Javascript语言精粹之正则表达式知识整理
Javascript语言精粹之正则表达式知识整理
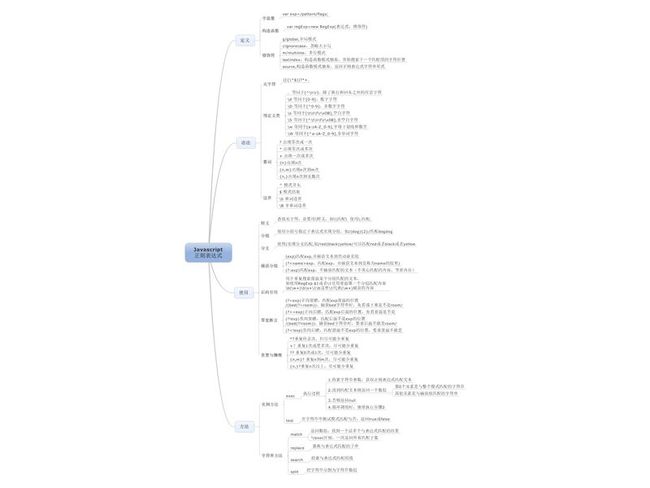
1.正则表达式思维导图
2.正则表达式常用示例
2.1 移除所有标签,只留下innerText
var html = "<p><a href='http://www.baidu.com/'>Ruby Louvre</a>by <em>test</em></p>"; var text = html.replace(/<(?:.|\s)*?>/g, ""); alert(text)
2.2移除hr以外的所有标签,只留下innerText
var html = "<p><a href='http://www.baidu.com/'>Ruby Louvre</a></p><hr/><p>by <em>test</em></p>"; var text = html.replace(/<(?!hr)(?:.|\s)*?>/ig,"") alert(text)//Ruby Louvre<hr/>by test
2.3匹配email
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*,其中\w+@\w+\.\w+是基础结构,剩余部分是在这个基础上添加
2.4 提取简单url的各项内容
https://www.fouwwwfos.gr:8080/c.html?a=1&b=2,提取protocol,hostname,port,querystring
(https?):\/\/(.*):(\d+)\/(?:.*\..*)\?(.*)
结果
["https://www.fouwwwfos.gr:8080/c.html?a=1&b=2", "https", "www.fouwwwfos.gr", "8080", "a=1&b=2"]
2.5 Javascript语言精粹中URL表达式
var parse_url=/^(?:(?:([A-Za-z]+:))(\/{0,3}))?([\w\.\-]+)(?::(\d+))?(?:\/([^?#]*))?(?:\?([^#]*))?(?:#(.*))?$/; var url="http://www.it-ora.com:80/goodparts?q#fragment"; var result=parse_url.exec(url); //result=["http://www.ora.com:80/goodparts?q#fragment","http","//","www.it-ora.com","80","goodparts","q","fragment"];
2.6 简单的URL匹配表达式
(https?:\/\/(?:www\.|(?!www))[^\s\.]+\.[^\s]{2,}|www\.[^\s]+\.[^\s]{2,})
Will match the following cases
http://www.foufos.grhttps://www.foufos.grhttp://foufos.grhttp://www.foufos.gr/kinohttp://www.t.cohttp://t.cohttp://werer.grwww.foufos.gr
Will NOT match the following
www.foufoshttp://www.foufoshttp://foufos
2.7 string.match和RegExp.exec区别
var someText="web2.0 .net2.0"; var pattern=/(\w+)(\d)\.(\d)/g; var outCome_exec=pattern.exec(someText); var outCome_matc=someText.match(pattern); //outCome_exec:["web2.0", "web", "2", "0"] //outCome_matc:["web2.0", "net2.0"] var someText="web2.0 .net2.0"; var pattern=/(\w+)(\d)\.(\d)/; //不带g var outCome_exec=pattern.exec(someText); var outCome_matc=someText.match(pattern); //outCome_exec :["web2.0", "web", "2", "0"] //outCome_matc: ["web2.0", "web", "2", "0"]
1)exec是RegExp对象方法,match是String对象方法;
2)如果没有找到结果,则二者都返回null;
3)只有在正则表达式必须指定全局g属性时,match才能返回所有匹配,否则match与exec方法结果无差异,是等价的;
4)exec永远返回与第一个匹配相关的信息,其返回数组第一个值是第一个匹配的字串,剩下的是所有分组的反向引用(即子括号的匹配内容);
5)exec在设置g属性后,虽然匹配结果不受g的影响,返回结果仍然是一个数组(第一个值是第一个匹配到的字符串,以后的为分组匹配内容),但是会改变index和lastIndex等的值,将该对象的匹配的开始位置设置到紧接这匹配子串的字符位置,当第二次调用exec时,将从lastIndex所指示的字符位置开始检索。同样match方法在设置了g属性后,也会改变index和lastIndex的值,但是是一次性的。无法像exec那样能逐过程累积(即将结果放入Matches 集合中去了),因此无法累积获取下一次检索的位置。