巴别时代基于 Apache Paimon 的 Streaming Lakehouse 的探索与实践
摘要:本文主要介绍巴别时代基于 Apache Paimon(Incubating) 构建 Streaming Lakehouse 的生产实践经验。我们基于 Apache Paimon(Incubating) 构建 Streaming Lakehouse 的落地实践主要分为三期:第一期是在调研验证的基础上进行数仓分层,并且上线一些简单的业务验证效果;第二期是实现流式数仓的基础设施建设,以便优先替换当前基于 Apache Kafka 构建的实时数仓;第三期主要是完善 Paimon 的生态建设,包括数据资产、数据服务等平台服务建设,主要目标是提供完整的基于 Apache Paimon(Incubating) 端到端的平台服务能力。目前基本完成第一期的数仓分层,同时进行数据质量验证,基本可以满足业务需求。
我们基于 Apache Paimon(Incubating) 构建 Streaming Lakehouse 的落地实践主要分为三期:第一期是在调研验证的基础上进行数仓分层,并且上线一些简单的业务验证效果;第二期是实现流式数仓的基础设施建设,以便优先替换当前基于 Apache Kafka 构建的实时数仓;第三期主要是完善 Paimon 的生态建设,包括数据资产、数据服务等平台服务建设,主要目标是提供完整的基于 Apache Paimon(Incubating) 端到端的平台服务能力。目前基本完成第一期的数仓分层,同时进行数据质量验证,基本可以满足业务需求。
点击进入 Apache Paimon 官网
1. 业务背景
基于 Apache Kafka 构建的实时数仓过程中我们遇到一些痛点,例如中间层数据不可分析,数据保留时间短等问题,同时我们的实时数仓是基于 Flink+Kafka+Redis+ClickHouse 构建的,难以查询和分析 Kafka 的中间层数据和 Redis 的维表数据。目前只有 ADS 层数据最终写入到 ClickHouse 里才能分析,但是 ClickHouse 对于数据更新支持的不是很好,所以我们需要通过写入重复数据的方式以达到更新的效果,ClickHouse 去重表执行操作也是异步的,这就需要在业务端进行数据去重,大大增加了业务 SQL 的复杂度,也有一定程度的性能损耗,并且 ClickHouse 不支持事务,很难做到 Flink 到 ClickHouse 端到端的数据一致性保障。
基于以上痛点,我们希望能够借助当下比较流行的数据湖存储方案简化我们的数仓架构,提高数据分析的效率,降低数据存储和开发成本,最终选择 Apache Paimon 作为湖仓底座,主要是基于以下几个方面的考量:
- Apache Paimon(Incubating) 基于 LSM 的强大的数据更新能力正是我们需要的,基于PK进行数据更新以及 Partial Update 的部分更新和 Aggregate 表的预聚合能力能够大大简化我们的业务开发的复杂度。
- Apache Paimon(Incubating) 当时作为 Apache Flink 的子项目,对于 Flink 集成的成熟度也是我们所考量的,Apache Paimon(Incubating) 支持所有的 Flink SQL 语法,对于 Flink 集成的优先支持是较其他数据湖框架优势的地方。
- Flink Forward Asia 2021 的主题演讲里,Apache Flink 中文社区发起人王峰老师提出流式数仓的概念,即整个数仓的数据全部实时流动起来,Paimon 就是在此背景下推出的流批一体的存储,是 Flink 在推动流批一体演进中存储领域上的重要一环,流式数仓作为新型数仓架构演进的一种方案,而 Paimon 作为流式湖仓的标杆,毋庸置疑成为构建流式数仓的首选,随着社区不断发展和框架本身的成熟,Paimon 将成为 Streaming Lakehouse 领域的标准。
- 调研测试过程中发现之前遇到的业务问题和需求通过在社区群中提问,能够得到社区各位老师的耐心答疑,反馈的相关问题能够得到社区的快速响应和 Bug 修复,促成最终选择 Apache Paimon(Incubating) 方案,打消使用 Apache Paimon(Incubating) 的诸多疑虑。
在此特别鸣谢之信老师、晓峰老师以及 Paimon 社区的各位开发者的支持。
2. 数仓架构
目前我们完成基于 Paimon 的数仓分层的设计,包括 ODS,DWD,DIM 层的搭建以及 DWS 层一些业务模型的建设,整体架构如下:

2.1 数据来源
我们的数据源主要包括前端和后端打点日志以及业务数据库的 Binlog,打点日志按项目通过 Filebeat 采集到 Kafka 对应的 Topic, 然后通过 Flink SQL 同步到湖仓的 ODS 层,业务库的数据通过 FlinkCDC 整库同步到湖仓的 ODS 层的 Paimon 表。
2.2 湖仓建设
湖仓主要基于 Apache Paimon(Incubating) 构建,各层都是通过 Flink SQL 进行数据的准实时同步。ODS 层采用 Paimon 的 Append Only 表,保留数据原貌不做更新。DIM 层采用 Paimon 的 PK 表,部分维表需要使用 Partial Update 能力保留最新的维表数据。
