataset),
# testsize=opt.testsize)
test_loader = test_dataset(image_root='./Dataset/TestDataset/Image/'.format(dataset),
gt_root='./Dataset/TestDataset/Image/'.format(dataset),
testsize=opt.testsize)
img_count = 1
for iteration in range(test_loader.size):
if img_count == 200:
break
# load data
image, gt, name, image_original = test_loader.load_data()
# image_original = image.copy()
gt = np.asarray(gt, np.float32)
gt /= (gt.max() + 1e-8)
image = image.cuda()
# inference
_, cam = model(image)
# reshape and squeeze
cam = F.upsample(cam, size=gt.shape, mode='bilinear', align_corners=True)
cam = cam.sigmoid().data.cpu().numpy().squeeze()
# normalize
cam = (cam - cam.min()) / (cam.max() - cam.min() + 1e-8)
cam *= 255
# cv2.namedWindow("test1", cv2.WINDOW_NORMAL)
# cv2.imshow("test1", cam)
# cv2.waitKey(0)
minval, maxval = 127, 255
ret, thresh = cv2.threshold(cam, minval, maxval, cv2.THRESH_BINARY)
cv2.namedWindow("thresh", cv2.WINDOW_NORMAL)
cv2.imshow("thresh", thresh)
cv2.waitKey(0)
cam_contours, hierarchy = cv2.findContours(np.uint8(thresh), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for i in range(len(cam_contours)):
x,y,w,h = cv2.boundingRect(cam_contours[i])
cv2.rectangle(image_original,(x,y), (x + w, y + h), (0,0,255), 2)
#这边要替换一下,因为scipy.misc中得imsave模块在1.20版本之后就不能用了,这里使用imageio.imwrite函数来进行替换
image_original = cv2.cvtColor(image_original, cv2.COLOR_BGR2RGB)
imageio.imsave(f'{save_path}'+ 'RGB' + f'{name}', image_original)
imageio.imsave(save_path+name, cam)
# evaluate
mae = eval_mae(numpy2tensor(cam), numpy2tensor(gt))
# coarse score
print('[Eval-Test] Dataset: {}, Image: {} ({}/{}), MAE: {}'.format(dataset, name, img_count,
test_loader.size, mae))
img_count += 1
print("\n[Congratulations! Testing Done]")
def load_data(self):
image = self.rgb_loader(self.images[self.index])
image_original = cv2.imread(self.images[self.index])
image = self.transform(image).unsqueeze(0)
gt = self.binary_loader(self.gts[self.index])
name = self.images[self.index].split('/')[-1]
if name.endswith('.jpg'):
name = name.split('.jpg')[0] + '.png'
self.index += 1
return image, gt, name, image_original
推理结果展示:


七、☀️将pth转成onnx,并使用onnxruntime推理☀️
pth转onnx
import torch
import torch.nn
import onnx
from Src.SINet import SINet_ResNet50
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def pth_onnx(pth_route, onnx_route):
device = torch.device('cuda')
model_SINet = SINet_ResNet50(channel=32).cuda()
model_state_dict = torch.load(f'{pth_route}', map_location=device)
model_SINet.load_state_dict(model_state_dict)
model_SINet.eval()
input_names = ['input']
output_names = ['output','output1']
x = torch.randn(1, 3, 352, 352, device=device)
torch.onnx.export(model_SINet, x, f'{onnx_route}', opset_version=12, input_names=input_names, output_names=output_names, verbose='True')
if __name__ == "__main__":
pth_onnx("Snapshot/2020-CVPR-SINet/SINet_40.pth", "SINet.onnx")
使用netron可视化一下看看网络结构:

使用onnxruntime推理
import onnxruntime
import torch
from torchvision.transforms import transforms
import cv2
from PIL import Image
import numpy as np
class onnx_transform():
def __init__(self,image_route, trainsize):
self.image = image_route
self.train_size = trainsize
self.img_transform = transforms.Compose([transforms.Resize((self.train_size, self.train_size)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229,0.224,0.225])])
# device = torch.device('cuda')
def pre_process(self):
img = Image.open(self.image)
img = img.convert('RGB')
img = self.img_transform(img)
return img
if __name__ == "__main__":
#输入图像路径
img_path = "Dataset/TestDataset/Image/COD10K-CAM-1-Aquatic-1-BatFish-5.jpg"
image_original = cv2.imread(img_path)
image_original = cv2.resize(image_original,(352,352))
transform_ = onnx_transform(image_route=img_path, trainsize=352)
input_image = transform_.pre_process()
input_image = input_image.unsqueeze(0)
input_image = input_image.numpy()
input_image = input_image.astype(np.float32)
# input_ = []
# input_.append(input_image)
sess = onnxruntime.InferenceSession("SINet.onnx", providers=['CUDAExecutionProvider'])
input_name = sess.get_inputs()[0].name
output_name = sess.get_outputs()[1].name
prediction = sess.run([output_name],{input_name:input_image})[0]
prediction = torch.from_numpy(prediction)
prediction = prediction.sigmoid().data.cpu().numpy().squeeze()
cam = (prediction - prediction.min()) / (prediction.max() - prediction.min() + 1e-8)
cam *= 255
minval, maxval = 127, 255
ret, thresh = cv2.threshold(cam, minval, maxval, cv2.THRESH_BINARY)
cv2.namedWindow("thresh", cv2.WINDOW_NORMAL)
cv2.imshow("thresh", thresh)
cv2.waitKey(0)
cam_contours, hierarchy = cv2.findContours(np.uint8(thresh), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for i in range(len(cam_contours)):
# area = cv2.contourArea(cam_contours[i])
# rect = cv2.maxAreaRect(cam_contours[i])
# box = cv2.boxPoints(rect)
# box = np.int0(box)
x, y, w, h = cv2.boundingRect(cam_contours[i])
# cv2.drawContours(image_original, [box], 0, (0,0,255), 5)
cv2.rectangle(image_original, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.namedWindow("test", cv2.WINDOW_NORMAL)
cv2.imshow("test", image_original)
cv2.waitKey(0)
# misc.imsave(save_path+name, cam)
# 这边要替换一下,因为scipy.misc中得imsave模块在1.20版本之后就不能用了,这里使用imageio.imwrite函数来进行替换
# image_original = cv2.cvtColor(image_original, cv2.COLOR_BGR2RGB)
# imageio.imsave(f'{save_path}' + 'RGB' + f'{name}', image_original)
# imageio.imsave(save_path + name, cam)
Tips
推理代码部分如有大佬们有更好的写法,欢迎留言交流,促进相互学习,大家好才是真的好。