递归、搜索与回溯算法(专题零:解释回溯算法中涉及到的名词)【回溯算法入门必看】
本篇文章的目的:
(1)给小伙伴们对回溯算法中的名词进行解释
(2)消除递归的恐惧(回溯是递归的一个分支)
给小伙伴们一个建议:整篇文章都要看完,一字不漏,全是干货。
注意:分析回溯的思想之前,我们得知道一个关系——递归包含搜索,搜索包含回溯。所以我们在学习的顺序应该是先了解递归,再了解搜索,最后才是了解回溯算法是个啥,这样学起来既有趣也轻松!
各位小伙伴如果想进一步了解回溯算法,可以看我的回溯系列的文章,此系列会一直更新!!!
目录
1. 递归
1.1 什么是递归
1.2 为什么会用到递归
1.3 如何理解递归
1.4 如何写好一个递归
2. 搜索和遍历的名词解析
2.1 拓展搜索问题
3. 回溯和剪枝
1. 递归
1.1 什么是递归
- 递归就是一个函数在它的函数体内调用它自身。执行递归函数将反复调用其自身,每调用一次就进入新的一层。递归函数必须有结束条件。在求f(n)的时候,你就默认f(n -1)已经被求出来了,至于怎么求的,这个是计算机通过回溯求出来的,也就是涉及到栈的存储结构。
- 递归函数有两个要素:(1)边界条件:确定递归到何时终止,也称为递归出口。(2)递归模式:大问题是如何分解为小问题的,也称为递归体。递归函数只有具备了这两个要素,才能在有限次计算后得出结果
递归函数的主要目的就是“大事化小,小事化了”。递归和二叉树是密切相关的,可以尝试通过二叉树的数据结构来理解递归是如何将一个问题拆分成若干子问题,求解再回溯的,得到最终答案。
给大家举个几个例子,方便大家的理解:
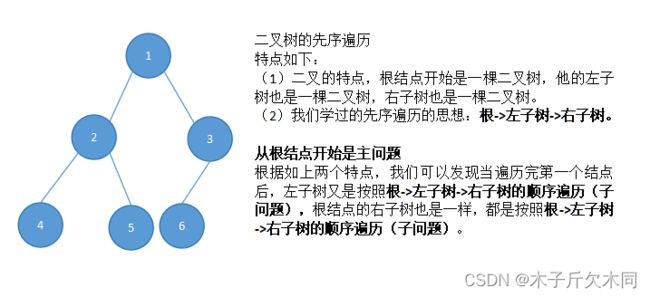
第一个例子(二叉树的遍历):
如果大家对二叉树的先、中和后序遍历等二叉树功能的模拟实现有兴趣,可以看下面这篇博客:
Java版数据结构——二叉树的模拟实现全代码-CSDN博客
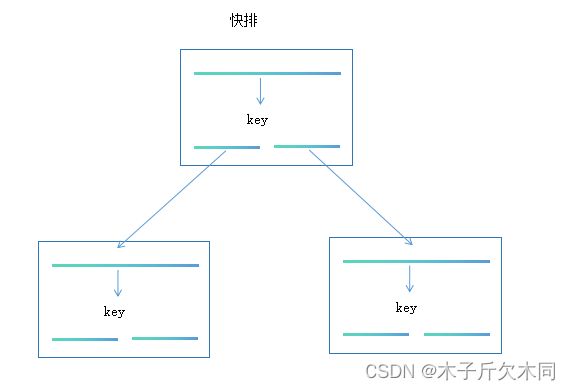
第二个例子(快速排序):
如果大家对快速排序和归并排序还不是很了解,可以看下面这两篇博客(超级详细):
深入浅出排序算法之快速排序(重要)⭐⭐⭐⭐⭐-CSDN博客
深入浅出排序算法之归并排序-CSDN博客
快速排序也是同一个意思:主问题和子问题都是,也就是上面提到的递归是起“大事化小,小事化了”的功能,主问题是大事,子问题是小事,主问题(大事)和子问题(小事)都具有相同的解决问题的步骤。
快排是 ① 先将第一个元素放到合适的位置,② 然后左右分,③ 再分别对左右进行快排;主问题和子问题都是这三个步骤。
说到这里,大家是不是都有点感觉啦!?如果还有些懵,请不要急,继续往下看!!!
1.2 为什么会用到递归
说到为什么会有递归,我们就要讨论递归的本质是什么?