DWD 层也采用 Paimon 的 PK 表,ODS 层的表数据经由 Flink SQL 做 ETL 清洗,并通过 Retry Lookup Join 关联维表拉宽后写入到 DWD 层对应的 Paimon 表里,由于维表数据可能晚于事实数据到达湖仓,存在 Join 不上的情况,所以这里需要增加重试机制。DWS 层主要是分主题进行数仓建模,目前主要采用 Paimon 的 Agg 表进行一些预聚合模型及大宽表的建设,ADS 层主要将 DWS 层的结果数据和 DWD 层的一些明细表数据流读到 ClickHouse 在线系统,提供在线服务使用。
2.3 在线系统
通过 Flink SQL 将 DWS 层的结果数据和 DWD 的一些明细表数据近实时地流读到 ClickHouse 在线系统进行 OLAP 分析,提供 BI 实时报表,大屏展示以及用户行为分析系统等使用,同时扩展 Paimon 的 Presto 连接器,数据分析师可以使用 Presto 引擎进行 Adhoc 查询和数据捞取工作。
2.4 平台服务
我们的湖仓目前使用 Paimon 的 Hive Catalog, 基于 HMS 做元数据的统一管理,其中数据开发是基于 Dinky 做得二次开发,使用 Dinky 在 Flink SQL 开发这块儿的能力,数据指标基于不同类型的游戏进行梳理,以便构建统一的指标体系。后面考虑基于 Paimon 构建数据资产以及数据服务。
3. 生产实践
介绍业务生产实践之前,首先介绍一些 Paimon 的正确使用姿势,以便更好理解以下的业务建表实践。
Merge Engine
指定 Merge Engine 的作用是把写到 Paimon 表的多条相同 PK 的数据合并为一条,用户可以通过 merge-engine 配置项选择以何种方式合并同 PK 的数据。
Paimon 支持的 Merge Engine 包括:
- deduplicate:如果用户建表时不指定 merge-engine 配置,创建的 PK 表默认的 Merge Engine 是 deduplicate 即只保留最新的记录,其他的同 PK 数据则被丢弃,如果最新的记录是 DELETE 记录,那么相同 PK 的所有数据都将被删除。
- partial-update:如果用户建表时指定'merge-engine' = 'partial-update',那么就会使用部分更新表引擎,可以做到多个 Flink 流任务去更新同一张表,每条流任务只更新一张表的部分列,最终实现一行完整的数据的更新,对于需要拉宽表的业务场景,partial-update 非常适合此场景,而且构建宽表的操作也相对简单。这里所说的多个 Flink 流任务并不是指多个 Flink Job 并发写同一张 Paimon 表,这样需要拆分 Compaction 任务,就不能在每个 Job 的 Writer 端做 Compaction, 需要一个独立的 Compaction 任务,比较麻烦。目前推荐将多条 Flink 流任务 UNION ALL 起来,启动一个 Job 写 Paimon 表。这里需要注意的是,对于流读场景,partial-update 表引擎需要结合 Lookup 或者 full-compaction 的 Changelog Producer 一起使用,同时 partial-update 不能接收和处理 DELETE 消息,为了避免接收到 DELETE 消息报错,需要通过配置 'partial-update.ignore-delete' = 'true' 忽略 DELETE 消息。
- aggregation:如果用户建表时指定 'merge-engine' = 'aggregation',此时使用聚合表引擎,可以通过聚合函数做一些预聚合,每个除主键以外的列都可以指定一个聚合函数,相同主键的数据就可以按照列字段指定的聚合函数进行相应的预聚合,如果不指定则默认为 last-non-null-value ,空值不会覆盖。Agg 表引擎也需要结合 Lookup 或者 full-compaction 的 Changelog Producer 一起使用,需要注意的是除了 SUM 函数,其他的 Agg 函数都不支持 Retraction,为了避免接收到 DELETE 和 UPDATEBEFORE 消息报错,需要通过给指定字段配置 'fields.${field_name}.ignore-retract'='true' 忽略。
Changelog Producer
Changelog 主要应用在流读场景,在数仓各层的建设过程中,我们需要流读上游的数据写入到下游,完成各层之间的数据同步,做到让整个数仓的数据全实时地流动起来。如果上游流读的 Source 是业务库的 Binlog 或者 Kafka 等消息系统的消息,直接生成完整的 Changelog 以供流读的。
