【征服redis7】谈谈Redis的RDB持久化方式
从现在开始,我们来探讨redis的一个非常重要的问题——集群,要讨论集群,我们需要先理解redis持久化数据的方法,因为集群本质上就是将一个集群的数据同步到其他机器上。
Redis 6的持久化机制主要有两种:RDB(Redis DataBase)和AOF(Append Only File)。前者效果好,但是代价高,使用频率低,后者则完全相反。本文将详细介绍这两种持久化方式的工作原理和配置要点。
目录
1. RDB持久化原理
1.1 基本原理
1.2 RDB的优点和缺点
2.持久化的5个步骤
3.RDB持久化实战
1. RDB持久化原理
1.1 基本原理
RDB持久化是将当前进程的数据生成快照保存到磁盘的过程。它可以通过手动触发或自动触发两种方式来执行。
手动触发RDB持久化可以使用save命令或bgsave命令。save命令会阻塞Redis服务器直到RDB过程完成,而bgsave命令则会创建一个子进程来执行持久化操作,主进程可以继续处理其他请求。
自动触发RDB持久化可以在配置文件中设置save指令,指定在一定时间间隔内有一定数量的修改操作时自动触发bgsave命令。
三种主要的触发机制:
1.Save命令:Save命令是手动触发RDB持久化的机制。当执行Save命令时,Redis会阻塞主线程,创建一个子进程,将数据快照保存到磁盘上的RDB文件中。在持久化完成之前,Redis的主线程将无法处理其他请求。
 2.BGSAVE命令:BGSAVE命令是异步触发RDB持久化的机制。当执行BGSAVE命令时,Redis会创建一个子进程,在子进程中进行数据快照的生成和保存。与Save命令不同的是,BGSAVE命令不会完全阻塞主线程,可以继续处理其他请求。
2.BGSAVE命令:BGSAVE命令是异步触发RDB持久化的机制。当执行BGSAVE命令时,Redis会创建一个子进程,在子进程中进行数据快照的生成和保存。与Save命令不同的是,BGSAVE命令不会完全阻塞主线程,可以继续处理其他请求。
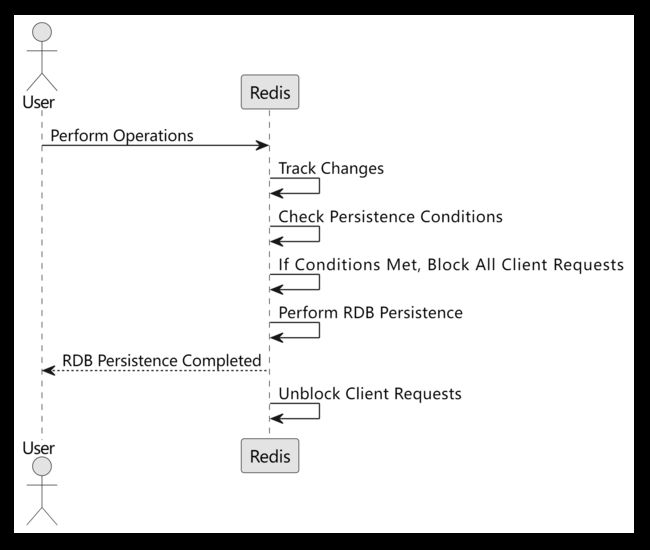
3. 自动触发:Redis 6.0引入了自动触发RDB持久化的机制。可以通过配置文件中的save选项来设置自动触发的条件。例如,设置save 900 1表示在900秒(15分钟)内,如果至少有1个键发生变化,则自动触发RDB持久化操作。这样可以根据实际需求来灵活地控制RDB持久化的频率。
这些触发机制可以根据需求和场景选择合适的方式来进行RDB持久化,以保证数据的持久性和恢复能力。再次对之前的回答失误表示歉意,希望这次回答能够满足你的需求。如果还有其他问题,请随时提问。
RDB持久化的优点包括快速恢复数据、压缩存储和加载速度快。缺点是实时性较差,无法做到秒级持久化,并且执行bgsave命令会进行fork子进程,频繁执行开销较大。
RDB持久化的配置项包括:
- dbfilename:RDB文件在磁盘上的名称。
- dir:RDB文件的存储路径。
- stop-writes-on-bgsave-error:如果持久化过程出错,主进程是否停止写入操作。
- rdbcompression:是否对RDB文件进行压缩。
