Mysql查询(笔记二)
1.两结构相同的表数据间移植
Inset into 表一
Select 字段1,字段2,....字段n from表二
建立数据库时设置数据库编码
create database 数据库名 charset uft8
模糊查询时
%(任意字符任意个数)
_(单个字符)
2.聚合函数使用时必须有group by给定分组条件
比如有一个表
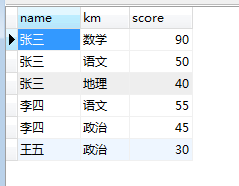
求平均成绩是用聚合函数avg()时必须制定此函数作用的范围依据
3.分组,排序,再次筛选,取几条执行顺序
Where>group by >having>order by >limit
4.如上表要求查询2门及2门以上同学的平均分和不及格科目数
方法一:分步查询
先查出2门及2门以上不及格学生是谁
然后再查这些同学的平均分,需要2个select语句
select name from stu where score<60 group by name having count(name)>=2
便得到表
| name |
| 张三 |
| 李四 |
注意sql的执行顺序
先执行select name from stu where score<60
会得到表2:
| name |
| 张三 |
| 张三 |
| 李四 |
| 李四 |
| 王五 |
之后再分组和再筛选
但要注意虽然group by在having前,但group by是作为having的筛选分组条件的
然后在表2中having筛选即得
第二步:
找到这些学生后,在把学生名最为查询条件再次筛选,因为第一步筛选掉了及格的了的成绩,结果破坏了数据的原始性,所以还得进行一次筛选
select name,avg(score) from stu where name in (select name from stu where
score<60 group by name having count(name)>=2) group by name;
方法二:利用select后可以直接是判断式及本题特点
分析:首先运行sql查询
select name ,score<60 from stu;
得到下表3:
| name |
Score<60 |
| 张三 |
0 |
| 张三 |
1 |
| 张三 |
1 |
| 李四 |
1 |
| 李四 |
1 |
| 王五 |
1 |
在select后的字段或条件mysql会依次与表中的数据对比,如score<60会拿60逐一与表中的score值比较
比如字段name没有要比较的值就显示它在表中的值
从表三发现:sum(score<60)的值就是不及格科目数
于是
select name ,avg(score),sum(score<60) as gk from stu group by name having
gk>=2;
聚合函数的执行时同时进行
得到结果表:

显然方法二比一更简洁高效
未完待续....!