但是目前数仓分层是在 Paimon 里做的,数据以 Table Format 的形式存储在文件系统上,如果下游的 Flink 任务要流读 Paimon 表数据,需要存储帮助生成 Changelog(成本较低,但延迟相对较高),以便下游流读的,这时就需要我们在建表时指定 Paimon 的 Changelog Producer 决定以何种方式在何时生成 Changelog。如果不指定则不会在写入 Paimon 表的时候生成 Changelog,那么下游任务需要在流读时生成一个物化节点来产生 Changelog。这种方式的成本相对较高,同时官方不建议这样使用,因为下游任务在 State 中存储一份全量的数据,即每条数据以及其变更记录都需要保存在状态中。
Paimon 支持的 Changelog Produer 包括:
- none:如果不指定,默认就是 none,成本较高,不建议使用。
- input:如果我们的 Source 源是业务库的 Binlog ,即写入 Paimon 表 Writer 任务的输入是完整的 Changelog,此时能够完全依赖输入端的 Changelog, 并且将输入端的 Changelog 保存到 Paimon 的 Changelog 文件,由 Paimon Source 提供给下游流读。通过配置 'changelog-producer' = 'input',将 Changelog Producer 设置为 input 。
- lookup:如果我们的输入不是完整的 Changelog, 并且不想在下游流读时通过 Normalize 节点生成 Changelog, 通过配置 'changelog-producer' = 'lookup',通过 Lookup 的方式在数据写入的时候生成 Changelog,此 Changelog Produer 目前处于实验状态,暂未经过大量的生产验证。
- full-compaction:除了以上几种方式,通过配置 'changelog-producer' = 'full-compaction' 将 Changelog Producer 设置为 full-compaction,Writer 端在 Compaction 后产生完整的 Changelog,并且写入到 Changelog 文件。通过设置 changelog-producer.compaction-interval 配置项控制 Compaction 的间隔和频率,不过此参数计划弃用,建议使用 full-compaction.delta-commits,此配置下默认为1 即每次提交都做 Compaction。
Append Only Table
建表时配置 'write-mode' = 'append-only',用户可以创建 Append Only 表。Append Only 表采用追加写的方式,只能插入一条完整的记录,不能更新和删除,也无需定义主键。Append Only 表主要用于无需更新的场景,例如 ODS 层数据将 Kafka 埋点日志数据解析后写入到 Paimon 表,保留原貌不做任何更新,此时推荐采用 Paimon 的 Append Only 表。
需要注意的是由于 Append Only 表没有主键,用户必须指定 bucket-key,否则采用整行数据做 Hash 效率偏低。
3.1 ODS 层入湖
3.1.1 业务库数据入湖
业务库数据入湖,我们使用的是 FlinkCDC 的整库同步,目前是基于 Dinky 实现的 FlinkCDC 到 Paimon 的整库同步能力(这里要特别鸣谢文末老师的支持),可以自动建表,多表或整库同步业务库数据到 Paimon 的对应库。由于我们是每个项目一个业务库,所以在 Paimon 中也是按项目建库,与 MySQL 中业务库对应,以下是部分项目的图示:
入湖 SQL:
下面以一个项目的入湖 SQL为例:
EXECUTE CDCSOURCE cdc_demo WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'username',
'password' = 'password',
'checkpoint' = '30000',
'scan.startup.mode' = 'initial',
'source.server-time-zone' = 'Asia/Tokyo',
'parallelism' = '4',
'database-name' = 'demo',
'sink.connector' = 'sql-catalog',
'sink.catalog.name' = 'fts_hive',
'sink.catalog.type' = 'fts_hive',
'sink.catalog.uri' = 'thrift://localhost:9083',
'sink.bucket' = '4',
'sink.snapshot.time-retained' = '24h',
'table-list' = 'A01,A02,A03,A04,A05',
'sink.changelog-producer' = 'input',
'sink.catalog.warehouse' = 'hdfs://cluster/warehouse/table_store',
'sink.sink.db' = 'fts_ods_db_demo'
);FlinkCDC 整库同步目前还是基于单表单 Task 的形式, 执行效果如下所示:

3.1.2 日志数据入湖
