JVM:性能监控工具分析和线上问题排查实践
前言
在日常开发过程中,多少都会碰到一些jvm相关的问题,比如:内存溢出、内存泄漏、cpu利用率飙升到100%、线程死锁、应用异常宕机等。
在这个日益内卷的环境,如何运用好工具分析jvm问题,成为每个java攻城狮必备的技能。所以白梦特意整理了jdk自带分析工具的使用,以及常见的jvm问题分析和处理。
一、jdk自带分析工具介绍
jps(Java Process Status):
用途: 用于列出当前系统中所有正在运行的 Java 进程,并显示其进程ID以及启动时的类名或 JAR 文件。
基本用法:
jps [ options ] [ hostid ]
常见选项:
-q: 仅显示进程ID,不显示类名或 JAR 文件。-m: 输出主类的全名,如果进程是通过 main 方法启动的话。-l: 输出主类或 JAR 文件的全路径名。-v: 输出传递给 JVM 的参数。
比如输出所有正在运行的进程:

jstat(JVM Statistics Monitoring Tool):
用途: 用于监控 JVM 的各种统计信息,如堆内存使用、垃圾回收、类加载等。
基本用法:
jstat [ options ] [ interval [ count ]]
jps命令查看。interval:采样时间间隔(以毫秒为单位)。count:采样次数,表示统计信息将被输出的次数。
常见选项:
-class:显示类加载器统计信息。-compiler:显示即时编译器统计信息。-gc:显示垃圾回收统计信息,包括各代的统计信息和总的垃圾回-gccapacity:显示堆内存各区域的容量统计信息。-gccause:显示垃圾回收的原因统计信息。-gcmetacapacity:显示元空间和压缩类空间的统计信息。-gcnew:显示新生代垃圾回收统计信息。-gcnewcapacity:显示新生代堆内存各区域的容量统计信息。-gcold:显示老年代垃圾回收统计信息。-gcoldcapacity:显示老年代堆内存各区域的容量统计信息。-gcutil:显示各代垃圾回收的百分比信息。-printcompilation:显示已经被编译的方法的信息。
比如想看垃圾回收统计数据,执行jstat -gc 7499命令
![]()
对应结果字段:
S0C: Survivor 0(S0)容量(以千字节为单位) - 用于对象的Survivor Space 0的总空间。S1C: Survivor 1(S1)容量(以千字节为单位) - 用于对象的Survivor Space 1的总空间。S0U: Survivor 0(S0)使用量(以千字节为单位) - 当前由对象使用的Survivor Space 0的量。S1U: Survivor 1(S1)使用量(以千字节为单位) - 当前由对象使用的Survivor Space 1的量。EC: Eden空间容量(以千字节为单位) - 用于对象的Eden空间的总空间。EU: Eden空间使用量(以千字节为单位) - 当前由对象使用的Eden空间的量。OC: 老年代空间容量(以千字节为单位) - 用于对象的老年代的总空间。OU: 老年代空间使用量(以千字节为单位) - 当前由对象使用的老年代的量。MC: 元空间容量(以千字节为单位) - Metaspace的总容量(用于存储类元数据的非堆内存)。MU: 元空间使用量(以千字节为单位) - 当前由对象使用的Metaspace的量。CCSC: 压缩类空间容量(以千字节为单位) - 压缩类空间的总容量。CCSU: 压缩类空间使用量(以千字节为单位) - 当前由对象使用的压缩类空间的量。YGC: Young代垃圾回收次数 - Young代被垃圾回收的次数。YGCT: Young代垃圾回收时间(以秒为单位) - 在Young代垃圾回收上花费的总时间。FGC: Full垃圾回收次数 - 发生Full(老年代)垃圾回收的次数。FGCT: Full垃圾回收时间(以秒为单位) - 在Full垃圾回收上花费的总时间。CGC: 编译次数 - JVM被要求编译方法的次数。CGCT: 编译时间(以秒为单位) - 在编译上花费的总时间。GCT: 总垃圾回收时间(以秒为单位) - Young和Full垃圾回收时间的总和。
jinfo(Java Configuration Info):
用途: 用于查看和调整 JVM 的配置信息,包括系统属性、JVM 参数等。
基本用法:
jinfo [ options ]
