数据分析师必会的SQL入门教程 全网最全
CREATE 创建表、数据库
CREATE DATABASE company;
USE在同一个localhost上选择不同的 database
# USE 这个database的名字
USE onlytest2
在database中创建一个table
第一行写你要创建的表的名字是什么
从第二行开始,第一个元素是列名,第二个元素是这一列的数据的类型,两个元素之间用空格分割,每一列的描述之间用逗号分割
USE onlytest2;
CREATE TABLE stest8(
id INT, 规定的类型是整数,你写小数、字符串进去都录入不进去
name VARCHAR(20), # 名字是字符串变量,长度不许超过20个字节
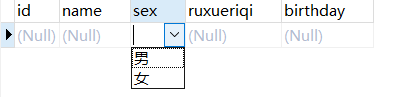
sex ENUM('男','女'), # 只能从男女中选
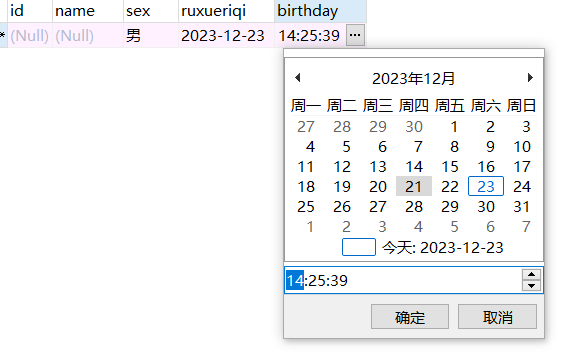
ruxueriqi DATE, # 类型是时间,年份
birthday DATETIME); # 类型是时间
在MySQL5.0以上VARCHAR(20)表示可以存储20个汉字。
下面是你打算存21个汉字,保存的时候会报错
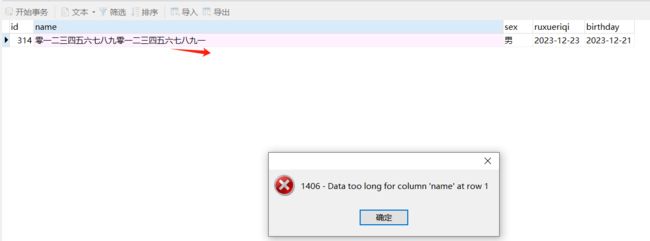
21个数字,报错
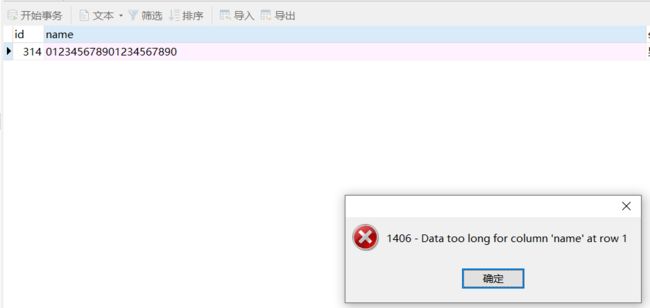
21个字母,报错

ENUM让你只能在后面两个中选一个,除了这两个选项之外,“男”和“女”之外的其他字符串,你想录入都录入不进去 。
DATE和DATETIME的区别如下
DATE就是 年-月-日

DATETIME是在DATE的 年-月-月 的基础上,多了 小时:分钟:秒
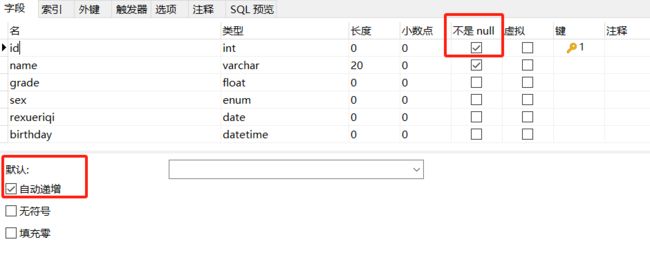
将一列设为主键、key自增、一列非空、默认为0
CREATE TABLE stest9(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
grade FLOAT DEFAULT 0,
sex ENUM('男','女'),
rexueriqi DATE,
birthday DATETIME # 切记,最后一列这个 结尾不要加逗号,否则会报错
);只要选定了某一列自增,这一列即使你不设定,也是默认设定为非空
外键CONSTRAINT ... FOREIGN KEY
创建一个叫mathgrade的TABLE,这个TABLE的PRIMARY KEY, id2 ,是 引用自 stest9的PRIMARY KEY id
CREATE TABLE mathgrade(
id2 INT PRIMARY KEY,
grade INT,
# constraint 给约束起的变量名字(自己随便起,爱叫啥叫啥) foreign key(引用别人的表的 ID) reference 被引用表(被 引用表中字段)
CONSTRAINT cons1 FOREIGN KEY(id2) REFERENCES stest9(id)
);注意点:
1 被引用字段必须有唯一特性(primary key unique)的 建议就是主键
2 被引用字段和引用字段 他们名字可以一样也可以不一样,但是 类型 必须一模
一样
3 注意外键的名字必须要唯一
4 删除表的时候 ,注意表示被引用状态 表示删除不了的?
解决: 第一种:先删除 引用表(成绩表)再删除 被引用表(学生表)
第二种: 解除外键关系 任意删除了
①查看外键的名字 ②根据外键的名字进行解除
代码:
ALTER TABLE mathgrade DROP foreign key aa_foreign11; #删除外键DESC,SHOW查看表
查看TABLE的每一列的列名,数据类型,是否默认非空,默认值有没有设定,有没有其他特性如设定为自增
DESC stest3;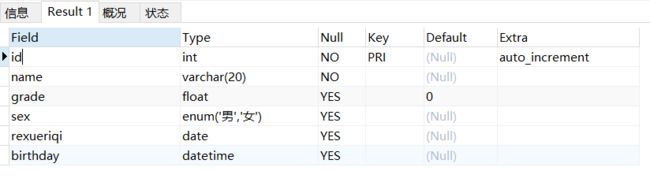 查看一个表创建时候用的SQL语句
查看一个表创建时候用的SQL语句
SHOW CREATE TABLE stest9;![]()
列出这个DATABASE下面所有的TABLE的名字
SHOW TABLES;
ALTER修改表的结构
修改表的名字
# alter table 旧名字 rename to 新名字
ALTER TABLE stest2 RENAME TO s2;改变某个TABLE的某一列的 列名和数据类型
语法:alter table 表名 change 旧字段名 新字段名 新字段的数据类型;
ALTER TABLE s2 CHANGE name fullname VARCHAR(4);给某个TABLE增加一列,设定列名和这一列数据的数据类型
# alter table 表名 add 字段名字 字段类型 (可选字段的约束)
ALTER TABLE s2 ADD grade FLOAT;删除某个TABLE中的某一列
#alter table 表名 drop 字段名字;
ALTER TABLE s2 DROP grade;直接删除一个TABLE
DROP TABLE s2;INSERT 向表格中插入数据
# insert into 表 (字段 1,字段 2,字段 3.。。) values (数据 1,数据 2,数据 3...)
INSERT INTO stest3(id, name, sex) VALUES(1, '令狐冲', '直');自增的那一列(那个字段)可以在插入数据的时候不写,id会自动增加数字
INSERT INTO stest9(name,grade) VALUES('孙悟空',99);一次插入多条记录。括号,逗号分割即可。
INSERT INTO stest9(name,grade) VALUES
('唐三藏',1),
('猪刚鬣',40),
('沙悟净',20),
('龙王三太子', 10);不写列名也可以插入,但是顺序要严格按照列名来写。顺序不能错,任何一列都不能缺。不可以省略任何一列
INSERT INTO stest9 VALUES (10,'银角大王',80,'男','2023-11-11','2023-11-11');UPDATE修改表的数据
update 表的名字 set 修改内容 where 字段 in (select 语句)
不设定条件,整个表,每一行,全部更新
# sc这个表里面所有的行的score这一列全部减2
UPDATE sc SET score=score-2;用WHERE,就只有满足这个条件的才修改
# 让sc这个TABLE中score这一列中,sid=101的 score加10
UPDATE sc SET score=score+10 WHERE sid=101;DELETE,DROP删除表
创建好要被删的数据
# 创建一个能被删的数据
# 创建表结构
CREATE TABLE student333(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
age INT,
gender ENUM('男','女')
);
# 向表内新增数据
INSERT INTO student333(name, age, gender) VALUES
('武大郎',40,'男'),
('西门庆',42,'男'),
('潘金莲',18,'女');既要删除表内数据,也要删除表的结构
DROP TABLE student333;删除表内的数据,但是保留表结构(表的每一列的列名和数据类型限定还有,其他东西没有了)
DELETE FROM student333;
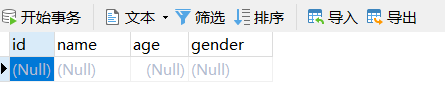
有条件的删除表内某些行
DELETE FROM student333 WHERE id=2;但是这个DELETE删除后,再往里面新增数据,PRIMARY KEY的序号从删除的那些行以后继续
删除之前的三行的id分别是0 1 2,删除以后再新增的三行id是在删除前的基础上自增,变成4 5 6

