【JavaSE学习】04-1Java高级(Stream流、异常处理、日志技术)
JavaSE(B站黑马)学习笔记
01Java入门
02数组、方法
03面向对象&Java语法
04-1Java高级(Stream流、异常处理、日志技术)
04-2Java高级(文件处理-IO流)
04-3Java高级(多线程、网络编程)
04-4Java高级(单元测试、反射、注解、动态代理、XML)
05-1常用API
05-2常用API(集合)
文章目录
- JavaSE(B站黑马)学习笔记
- 前言
- 04-1Java高级(Stream流、异常处理、日志技术)
- Stream流
-
- Stream流的概述
- Stream流的获取
- Stream流的常用API
- Stream流的综合应用(案例)
- 收集Stream流
- 异常处理
-
- 异常概述、体系
- 常见运行时异常
- 常见编译时异常
- 异常的默认处理流程
- 编译时异常的处理机制
- 运行时异常的处理机制
- 异常处理使代码更稳健的案例
- 日志技术
-
- 日志是什么
- 日志技术体系、Logback概述
- Logback快速入门
- Logback配置详解
-
- 输出位置、格式设置
- 日志级别设置
- 注:
前言
JavaSE(B站黑马)学习笔记 04-1Java高级(Stream流、异常处理、日志技术)
04-1Java高级(Stream流、异常处理、日志技术)
Stream流
Stream流的概述
什么是Stream流?
- 在Java 8中,得益于Lambda所带来的函数式编程, 引入了一个全新的Stream流概念。
- 目的:用于简化集合和数组操作的API。

案例

未使用Stream流实现

使用Stream流实现

Stream流的思想


Stream流的获取
Stream操作集合或者数组的第一步是先得到Stream流,然后才能使用流的功能。
Stream流的三类方法
-
获取Stream流
- 创建一条流水线,并把数据放到流水线上准备进行操作
-
中间方法
- 流水线上的操作。一次操作完毕之后,还可以继续进行其他操作。()
-
终结方法
- 一个Stream流只能有一个终结方法,是流水线上的最后一个操作
集合获取Stream流的方式
- 可以使用Collection接口中的默认方法stream()生成流

数组获取Stream流的方式


Stream流的常用API
Stream流的常用API(中间操作方法)

| Stream map(Function mapper); | map加工方法:第一个参数是原材料 -> 第二个参数是加工后的结果 |
|---|---|
| Optional max(Comparator comparator) | 制定大小规则返回最大值,返回一个Optional对象,可用其对象的get方法获取这个值 |
注意:
- 中间方法也称为非终结方法,调用完成后返回新的Stream流可以继续使用,支持链式编程。
- 在Stream流中无法直接修改集合、数组中的数据。
Stream流的常见终结操作方法

注意:终结操作方法,调用完成后流就无法继续使用了,原因是不会返回Stream了。
“流只能使用一次”,只要有一个方法没有再返回Stream流就终止了,就像水没有拿水管一节一节接着就没了
终结和非终结方法的含义是什么?
- 终结方法后流不可以继续使用,非终结方法会返回新的流,支持链式编程。



Stream流的综合应用(案例)





1、筛选最高工资员工信息,封装成优秀员工对象Topperformer思路:
用流的max方法制定大小规则返回最大值,再用map加工方法封装成Topperformer对象后使用get方法返回Topperformer对象
2、去掉最高工资和最低工资后统计平均工资思路:
先用流的sorted方法对其进行升序排序,然后用skip方法跳过第一个的最低工资,再用limit方法获取除去最后一个最高工资和第一个最低工资后的其它元素(skip跳过了第一个元素,但是one.size的长度还是4,因为Stream流中无法直接修改集合、数组中的数据。除去skip跳过的就是取前两个了)得到去掉最高工资和最低工资后其它人的工资,最后用lambda表达式遍历其余工资相加的总和。
细节:
Lambda表达式是简化匿名内部类的写法,{ }内其实是个方法,而这个方法是属于匿名内部类的,有自己独立的栈,如果把allMoney变量定义到main方法里就属于另一个方法栈内,不同栈里是不能互相访问变量的。所以定义一个静态变量让其进行共享访问。
3、统计2个开发部门整体去掉最低和最高工资的平均工资思路:
获取两个部门的流,将两个流合并再用 2 的思路求平均工资。
细节:因为是两个部门进行计算,所以要把相应位置换成两个部门的总和。还有为了避免浮点类型计算的精度问题,要使用BigDecimal对其进行处理
收集Stream流
Stream流的收集操作
- 收集Stream流的含义:就是把Stream流操作后的结果数据转回到集合或者数组中去。
- Stream流:方便操作集合/数组的手段。
- 集合/数组:才是开发中的目的。
Stream流的收集方法API

