组合和聚合
不是c++的语法要求,是一种建模思想
目录
1.组合
1. 使用 -- 在一个类中创建另外一个类的对象
代码中的解释:
代码结果:
组合:
2. 使用 -- 在一个类中创建另外一个类的指针
2.使用类定义一个指针 -- 不是创建一个对象
3.聚合
1. 使用
代码中的解释:
结果:
聚合:
1.组合
1. 使用 -- 在一个类中创建另外一个类的对象
就是,一个类中包含有另外一个类创建的对象。(则这两个类就是组合关系)
根据下面代码说明组合的关系。
// 实现创建两个类,使用类文件分离的方式
testCPU.h:
class testCPU
{
public:
// 使用指针传入字符串
testCPU(const char *versionCpu = "intel");
void setCpu(const char* versionCpu);
~testCPU();
private:
string versionCpu; // CPU的类型
};
testComputer.h:
#include "testCPU.h" // 导入Ccpu头文件使用其构造函数
class testComputer
{
public:
// 使用指针传字符串更加的高效,并且可以直接复制给string类型
testComputer(const char *version="len",int memory = 64,const char*
versionCpu = "intel");
~testComputer();
private:
int memory; // 电脑的内存大小
testCPU cpu; // 在testComputer内部创建testCPU类对象
};
testComputer.cpp:
testComputer::testComputer(const char* version, int memory, const char*
versionCpu ){
this->cpu.setCpu(versionCpu);
cout << __FUNCTION__ << endl; // 打印调用函数的名字
}
testComputer::~testComputer() {
cout << __FUNCTION__ << endl;
}
testCPU.cpp:
testCPU::testCPU(const char* versionCpu){
cout << __FUNCTION__ << endl; // 打印函数的名字
}
void testCPU::setCpu(const char* versionCpu) {
this->versionCpu = versionCpu;
}
testCPU::~testCPU(){
cout << __FUNCTION__ << endl; // 打印函数的名字
}
main.cpp:
void test() {
testComputer com; //使用测试函数,测试组合的规则
}
int main(void){
test();
system("pause");
return 0;
}
代码中的解释:
1. 当我们使用string定义字符串时,在传递参数的时候,可以使用char* 来传递一个字符串的地址,然后赋值给string类型的变量。 (更加高效)
2. 我们在Computer类中创建了一个CPU类对象。
3. 在使用有参构造函数的时候,我们使用了默认值,通过指定一个默认值,保证我们在不传递数据的情况下也可以有一个值。 (在使用默认值的情况下,我们可以不传递参数的情况下调用有参构造函数。如上面,testCpu cpu 没有使用参数,但是调用的是有参构造函数,因为我们指定了默认值--但是,有默认构造函数的时候就不能这样写了,会出错)
4. 在构造函数和析构函数中,使用__FUNCTION__宏来输出调用的函数名,用来观察组合的关系。
代码结果:
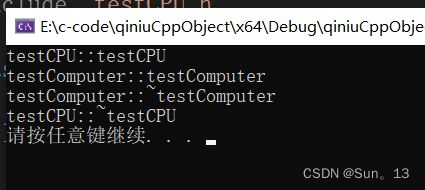
组合:
在一个类中创建另外一个类的对象 ,然后这两个类会同生共死,当包含的类创建对象时,会先创建被包含类的对象,当包含类对象死亡时,被包含的类的对象也死亡 。
就相当于,你买了一台电脑,电脑里面的cpu也一起被你买到,当你不使用这台电脑的时候,里面的cpu你也不用了。
2. 使用 -- 在一个类中创建另外一个类的指针
这种情况, 就是在类中不创建对象,定义一个指向该类的指针。testCPU *cpu。因为定义的是指针,不会调用构造函数,所以要想实现组合。就得在构造函数中,为指针开辟空间。在析构函数中释放指针的空间。
3. 初始化组合的对象
建议使用初始化列表对组合成员进行初始化。