如果你不想删除三行以后,新增数据的 id在删除前的基础上自增,删除应该用TRUNCATE
TRUNCATE TABLE student333;结果真的从1 开始了,不是从4开始了

作业
1)根据以下信息写出建表语句: 有一张学生表 stu,包含以下信息:
学号 int 主键约束
姓名 varchar(8) 非空约束
年龄 int
性别 varchar(4)
家庭住址 varchar(50)
联系电话 int 唯一约束
首先你要注意,在SQL里面列名可以是英文,也可以是中文
限制条件要求某一列必须不重复,要用CONSTRAINT来实现
CREATE TABLE stu(
`学号` INT PRIMARY KEY,
`姓名` VARCHAR(8) NOT NULL,
`年龄` INT,
`性别` VARCHAR(4),
`家庭住址` VARCHAR(50),
`联系电话` INT,
CONSTRAINT c1 UNIQUE(`联系电话`)
);
2)修改学生表的结构,添加一列信息,学历 varchar(6)
ALTER TABLE stu ADD `学历` VARCHAR(6);
3)修改学生表的结构,删除一列信息,家庭住址
ALTER TABLE stu DROP `家庭住址`;SELECT查询数据
SELECT 你想要查询调用的列的列名 FROM 这一列所在的TABLE的名字
SELECT sname FROM student;

检索过个列,就在SELECT后面多写几个列的名字
SELECT sname,sage FROM student;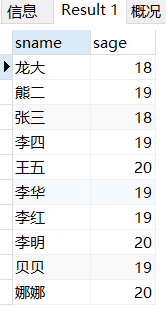
调用取出所有列,用 星号 * 表示所有列
SELECT * FROM student;
DISTINCT取出某一列中不重复的行
加个DISTINCT即可
SELECT DISTINCT sid FROM sc;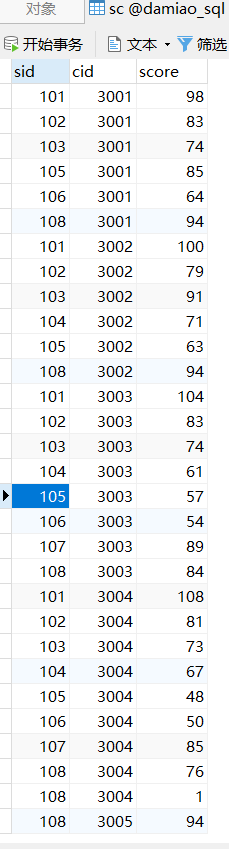

如何你想要两列的组合,这个组合是不重复的,在两列的列名前加DISTINCT
SELECT DISTINCT sid,cid FROM sc;

LIMIT限制只返回前n行
想从头返回之后的6条
SELECT * FROM student LIMIT 6;
想从索引为3的那一条(实际是第4条),返回之后的3条
SELECT * FROM student LIMIT 3,3;
跳过第一行,再取1行
SELECT * FROM student LIMIT 1 OFFSET 1;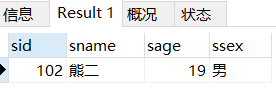
上面那条LIMIT3,3等价于 用OFFSET下面这样写
SELECT * FROM student LIMIT 3 OFFSET 3;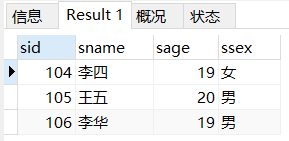
ORDER BY DESC对于取出的数据进行排序
排序按照一个条件的时候。默认是升序。
SELECT * FROM student ORDER BY sage;