jps命令查看。
常见选项:
-flags:显示虚拟机启动时的命令行标志和系统属性。-sysprops:显示 Java 系统属性的值。
假如想看某个jar启动时用到的哪些参数,可以执行jinfo -flags xxxx。
![]()
jmap(Java Memory Map):
用途: 用于生成堆转储快照,以便分析 Java 进程的内存使用情况。
基本用法:
jmap [ options ]
jps命令查看。
常见选项:
-
-clstats:
连接到运行中的 Java 进程并打印类加载器的统计信息。该选项显示有关类加载器及其加载的类的信息。 -
-finalizerinfo:连接到运行中的 Java 进程并打印等待终结的对象信息。这会显示等待执行 finalize() 方法的对象的数量和相关信息。 -
-histo[:[:连接到运行中的 Java 进程并打印 Java 对象堆的直方图(histogram)。该选项显示不同类型对象的数量和占用的内存。]] histo-options可选参数包括:live: 仅统计活动对象。all: 统计所有对象。file=: 将直方图数据写入指定文件。parallel=: 用于堆检查的并行线程数。
-
-dump::连接到运行中的 Java 进程并生成 Java 堆的转储(dump)。可以选择性地指定转储选项,例如 live 以仅转储活动对象,all 以转储整个堆。dump-options可选参数包括:live: 仅转储活动对象。all: 转储整个堆。format=b: 以二进制格式转储。file=: 将转储数据写入指定文件。gz=: 如果指定,以给定的压缩级别以 gzip 格式进行转储
比如发生oom后要导出dump文件,执行jmap -dump:all,format=b,file=heapdump.bin 123456,其中123456是进程pid。生成的文件拖进visualVM进行下一步分析。参考下面讲到的内存溢出排查。
![]()
jstack(Java Stack Trace):
用途: 用于生成线程转储快照,以便分析 Java 进程中的线程状态和堆栈信息。
基本用法:
jstack [ options ]
jps命令查看。
常见选项:
-l:长格式选项主要关注锁相关的信息,包括线程所拥有的锁以及线程等待的锁。对于识别锁竞争和死锁等问题非常有用。-e:拓展格式选项显示线程的更多信息,包括线程的状态、等待条件、锁的拥有者等。它的焦点更广泛,包括线程的整体状态和执行信息。
二、问题排查
1、内存溢出排查
内存溢出常见的原因之一是内存泄漏。当应用程序中的对象不再被引用,但仍然占用内存时,就会发生内存泄漏。如果这种情况发生得足够频繁,最终会导致整个堆内存耗尽。
还有其他原因例如:不恰当的缓存使用、限递归或循环、大对象、过度使用线程、JVM参数配置堆内存设置太小等。下面模拟内存溢出问题的排查。
首先写一个简单的内存溢出的springboot代码。
@GetMapping("/demo3")
public void demo3() {
List<CustomObj> list = new ArrayList<>();
while (true) {
list.add(new CustomObj());
}
}
public class CustomObj{
}
启动项目时,加上如下代码,让程序内存溢出时生成日志
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/to/dumpfile
当然,如果项目没有配置HeapDumpOnOutOfMemoryError,也可先用jps查看java进程pid,再使用jmap手动导出。
jmap -dump:all,format=b,file=heapdump.bin 123456
使用jmap(特别是线上)时的注意事项:
- 生成堆转储文件可能对应用程序的性能产生一些短暂的影响,因为在生成转储文件时,Java 虚拟机会停止应用程序的执行一小段时间。
- 堆转储文件可能非常大,因此在生成之前,请确保有足够的磁盘空间。
启动项目后,访问controller方法,程序会抛出java.lang.OutOfMemoryError: Java heap space异常,并生成hropf文件。
![]()