2.使用类定义一个指针 -- 不是创建一个对象
首先,使用类定义一个指针的时候是不会调用构造函数的。因为:它只是定义了一个指针,这个指针指向这个类型,并不表示创建了一个对象。 -- 其实指针是一个整形变量。
这就是为什么我们上面使用在类中定义另外一个类的指针的时候,需要自己在函数中实现开辟空间和释放空间。
3.聚合
1. 使用
// 实现创建两个类,使用类文件分离的方式
testCPU.h:
class testCPU
{
public:
// 使用指针传入字符串
testCPU(const char *versionCpu = "intel");
void setCpu(const char* versionCpu);
~testCPU();
private:
string versionCpu; // CPU的类型
};
testComputer.h:
class testCPU; // 不导入头文件,告诉编译器要使用这个类就行,(因为没有使用类中的内容,只用了类名)
class testComputer
{
public:
testComputer(testCPU *cpu); // 有参数的构造函数,传入指向对应类型的指针
void setCpu(testCPU* cpu);
~testComputer();
private:
testCPU *cpu; // 定义一个指向类的指针,并不创建对象
};
testComputer.cpp:
testComputer::testComputer(testCPU* cpu){
this->cpu = cpu;
cout << __FUNCTION__ << endl;
}
testComputer::~testComputer() {
cout << __FUNCTION__ << endl;
}
void testComputer::setCpu(testCPU* cpu) {
this->cpu = cpu;
}
testCPU.cpp:
testCPU::testCPU(const char* versionCpu){
cout << __FUNCTION__ << endl; // 打印函数的名字
}
void testCPU::setCpu(const char* versionCpu) {
this->versionCpu = versionCpu;
}
testCPU::~testCPU(){
cout << __FUNCTION__ << endl; // 打印函数的名字
}
main.cpp:
#include "testComputer.h"
#include "testCPU.h" // 因为testComputer中不包含此头文件,所以需要再此处包含头文件
using namespace std;
void test(testCPU* cpu) {
testComputer com(cpu); //使用测试函数,测试组合的规则
}
int main(void){
testCPU cpu; // 创建一个cpu的对象
test(&cpu);
system("pause");
return 0;
}
代码中的解释:
1. 聚合的代码和组合的代码CPU那块是一样的,因为他值需要定义一个类。
2. 我们在Computer类中定义了一个CPU类的指针,只使用到了CPU这个类的名称,并没有使用类中的内容,所以我们不需要包含它的头文件,只需要写一个类的声明就行。(更高效--但是需要使用类中内容的时候,就必须得包含了,比如使用构造函数创建对象) 。
3. 和组合不一样,聚合我们需要在主程序创建CPU类对象,所以需要包含其头文件。
4. 我们定义了一个指向CPU类对象的指针,通过构造函数传入,就可以使用这个指针指向传进来的对象。
结果:
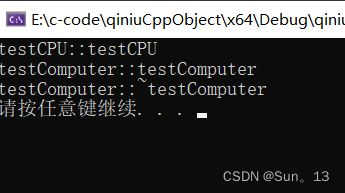
根据结果:看出,当Computer创建的时候,并不会创建CPU,在Computer死亡的时候,也CPU不会死亡。-- 也就是他两的生存和死亡没有关系。
就好比:你买了一个电脑,但是里面没有CPU,但是有一个可以安装CPU的接口,你又另外买了一个CPU,安装在电脑上。当你的电脑不使用了,你的cpu还可以继续使用,你可以将它拆下来安装到别的电脑上继续使用。
聚合:
聚合其实就是,在一个类里面定义一个别的类的指针,然后在需要的时候(可以是初始化的时候,也可以不初始化,在后面使用接口(代码中的setCPU函数)再指向),将这个类内部的指针,指向另外一个类的对象。
所以,聚合就是,类内部有一个指针,用于指向其它类的对象。当我们需要的时候将这个指针,指向这个对象就行。