在上面的二叉树和快排的例子中,我一直提到两个名字,主问题(大事)和子问题(小事)。主问题和子问题都具有相同的解题步骤。
主问题 -> 子问题;子问题 -> 子问题;子问题 -> 子问题 …… 直到把“小事化了”!!!
注意:因为主问题和子问题们的解题步骤都是一样,所以他们可以用一个函数来统一解决。这就有了递归的出现啦。
1.3 如何理解递归
根据我的学习,觉得递归的理解可以分为如下三种层次:
第一层:从递归展开图的细节理解递归
- 这种理解方式,适合入门,但不适合长期使用。为什么呢?如果一道题十分简单(例如:用递归的方式打印数组),那么他的递归展开图可能就会比较简单(递归打印数组的递归展开图是一棵单分支的树);假设一道题的递归方法解题的递归展开图是一棵多分支树,那用这种方式学递归就十分痛苦了,可能一道中等的题目用递归解题的递归展开图三、四张A4纸都写不完!
注意:上面提到的展开图是单分支树还是多分支树,大家如果不是很明白,不要紧的。下面会对递归展开图进一步解释。大家只需要知道递归展开图是多分支的话,画起来比单分支树更耗费纸张和时间。
第二层:从二叉树中的题目理解递归
- 来到这一层,证明各位小伙伴们已经开始入门啦。二叉树的设计就是根据递归来设计的,二叉树的先、中和后序遍历都是可以用递归的方式来实现。二叉树的其他操作都是根据遍历实现,也就是说二叉树的其它操作也是可以用递归实现的。了解二叉树的模拟实现,可以使我们对递归的了解上升一个台阶。
注意:这里有一篇博客,里面有Java版的二叉树模拟实现的所有代码。
Java版数据结构——二叉树的模拟实现全代码-CSDN博客
第三层:从宏观角度看待递归过程
能来到这一层,证明各位小伙伴对递归的理解已经很透彻了。在此我详细分享一下,如果宏观来理解递归:
- 一:不要在意递归的细节展开图
- 二:把递归的函数当成一个“黑盒”
- 三:我们的无条件的相信“黑盒”可以为我们解决当前的子问题(再次强调,递归中的每个子问题的解题步骤都是一样)
1.4 如何写好一个递归
(1)先找到相同的子问题!!!
找到相同的子问题十分重要,这一步关乎到函数头的设计。例如:二叉树的先序遍历,首先我们知道遍历的方式是根 -> 左 -> 右,目的是遍历,所以不需要返回值(void),需要有当前根结点传入(需要参数TreeNode root)。故有函数头:public void prevOrder(TreeNode root)
(2)只关心某一个子问题是如何解决的
这一部分涉及函数体的书写,还是拿二叉树的先序遍历举例:遍历方式是根->左->右,所以函数体要把根->左->右给完成了!
(3)注意一下递归函数的出口
递归函数不能一直递归下去,一定要有终止条件。例如二叉树的遍历的终止条件就是 root == null。
具体的例题,在我的下一篇回溯算法文章中!
1.5 递归和for循环的交替
- for循环也是和递归一样都是解决重复子问题的过程
这里就有个疑问,for循环和递归是否可以相互转换呢?