日志入湖是通过 Flink SQL 将 Kafka 中的日志数据同步到 ODS 层的 Paimon 表,ODS 层埋点日志没有确定类型,避免由于类型转换过滤掉数据,这里以用户登录日志为例,介绍日志数据入湖:
入湖 SQL:
--CREATE TABLE
create table t_ods_table(
......
gn string,
dt string
) partitioned by (gn,dt)
WITH (
'bucket' = '8',
'bucket-key' = 'id',
'write-mode' = 'append-only', --创建 Append Anly 表
'snapshot.time-retained' = '24h'
);
--INSERT
create table default_catalog.default_database.role_login (
message string,
fields row < project_id int,
topic string,
gn string >
) with (
'connector' = 'kafka',
'topic' = 'topic',
'properties.bootstrap.servers' = '${kafka_server}',
'properties.group.id' = 'topic_group',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
insert into
fts_ods_log.t_ods_table
select
......
cast(SPLIT_INDEX(message, '|', 5) as int) log_create_unix_time,
fields.gn gn,
FROM_UNIXTIME(
cast(SPLIT_INDEX(message, '|', 5) as int),
'yyyy-MM-dd'
) dt
from
default_catalog.default_database.role_login
where
try_cast(SPLIT_INDEX(message, '|', 5) as int) is not null
and cast(SPLIT_INDEX(message, '|', 5) as int) between 0 and 2147483647;日志数据入湖的执行效果如下所示:

3.2 DIM 层入湖
DIM 层数据主要是将 ODS 层多个业务库的相同表的数据同步到 DIM 层对应的表,比如 fts_ods_db_A 和 fts_ods_db_B 都有同名的表 A01,需要 ODS 不同业务库中同名的表同步 DIM 层的 fts_dim 库中的 t_dim_A01 表中,该表的更新频率较低且数据量较小。也有的是业务库表和日志表数据通过 Partial Update 能力拉宽后形成的维表。这里以 tdim_A01 表为例,介绍 DIM 层数据入湖:
入湖 SQL:
--CREATE TABLE
create table t_dim_A01(
......
gn string,
PRIMARY KEY (gn,lid) NOT ENFORCED
) WITH (
'bucket' = '4',
'snapshot.time-retained' = '24h'
);
--INSERT
insert into
fts_dim.t_dim_A01
select
'AA' as gn,
......
from
fts_ods_db_A.A01
union all
select
'BB' as gn,
......
from
fts_ods_db_B.A01
......3.3 DWD 层入湖
DWD 层数据入湖是通过 Flink SQL 清洗过滤,关联维表后形成宽表写入到 DWD 层的 Paimon 表。维表也是在 Paimon 中,所以这里很方便通过 Lookup Join 关联维表,由于维表数据可能会晚于事实表数据到达 Paimon, 所以使用 Retry Lookup Join,如果事实表一开始关联不上维表,可以增加一些重试,以便能够关联上维表数据,这里以用户登录表为例。
入湖 SQL:
--CREATE TABLE
create table t_dwd_table(
......
id string,
gn string,
dt string,
PRIMARY KEY (gn, id, log_create_unix_time, dt) NOT ENFORCED
) partitioned by (gn, dt) WITH (
'bucket' = '8',
'bucket-key' = 'id',
'changelog-producer' = 'full-compaction',
'changelog-producer.compaction-interval' = '54s',
'snapshot.time-retained' = '24h'
);
--INSERT
create view default_catalog.default_database.t_table_view as (
select
......
