go排序sort包详解
sort包提供了排序切片和用户自定义数据集的函数。
目录
- 接口——排序(接口)的三个要素
-
- int类型
- float类型
- string类型
- 基本类型 int 、 float64 和 string 的排序
- 降序排序
- 结构体类型的排序
-
- 结构体排序方法 1——实现接口(最简单的一种)
- 结构体排序方法 2——提供动态的Less方法
- 结构体排序方法 3——扩展初始化函数
- 结构体排序方法 4
- 小结
- 复杂结构排序
-
- `[][]int`
- `[]map[string]int [{"k":0},{"k1":1},{"k2":2]`
- 其他方法
-
- func Sort(data Interface)
- func Stable(data Interface)
- func IsSorted(data Interface) bool
- func Reverse(data Interface) Interface
- func Search(n int, f func(int) bool) int
- 排序算法pdqsort
-
- 选择插入排序,快排,堆排序对比
-
- 插入排序
- 快排
- 堆排序
- 三者对比
- pdqsort算法
接口——排序(接口)的三个要素
go的排序操作需要该类型实现Interface接口,
type Interface interface {
// Len方法返回集合中的元素个数
Len() int
// Less方法报告索引i的元素是否比索引j的元素小
Less(i, j int) bool
// Swap方法交换索引i和j的两个元素
Swap(i, j int)
}
int类型
出厂已经实现了上述接口:
// IntSlice将接口方法附加到[]int,按递增顺序排序。
type IntSlice []int
func (x IntSlice) Len() int { return len(x) }
func (x IntSlice) Less(i, j int) bool { return x[i] < x[j] }
func (x IntSlice) Swap(i, j int) { x[i], x[j] = x[j], x[i] }
// Sort是一种方便的方法:x.Sort()调用Sort(x)。
func (x IntSlice) Sort() { Sort(x) }
// Search返回将SearchInts应用于receiver和x的结果。
func (p IntSlice) Search(x int) int { return SearchInts(p, x) }
int提供的方法:
Ints函数将a排序为递增顺序。
1. func Ints(a []int)
IntsAreSorted检查a是否已排序为递增顺序。
2. func IntsAreSorted(a []int) bool
SearchInts在递增顺序的a中搜索x,返回x的索引。如果查找不到,返回值是x应该插入a的位置(以保证a的递增顺序)不会插入,返回值可以是len(a)。
3. func SearchInts(a []int, x int) int
float类型
出厂也已经实现了接口:
type Float64Slice []float64
func (x Float64Slice) Len() int { return len(x) }
// Less根据排序接口的要求,报告x[i]是否应在x[j]之前排序。
// 请注意,浮点比较本身不是传递关系
// 报告not-a-number(NaN)值的一致顺序。
// 此Less实现将NaN值置于任何其他值之前:
//
// x[i] < x[j] || (math.IsNaN(x[i]) && !math.IsNaN(x[j]))
//
func (x Float64Slice) Less(i, j int) bool { return x[i] < x[j] || (isNaN(x[i]) && !isNaN(x[j])) }
func (x Float64Slice) Swap(i, j int) { x[i], x[j] = x[j], x[i] }
// isNaN是从math包copy过来的,以避免对数学包的依赖。
func isNaN(f float64) bool {
return f != f
}
func (x Float64Slice) Sort() { Sort(x) }
// Search等价于调用SearchFloat64s(p, x)
func (p Float64Slice) Search(x float64) int { return SearchFloat64s(p, x) }
float64提供的方法:
// 递增排序
1.func Float64s(a []float64)
// 判断是否有序
2.func Float64sAreSorted(a []float64) bool
// 返回查找到的x位置
3.func SearchFloat64s(a []float64, x float64) int
string类型
string实现的接口:
// StringSlice attaches the methods of Interface to []string, sorting in increasing order.
type StringSlice []string
func (x StringSlice) Len() int { return len(x) }
func (x StringSlice) Less(i, j int) bool { return x[i] < x[j] }
func (x StringSlice) Swap(i, j int) { x[i], x[j] = x[j], x[i] }
// Sort is a convenience method: x.Sort() calls Sort(x).
func (x StringSlice) Sort() { Sort(x) }
// Search returns the result of applying SearchStrings to the receiver and x.