- rdbchecksum:在RDB文件末尾添加冗余校验编码。
1.2 RDB的优点和缺点
RDB 它会周期性地将 Redis 内存中的数据快照写入到硬盘中,并生成对应的 RDB 文件。
优点是:
- 数据恢复速度快:由于 RDB 文件采用二进制格式存储,文件体积较小,恢复速度非常快。
- 对性能影响小:与 AOF 持久化方式相比,RDB 持久化方式对 Redis 的性能影响要小很多,因为 RDB 仅在指定的时间间隔内执行一次快照存储操作。
- 文件体积小:由于 RDB 文件采用二进制格式存储,文件体积较小,可节省存储空间。
- 可以单独备份:RDB 文件可以单独备份,方便进行数据迁移和备份。
缺点是:
- 可能会丢失一定量的数据:由于 RDB 持久化方式是周期性地生成快照文件,如果在两次快照文件之间 Redis 发生宕机,就会丢失这段时间内的数据。
- 数据一致性较低:由于 RDB 持久化方式并不是实时同步,而是周期性快照存储,因此在宕机时可能会丢失一部分数据,数据一致性较 AOF 持久化方式要低。
- 不支持实时备份:由于 RDB 持久化方式是周期性快照存储,因此不支持实时备份。
整体而言RDB 持久化方式可以提供快速的数据恢复能力,对 Redis 的性能影响比较小,同时也可以节省存储空间。但是,它也存在丢失一定量数据和数据一致性较低的问题,需要根据实际情况进行权衡和选择。后面我们讲解另一种持久化方式AOF。我们可以对照着学习一下。
2.持久化的5个步骤
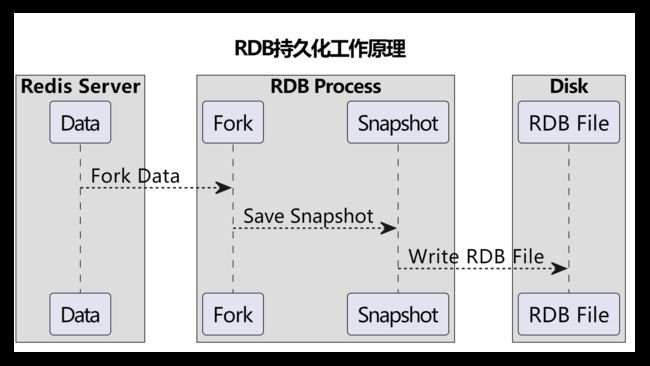
RDB持久化方式一共可以分为5步,第五步其实就是持久化恢复,也可以不算。
具体来说:
1. 触发条件: 可以通过配置文件中的save参数来设置RDB持久化的触发条件。当满足设定的触发条件时,Redis会执行RDB持久化操作。
2. 快照生成:当触发条件满足时,Redis会调用fork函数创建一个子进程。父进程继续处理客户端的请求,而子进程负责将数据写入RDB文件。
3. 写入过程:子进程会遍历Redis服务器中的所有数据库,将每个数据库的键值对写入到RDB文件中。写入过程中,子进程会将数据转换为二进制格式,并按照一定的规则进行压缩。
4. 写入完成:当子进程完成RDB文件的写入后,它会用新生成的RDB文件覆盖原来的RDB文件。这个过程是原子的,可以保证RDB文件的完整性。
5. 恢复:当Redis服务器重新启动时,它会检查是否存在RDB文件。如果存在,Redis会加载RDB文件,并将其中的数据恢复到内存中,从而完成数据的持久化恢复。
比较坑的是 RDB持久化是一个阻塞操作,即在进行RDB持久化期间,Redis服务器将暂停响应客户端的请求。这是因为RDB持久化是通过fork子进程来完成的,而fork操作会复制整个父进程的内存空间,可能会耗费大量的CPU和内存资源。
此外,RDB持久化还有一些配置选项可以进行调整,例如可以设置RDB文件的路径和名称、是否压缩RDB文件、触发条件的设置等。这些选项可以通过Redis的配置文件redis.conf来进行配置。
3.RDB持久化实战
这里想研究一下如何在本地模拟观察一下rdb初始化,如果想启动两个以上的redis用docker方式好一些,后面研究一下怎么更方便的进行。
文章参考:rdb持久化