| Object[] toArray(); | 返回成数组,返回类型为Object(因为怕里面类型不统一) |
|---|---|
| A[] toArray(IntFunction |
返回成数组,指定返回类型 |
JDK16开始支持直接流转换成不可变集合,可以不用提供收集方式
Collectors工具类提供了具体的收集方式


返回成数组,指定返回类型原理:
从s3流里知道元素有4个,传给匿名内部类的方法内的value,然后方法返回对应类型和长度的数组,最后遍历流里的元素赋给自定义的数组(一般返回Object数组就行)
异常处理
异常概述、体系
什么是异常?
- 异常是程序在“编译”或者“执行”的过程中可能出现的问题,注意:语法错误不算在异常体系中。
- 比如:数组索引越界、空指针异常、 日期格式化异常,等…
为什么要学习异常?
- 异常一旦出现了,如果没有提前处理,程序就会退出JVM虚拟机而终止.
- 研究异常并且避免异常,然后提前处理异常,体现的是程序的安全, 健壮性。

异常体系

Error:
- 系统级别问题、JVM退出等,代码无法控制。
Exception: java.lang包下,称为异常类,它表示程序本身可以处理的问题
- RuntimeException及其子类:运行时异常,编译阶段不会报错。 (空指针异常,数组索引越界异常)
- 除RuntimeException之外所有的异常:编译时异常(写代码的时候),编译期必须处理的,否则程序不能通过编译。 (日期格式化异常)。
编译时异常和运行时异常

常见运行时异常
运行时异常
- 直接继承自RuntimeException或者其子类,编译阶段不会报错,运行时可能出现的错误。
运行时异常示例
- 数组索引越界异常: ArrayIndexOutOfBoundsException
- 空指针异常 : NullPointerException,直接输出没有问题,但是调用空指针的变量的功能就会报错。
- 数学操作异常:ArithmeticException
- 类型转换异常:ClassCastException
- 数字转换异常: NumberFormatException

运行时异常:一般是程序员业务没有考虑好或者是编程逻辑不严谨引起的程序错误,自己的水平有问题!

常见编译时异常
编译时异常
- 不是RuntimeException或者其子类的异常,编译阶就报错,必须处理,否则代码不通过。
- 简单来说,编译时异常起到提醒作用,就是调用者在此处容易出错,比如传入参数错误,Java就在打代码时(编译时)就直接弹出错误提醒你,这里容易出错必须抛出异常或者try{}catch{}捕获处理异常(下面讲抛出异常和try{}catch{}捕获处理异常)
编译时异常示例

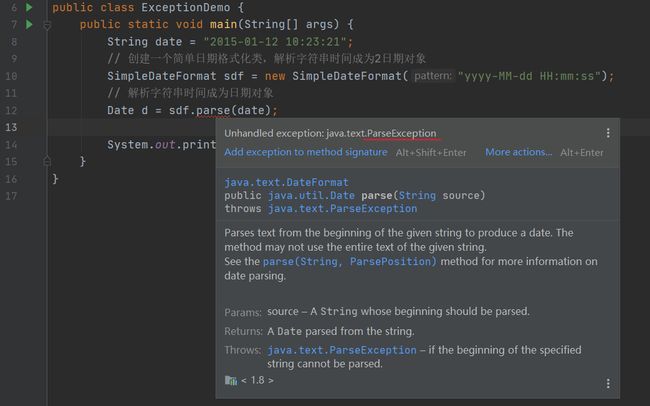
处理办法:光标位于异常处,按快捷键 Alt + 回车。会弹出两种解决办法,一种直接抛,一种try{}catch{}(后面解释,这里选择直接抛)