答案:可以的。
例如:打印整型数组
(1)使用for循环进行打印
public class Test17 {
static int[] a = {1, 2, 3, 4, 5, 6, 7, 8};
//for循环进行打印
public static void main(String[] args) {
for (int i = 0; i < a.length; i++) {
System.out.print(a[i]+" ");
}
}
}
(2)使用递归进行打印
public class Test17 {
static int[] a = {1, 2, 3, 4, 5, 6, 7, 8};
//使用递归进行打印
public static void main(String[] args) {
dfs(a, 0);
}
public static void dfs(int[] a, int i) {
//递归终止条件
if (i == a.length)
return;
System.out.print(a[i] + " ");
dfs(a, i + 1);
}
}
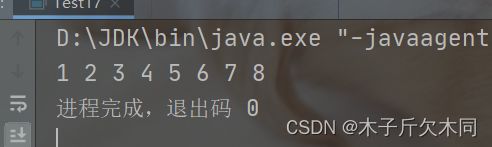
递归展开图如下:

使用递归打印数组的递归展开图明显是一棵单分支树。
- 如果一个递归展开图是单分支树,就可以能比较容易将递归解法转换为 for 循环的解法。
- 如果递归展开图是一棵多分支树,就很难将递归解法转化为 for 循环的解法(注意:这里是指很难,并不是不能实现)
2. 搜索和遍历的名词解析
对比:搜索 vs 深度优先遍历 vs 深度优先搜索 vs 宽度优先遍历 vs 宽度优先搜索 vs 暴搜
(1)深度优先遍历 vs 深度优先搜索 vs 宽度优先遍历 vs 宽度优先搜索
遍历和搜索区别不大,可以这么理解,遍历是形式,目的是搜索。用深度遍历(搜索)还是宽度遍历(搜索)主要看题目,他们也是在遍历(搜索)的顺序上有些区别而已。
深度优先搜索有个简称:dfs;宽度优先搜索有个简称:bfs
(2)搜索 vs 暴搜
搜索就是暴力地枚举一遍所有的情况。搜索包含了暴搜,暴搜包含了深度优先搜索和宽度优先搜索。
2.1 拓展搜索问题
用全排列举例
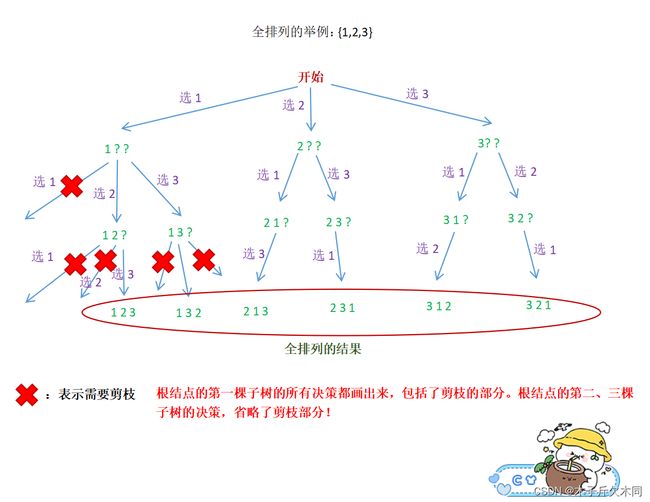
我们可以发现,用递归解决全排列的问题的递归展开图是一棵多叉树。还好这道题给的例子只有{1,2,3}三个元素,如果是10个呢?100个呢?这时候把所有情况按递归展开图画出来就不现实了。这就是我前面说的理解递归的第一层,从递归展开图的细节理解递归。
我们用第三层的思路来理解:
(1)确定相同的子问题:每一次选一个元素,不能选择已经选过的元素。不需要返回值(因为将最终结果存放到了全局变量中),参数需要数组 int[] nums。故有函数头public void dfs(int[] nums)
(2)只关心一个子问题如何解决的。此题要记录哪个位置已选择,从哪个位置继续开始选,把当前选择的元素加入全局数组中。
(3)递归出口:数组的元素都被选过了,或者说来到了树的叶子结点处。
如果大家对这道题还不理解,不要紧,我在这里只是想让大家知道怎么用第三层的思路来思考递归问题。全排列的细节问题并没有展开分享,详细内容在如下的博客中(建议大家先把递归和深搜学明白再来回头看这篇文章):
回溯算法第二篇(全排列【基于排列树实现】、旅行售货员问题【基于排列树实现】、N皇后【基于子集树实现的】)-CSDN博客
3. 回溯和剪枝
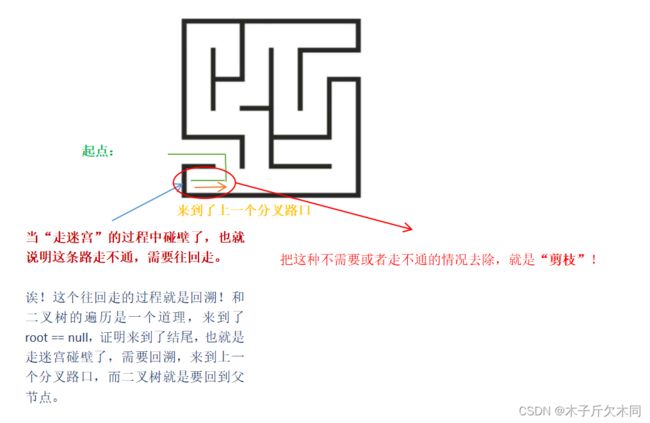
回溯并不神秘,本质就是深搜!!!
这里用一个迷宫来分享我对回溯和剪枝的理解。