func (p StringSlice) Search(x string) int { return SearchStrings(p, x) }
string提供的方法:
// 递增排序
1. func Strings(a []string)
// 判断是否有序
2. func StringsAreSorted(a []string) bool
// 在[]string中查找string
3. func SearchStrings(a []string, x string) int
基本类型 int 、 float64 和 string 的排序
- go 分别提供了 sort.Ints() 、 sort.Float64s() 和 sort.Strings() 函数, 默认都是从小到大排序。(但没有 sort.Float32s() 函数)
- 可以借助以上函数快速对基本类型进行排序:
func main() {
intList := [] int {2, 4, 3, 5, 7, 6, 9, 8, 1, 0}
float8List := [] float64 {4.2, 5.9, 12.3, 10.0, 50.4, 99.9, 31.4, 27.81828, 3.14}
// no function : sort.Float32s
// float4List := [] float32 {4.2, 5.9, 12.3, 10.0, 50.4, 99.9, 31.4, 27.81828, 3.14}
stringList := [] string {"a", "c", "b", "d", "f", "i", "z", "x", "w", "y"}
sort.Ints(intList)
sort.Float64s(float8List)
sort.Strings(stringList)
fmt.Printf("%v\n%v\n%v\n", intList, float8List, stringList)
}
或者
ls := sort.Float64Slice{
1.1,
4.4,
5.5,
3.3,
2.2,
}
fmt.Println(ls) //[1.1 4.4 5.5 3.3 2.2]
sort.Float64s(ls)
fmt.Println(ls) //[1.1 2.2 3.3 4.4 5.5]
-----------------------------------------------------
ls := sort.IntSlice{
1,
4,
5,
3,
2,
}
fmt.Println(ls) //[1 4 5 3 2]
sort.Ints(ls)
fmt.Println(ls) //[1 2 3 4 5]
------------------------------------------------
//字符串排序,先比较高位,相同的再比较低位
ls := sort.StringSlice{
"100",
"42",
"41",
"3",
"2",
}
fmt.Println(ls) //[100 42 41 3 2]
sort.Strings(ls)
fmt.Println(ls) //[100 2 3 41 42]
-------------------------------------------------
//汉字排序,依次比较byte大小
ls := sort.StringSlice{
"啊",
"博",
"次",
"得",
"饿",
"周",
}
fmt.Println(ls) //[啊 博 次 得 饿 周]
sort.Strings(ls)
fmt.Println(ls) //[博 周 啊 得 次 饿]
降序排序
- int 、 float64 和 string 都有默认的升序排序函数
- go 中对某个 Type 的对象 obj 排序, 可以使用 sort.Sort(obj) 即可,就是需要对 Type 类型绑定三个方法 : Len() 求长度、 Less(i,j) 比较第 i 和 第 j 个元素大小的函数、 Swap(i,j) 交换第 i 和第 j 个元素的函数。sort 包下的三个类型 IntSlice 、 Float64Slice 、 StringSlice 分别实现了这三个方法, 对应排序的是 [] int 、 [] float64 和 [] string 。如果期望逆序排序, 只需要将对应的 Less 函数简单修改一下即可。
- go 的 sort 包可以使用 sort.Reverse(slice) 来调换 slice.Interface.Less ,也就是比较函数,所以, int 、 float64 和 string 的逆序排序函数可以这么写:
func main() {
intList := [] int {2, 4, 3, 5, 7, 6, 9, 8, 1, 0}
float8List := [] float64 {4.2, 5.9, 12.3, 10.0, 50.4, 99.9, 31.4, 27.81828, 3.14}
stringList := [] string {"a", "c", "b", "d", "f", "i", "z", "x", "w", "y"}
sort.Sort(sort.Reverse(sort.IntSlice(intList)))
sort.Sort(sort.Reverse(sort.Float64Slice(float8List)))
sort.Sort(sort.Reverse(sort.StringSlice(stringList)))