上面这句话是省略了ASC
SELECT * FROM student ORDER BY sage ASC;希望是降序加个DESC
SELECT * FROM student ORDER BY sage DESC;
一列升序,一列降序排列
两列的列名写上 后面跟ASC或DESC
SELECT * FROM sc ORDER BY sid DESC, cid ASC;先按照sid降序排列,然后在不改变sid这一列号码顺序的基础上,对cid进行排序
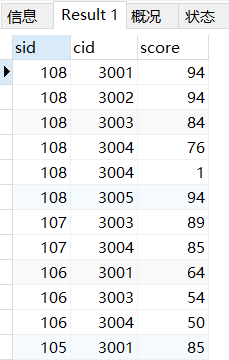
也就是先按照前面那个条件排,排完了,再在后面那个基础上排序。
不信的话,两个排序条件一对调,就会发现排序结果不同了
SELECT * FROM sc ORDER BY cid ASC, sid DESC; 
用WHERE来施加过滤条件
结尾写WHERE,加条件,等于
SELECT * FROM student WHERE ssex='女';
小于,取年龄小于20岁的
SELECT * FROM student WHERE sage<20;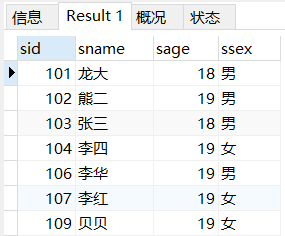
大于等于19,小于等于20
SELECT * FROM student WHERE sage>=19 AND sage<=20;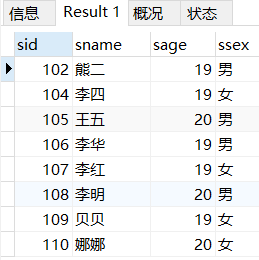
BETWEEN AND是 大于等于+小于等于
SELECT * FROM student WHERE sage BETWEEN 19 AND 20;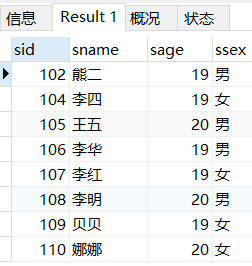
三个条件同时满足,用OR来连接
SELECT * FROM student WHERE sname='李华' OR sname='张三' OR sname='王五'; 
上面这种写法 可以用sname IN 一个集合的方式写,更简便
SELECT * FROM student WHERE sname IN ('李华','张三','王五');把数据中某一行的某一列为空的筛选出来
WHERE结尾加NULL,用IS连接
SELECT * FROM student WHERE sage IS NULL;
LIKE,通配符,查姓张的、姓李的学生
% 代表 0 ~多个字符
%张% 名字中含张。 比张翼德,比如开张大吉,张 前面有0到多个字符都可以
张%,“张飞”,“张狗蛋”,“张灯结彩”,别管张后面几个字全能匹配出来
_ 下划线代表 1 个字符
想查询出,“张翼德”,用 张__
想查询出,“张飞”,用 张_
匹配姓李的,两个字名字的学员
SELECT * FROM student WHERE sname LIKE '李_';
三个字
SELECT * FROM student WHERE sname LIKE '李__';
四个字
SELECT * FROM student WHERE sname LIKE '李___';
AS 将一列选出来然后重命名
SELECT score AS '成绩修正' FROM sc;
其实AS可以不写,可以省略。只是看这句命令的人,会觉得有点懵
SELECT score '成绩修正' FROM sc;
这一列也可以做各种计算,比如同给成绩打八折
SELECT score*0.8 '成绩打八折' FROM sc;
聚合函数
AVG()求学生的平均成绩
在调取的那一列前面加AVG
SELECT AVG(score) AS '平均分' FROM sc; 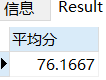
求sid学号为102的学生的各科成绩的平均分
SELECT AVG(score) AS '102各科平均分' FROM sc WHERE sid=102; 
COUNT()数个数
想数出表中,3003这门课上,学生的人数
SELECT COUNT(sid) '学生人数' FROM sc WHERE cid=3003;
MAX()最大值
求3003这门课上,考试最高分
SELECT MAX(score) '3003最高分' FROM sc WHERE cid=3003; 
MIN()最小值
求3003这门课上,考试最低分
SELECT MIN(score) '3003最低分' FROM sc WHERE cid=3003; 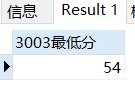
SUM 求和
将学生103的各个科目所有的分数求和,算出他的总分
SELECT SUM(score) '1003的总分' FROM sc WHERE sid=103; 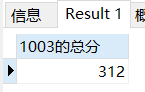
同时取出103这个学生的 平均分、总分、考了几科、最高分、最低分
SELECT
AVG(score) '平均分',
SUM(score)'总分',
COUNT(score)'科目数量',
MAX(score) '最高分',
MIN(score) '最低分'
FROM sc WHERE sid=103;
作业
题目:
有一张学生表 stutest,包含以下字段信息:
学号 int
姓名 varchar(8)
年龄 int
性别 varchar(4)
家庭住址 varchar(50)
联系电话 int
CREATE TABLE stutest(
学号 INT,
姓名 VARCHAR(8),
年龄 INT,
性别 VARCHAR(4),
家庭住址 VARCHAR(50),
练习电话 INT);记得列名即使是中文的,也不能用引号引起来
1)向学生表添加如下信息:
学号 姓名 年龄 性别 家庭住址 练习电话
1 A 22 男 '北京市' 110
2 B 21 男 '上海市' 120
INSERT INTO stutest VALUES
(1,'李白',22,'男','四川', 110),
(2,'武则天',18,'女','河南',120),
(3,'朱元璋',28,'男','安徽',119),
(4, '戴笠',26,'男','浙江',NULL);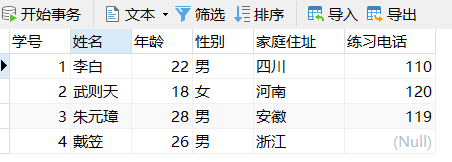
2)修改学生表的数据,将电话号码为 11 开头的学员的家庭住址改为”京城”
修改表的数据用UPDATE
UPDATE stutest SET 家庭住址='京城' WHERE 练习电话 LIKE '11%';注意,列名即使是中文也别加引号
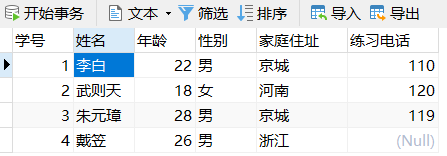
3)删除学生表的数据,姓名以 李 开头,性别为男的记录删除
删除某些行数据,用DELETE
DELETE FROM stutest WHERE 姓名 LIKE '李%' AND 性别='男';李白这个李姓男子被删掉了
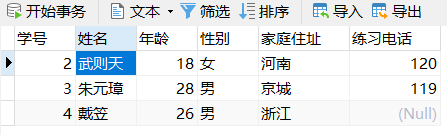
4)查询学生表的数据,将所有年龄小于 27 岁的,家庭住址为“河南”的,学生的姓名和学号查询出来;
SELECT 姓名,学号 FROM stutest WHERE 年龄<27 AND 家庭住址='河南';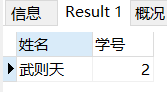
5)查询年龄在 25 到 30 岁之间的学生
SELECT * FROM stutest WHERE 年龄 BETWEEN 25 AND 30;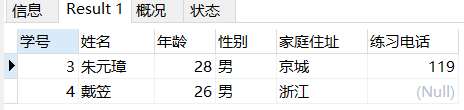
6)查询联系电话不为空的学生信息
SELECT * FROM stutest WHERE 练习电话 IS NOT NULL;
7)把 练习电话 这一列的错别字 改为 联系电话
ALTER TABLE stutest CHANGE 练习电话 联系电话 INT; 
GROUP BY 根据某一列来分组,计算其他数据
求每一门课上的平均分
记住顺序,先写FROM ,之后再写GROUP BY
SELECT cid 课程, AVG(score) 平均分 FROM sc GROUP BY cid;
查一下每个科目及格的人数
计数用COUNT()
SELECT cid 科目,COUNT(score) 选课人数 FROM sc WHERE score>=60 GROUP BY cid; 
下面这样写 是不对的GROUP BY 必须放在WHERE之后,否则会报错
SELECT cid,COUNT(score) FROM sc GROUP BY cid WHERE score>=60;
HAVING对聚合的结果再进行筛选
HAVING 和 WHERE 的差别 这里有另一种理解方法,WHERE 在数据分组前进行过滤,HAVING在数据分组后进行过滤。
在聚合结果的基础上,筛选出聚合结果大于93分的结果
筛选出每个科目分数大于80分的平均分,然后在此基础上筛选出聚合结果大于93分的结果
HAVING二次筛选前
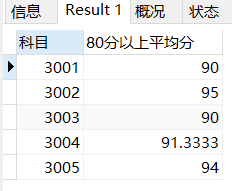
SELECT
cid 科目,
AVG(score) 80分以上平均分
FROM sc
WHERE
score>=80
GROUP BY cid
HAVING 80分以上平均分>93;HAVING二次筛选后
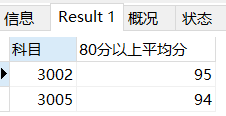
筛选出挂科在2门以上的学生
首先用WHERE筛出挂科的学生
然后用GROUP BY把sid相同的归类为同一个GROUP,
在这个GROUP内数出挂科的次数,展示学号
最后用HAVING把挂科次数大于等于2的筛出来
# 筛选出挂科在2门以上的学生
SELECT
sid 学号,
COUNT(*) 挂科次数
FROM sc
WHERE score<=60
GROUP BY sid
HAVING 挂科次数>=2; 
跨表查询-笨办法
我们目前有两张表student和sc
student表有学号、姓名、年龄、性别