编译时异常的作用是什么:
- 是担心程序员的技术不行,在编译阶段就爆出一个错误, 目的在于提醒不要出错!
- 编译时异常是可遇不可求。遇到了就遇到了呗。
异常的默认处理流程
- 默认会在出现异常的代码那里自动的创建一个异常对象:ArithmeticException。
- 异常会从方法中出现的点这里抛出给调用者,调用者最终抛出给JVM虚拟机。
- 虚拟机接收到异常对象后,先在控制台直接输出异常栈信息数据。
- 直接从当前执行的异常点干掉当前程序。
- 后续代码没有机会执行了,因为程序已经死亡。

默认的异常处理机制并不好,一旦真的出现异常,程序立即死亡!
编译时异常的处理机制
编译时异常是编译阶段就出错的,所以必须处理,否则代码根本无法通过
编译时异常的处理形式有三种:
- 出现异常直接抛出去给调用者,调用者也继续抛出去。
- 出现异常自己捕获处理,不麻烦别人。
- 前两者结合,出现异常直接抛出去给调用者,调用者捕获处理。
异常处理方式1 —— throws
- throws:用在方法上,可以将方法内部出现的异常抛出去给本方法的调用者处理。
- 这种方式并不好,发生异常的方法自己不处理异常,如果异常最终抛出去给虚拟机将引起程序死亡。(跟默认方式没啥区别,只是让程序在编译阶段通过,不出bug还好,一出就全死)
简单来说,就是一层一层往上抛,除非有谁处理,否则最后谁也不处理直接挂掉
抛出异常格式:

规范做法:

- 代表可以抛出一切异常
一层一层往上抛,谁接到谁异常,最后抛给虚拟机将引起程序死亡。

一个方法内部可能有很多异常要抛出,要一一抛出,谁先出现异常抛出谁
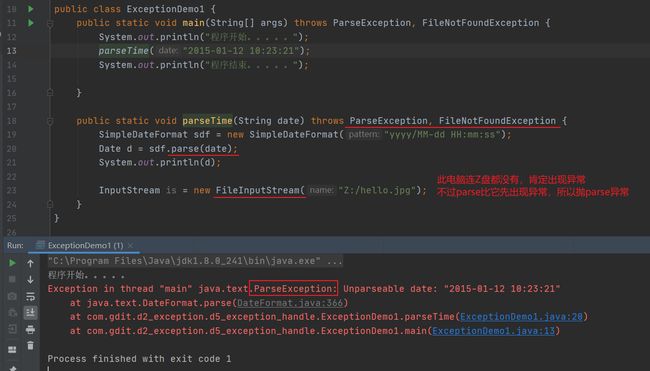
如果需要抛的异常特别多,可以直接抛Exception,效果一样的

快捷键: Alt + 回车。会弹出两种解决办法,选择第一个

异常处理方式2 —— try…catch…
- 监视捕获异常,用在方法内部,可以将方法内部出现的异常直接捕获处理。
- 这种方式还可以,发生异常的方法自己独立完成异常的处理,程序可以继续往下执行。

将可能出现异常的地方用try{}捕获,在catch{}进行处理。这样就能让程序继续运行不会直接死亡

可以只用一个try{}捕获异常,然后使用Exception处理所有异常或者分开处理,因为开发中在中间出现异常就没必要往下走了,下面可能要使用上面的数据,所以整体处理。


异常处理方式3 —— 前两者结合
- 方法直接将异常通过throws抛出去给调用者
- 调用者收到异常后直接捕获处理。
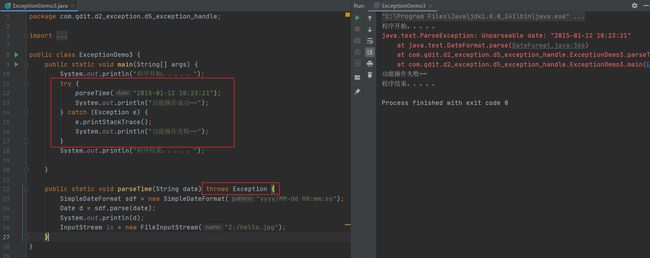
异常处理的总结
- 在开发中按照规范来说第三种方式是最好的:底层的异常抛出去给最外层,最外层集中捕获处理。
- 实际应用中,只要代码能够编译通过,并且功能能完成,那么每一种异常处理方式似乎也都是可以的。(人和代码有一个能跑就行)
运行时异常的处理机制
运行时异常的处理形式
- 运行时异常编译阶段不会出错,是运行时才可能出错的,所以编译阶段不处理也可以。
- 按照规范建议还是处理:建议在最外层调用处集中捕获处理即可。