fmt.Printf("%v\n%v\n%v\n", intList, float8List, stringList)
}
结构体类型的排序
- 结构体类型的排序是通过使用 sort.Sort(slice) 实现的, 只要 slice 实现了 sort.Interface 的三个方法就可以。
- 虽然这么说,但是排序的方法却有那么好几种。首先一种就是模拟排序 [] int 构造对应的 IntSlice 类型,然后对 IntSlice 类型实现 Interface 的三个方法。
结构体排序方法 1——实现接口(最简单的一种)
type Person struct {
Name string // 姓名
Age int // 年纪
}
// 按照 Person.Age 从大到小排序
type PersonSlice [] Person
func (a PersonSlice) Len() int { // 重写 Len() 方法
return len(a)
}
func (a PersonSlice) Swap(i, j int){ // 重写 Swap() 方法
a[i], a[j] = a[j], a[i]
}
func (a PersonSlice) Less(i, j int) bool { // 重写 Less() 方法, 从大到小排序
return a[j].Age < a[i].Age
}
func main() {
people := [] Person{
{"zhang san", 12},
{"li si", 30},
{"wang wu", 52},
{"zhao liu", 26},
}
fmt.Println(people)
sort.Sort(PersonSlice(people)) // 按照 Age 的逆序排序
fmt.Println(people)
sort.Sort(sort.Reverse(PersonSlice(people))) // 按照 Age 的升序排序
fmt.Println(people)
}
结构体排序方法 2——提供动态的Less方法
type Person struct {
Name string // 姓名
Age int // 年纪
}
type PersonWrapper struct {
people [] Person
by func(p, q * Person) bool
}
func (pw PersonWrapper) Len() int { // 重写 Len() 方法
return len(pw.people)
}
func (pw PersonWrapper) Swap(i, j int){ // 重写 Swap() 方法
pw.people[i], pw.people[j] = pw.people[j], pw.people[i]
}
func (pw PersonWrapper) Less(i, j int) bool { // 重写 Less() 方法
return pw.by(&pw.people[i], &pw.people[j])
}
func main() {
people := [] Person{
{"zhang san", 12},
{"li si", 30},
{"wang wu", 52},
{"zhao liu", 26},
}
fmt.Println(people)
sort.Sort(PersonWrapper{people, func (p, q *Person) bool {
return q.Age < p.Age // Age 递减排序
}})
fmt.Println(people)
sort.Sort(PersonWrapper{people, func (p, q *Person) bool {
return p.Name < q.Name // Name 递增排序
}})
fmt.Println(people)
}
结构体排序方法 3——扩展初始化函数
type Person struct {
Name string // 姓名
Age int // 年纪
}
type PersonWrapper struct {
people [] Person
by func(p, q * Person) bool
}
type SortBy func(p, q *Person) bool
func (pw PersonWrapper) Len() int { // 重写 Len() 方法
return len(pw.people)
}
func (pw PersonWrapper) Swap(i, j int){ // 重写 Swap() 方法
pw.people[i], pw.people[j] = pw.people[j], pw.people[i]
}
func (pw PersonWrapper) Less(i, j int) bool { // 重写 Less() 方法
return pw.by(&pw.people[i], &pw.people[j])
}
func SortPerson(people [] Person, by SortBy){ // SortPerson 方法
sort.Sort(PersonWrapper{people, by})
}
func main() {
people := [] Person{
{"zhang san", 12},
{"li si", 30},
{"wang wu", 52},
{"zhao liu", 26},
}
fmt.Println(people)