sc这个表 有学号 课程名 分数

我希望查询名字为张三的学生的成绩。
这里就需要关联两张表。
首先,用student表拿到sname为 张三 的用户的 sid
SELECT sid FROM student WHERE sname='张三';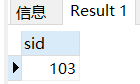
然后, 从sc表格中取出sid为103的所有行
SELECT * FROM sc WHERE sid=103; 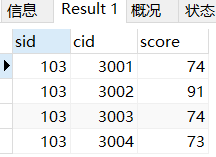
我们肯定是希望一句话能搞定的事,为什么要拆开成两句话来写呢?
一句话也能搞定,比如下面这样
把第一句话的输出作为第二句话的输入
SELECT *
FROM sc
WHERE sid in
(SELECT sid
FROM student
WHERE sname='张三');查询女生的成绩之和
# 查询女生的成绩之和
# 先将女生的学号sid筛选出来
# SELECT sid FROM student WHERE ssex='女';
SELECT SUM(score) FROM sc WHERE sid in (SELECT sid FROM student WHERE ssex='女');查一下张三的语文这门课的成绩
张三的sid需要去student表中查询
语文这门课对应的cid要去course中查询
最后拿着sid和cid再去sc表中查到你要的成绩
也就是说这一次查询实际涉及了3个表
# 查一下张三的语文这门课的成绩
# S1 首先需要拿到张三的sid
# SELECT sid FROM student WHERE sname='张三';
# S2 其次根据张三的sid拿到他所有的成绩
# SELECT sid,cid,score FROM sc WHERE sid=(SELECT sid FROM student WHERE sname='张三');
# S3 把语文这门课对应的cid查出来
# SELECT cid FROM course WHERE cname='语文';
# S4 张三 的 语文 成绩
SELECT
sid,cid,score
FROM sc
WHERE sid=(
SELECT sid FROM student
WHERE sname='张三')
AND cid=(SELECT cid FROM course
WHERE cname='语文');
跨表连接
SELECT时候多写几个表名,将多个表合并成一个表
不加条件,笛卡尔积
比如sc这个TABLE这样
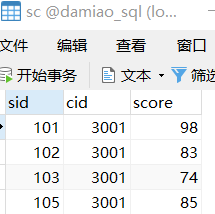
student这个TABLE这样

你可以通过下面这句命令把这两个表格 拼在一起
SELECT * FROM sc,student;但是这种拼接,不是简单的放在一起,而是两个表格所有行和行之间的组合
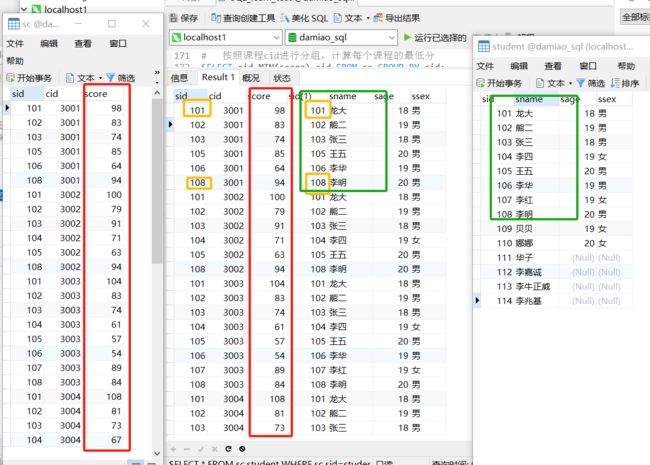
结果如下
按住sc表的 101 3001这一行,倒着和student 表的最后一 李兆基、李牛正威这些来倒着组合
sc的101 3001搞完了,再去弄102 3001,依次组合穷举下去