异常处理使代码更稳健的案例

理想状态下,用户只输入负数会一直循环,输入正数结束。但如果用户不老实,乱输入 如:abc21,程序就直接崩了。


虽然可以使用正则表达式判断输入或者用if else进行判断,但这里主要体验异常处理的强大
使用异常处理后,就算用户一顿乱输,都能被异常捕获重新进入循环,然后还乱输入的话继续捕获异常进行处理。
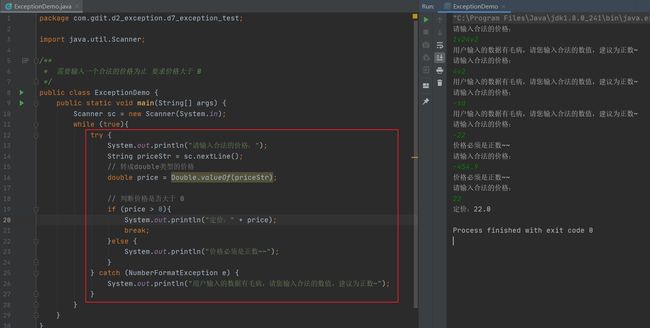
自定义异常
自定义异常的必要?
- Java无法为这个世界上全部的问题提供异常类。
- 如果企业想通过异常的方式来管理自己的某个业务问题,就需要自定义异常类了。
自定义异常的好处:
- 可以使用异常的机制管理业务问题,如提醒程序员注意。
- 同时一旦出现bug,可以用异常的形式清晰的指出出错的地方。
自定义异常的分类
- 自定义编译时异常
- 定义一个异常类继承Exception.
- 重写构造器。
- 在出现异常的地方用throw new 自定义对象抛出,
- 作用:编译时异常是编译阶段就报错,提醒更加强烈,一定需要处理!!
真实项目可能写成千上万行代码,使用异常就能够被记录下来快速定位哪里出现了异常,不然得一行一行找
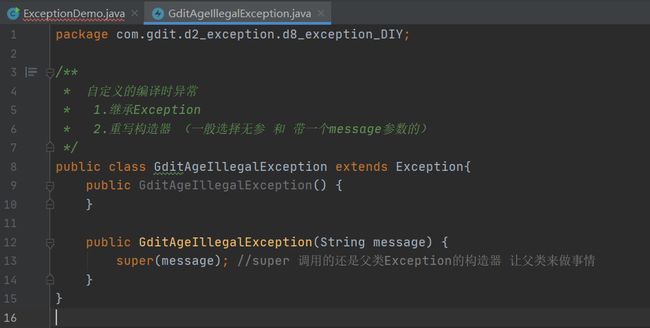


自定义编译异常就是在方法内部创建一个异常对象(此对象就是自定义编译异常),并从此点抛出,再向上抛,当其他人调用此方法时就直接报错,提醒它 意思是:请注意,这里容易出现年龄非法异常。然后调用者必须抛出异常或者try{}catch{}捕获处理异常
上面调用Java的日期格式异常的源码也是这样的原理,一调用就报错,目的就是提醒调用者,传入的参数容易出错,然后必须抛出一个ParseException异常或者try{}catch{}捕获处理异常

-
自定义运行时异常
- 定义一个异常类继承RuntimeException.
- 重写构造器。
- 在出现异常的地方用throw new 自定义对象抛出!
- 作用:提醒不强烈,编译阶段不报错!!运行时才可能出现!!
认为不是很严重的错误,很少见,或者不用特别强烈的提醒就可以定义成运行时异常


日志技术
日志是什么
- 希望系统能记住某些数据是被谁操作的,比如被谁删除了?
- 想分析用户浏览系统的具体情况,以便挖掘用户的具体喜好?
- 当系统在开发或者上线后出现了bug,崩溃了,该通过什么去分析、定位bug?