PROCTIME() proc_time,
gn,
dt
from
fts_ods_log.t_ods_table
where
AA is not null
and try_cast(BB as int) is not null
and try_cast(CC as int) is not null
)
insert into
fts_dwd.t_dwd_table
select
/*+ LOOKUP('table'='fts_dim.t_dim_A01', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='10s','max-attempts'='30'),
LOOKUP('table'='fts_dim.t_dim_A02', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='10s','max-attempts'='30'),
LOOKUP('table'='fts_dim.t_dim_A03', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='10s','max-attempts'='30')*/
......
cast(d.open_date_time as int) open_date_time,
cast(d.merge_server_time as int) merge_server_time,
CONCAT(a.aa, a.bb) id,
a.gn,
a.dt
from
default_catalog.default_database.t_table_view as a
left join fts_dim.t_dim_A01 for SYSTEM_TIME AS OF a.proc_time as b on a.AA = b.AA
and a.BB = b.BB
left join fts_dim.t_B01 for SYSTEM_TIME AS OF a.proc_time as c on a.AA = c.AA
and a.BB = c.BB
left join fts_dim.t_dim_C01 for SYSTEM_TIME AS OF a.proc_time as d on a.AA = d.AA
and a.BB = d.BB;3.4 DWS 层入湖
DWS 主要是分主题,按不同的维度进行聚合,我们也有一些宽表需要有聚合的列,也放在 DWS 层构建。这里以角色域的一张角色宽表为例,介绍 DWS 层使用 Paimon 的 Agg 表做预聚合的场景。
角色宽表的建表语句如下:
CREATE TABLE t_dws_role(
......
gn string,
id bigint,
aa int,
bb int,
acc int,
PRIMARY KEY (gn, id) NOT ENFORCED
) WITH (
'bucket' = '16',
'bucket-key' = 'id',
'merge-engine' = 'aggregation', --指定使用 Agg 表引擎
'changelog-producer' = 'full-compaction', --指定 changelog producer 为 full-compaction
'changelog-producer.compaction-interval' = '40s', --指定 campaction 的间隔为40秒
'fields.aa.aggregate-function' = 'max',
'fields.bb.aggregate-function' = 'min',
'fields.acc.aggregate-function' = 'sum',
'fields.aa.ignore-retract' = 'true', --忽略掉 retract,避免接收到 DELETE 消息出错
......
'snapshot.time-retained' = '24h' --指定 snapshot 文件保留24小时
);角色宽表需要由 DWD 层的多张表关联生成。基于 Paimon 的 Agg 表引擎创建,PK 为 gn + id 构成的联合主键, 只要我们需要关联的表与角色表有相同的主键就可以很方便的做到部分更新和预聚合,所以角色表,登录登出表等都比较好处理,但是注册表和前端日志表是没有 roleid的,没法直接写入角色宽表做处理,因为主键不同。
这里我们首先想到是不是可以通过流 Join 的形式,分别给注册表和前端日志表添上 roleid, 这样就与角色表有相同的 PK, 就可以更新和聚合了。但是流 Join 的方式需要保存的状态就相对要大。
所以我们最终是通过 Paimon 的 Partial Update 将注册表和前端日志表做成一张维表,然后 Flink SQL 流读 DWD 层角色表写入角色宽表的时候和维表做 Lookup Join, 最终补全一些字段。由于注册表和前端日志表的数据都可能先于角色表的数据到达 Paimon,所以需要用 Retry Lookup Join,保证能够 Join 上。
还有需要做特殊处理的就是订单表,比如角色宽表中有累积付费字段,来自于订单表,每个角色的累积付费需要用订单表中的充值金额做 SUM 聚合,但是订单表可能出现重复数据,比如发现订单数据有问题或是缺数,都可能在 CDC 端进行重跑来修复或补全数据,由于 DWD 层的订单表是 PK 表,过来重复数据就会在changelog 文件中保存 -U 和 +U 的记录,这样 Flink SQL 流读订单表写到角色宽表做聚合时,过来重复的数据就会重复求和,计算结果就不准了,这里使用 audit_log 系统表过滤 Changelog, 只要 +I 的记录,过滤掉 -U 和 +U 的记录,忽略掉更新的订单数据,这样也会存在一定的问题,比如丢失订单的更新数据,不过充值金额一般是极少更新的。
audit_log 系统表使用示例:
SELECT * FROM MyTable$audit_log where rowkind='+I'下面先介绍下注册表和 foreend 表通过 Partial Update 构建维表的示例:
建表语句:
CREATE TABLE t_dim_table (
gn string,
......