这种 穷举组合的 两个表的拼接方式被称为"笛卡儿积"
由没有联结条件的表关系返回的结果为笛卡儿积。检索出的行的数目将是第一个表中的行数
乘以第二个表中的行数。

WHERE某些列相等
SELECT * FROM sc,student WHERE sc.sid=student.sid;只有当sc表和student表的sid这一列的每一行是相同的二者才会合并在一起
其实就是拿着student这个表,在sc这个表的基础上,根据sc这个表的sid这一列把student表中用户的信息补充过去。
输出表的长度取与sc表的长度相同
但是两个sid都显示
查询各个学生的考试信息(显示姓名,学员,课程号和成绩)
在上面的基础上把 星号 换成 列名
SELECT sname 姓名,sc.sid 学号,cid 课程号,score 成绩 FROM sc,student WHERE sc.sid=student.sid;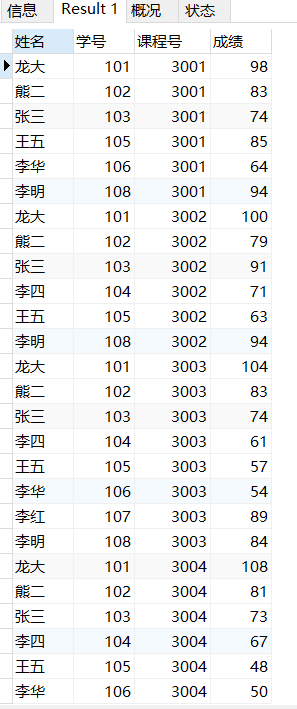
查询龙大的考试信息(显示姓名,学员,课程号和成绩)
只是在结尾加了一个龙大的条件
SELECT
sname 姓名,sc.sid 学号,cid 课程号,score 成绩
FROM sc,student
WHERE sc.sid=student.sid
HAVING 姓名='龙大';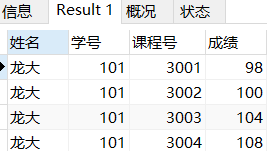
三张表合并成一张大表
FROM后面三张表列出来,拼接的条件是一些列相同
SELECT * FROM sc,student,course WHERE sc.sid=student.sid AND sc.cid=course.cid; 
当你让相等的这些列中,有些元素在另一张表上不出现的时候
会默认只保留在两张表都出现的行,也是就是默认就是INNER模式
比如student_t1这个表的id这一列有mathgrade_t1这一列所没有的333和444
CREATE TABLE student_t1(
id INT,
name VARCHAR(2));
INSERT INTO student_t1 VALUES
(111,'张三'),
(222,'李四'),
(333,'王五'),
(444,'赵六');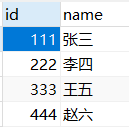
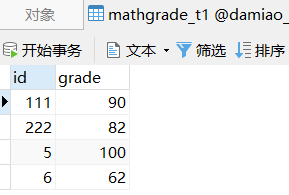
mathgrade_t1这个表的id这一列有student_t1这一列所没有的5和6
CREATE TABLE mathgrade_t1(
id INT,
grade INT);
INSERT INTO mathgrade_t1 VALUES
(111,90),
(222,82),
(5,100),
(6,62);
当你试图通过id相等来将上面两张表拼接起来的时候,你会发现只有二者都有的行才会被保留下来
SELECT
student_t1.id, name,grade
FROM student_t1,mathgrade_t1
WHERE student_t1.id=mathgrade_t1.id;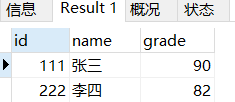
而像上面提到的333 444 和 5 6这些只在一张表上出现的数据统统都没有被保留下来。
INNER JOIN
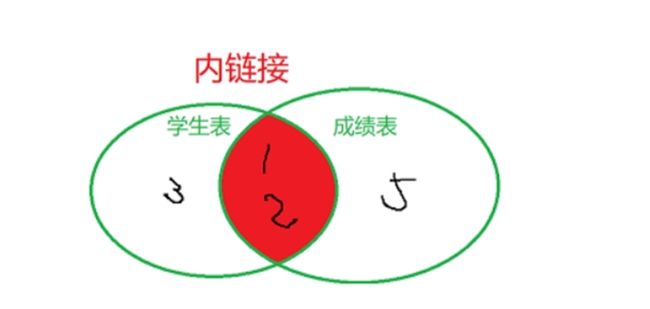
select语句 from 表1 inner join 表2 on 等值条件1 where 。。。条件2
ON后面写的是拼接的条件,就是两个表拼在一起 如何拼接依赖的相同的那一列
SELECT *
FROM student_t1 INNER JOIN mathgrade_t1
ON student_t1.id=mathgrade_t1.id;
加WHERE也是可以的,就是可以多写一个筛选条件
SELECT *
FROM student_t1 INNER JOIN mathgrade_t1
ON student_t1.id=mathgrade_t1.id WHERE name='李四'; 
如果希望三个表的INNER JOIN怎么写?
INNER JOIN和ON连写两次,从而把sc,student,course三个表连接在一起了
SELECT *
FROM
sc INNER JOIN student ON sc.sid=student.sid
INNER JOIN course ON sc.cid=course.cid
不想取出这么多列,想精准的取出自己想要的列
From后面这一串就是把上面这些列都放在一个表里面了,SELECT只是从这些列中把你想要的列筛选出来。
所以score,name,cname这三列你不必写成 sc.score,student.sname,course.cname, 直接写score,name和cname即可
但是像sid和cid,上面也展示了,拼接后的表有两个,所以需要你用sc.sid这个方式取出来
SELECT sc.sid,score,sname,cname
FROM
sc INNER JOIN student ON sc.sid=student.sid
INNER JOIN course ON sc.cid=course.cidLEFT JOIN

他这个LEFT JOIN不同于只用左边这个表,左边这个表有的,右边没有就会用NULL来显示
再有就是这两个表,谁在左,谁在右边
SELECT *
FROM
student_T1 LEFT JOIN mathgrade_t1
ON student_t1.id=mathgrade_t1.id
RIGHT JOIN
SELECT *
FROM
student_t1 RIGHT JOIN mathgrade_t1
ON student_t1.id=mathgrade_t1.id
UNION与UNION ALL纵向合并两个表
UNION是纵向合并的过程中会对比两个表,如何有两个表中有两行完全相同,那么会去重。去重这一步就会拖慢这一步拼接的速度,比起UNION ALL你需要等更久的时间才能拿到结果
制作有重复数据的TABLE
SELECT *
FROM
student_t1 RIGHT JOIN mathgrade_t1
ON student_t1.id=mathgrade_t1.id
CREATE TABLE student_t2(
id INT,
name VARCHAR(2));
INSERT student_t2 VALUES
(111, '张三'),
(111,'李鬼'),
(222,'赵五'),
(555,'武五');student_t1表格如下

student_t2表格
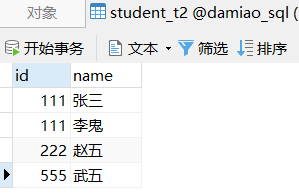
两个表格的不同如下
student_t1和student_t2有完全相同的一行 111 张三——UNION会去重这一行
有id相同的111张三和111李鬼,以及id相同的222李四和222赵五,这些虽然id相同,但是name不同,所有不会被去重,还会被保留下来
UNION结果如下
SELECT * FROM student_t1
UNION
SELECT * FROM student_t2;
UNION ALL则是不做区去重这一步,直接拼接起来,所以省去去重这个步骤,速拼接的速度会快很多
SELECT * FROM student_t1
UNION ALL
SELECT * FROM student_t2;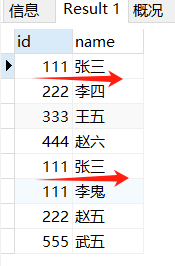
全连接
MySQL中并没有内置的全连接,可以通过先一个LEFT JOIN和一个RIGHT JOIN,然后两个再UNION
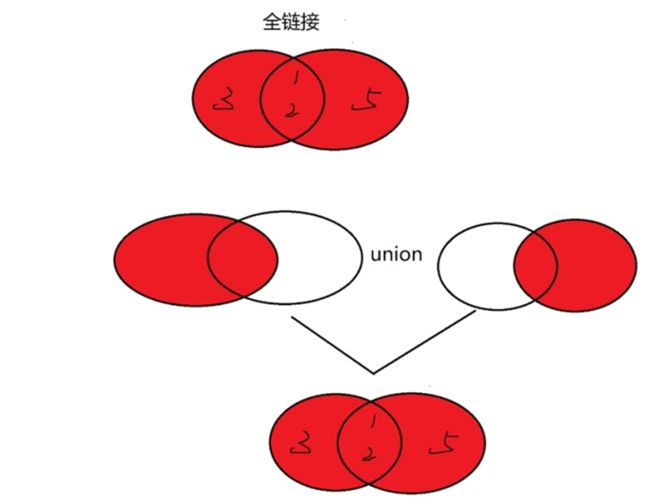
student_t1