sort.Sort(PersonWrapper{people, func (p, q *Person) bool {
return q.Age < p.Age // Age 递减排序
}})
fmt.Println(people)
SortPerson(people, func (p, q *Person) bool {
return p.Name < q.Name // Name 递增排序
})
fmt.Println(people)
}
结构体排序方法 4
type Person struct {
Name string
Weight int
}
type PersonSlice []Person
func (s PersonSlice) Len() int { return len(s) }
func (s PersonSlice) Swap(i, j int) { s[i], s[j] = s[j], s[i] }
type ByName struct{ PersonSlice } // 将 PersonSlice 包装起来到 ByName 中
func (s ByName) Less(i, j int) bool { return s.PersonSlice[i].Name < s.PersonSlice[j].Name } // 将 Less 绑定到 ByName 上
type ByWeight struct{ PersonSlice } // 将 PersonSlice 包装起来到 ByWeight 中
func (s ByWeight) Less(i, j int) bool { return s.PersonSlice[i].Weight < s.PersonSlice[j].Weight } // 将 Less 绑定到 ByWeight 上
func main() {
s := []Person{
{"apple", 12},
{"pear", 20},
{"banana", 50},
{"orange", 87},
{"hello", 34},
{"world", 43},
}
sort.Sort(ByWeight{s})
fmt.Println("People by weight:")
printPeople(s)
sort.Sort(ByName{s})
fmt.Println("\nPeople by name:")
printPeople(s)
}
func printPeople(s []Person) {
for _, o := range s {
fmt.Printf("%-8s (%v)\n", o.Name, o.Weight)
}
}
小结
- 第一种排序对只根据一个字段的比较合适, 另外三个是针对可能根据多个字段排序的。
- 2、 3 没有太大的差别, 3 只是简单封装了一下。
复杂结构排序
[][]int
type testSlice [][]int
func (l testSlice) Len() int { return len(l) }
func (l testSlice) Swap(i, j int) { l[i], l[j] = l[j], l[i] }
func (l testSlice) Less(i, j int) bool { return l[i][1] < l[j][1] }
func main() {
ls := testSlice{
{1,4},
{9,3},
{7,5},
}
fmt.Println(ls) //[[1 4] [9 3] [7 5]]
sort.Sort(ls)
fmt.Println(ls) //[[9 3] [1 4] [7 5]]
}
[]map[string]int [{"k":0},{"k1":1},{"k2":2]
type testSlice []map[string]float64
func (l testSlice) Len() int { return len(l) }
func (l testSlice) Swap(i, j int) { l[i], l[j] = l[j], l[i] }
func (l testSlice) Less(i, j int) bool { return l[i]["a"] < l[j]["a"] } //按照"a"对应的值排序
func main() {
ls := testSlice{
{"a":4, "b":12},
{"a":3, "b":11},
{"a":5, "b":10},
}
fmt.Println(ls) //[map[a:4 b:12] map[a:3 b:11] map[a:5 b:10]]
sort.Sort(ls)
fmt.Println(ls) //[map[a:3 b:11] map[a:4 b:12] map[a:5 b:10]]
}
其他方法
func Sort(data Interface)
对实现接口的类型进行排序
tmp:=[]int{1,2,3,5,6}
sort.Sort(sort.IntSlice(tmp))
func Stable(data Interface)
Stable排序data,并保证排序的稳定性,相等元素的相对次序不变。
tmp:=[]int{1,2,3,5,6}
sort.Stable(sort.IntSlice(tmp))
func IsSorted(data Interface) bool
IsSorted报告data是否已经被排序。
func Reverse(data Interface) Interface