导入到visualVM工具分析,VisualVM是一款由 Oracle 提供的免费的、功能强大的 Java 虚拟机监控、故障诊断和性能调优工具。它为开发者提供了一个集成的可视化界面,用于监控和分析 Java 应用程序的运行时行为。
图中可以看出CustomObj对象数量占比高达93.3%,并且类大小占到了68.3%。
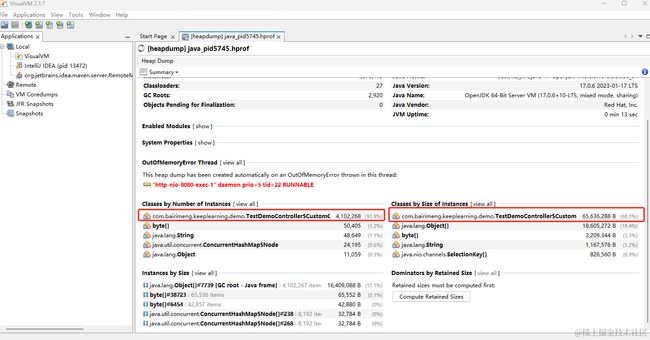
左上角选择Threads,展开红色实例,找到出现异常的代码位置

同理,内存泄漏的的排查也可以使用以上的方式。
2、CPU利用率飙升到100%
CPU100%有以下常见原因导致的:
- 无限循环或死循环: 如果程序中存在无限循环或者死循环,会导致程序一直在执行某个循环,使得CPU占用率保持在高水平。
- 线程问题: 多线程程序中,如果线程没有正确地被管理或者存在死锁,会导致CPU资源被不断占用。
- 内存泄漏: 如果程序中存在内存泄漏,即无用的对象无法被垃圾回收机制释放,最终导致内存耗尽,引起频繁的垃圾回收,从而影响CPU性能。
- 过多的IO操作: 如果程序中涉及大量的IO操作,并且这些IO操作被频繁调用而且没有得到有效的处理,可能导致CPU占用率上升。
- 大数据量的计算: 大规模的数据处理或者复杂的计算也可能导致CPU占用率飙升。
写一段代码模拟大量创建对象,并且频繁垃圾回收。
@GetMapping("/demo5")
public void demo5() {
while (true) {
allocateMemory();
triggerGarbageCollection();
}
}
private static void allocateMemory() {
// 模拟内存分配
for (int i = 0; i < 100000; i++) {
Object obj = new Object();
}
}
private static void triggerGarbageCollection() {
// 模拟垃圾回收
System.gc();
}
首先top命令查看cpu占用率,发现占用率高达98.3%

接着jstat -gcutil 3253 1000查看垃圾回收信息。FGC表示FullGC回收次数,FGCT表示FullGC回收上花费的总时间。
可以看出程序一直在频繁的进行FullGC,而YGC基本不变,几乎可以确定是FullGC导致CPU占用100%。

输入命令top Hp 3253找出进程下哪个线程占用cpu高
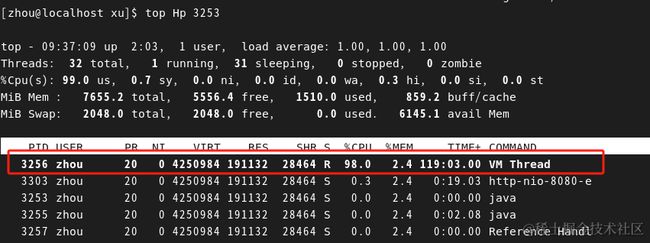
发现是一个VM Thread一直占用着资源,VM Thread 在执行与垃圾收集相关的底层任务时,可能导致 CPU 使用率升高。
3、线程死锁
先写一段模拟线程死锁的demo:
private static Object resource1 = new Object();
private static Object resource2 = new Object();
@GetMapping("/demo4")
public void demo4(){
Thread thread1 = new Thread(() -> {
synchronized (resource1) {
System.out.println("Thread 1: Holding lock 1...");
try {
Thread.sleep(1000); // Introducing delay to make deadlock more likely
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread 1: Waiting for lock 2...");
synchronized (resource2) {
System.out.println("Thread 1: Holding lock 1 and lock 2...");
}
}
});
Thread thread2 = new Thread(() -> {
synchronized (resource2) {
System.out.println("Thread 2: Holding lock 2...");
try {
Thread.sleep(1000); // Introducing delay to make deadlock more likely