mathgrade_t1
SELECT *
FROM student_t1 LEFT JOIN mathgrade_t1
ON student_t1.id=mathgrade_t1.id
UNION
SELECT *
FROM student_t1 RIGHT JOIN mathgrade_t1
ON student_t1.id=mathgrade_t1.id; 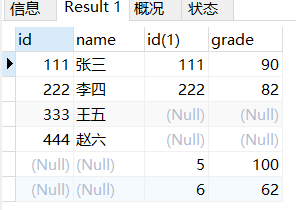
id一样的列在同一行
格子各自有的,单独一行,另一个表格为NULL
作业
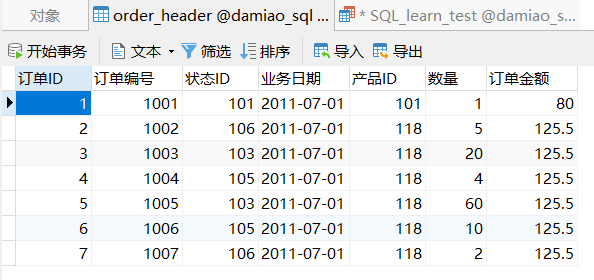
订单表如下
CREATE TABLE ORDER_HEADER(
订单ID INT PRIMARY KEY AUTO_INCREMENT,
订单编号 INT,
状态ID INT,
业务日期 DATE,
产品ID INT,
数量 INT,
订单金额 FLOAT);
INSERT ORDER_HEADER VALUES
(1,1001,101,'2011-07-01',101,1,80.00),
(2,1002,106,'2011-07-01',118,5,125.5),
(3,1003,103,'2011-07-01',118,20,125.5),
(4,1004,105,'2011-07-01',118,4,125.5),
(5,1005,103,'2011-07-01',118,60,125.5),
(6,1006,105,'2011-07-01',118,10,125.5),
(7,1007,106,'2011-07-01',118,2,125.5)
状态ID的含义的对照表如下
CREATE TABLE status(
状态ID INT,
状态名称 VARCHAR(4));
INSERT INTO status VALUES
(101,'创建'),
(102,'接收'),
(103,'派单'),
(104,'备餐'),
(105,'送出'),
(106,'结账'),
(107,'无人接收');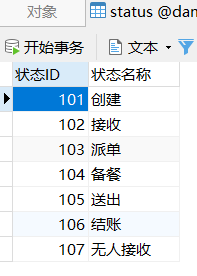
写出如下select语句: 每个业务日期的“状态为派单,送出和结账” 的订单金额合计值(单价乘以数量再相加)。
先将两张表拼接起来,
订单表ORDER_HEADER放在左边,INNER JOIN和LEFT JOIN都可以。
因为ORDER_HEADER上的业务状态ID的种类比status表的种类要少
JOIN的依据是状态ID这一列
SELECT *
FROM order_header LEFT JOIN status
ON order_header.状态ID=status.状态ID; 选出题目要求的那几种订单状态(1)派单(2)送出(3)结账
选出题目要求的那几种订单状态(1)派单(2)送出(3)结账
SELECT *
FROM
order_header
LEFT JOIN
status
ON order_header.状态ID=status.状态ID
WHERE 状态名称 IN ('派单','送出','结账'); 然后数量×订单金额
然后数量×订单金额
SELECT 数量*订单金额 总金额 FROM order_header LEFT JOIN status ON order_header.状态ID=status.状态ID
WHERE 状态名称 IN ('派单','送出','结账');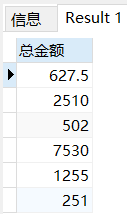
求和
SELECT SUM(数量*订单金额) FROM order_header LEFT JOIN status ON order_header.状态ID=status.状态ID
WHERE 状态名称 IN ('派单','送出','结账');
你有下面下面这样一个图书数据库请完成以下查询
create table books
(
bid int primary key auto_increment,
btitle varchar(100) unique not null,
bauthor varchar(50) not null,
bprice decimal(5,1) not null,
bpublisher varchar(100) default '人民教育出版社' not null,
bstatus enum('已上架','已下架') not null,
bpublishdate date not null,
bremark text,
bemail varchar(100),
bcreatetime datetime not null
);
INSERT INTO books VALUES
(1,'红楼梦','曹雪芹',45,'人民文学出版社','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(2,'马斯克传','沃尔特',9.99,'人民文学出版社','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(3,'我的母亲做保洁','张小满',1.99,'人民文学出版社','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(4,'法律的悖论','罗翔',1.99,'人民文学出版社','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(5,'红楼梦刘心武续传','刘心武',69.9,'机械工业出版社','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(6,'寒夜无声','吴忠全',43.2,'机械工业出版社','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(7,'成为雍正','李正',88.88,'机械工业出版社','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(8,'名侦探的献祭','白井智之',66.66,'机械工业出版社','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(9,'红楼梦脂砚斋','王丽文',89.9,'湖南文艺出版社','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(10,'明亮的夜晚','崔恩荣',76.5,'湖南文艺出版社','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(11,'太白金星有点烦','马伯庸',19.9,'湖南文艺出版社','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(12,'豆子芝麻茶','杨本芬',54.68,'湖南文艺出版社','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(13,'上野千鹤子的午后时光','上野千鹤子',58,'中华书局','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(14,'红楼梦评传','曹雪芹',120,'中华书局','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(15,'沿着季风的方向:从印度到东南亚的旅程','刘子超',69,'中华书局','已上架','2016-01-01',NULL,NULL,'2016-01-01'),
(16,'求剑:年纪·阅读·书写','唐诺',58.5,'中华书局','已上架','2016-01-01',NULL,NULL,'2016-01-01');

