CNN:Convolutional Neural Network(下)
目录
1 CNN 学到的是什么
1.1 Convolution 中的参数
1.2 FFN 中的参数
1.3 Output
2 Deep Dream
3 Deep Style
4 More Application
4.1 AlphaGo
4.2 Speech
4.3 Text
原视频:李宏毅 2020:Convolutional Neural Network
本博客属于学习笔记,如有问题请大佬指正~
1 CNN 学到的是什么
我们可能会认为神经网络都是一个黑箱(black box),我们没有办法知道也没有办法解释其中的参数,只能知道训练出来的预测效果可能很好。但实际上,我们可以通过一些间接的方法来了解神经网络都学到了什么。
1.1 Convolution 中的参数
继续用上一篇博客的例子举例。假设我们通过梯度下降和反向传播,已经训练好了该 CNN 中的所有参数。在该 CNN 的第二个 Convolution 模块中,每个过滤器(filter)的输出均为一个 11×11 的矩阵(通道数是 25):

我们用以下符号来表示结果矩阵中的每一个值:
![]()
其中,k 表示这是第 k 个过滤器(filter)的输出,i 和 j 分别表示该结果所属的行和列。
为了知道这个训练好的 CNN 到底学到的是什么?我们的逻辑是,固定该 CNN 中某个过滤器(filter)的所有参数,寻找一个输入使得它的输出最大。这样我们便能知道哪些图片和该过滤器(filter)最匹配。这和训练模型时的逻辑正好相反。因为在训练模型时,我们是固定模型的输入,通过更新模型中的参数来使模型的输出最大。
“输出最大” 要具体情况具体分析,也可能是使损失函数最小。
因此,可以定义如下公式来衡量过滤器(filter)的激活程度(degree of the activation):
![]()
我们想要找到这样一个输入:
![]()
它能使过滤器(filter)的激活程度最大。事实上,根据所定义的公式,就是找一个和过滤器(filter)的点积结果最大的输入。再将这个输入以图片的形式表示出来:

这是李宏毅老师截取的前 12 个结果(我们所寻找的输入),它分别对应了 12 个过滤器(filter)所代表和寻找的样式(pattern)。这是因为向量点积结果越大表示两个向量越相似,所以通过观察这些寻找到的输入,我们能间接知道过滤器(filter)所代表和寻找的是哪一种图片样式(pattern)。
比如,第 7 个结果代表了第 7 个过滤器(filter)的工作是寻找图片中的斜纹样式(pattern),这就是该 CNN 的学习成果。
1.2 FFN 中的参数
根据 1.1 节中的逻辑,我们同样可以固定 FFN 中某个神经元的所有参数,通过使该神经元加权和最大来寻找适配该神经元的图片:

我们定义某神经元中的加权和为:
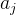
想要找到这样一个输入:
![]()
它能使该神经元的加权和最大。结果如下:

每一张小图均对应了某一个神经元所适配的图片。
1.3 Output
甚至我们还能控制输出层(output layer)的参数,了解该 CNN 眼中的结果长啥样。

假设这里模型处理的是一个数字辨识的分类问题,输出层(output layer)的结果表明输入的图片属于 0-9 这 10 个数字中的哪一个。
现在我们有一个训练好了的 CNN 模型,来看看它眼中的数字长啥样。我们定义输出层中某一神经元的加权和为:

它代表的是输入的图片属于哪一个数字。想要找到这样一个输入:
![]()
由于找到的这张图片在某一数字类别得到了最高分,因此可以认为它就代表了模型眼中某某数字的样子。结果如下:

由此可见,模型学习到的知识和我们人类学习到的知识天差地别。但是,我们也可以添加一些约束,类似于先验知识,来告诉模型什么样的东西才是数字。比如,在一个数字图片中,数字只会占据部分区域。因此,添加约束:
![]()
其中,x_ij 表示图片中第 i 行第 j 列的像素值(由于是黑白图片,所以只会取值 0 或 1)。公式表明,x_ij=1 是一个扣分项。也就是说,我们希望模型用尽量少的黑或白像素点来表示一个数字,从而实现了 “数字只会占据部分区域” 的约束。结果如右图所示:

添加约束后,我们似乎能看出一些数字的轮廓了。当然添加的约束可以不仅限于这一种,还可以要求同色像素点之间要连续等。
2 Deep Dream
后面的内容主要是李宏毅老师讲的一些 CNN 的玩法。
比如这里扔一张原始图片进 CNN,将正的参数设置得更正,负的参数设置得更负,最后再生成一张修改后的图片:
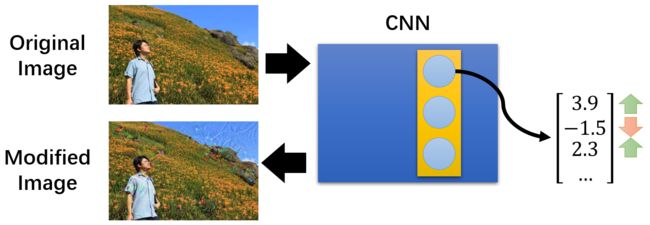
这一节没太听懂,如有错误请指正!
3 Deep Style
第一个 CNN 用于提取图片的内容,它关注的是过滤器(filter)的卷积结果;第二个 CNN 用于提取图片的画风,它关注的是过滤器(filter)之间的相互关系(correlation):

要求第三个 CNN 既匹配第一个 CNN 的过滤器(filter)卷积结果,又要匹配第二个 CNN 的过滤器(filter)之间的相互关系(correlation),最后通过反推生成一张新的图片。
4 More Application
与其说是介绍 CNN 的应用领域,不如说是李宏毅老师告诫我们不要照搬 CNN,而要根据实际场景进行取舍。
4.1 AlphaGo
比如在围棋领域,我们就不能使用 CNN 的 ③ 号功能,即采样原始图片像素的子集以获得更小的图片。因为棋盘中每行每列的棋子都可能参与到一个棋局的形成,擅自去除一些行和列会影响到整盘棋。所以 AlphaGo 中没有使用 Max Pooling 模块:

4.2 Speech
在语音识别中,频谱(spectrogram)也能用 CNN 进行处理。在频谱(spectrogram)中,横轴是时间,纵轴是声音的频率,颜色是声音的能量:
这是李宏毅老师说 “你好” 的频谱,我们只会截取一段频谱(spectrogram)作为 CNN 的输入,即浅色蓝框中的部分。这是因为每个字只会持续一段时间,我们不需要关注整个时间上的频谱。
在处理这一段频谱(spectrogram)时,过滤器(filter)(深色蓝框)只会沿着频率(frequency)的方向移动。这样做的原因有两个:
① 过滤器(filter)沿着时间(time)移动没有太大的帮助。因为在实际应用中,CNN 后面往往会接 LSTM 等模型,这些模型能够提取时间(temporal)信息,所以没有必要再让 CNN 去提取时间(temporal)信息。
② CNN 中过滤器(filter)的本质就是捕捉图片中的一些样式(pattern),虽然男生和女生说 “你好” 的频谱可能长得非常不同,但是在频率方向上存在相同的样式(pattern)。因此,让过滤器(filter)沿着频率(frequency)方向移动很有帮助。
4.3 Text
同样地,在 NLP 领域,过滤器(filter)也只会顺着句子进行移动,而不会把词嵌入(word embedding)截断,进行一个左右横跳:
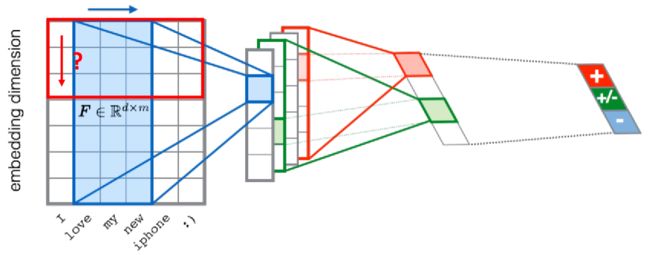
我猜,Speech 和 Text 的例子都属于是一维卷积,即过滤器(filter)只沿着一个方向进行移动,也就是我们常常在论文中看到的 Conv1D 。