rabbitmq的介绍、使用、案例
1.介绍
rabbitmq简单来说就是个消息中间件,可以让不同的应用程序之间进行异步的通信,通过消息传递来实现解耦和分布式处理。
消息队列:允许将消息发到队列,然后进行取出、处理等操作,使得生产者和消费者之间能够解耦,异步地进行通信。
持久性,可靠性的消息传递机制。
2.安装rabbitmq
2.1新建文件夹
[root@localhost local]# mkdir rabbitmq [root@localhost rabbitmq]# mkdir data
新建一个rabbitmq的文件夹,然后在rabbitmq文件夹下新建一个data的文件夹。data文件夹用来挂载rabbitmq内部文件,然后用来存储数据。
2.2查看rabbitmq的镜像
[root@localhost rabbitmq]# docker search rabbitmq

然后就可以下载官方的rabbitmq了。
2.3下载rabbitmq镜像
[root@localhost rabbitmq]# docker pull rabbitmq 下载镜像 [root@localhost rabbitmq]# docker images 查看镜像
![]()
下载好之后就可以查看下镜像,这样最新的rabbitmq就已经下载成功了,下一步就是创建容器了。
2.4创建rabbitmq容器
docker run -it \ --name rabbitmq \ --network wn_docker_net \ --ip 172.18.12.20 \ -v /etc/localtime:/etc/localtime \ -v /usr/local/software/rabbitmq/data:/var/lib/rabbitmq \ -e RABBITMQ_DEFAULT_USER=admin \ -e RABBITMQ_DEFAULT_PASS=123 \ -p 15672:15672 \ -p 5672:5672 \ -d rabbitmq
--network,--ip自己设置的网络ip。可以查看下自己的ip是多少。
[root@localhost rabbitmq]# docker inspect rabbitmq

这就是我们之前设置的ip地址了。
-v是挂载容器内部的文件,这样方便我们在Linux上就可以直接对文件进行操作,在容器内部,先当与一个简单的Linux,里面有一些指令是没有的,需要下载,不方便我们进行操作。-v冒号前面的是自己的路径,注意看自己的路径名称和路径是否正确,避免创建时出错。在创建的时候可以先复制到记事本上,对比自己的信息,进行更改,在Linux上不便操作。
-e是用来设置rabbitmq的默认的账号和密码。
[root@localhost rabbitmq]# docker ps

是up的话就是创建成功了。这里也可以查看日志检查是否成功。
[root@localhost rabbitmq]# docker logs rabbitmq
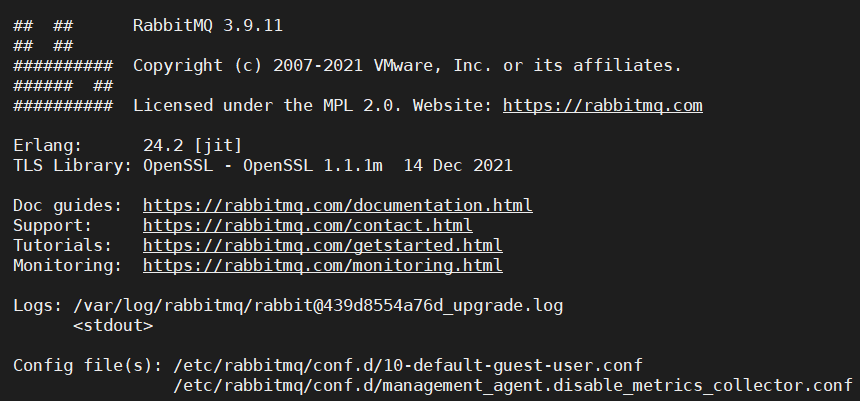

看到版本号,这些info就是ok了,遇到错误的时候,多看看日志,帮助自己解决问题。
3.查看官网
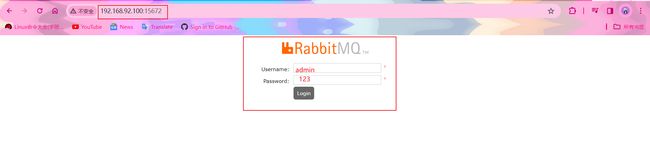
输入自己的虚拟机ip+刚刚设置的端口号,进到这个页面,然后输入之前设置好的默认的账号和密码。
3.1访问失败解决办法

如果是这个页面的话,多半和防火墙有关,没有开放端口。这里的话我是自己电脑学习和测试用的,直接把防火墙关了,如果你不放心的话,就每次安装一个新的东西的时候,记得开放下端口。
[root@localhost rabbitmq]# firewall-cmd --add-port=15672/tcp --permanent
这样就是把15672这个端口给永久开放了,顺便把5672也给打开,后面用java代码的时候有用。
firewall-cmd --reload
可以检查有没有打开。如果还是访问不了,那么就有可能是rabbitmq有个插件没有开,不让我们用浏览器打开。
进到rabbitmq容器的内部。
[root@localhost rabbitmq]# docker exec -it rabbitmq bash
root@439d8554a76d:/# rabbitmq-plugins enable rabbitmq_management
运行命令,打开管理端,然后exit可以退出容器,刷新下页面看下能不能成功,如果还是不行,查看日志。

这样就成功的进到了rabbitmq的操作页面了。
4.生产者和消费者模型
4.1介绍
rabbitmq的基础理论就是生产者和消费者模型,在这里进行解释,方便对rabbitmq进行理解和使用。
生产者和消费者模型是分为以下几个要素:共享缓冲区、生产者、消费者。下面以去kfc买鸡腿举例:
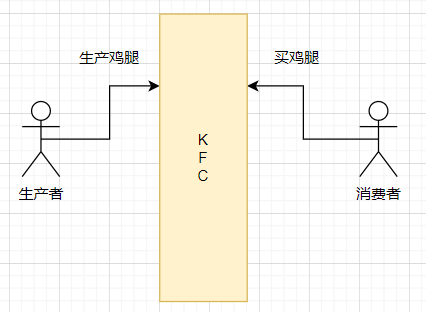
就是顾客要买鸡腿,肯定是需要去店里去买的,只有店员在炸好鸡腿之后,顾客点餐买好鸡腿。炸鸡腿的店员和顾客是不直接接触的,是互相不认识的。
在rabbitmq的消费者和生产者模型中通常就是消费者将消息发送到消息队列中,消费者从消息队列中获取消息并处理。实现解耦和异步通信。
4.1.1队列的解释
首先队列是一种数据结构,它的底层可能是数组也可以是链表两种。在这里先解释数组和链表的区别:
数组:连续的内存空间,查询比较高效,数组需要指定大小,超过范围要考虑扩容的问题。
链表:非连续的内存空间,对在链表中进行插入和删除很高效,动态大小。
4.2代码举例
以去KFC买鸡腿为例:
4.2.1entity 实体类
package com.mq.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/*
kfc中的产品名称
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Food {
private String name;
}
就是简单的写个名字。
lombok可以简化代码,提高代码的可读性和可维护性。在pom文件中引入。
org.projectlombok lombok 1.18.24
@Data 通用方法,set、get、tostring等
@AllArgsConstructor 全参
@NoArgsConstructor 无参
4.2.2service
接口:
/**
* produce:生产者
* consume:消费者
*/
public interface IKFC {
public void produce();
public void consume();
}
在IKFC这个接口中,写了一个生产者的抽象方法和一个消费者的抽象方法来模拟实际的场景。