(1)查询价格在50到100之间的图书信息
SELECT * FROM books WHERE bprice BETWEEN 50 AND 100;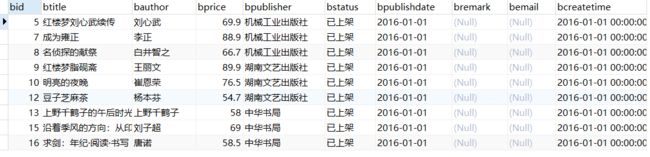
(2)查询出书名中包含“红楼”的图书信息
SELECT * FROM books WHERE btitle LIKE '%红楼%';(3)按出版社分组统计各组的图书数量、平均书价、最高书价、最低书价。并筛掉分组后平均书价不到20元的信息
SELECT
COUNT(*),
AVG(bprice),
MAX(bprice),
MIN(bprice)
FROM books
GROUP BY bpublisher;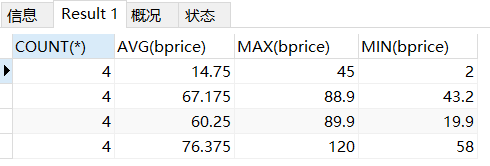
SELECT
COUNT(*),
AVG(bprice),
MAX(bprice),
MIN(bprice)
FROM books
GROUP BY bpublisher
HAVING AVG(bprice)>=20; 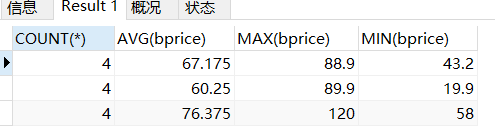
条件判断
IF
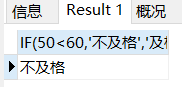
if(condition,a,b) 如果 condition 为真,则返回 a 值,否则返回 b 值。
SELECT IF(50<60,'不及格','及格');50<60为True,所以取前者'不及格'
IF一个条件再去嵌套另一个条件
如果满足或不满足前面那个条件就会进入IF组成的第二个条件
这里实际想要实现的就是if elif 。如果成绩低于60就是不及格,如果成绩在60到80之间就是良好,高于80就是优秀。但是因为SQL里面不支持if elif所以才有这个替代方案
SELECT IF(70<60,'不及格',IF(70<80,'良好','优秀'));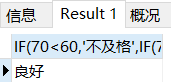
sc这个表格的score,我想按照分数用IF进行判断分别打上不及格、良好和优秀的标签
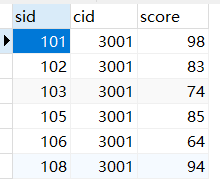
SELECT
sid,cid,score,
IF(score<60,'不及格',IF(score<80,'良好','优秀')) 等级
FROM sc;
IFNULL
IFNULL (v1, v2) 表达的语义是:如果 v1 不为 NULL,则返回 v1,否则,返回v2
mathgrade_t1这个表如下有一些控制,我希望通过使用ifnull这个函数把这个空值的地方用0来填充
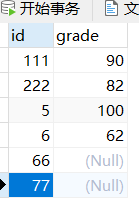
SELECT id,grade,IFNULL(grade,0) grade_adjust FROM mathgrade_t1;
NULLIF
NULLIF (v1, v2),它表达的语义是:如果 v1 等于 v2,那么返回值是 NULL,否
则返回值为 v1
相等返回NULL
SELECT NULLIF(1,1); 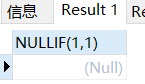
不相等返回第一个
SELECT NULLIF(88,1); 
假设有下面这个叫salary的数据库。只有A被判定为研发岗位,其他岗位都被判定为非研发岗位。如何用IF来说实现?
CREATE TABLE `salary` (
`id` int(11) NOT NULL,
`type` varchar(255) DEFAULT NULL,
`salary` float(255,0) DEFAULT NULL,
PRIMARY KEY (`id`)
)
INSERT INTO `salary` VALUES ('1', 'A', '32000');
INSERT INTO `salary` VALUES ('2', 'B', '18000');
INSERT INTO `salary` VALUES ('3', 'C', '20000');
INSERT INTO `salary` VALUES ('4', 'A', '22000');
INSERT INTO `salary` VALUES ('5', 'D', '8000');
INSERT INTO `salary` VALUES ('6', 'C', '13200');
INSERT INTO `salary` VALUES ('7', 'D', '9500');
SELECT type,IF(type='A','研发','非研发') 岗位类别 FROM salary;
CASE WHEN
具体的值
MySQL里面的 if elif else
CASE [col_name] WHEN [value1] THEN [result1]...ELSE [default] END 枚举这个字段所
有可能的值
course这个表中tid为1,2,3,4的分别命名为火箭班、实验班、平行班、摸鱼班
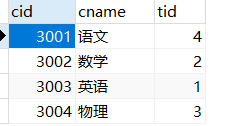
SELECT cid, cname, tid,
CASE tid
WHEN 1 THEN '火箭班'
WHEN 2 THEN '实验班'
WHEN 3 THEN '平行班'
ELSE '摸鱼班'
END 班级类型
FROM course;
一个区间
books这个表的bprice这一列
价格在0-20 低价书,小意思!随便买
20-50 小贵,买还是不买让我犹豫几天
50-70 有点承受不住,能不买还是不买了
70-100 太贵了!狗都不买
100+ 这书金子做的啊!这么贵!不如去抢好了!
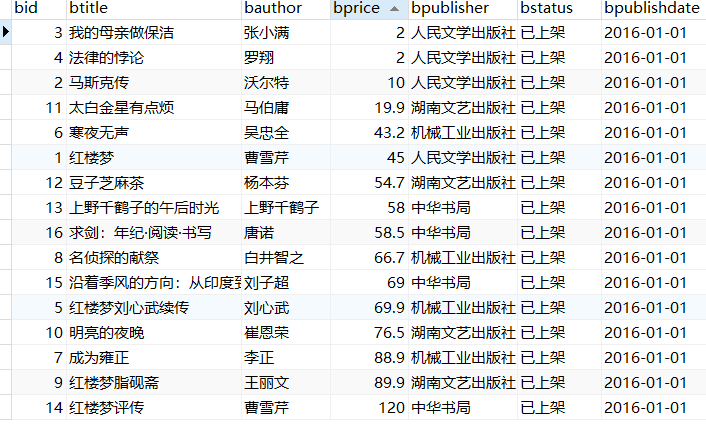
这里你千万注意,
上面只要几种选择的那个在CASE后面写了列名,但是WHEN后面也是没有加列名的
但是你这里是一个区间,所以你CASE后面不要加列名,但是在when后面加上列名

SELECT bid,btitle,bauthor,bpublisher,bprice,
CASE
WHEN bprice<=20 THEN '低价书,小意思!随便买'
WHEN bprice<=50 THEN '小贵,买还是不买让我犹豫几天'
WHEN bprice<=70 THEN '有点承受不住,能不买还是不买了'
WHEN bprice<=100 THEN '太贵了!狗都不买'
ELSE '这书金子做的啊!这么贵!不如去抢好了!'
END 消费者心理OS
FROM books; 
salary这张表,ABCD分别对应一种岗位,你做一下

