《scikit-learn》xgboost
XGBoost算法
• XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。
• XGBoost的基学习器除了可以是CART(这个时候就是GBDT)也可以是线性分类器,而GBDT只能是CART。
• XGBoost的目标函数的近似用了二阶泰勒展开,模型优化效果更好。
• XGBoost在代价函数中加入了正则项,用于控制模型的复杂度(正则项的方式不同,如果你仔细点话,GBDT是一种类似于缩减系数,而XGBoost类似于L2正则化项)。
• XGBoost借鉴了随机森林的做法,支持特征抽样,不仅防止过拟合,还能减少计算
• XGBoost工具支持并行化
• 综合来说Xgboost的运算速度和算法精度都会优于GBDT
具体的算法细节,且看之前学习的内容
我们得先安装xgboost库,pip install xgboost
我们直接来看下代码看看怎么玩的。
第一步,我们加载数据。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from time import time
import datetime
from xgboost import XGBRegressor as XGBR # xgboost模块
from sklearn.ensemble import RandomForestRegressor as RFR # 随机森林模块
from sklearn.linear_model import LinearRegression as LR # 线性回归模块
from sklearn.datasets import load_boston # 使用波士顿房价进行回归试验预测
from sklearn.model_selection import KFold, cross_val_score, train_test_split
from sklearn.metrics import mean_squared_error as MSE # 评估指标是均方误差
# 第一步,导入数据
data = load_boston()
x, y = data.data, data.target
print(x.shape) # (506, 13)
print(y.shape)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=420)
import sklearn
print(sklearn.metrics.SCORERS.keys()) # 查看所有的模型评估指标
第二步骤:我们先实例化一个模型看看
# 第二步:建立一个xgboost模型,来看看是啥样子的。
xgbr = XGBR(n_estimators=100, silent=True).fit(X_train, y_train) # 100个弱回归器,silent 会打印运行过程
print(xgbr.score(X_test, y_test)) # 查看分数,分数是R2误差
print(xgbr.feature_importances_) # 查看各个属性的重要程度
# print(xgbr.predict(X_test)) # 进行预测
print(MSE(y_true=y_test, y_pred=xgbr.predict(X_test))) # 查看下均方误差
第三步骤:和其他模型,随机森林和线性回归做个对比
# 第三步:看看在交叉验证的情况下,看看xgboost和random、线性回归看看区别
# 先看看xgboost
xgbr = XGBR(n_estimators=100, silent=True) # 如果开启参数slient:在数据巨大,预料到算法运行会非常缓慢的时候可以使用这个参数来监控模型的训练进度
# 不严谨的交叉验证可以使用全部数据,避免把我的测试数据提起给暴露了
# 严谨的交叉验证就是使用部分数据,比如训练数据
res1 = cross_val_score(xgbr, X_train, y_train, cv=5, scoring='neg_mean_squared_error').mean() # 必须得导入没有训练过的模型,切记啊!!!
print('XGBR cross val score is %f' % res1)
# 来看看随机森林
rfr = RFR(n_estimators=100)
res2 = cross_val_score(rfr, X_train, y_train, cv=5, scoring='neg_mean_squared_error').mean() # 必须得导入没有训练过的模型,切记啊!!!
print('RFR cross val score is %f' % res2)
# 来看看线性回归模型
lr = LR()
res3 = cross_val_score(lr, X_train, y_train, cv=5, scoring='neg_mean_squared_error').mean() # 必须得导入没有训练过的模型,切记啊!!!
print('LR cross val score is %f' % res3)
下面我们看看在不同规模的数据集下,训练分数和测试分数的大小的变化曲线。
# 第四步:调整参数,通过学习曲线来观察xgboost在boston数据上的表现
def plot_learing_curve(estimators, title, X, y,
ax=None,
ylim=None,
cv=None,
n_jobs=None):
from sklearn.model_selection import learning_curve
# 根据不同的数据集样本数目,来看看训练分数和测试分数
train_sizes, train_scores, test_scores = learning_curve(
estimators, X, y,
shuffle=True, cv=cv, random_state = 23,
n_jobs=n_jobs)
if ax is None:
ax = plt.gca()
else:
ax = plt.figure()
ax.set_title(title)
ax.set_xlabel('Training examples')
ax.set_ylabel('Score')
ax.plot(train_sizes, np.mean(train_scores, axis=1), 'o-', c='r', label='Training score')
ax.plot(train_sizes, np.mean(test_scores, axis=1), 'o-', c='g', label='Test score')
ax.grid()
ax.legend()
return ax
cv = KFold(n_splits=5, shuffle=True, random_state=42) ## shuffle 表示把数据集打乱, cv就是把数据集分成几份
plot_learing_curve(XGBR(n_estimators=100, random_state=42, silent=True), "XGB", X_train, y_train, cv=cv)
plt.show()
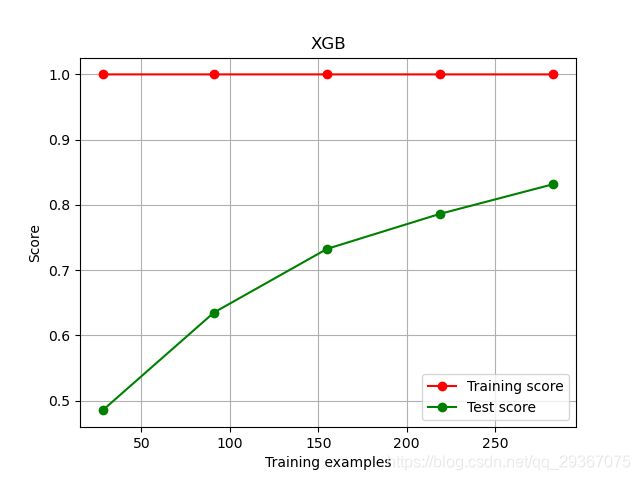
上图中,横坐标是训练样本的数目,很明显,我们目前的模型在训练集上的准确度很高很高,但是在测试数据上表现的不是很好,说明模型处于过拟合的状态了,
那么我们接下来就是要调整参数了啊,第一个需要调整的就是n_estimators。
# 绘制n_estimators的学习曲线
axis_x = range(10, 1010, 40)
nmse = [] # 储存负均方误差
cv = KFold(n_splits=5, shuffle=True, random_state=42) ## shuffle 表示把数据集打乱, cv就是把数据集分成几份
for i in axis_x:
reg = XGBR(n_estimators=i, random_state=42, silent=True)
nmse.append(cross_val_score(reg, X_train, y_train, cv=cv, scoring='neg_mean_squared_error').mean())
print(axis_x[nmse.index(max(nmse))], max(nmse))
plt.figure(figsize=(20, 8))
plt.plot(axis_x, nmse, c='r', label='XGB')
plt.legend()
plt.show()

此时呢,当n_estimators = 130的时候就差不多优比较大的值了