Reverse包装一个Interface接口并返回一个新的Interface接口,对该接口排序可生成递减序列。
s := []int{5, 2, 6, 3, 1, 4} // unsorted
sort.Sort(sort.Reverse(sort.IntSlice(s)))
fmt.Println(s)
type doubleArray [][]int
func (d doubleArray)Len() int{ return len(d) }
func (d doubleArray) Less(i, j int) bool { return i<j }
func (d doubleArray) Swap(i, j int) { d[i], d[j] = d[j], d[i] }
func main(){
tmp:=[][]int{
[]int{1},
[]int{1,2},
[]int{1,2,3},
}
res:=sort.Reverse(doubleArray(tmp))
sort.Sort(res)
fmt.Println(res)
// &{[[1 2 3] [1 2] [1]]}
}
func Search(n int, f func(int) bool) int
Search函数采用二分法搜索找到[0, n)区间内最小的满足f(i)==true的值i。
func main(){
tmp:=[]int{1,2,6,3,5,6}
res:=sort.Search(len(tmp), func(i int) bool {
return tmp[i]==3
})
fmt.Println(res)
// 3
}
排序算法pdqsort
pdqsort 是一种用于排序的 C++ 算法,旨在在许多情况下作为传统的 std::sort 算法的更快替代方案。它的全名是“Pattern-Defeating QuickSort”,由 Orson Peters 创建。pdqsort 的主要思想是最小化比较和分支预测错误的数量,这些都是排序算法中常见的瓶颈。
以下是 pdqsort 的一些关键特点和方面:
-
Pattern Defeating 模式克服:
pdqsort旨在克服实际数据集中可能出现的模式。传统的排序算法(如快速排序和归并排序)在某些输入模式下表现不佳,例如部分有序或逆序的数组。pdqsort设计得更有效地处理这些模式。 -
自适应性:
pdqsort是自适应的,意味着它会根据排序的数据自动调整其行为。它利用数据中已有的顺序来减少比较次数,从而减少排序时间。 -
内存效率:与一些其他自适应排序算法(如 Timsort)相比,
pdqsort使用较少的内存资源。在对大型数据集进行排序时,这可能非常有益。 -
高缓存友好性:
pdqsort的设计考虑了缓存性能。它旨在最小化缓存未命中和分支预测错误,这可以显著影响排序算法的运行时间。 -
随机化的轴元素选择:与快速排序类似,
pdqsort也使用轴元素来将数组划分为较小的段。但是,pdqsort中的轴元素选择是随机的,以减少对抗性输入所导致的性能下降。 -
插入排序:对于小的子数组,
pdqsort切换到插入排序,以进一步优化排序过程。由于插入排序的开销较低,对于小数组来说效率很高。 -
避免分支:算法设计旨在尽可能避免分支,这有助于减少分支预测错误,从而降低排序过程的速度。
-
稳定排序:默认情况下,
pdqsort不是稳定的,这意味着它不保证相等元素的顺序。然而,可以使用一个可选的标志使其保持稳定,但会稍微降低性能。
以下是 pdqsort 的简化流程:
- 如果数组大小小于某个阈值,切换到插入排序。
- 随机选择一个轴元素。
- 将数组划分为三个部分:小于轴元素的元素、等于轴元素的元素和大于轴元素的元素。
- 递归地对小于轴元素和大于轴元素的部分进行排序。
- 重复上述过程,直到整个数组排序完成。
选择插入排序,快排,堆排序对比
插入排序
插入排序是一种简单直观的排序算法,它逐步构建有序序列。这种算法的工作方式类似于我们整理一手扑克牌,一张一张地将牌插入到已经有序的牌堆中。插入排序的主要思想是,将未排序的元素逐个插入到已排序的部分中,以构建最终有序的数组。
以下是插入排序的详细步骤:
-
初始状态:将第一个元素视为已排序部分,其余元素视为未排序部分。
-
从未排序部分选择元素:从未排序的部分中依次选择一个元素。
-
插入元素到已排序部分:将选中的未排序元素插入到已排序部分的适当位置,使得已排序部分仍然保持有序。
-
重复步骤 2 和 3:重复选择未排序部分中的元素并将其插入到已排序部分,直到所有元素都被插入到已排序部分。
以下是插入排序的伪代码表示:
InsertionSort(arr):
for i from 1 to length(arr) - 1:
currentElement = arr[i]
j = i - 1
while j >= 0 and arr[j] > currentElement:
arr[j + 1] = arr[j]
j = j - 1
arr[j + 1] = currentElement
插入排序的特点:
-
稳定性:插入排序是稳定的,即相等元素的相对顺序不会发生改变。
-
原地排序:插入排序只需要常数级别的额外空间来存储临时变量,因此可以在原数组上进行排序,不需要额外的内存空间。
-
最佳情况时间复杂度:如果输入数组已经几乎有序,插入排序的时间复杂度可以接近O(n),其中n是元素的数量。
-
最坏情况时间复杂度:如果输入数组完全逆序,插入排序的时间复杂度为O(n^2)。