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread 2: Waiting for lock 1...");
synchronized (resource1) {
System.out.println("Thread 2: Holding lock 2 and lock 1...");
}
}
});
thread1.start();
thread2.start();
}
执行后控制台会输出线程互相等待的信息:
输入jstack -l 9085输出线程状态信息
Found one Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor 0x00007f33cc2fc9b0 (object 0x00000000fb9ccec0, a java.lang.Object),
which is held by "Thread-2"
"Thread-2":
waiting to lock monitor 0x00007f33bc0d6c10 (object 0x00000000fb944b68, a java.lang.Object),
which is held by "Thread-1"
Java stack information for the threads listed above:
===================================================
"Thread-1":
at com.bairimeng.keeplearning.demo.TestDemoController.lambda$demo4$3(TestDemoController.java:94)
- waiting to lock <0x00000000fb9ccec0> (a java.lang.Object)
- locked <0x00000000fb944b68> (a java.lang.Object)
at com.bairimeng.keeplearning.demo.TestDemoController$$Lambda$756/0x0000000801050748.run(Unknown Source)
at java.lang.Thread.run(java.base@17.0.6/Thread.java:833)
"Thread-2":
at com.bairimeng.keeplearning.demo.TestDemoController.lambda$demo4$4(TestDemoController.java:111)
- waiting to lock <0x00000000fb944b68> (a java.lang.Object)
- locked <0x00000000fb9ccec0> (a java.lang.Object)
at com.bairimeng.keeplearning.demo.TestDemoController$$Lambda$757/0x0000000801050968.run(Unknown Source)
at java.lang.Thread.run(java.base@17.0.6/Thread.java:833)
Found 1 deadlock.
从上面日志看出线程1内存地址为0x00000000fb9ccec0,线程2内存地址为0x00000000fb944b68。
线程1 locked <0x00000000fb944b68>,表示当前已经被线程2加锁了,需要等待线程2释放锁。
线程2 locked <0x00000000fb9ccec0>,表示当前已经被线程1加锁了,需要等待线程1释放锁。
两者相互等待,导致了死锁,并且可以在日志中,找到第94和111行锁代码位置。
附加: 假如安装了阿里的arthas工具,更加方便进行分析。
启动后输入thread,看到两个线程处于BLOCKED阻塞状态
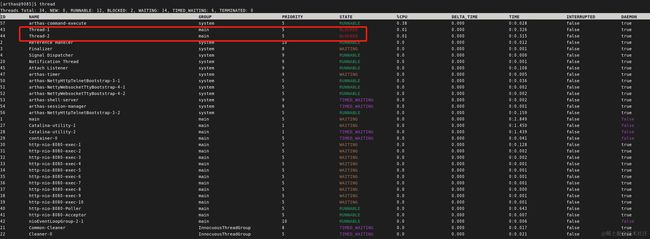
这样还不能清楚知道是否造成死锁,以及死锁的位置。接着输入thread -b

这次就能直接定位到死锁是在代码94行,并且从红色部分<---- but blocks 1 other threads!看出阻塞的线程数量。
结束
至此,jdk分析工具和jvm问题分析已经介绍完毕,点个赞再走啦!