- 用来记录程序运行过程中的信息,并可以进行永久存储。好比生活中的日记,可以记录你生活的点点滴滴。

日志技术应该具备哪些特点和优势
- 可以将系统执行的信息,方便的记录到指定的位置(控制台、文件中、数据库中)。
- 可以随时以开关的形式控制是日志的记录和取消,无需侵入到源代码中去进行修改。

打印语句写在代码里,拖慢程序运行时时间,日志技术是独立出来的
日志技术体系、Logback概述
日志体系结构

- 日志接口:一些规范,提供给日志的实现框架设计的标准。
- 日志框架:牛人或者第三方公司已经做好的实现代码,后来者直接可以拿去使用。
- 注意:因为对Commons Logging接口不满意,有人就搞了SLF4J。因为对Log4j的性能不满意,有人就搞了Logback,Logback是基于slf4j的日志规范实现的框架。
常见的日志实现框架
- Log4j
- Logback(重点学习的,其它都大同小异)
Logback日志框架
- Logback是由log4j创始人设计的另一个开源日志组件,性能比log4j要好
- 官方网站:https://logback.qos.ch/index.html
- Logback是基于slf4j的日志规范实现的框架
Logback日志框架分为以下模块:
- logback-core: 该模块为其他两个模块提供基础代码。 (必须有)
- logback-classic:完整实现了slf4j API的模块。 (必须有)
- logback-access 模块与 Tomcat 和 Jetty 等 Servlet 容器集成,以提供 HTTP 访问日志功能(可选模块,以后接触)
想使用Logback日志框架,至少需要在项目中整合如下三个模块:

下载(配套资料有,下面介绍在哪可以下载)
方式一:
可到上方官网下载:打开官网,找到Download,点击Maven central,找到对应文件 点进去 选择相应版本即可(没找到slf4j-api)


方式二:
在maven中央仓库下载,官网:https://mvnrepository.com/ 搜索slf4j,点击进入,选择版本号下载,一般选择使用最多的。(logback-classic和logback-core也可以在这下载)




Logback快速入门

-
导入logback框架到项目中去。在项目下新建文件夹lib(一般命名都为lib),导入Logback的jar包到该文件夹下

-
将存放jar文件的lib文件夹添加到项目依赖库中去。

-
将Logback的核心配置文件logback.xml直接拷贝到src目录下(必须是src下)。
logback.xml文件在官网(https://logback.qos.ch/manual/configuration.html),往下翻找到这段代码,在项目中新建logback.xml文件复制进去。(官网只是基础的,别人已经配好了更详细的配置直接拿来用即可——在配套资料里)


- 创建Logback框架提供的Logger日志对象,后续使用其方法记录系统的日志信息。


成功打印到控制台和输出日志文件


Logback配置详解
输出位置、格式设置
对Logback日志框架的控制,都是通过核心配置文件logback.xml来实现的。
Logback日志输出位置、格式设置:
- 通过logback.xml 中的标签可以设置输出位置。
- 通常可以设置2个日志输出位置:一个是控制台、一个是系统文件中
输出到控制台的配置标志
![]()
输出到系统文件的配置标志
![]()
找到对应的位置改就行了


日志级别设置
1、如果系统上线后想关闭日志,或者只想记录一些错误的日志信息,怎么办?
- 可以通过设置日志的输出级别来控制哪些日志信息输出或者不输出。
日志级别
- ALL 和 OFF分别是打开、及关闭全部日志信息。
- 除此之外,日志级别还有: TRACE < DEBUG < INFO < WARN < ERROR ; 默认级别是DEBUG,对应其方法
- 作用:当在logback.xml文件中设置了某种日志级别后,系统将只输出当前级别,以及高于当前级别的日志。



注:
该内容是根据B站黑马程序员学习时所记,相关资料可在B站查询:Java入门基础视频教程,java零基础自学就选黑马程序员Java入门教程(含Java项目和Java真题)