插入排序在小型数据集上性能良好,而在大型数据集上通常会比其他高级排序算法(如归并排序或快速排序)慢,因为它的时间复杂度较高。然而,在某些情况下,插入排序的优点在于它具有相对低的常数因子,因此对于部分有序的数据集,插入排序可能比其他算法更快。
插入排序是一种简单但有用的排序算法,特别适用于小规模或基本有序的数据集。

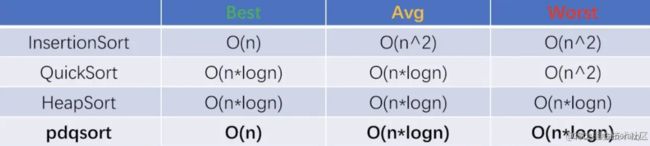
时间复杂度:
最优:O(n)
平均:O(n^2)
最差:O(n^2)
快排
快速排序(QuickSort)是一种高效的分治排序算法,它以递归的方式将一个数组分成较小和较大的子数组,然后对这些子数组进行排序。快速排序的核心思想是选择一个轴元素(pivot),然后将数组分为两个子数组,一个包含所有小于轴元素的值,另一个包含所有大于轴元素的值,最后递归地对子数组进行排序。
以下是快速排序的详细步骤:
-
选择轴元素:从数组中选择一个轴元素。选择轴元素的方式可以有多种,常见的方法是随机选择、选择第一个元素或选择中间元素。
-
分区:将数组分为两个部分,一部分包含小于轴元素的值,另一部分包含大于轴元素的值。这个过程称为分区,通常通过移动元素来实现。
-
递归排序子数组:对两个子数组递归地应用快速排序算法,即对小于轴元素的子数组和大于轴元素的子数组进行排序。
-
合并:合并已排序的子数组,将小于轴元素的子数组、轴元素本身和大于轴元素的子数组合并成一个有序的数组。
以下是快速排序的伪代码表示:
QuickSort(arr, low, high):
if low < high:
pivotIndex = Partition(arr, low, high)
QuickSort(arr, low, pivotIndex - 1)
QuickSort(arr, pivotIndex + 1, high)
Partition(arr, low, high):
pivot = arr[high] // Choose the pivot as the last element
i = low - 1
for j from low to high - 1:
if arr[j] <= pivot:
i = i + 1
Swap(arr[i], arr[j])
Swap(arr[i + 1], arr[high])
return i + 1
快速排序的特点:
-
原地排序:快速排序是原地排序,它只需要常数级别的额外空间用于交换元素。
-
不稳定性:在交换元素的过程中,可能会破坏相等元素的相对顺序,因此快速排序是不稳定的排序算法。
-
平均时间复杂度:在平均情况下,快速排序的时间复杂度为O(n log n),其中n是元素数量。这使得它成为大多数实际应用场景中最快的排序算法之一。
-
最坏情况时间复杂度:在最坏情况下,即数组已经有序或接近有序时,快速排序的时间复杂度为O(n^2),但通过合理的选择轴元素和随机化等方法,可以减少最坏情况的发生。
快速排序是一种高效的排序算法,特别适用于大规模数据集的排序。但需要注意的是,选择不当的轴元素或数据集的分布可能会影响性能。
时间复杂度:
最优:O(nlogn)
平均:O(nlogn)
最差:O(n^2)
堆排序
堆排序(Heap Sort)是一种基于堆数据结构的排序算法,它利用了堆的性质来进行排序。堆是一种特殊的树状数据结构,具有以下特点:在最大堆中,父节点的值总是大于或等于其子节点的值;在最小堆中,父节点的值总是小于或等于其子节点的值。堆排序的核心思想是通过构建堆,将最大(或最小)元素移到数组的末尾,然后从堆中移除它,再继续重复这个过程,直到所有元素都有序。
以下是堆排序的详细步骤:
-
构建堆:将待排序的数组构建成一个堆。可以根据需要选择构建最大堆或最小堆。
-
取出根节点:从堆中取出根节点(堆顶元素),即最大(或最小)元素。
-
重新调整堆:在取出根节点后,将堆的最后一个元素移到根节点的位置,然后通过向下调整(Heapify)的方式,使得堆继续满足堆的性质。
-
重复步骤 2 和 3:重复取出根节点、重新调整堆的步骤,直到堆中的所有元素都被取出,得到一个有序数组。
以下是堆排序的伪代码表示:
HeapSort(arr):
BuildHeap(arr) // 构建最大堆
for i from length(arr) - 1 down to 1:
Swap(arr[0], arr[i]) // 将最大元素移到末尾
Heapify(arr, 0, i) // 重新调整堆
BuildHeap(arr):
n = length(arr)
for i from n/2 - 1 down to 0:
Heapify(arr, i, n)
Heapify(arr, index, heapSize):
largest = index
left = 2 * index + 1
right = 2 * index + 2
if left < heapSize and arr[left] > arr[largest]:
largest = left
if right < heapSize and arr[right] > arr[largest]:
largest = right
if largest != index:
Swap(arr[index], arr[largest])
Heapify(arr, largest, heapSize)
堆排序的特点:
-
原地排序:堆排序是原地排序,它只需要常数级别的额外空间用于交换元素。
-
不稳定性:由于在堆的调整过程中,可能破坏相等元素的相对顺序,因此堆排序是不稳定的排序算法。
-
平均和最坏情况时间复杂度:堆排序的平均和最坏情况时间复杂度均为O(n log n),其中n是元素数量。
-