PRIMARY KEY (gn, id) NOT ENFORCED
) WITH (
'bucket' = '8',
'bucket-key' = 'id'
'merge-engine' = 'partial-update', --指定 merge engine 为部分更新列
'changelog-producer' = 'full-compaction', --指定 changelog producer 为 full-compaction
'changelog-producer.compaction-interval' = '48s', --compaction 间隔48秒
'snapshot.time-retained' = '24h',
'partial-update.ignore-delete' = 'true' --忽略 DELETE 数据
);插入 SQL:
--省略 Flink SQL 参数设置
INSERT INTO
fts_dim.t_dim_table
SELECT
gn,
id,
......
CAST(NULL AS STRING),
CAST(NULL AS STRING),
unix_timestamp()
FROM
fts_dwd.t_dwd_table
UNION ALL
SELECT
gn,
id,
CAST(NULL AS STRING),
CAST(NULL AS INT),
......
unix_timestamp()
FROM
fts_dwd.t_dwd_foreend
WHERE pid <> '0'执行效果如下所示:
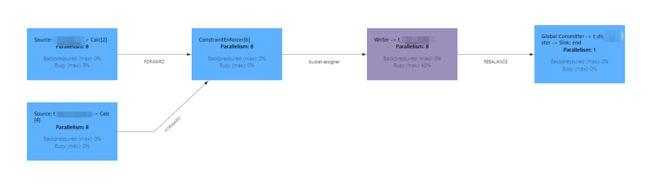
可以看到,在数据写入频率比较高,Compaction时间间隔设置的比较短的时候,Writer端存在一定的压力,经常处于Busy状态。
角色宽表入湖 SQL:
--省略 Flink SQL 参数设置
CREATE view default_catalog.default_database.t_view AS
SELECT
......
id,
gn,
PROCTIME() AS proc_time
FROM
fts_dwd.t_dwd_table
--插入数据
INSERT INTO
fts_dws.t_dws_role
SELECT
......
id,
CAST(NULL AS STRING),
unix_timestamp(),
FROM
(
SELECT
/*+ LOOKUP('table'='fts_dim.t_dim_register', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='10s','max-attempts'='30')*/
a.*,
b.aa,
b.bb
FROM
(
SELECT
*
FROM
default_catalog.default_database.t_view
) AS a
LEFT JOIN fts_dim.t_dim_table for SYSTEM_TIME AS OF a.proc_time AS b ON a.AA = b.AA
AND a.BB = b.BB
)
UNION ALL
SELECT
......
createt_time,
unix_timestamp(),
CAST(NULL AS INT)
FROM
fts_dwd.`t_dwd_o_table$audit_log`
WHERE
rowkind = '+I'
UNION ALL
......宽表入湖执行效果如下:
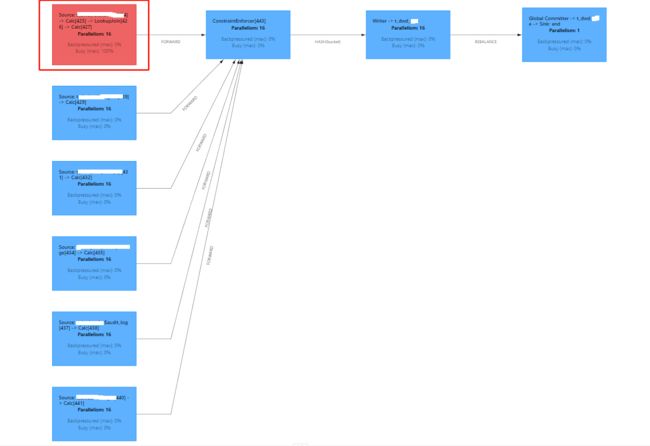
可以看到,第一个 Source 因为用到了 Retry Lookup Join, 后面来的数据在排队,需要等前面的数据 Join 上或是重试次数用完,后面的数据才会处理,很多情况下这个节点处于 Busy 状态,导致效率很低。
3.5 ADS 层流读到 ClickHouse
--CREATE TABLE
CREATE TABLE t_role (
gn string,
id string,
......
