携程网景点评论爬虫
携程网景点评论爬虫
找到的携程网爬虫代码有点过时,在网页检查界面找不到文章中说的comment模块,正好在b站看到有最新视频,把博主的代码打了出来,up主的视频链接如下:
【小白操作】Python爬取携程景点评论信息,供学习研究使用!
本人小白,就是单纯地把博主的代码打了出来,然后有一些细微的地方进行了调整,便于代码可以在我的电脑上运行。
爬取成果展示:
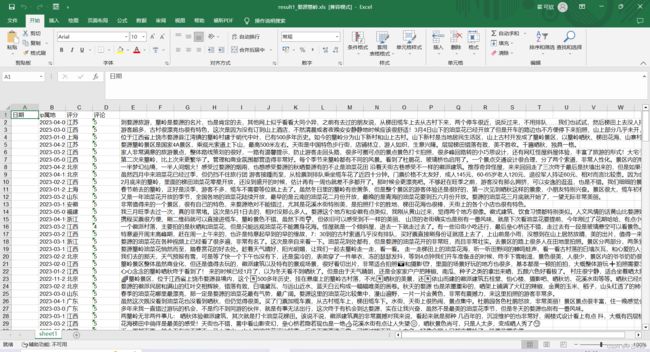
本代码主要运用的是selenium和chromedriver插件,hromedriver插件的下载与配置连接如下:chromedriver下载与安装方法
整体代码如下:
首先导入用到的库:
import re
import random
import time
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
import xlwt
from selenium import webdriver
from selenium.webdriver.common.by import By
import warnings
warnings.filterwarnings('ignore')
然后定义了四个变量来储存评论信息,分别是发表时间、ip属地、评分、评论文本:
timeList=[] #发表时间
ip=[]#ip属地
scoreList=[]#评分
comments=[]#评论文本
数据获取函数:
def getData(driver,ddl1,j):#获取数据
times =driver.find_elements(By.CSS_SELECTOR,'.commentTime')
#就是利用CSS_SELECTOR定位class是commentTime,class的定位用的是.Class,不可以忽略这里的'.'
ip_s = driver.find_elements(By.CSS_SELECTOR, '.ipContent')
scores=driver.find_elements(By.CSS_SELECTOR,'.averageScore')[1:]
comment=driver.find_elements(By.CSS_SELECTOR,'.commentDetail')
for c,ips,t,s in zip(comment,ip_s,times,scores):
try:
timeList.append(re.findall(r'(\d{4}-\d{1,2}-\d{1,2})',t.text)[0])
#利用re.findall找到(\d{4}-\d{1,2}-\d{1,2})这个样子的数据,进行定位并输出,然后储存到前面定义的timeList里
ip.append(re.findall(r":(.*)",ips.text)[0])
scoreList.append(re.findall(r"(.*)分",s.text)[0])
comments.append(c.text)
#print(f"s.text={s.text}")
#print(f"c.text={c.text}")
except:
pass
print(f"共{int(ddl1)}页,第{j}页下载完成...")
主函数:
id =input("请输入景点名称:")
url=input("请输入下载链接:")
i=10
#这里设置了一个爬取最大页数
options=webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('User-Agent=***********')
#这个地方需要更换成自己的User-Agent,使用谷歌浏览器打开的User-Agent
driver=webdriver.Chrome(chrome_options=options)
try:
driver.get(url)
time.sleep(4)
#获取总页码
ddl=driver.find_elements(By.CSS_SELECTOR,'.ant-pagination')
for t in ddl:
ddl1=t.text.split("\n")[-2]
j=1
# print(f"t.text={t.text}")
# print(f"ddl1={ddl1}")
while True:
t1=random.uniform(3,4)
#设置随机间隔时间
getData(driver,ddl1,j)
#获取数据
j+=1
#翻页
element=driver.find_element(By.CSS_SELECTOR,'.ant-pagination-next')
element.click()
if j== int(ddl1) +1 or j>i:
break
time.sleep(t1)
finally:
driver.close()
将数据导出为excel表格
这个的源代码在这里:python实现将数据写入Excel文件中
book=xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet = book.add_sheet('sheet1', cell_overwrite_ok=True)
col=('日期','ip属地','评分','评论')
for i in range(0,4):
sheet.write(0,i,col[i])
for i in range(0,len(timeList)):
sheet.write(i+1,0,timeList[i])
sheet.write(i+1, 1, ip[i])
sheet.write(i+1, 2, scoreList[i])
sheet.write(i+1, 3, comments[i])
book.save(f"./data/result_{id}.xls")
print("*******************done************************")
到这里就完成了
运行代码:
这里就正常输入信息就可以,网站连接就找景点的链接

然后回车稍微等待一会会就会出来数据啦!