适用性:堆排序在大规模数据集中表现良好,但在常数因子方面通常比快速排序稍慢。然而,堆排序的一个优点是它对于输入数据的分布不敏感,始终保持O(n log n)的时间复杂度。
堆排序是一种高效的排序算法,特别适用于需要稳定的时间复杂度,并且对额外内存空间要求较低的场景。
时间复杂度:
最优:O(nlogn)
平均:O(nlogn)
最差:O(nlogn)
三者对比

根据序列元素排列情况划分:
- 完全随机的情况(random)
- 有序/逆序的情况(sorted/reverse)
- 元素重复度较高的情况(mod8)
在此基础上,还需要根据序列长度的划分(16/128/1024)
Benchmark-random:
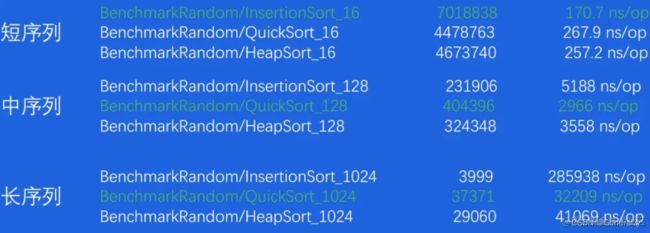
Benchmark-sorted

- 所有短序列和元素有序情况下,插入排序性能最好
- 在大部分的情况下,快速排序有较好的综合性能
- 几乎在任何情况下,堆排序的表现都比较稳定
pdqsort算法
// pdqsort_func 对数据[a:b]进行排序。
// 该算法基于模式克服快速排序(pdqsort)
// pdqsort 论文:https://arxiv.org/pdf/2106.05123.pdf
// C++ 实现:https://github.com/orlp/pdqsort
// Rust 实现:https://docs.rs/pdqsort/latest/pdqsort/
// limit 在回退到堆排序之前,limit是允许的不良(非常不平衡)轴元素数量(在排序算法中,轴元素是用来划分数据集的元素,例如在快速排序中用来划分较大和较小元素的基准元素。)。
func pdqsort_func(data lessSwap, a, b, limit int) {
// 插入排序极限:12
const maxInsertion = 12
var (
wasBalanced = true // whether the last partitioning was reasonably balanced
wasPartitioned = true // whether the slice was already partitioned
)
for {
length := b - a
// 当长度不超12时采用插入排序
if length <= maxInsertion {
insertionSort_func(data, a, b)
return
}
// 回退到堆排序
if limit == 0 {
heapSort_func(data, a, b)
return
}
// If the last partitioning was imbalanced, we need to breaking patterns.
if !wasBalanced {
breakPatterns_func(data, a, b)
limit--
}
pivot, hint := choosePivot_func(data, a, b)
if hint == decreasingHint {
reverseRange_func(data, a, b)
// The chosen pivot was pivot-a elements after the start of the array.
// After reversing it is pivot-a elements before the end of the array.
// The idea came from Rust's implementation.
pivot = (b - 1) - (pivot - a)
hint = increasingHint
}
// The slice is likely already sorted.
if wasBalanced && wasPartitioned && hint == increasingHint {
if partialInsertionSort_func(data, a, b) {
return
}
}
// Probably the slice contains many duplicate elements, partition the slice into
// elements equal to and elements greater than the pivot.
if a > 0 && !data.Less(a-1, pivot) {
mid := partitionEqual_func(data, a, b, pivot)
a = mid
continue
}
mid, alreadyPartitioned := partition_func(data, a, b, pivot)
wasPartitioned = alreadyPartitioned
leftLen, rightLen := mid-a, b-mid
balanceThreshold := length / 8
if leftLen < rightLen {
wasBalanced = leftLen >= balanceThreshold
pdqsort_func(data, a, mid, limit)
a = mid + 1
} else {
wasBalanced = rightLen >= balanceThreshold
pdqsort_func(data, mid+1, b, limit)
b = mid
}
}
}
时间复杂度:
其他排序算法:TimSort