) WITH (
'connector' = 'clickhouse',
'url' = 'clickhouse://localhoust:8123',
'database-name' = 'streaming_warehouse',
'table-name' = 't_role_all',
'use-local' = 'false',
'is-changelog' = 'true',
'sink.batch-size' = '5000',
'sink.flush-interval' = '2000',
'sink.max-retries' = '3',
'username' = 'username',
'password' = 'password'
);
-- INSERT
INSERT INTO
t_role
SELECT
*
FROM
fts_dws.t_dws_role
WHERE
is_role = 1综上所述,基于 Apache Paimon(Incubating) 构建 Streaming Lakehouse 能够解决我们当前实时数仓中间层数据不可分析,保留时间短,问题排查困难、数据更新处理复杂等痛点,并能够将 Hive 离线数仓 T+1 的延迟缩小到分钟级,上线后将会优先替换实时数仓,后期慢慢赋能离线业务,用流批一体的计算引擎+流批一体的存储做到真正的流批一体的湖仓体验。
4. 实践总结
- 使用 full-compaction Changelog Producer 时,changelog-producer.compaction-interval 和 checkpoint interval 设置值较小,比如一分钟以下时,Writer 端在写入数据和 Compaction 时的压力较大,需要较大的资源,如果任务暂停一段时间,再从 Savepoint 恢复时,Writer 端反压严重,需不断调整资源。后面考虑测试 lookup Changelog Producer,和 full-compaction Changelog Producer 对比,测试是否可以满足生产环境低延迟流读场景需求。
- 当数仓某一层的数据出现问题,需要通过 Time Travel 重新读取某个快照或是某个时间点开始的数据修复问题,此时需要 Snaphot 文件保留时间能够满足问题回溯周期,但是目前 Checkpoint Interval 设置较小,写入数据延迟较小,导致 Snapshot 保留时间越长,生成越多的小文件,存在小文件过多的问题。
- 目前的 Retry Lookup Join 是有序的,如果前面一条数据一直 Join 不上,那么后面来的数据也会排队,并不会处理,需要一直等到前面的数据Join上维表数据或重试次数用完,这样造成数据处理效率很低,此时如果使用 Unordered Output,则需要 Paimon 实现异步 Lookup Join,目前社区正在支持:([Feature] Introduce async lookup join for Paimon · Issue #848 · apache/incubator-paimon · GitHub)。
5. 未来规划
- 完善基于 Apache Paimon(Incubating) 的流式数仓的建设。
- 优化 Presto 查询,帮助基于 Paimon 进行即席查询发挥作用。
- 目前 Paimon 需要对接 BI 报表或是分析系统的数据都是事先流读到 ClickHouse, 然后再于 ClickHouse 进行可视化展示,后面考虑是否直接在 Paimon 里预聚合完结果数据,与前端交互直接查询 Paimon,减少数据处理链路以及降低复杂度。
- 完善基于 Apache Paimon(Incubating) 的平台服务建设。
6. Paimon 信息
- 官方网站:Apache Paimon
- Github 项目:GitHub - apache/incubator-paimon: Apache Paimon(incubating) is a streaming data lake platform that supports high-speed data ingestion, change data tracking and efficient real-time analytics. (欢迎大家 star&fork 支持)
- 钉钉交流群:10880001919 Apache Paimon 交流群
作者简介
石在虎,大数据研发工程师,专注于实时计算,对数据湖和数据集成有着浓厚的兴趣
史亚光,大数据平台工程师,专注于数据集成与平台开发,对流式数仓和数据湖有着浓厚的兴趣
点击进入 Apache Paimon 官网