注意是像下面这样写才是对的
SELECT
id,type,salary,
CASE type
WHEN 'A' THEN '开发狗'
WHEN 'B' THEN '销售大忽悠'
WHEN 'C' THEN '运营小姐姐'
WHEN 'D' THEN '产品经理个杀千刀的'
END 岗位绰号
FROM salary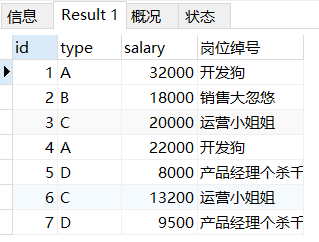
注意有选项的这种情况,就不要在WHEN的里面写列名等于某一个选项,这样会像下面这样很奇怪的一种匹配
SELECT
id,type,salary,
CASE type
WHEN type='A' THEN '开发狗'
WHEN type='B' THEN '销售大忽悠'
WHEN type='C' THEN '运营小姐姐'
WHEN type-'D' THEN '产品经理个杀千刀的'
END 岗位绰号
FROM salary
根据salary的工资水平的不同,写一个 打工人os
SELECT
id, type,salary,
CASE
WHEN salary<=10000 THEN '在北京,工资低于一万,狗都不给你干!但是谁叫我毕业三个月都没找到工作呢'
WHEN salary>10000 AND salary<=15000 THEN '凑合过吧,每个月都攒不下钱'
WHEN salary<20000 THEN '生活初见起色'
WHEN salary>=20000 THEN '走上人生巅峰,准备迎娶白富美'
END 打工人心理OS
FROM salary; 
时间类函数
时间存储类型
date 只能存年月日
datetime 年月日时分秒
对时间如何运算?
1) 日期函数
now() 返回当前的时间,年-月-日 小时:分钟:秒
SELECT NOW();
curdate() 返回当时的日期,年-月-日
SELECT CURDATE();
date() 转换为日期函数
将任何形式的时间转换成年-月-日的形式
SELECT DATE(NOW());
year() 获取输入日期里面的年份
SELECT YEAR(NOW());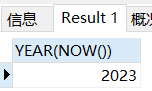
month() 月
SELECT MONTH(NOW());
day() 日
SELECT DAY(NOW());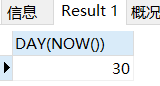
2) 日期和时间转换函数
date_format("日期","日期格式")
格式格式的表示规则
%Y 年 %m 月 %d 日子
%H 时 %i 分 %s 秒
SELECT DATE_FORMAT(NOW(),'%Y/%m/%d %H-%i-%s');
自己写一个时间也可以转
SELECT DATE_FORMAT('2002-11-26 14:23:10', '%Y_%m_%d#%H&%i&%s');
3)日期计算(重点~)
date_add(日期, 日期的差值 单位 ) 增加日期 #用负数表示减少日期
比如给一个日期,往后加7天
加七天
SELECT DATE_ADD(NOW(),INTERVAL 7 DAY);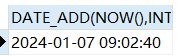
加7个月
SELECT DATE_ADD(NOW(),INTERVAL 7 MONTH);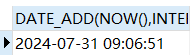
加7年
SELECT DATE_ADD(NOW(),INTERVAL 7 YEAR);
date_sub(日期,日期的差值 单位) 减少日期
一起日期向前减去7天
其它函数:
to_days 可以计算 从 参考日期年 到现在的天数
注意这个“参考日期”,不同版本的MySQL 是不相同的,有的是1970年1月1号这个UNIX纪年,有的是公元元年。我电脑上的这个参考日期就是公元元年.
公元元年1月2号距离公元元年1月1号是2天
SELECT TO_DAYS('0000-1-2'); 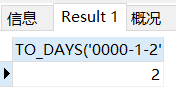
1970年1月1日距离公元元年元旦以下天数.说明我的MYSQL版本的参考日期不是1970年的UNIX纪年
SELECT TO_DAYS('1970-1-1');
这个时候你会问,我为啥要知道某个日期距离公元元年元旦的多少天呢?是的你确实不需要知道,但是这个方法的主要用途是用来计算两个日期之间相差多少天而设计的。
SELECT TO_DAYS(NOW())-TO_DAYS('2023-12-01');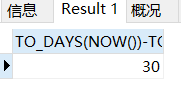
yearweek 一年中的第几周
SELECT YEARWEEK(NOW());显示这是2023年的第53周

算这一天是当年第几周
quarter 获取一年中的季度
SELECT QUARTER(NOW());显示现在是第4季度

作业
创建数据库 company
CREATE DATABASE company;在 company 里创建两张表
雇员表里的工号是主键,姓名是非空约束,
CREATE TABLE gyb(
工号 INT PRIMARY KEY,
姓名 VARCHAR(2) NOT NULL,
年龄 INT,
职位 VARCHAR(3));USE company;
INSERT INTO gyb VALUES
(001, '张三',47,'会计'),
(002,'李四',29,'HR'),
(003,'赵倩',39,'经理'),
(004,'孙俪',27,'行政'),
(005,'樊磊',28,'销售'),
(006,'盛益',30,'销售'),
(007,'房斌',46,'销售'),
(008,'宋悟',51,'销售'),
(009,'方敬',54,'销售'),
(010,'宗峰',26,'销售'),
(011,'辜合',37,'销售'),
(012,'钟墨',52,'销售'),
(013,'陈沛',25,'销售'),
(014,'娄燎',40,'销售'),
(015,'孔桂',43,'销售')
工资表的工号是外键约束,参照雇员表的工号
USE company;
CREATE TABLE gzb(
工号 INT,
工资 INT,
CONSTRAINT cons1 FOREIGN KEY(工号) REFERENCES gyb(工号)
); 
向工资表中添加数据
INSERT INTO gzb VALUES
(001,44731),
(002,4226),
(003,10635),
(004,19351),
(005,10489),
(006,47475),
(007,3887),
(008,NULL),
(009,23206),
(010,8004),
(011,20208),
(012,NULL),
(013,35482),
(014,NULL),
(015,31910)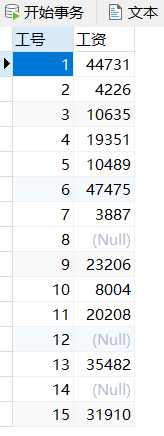
查询公司员工的姓名、年龄及工资,没有工资的员工信息也要展示
SELECT *
FROM
gzb INNER JOIN gyb
ON gzb.工号=gyb.工号;
查询领 35482块工资的员工的姓名
SELECT *
FROM
gzb INNER JOIN gyb
ON gzb.工号=gyb.工号
WHERE 工资=35482;
工资大于三万块的是这些
SELECT *
FROM
gzb INNER JOIN gyb
ON gzb.工号=gyb.工号
WHERE 工资>30000;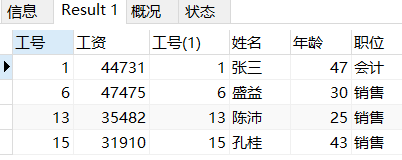
从“雇员表”和“工资表”查出年龄在 25-35 之间的雇员工资,并按照工号降序排列
注意ORDER BY要放在WHERE后面,否则会报错
SELECT *
FROM
gzb INNER JOIN gyb
ON gzb.工号=gyb.工号
WHERE 年龄 BETWEEN 25 AND 35
ORDER BY gzb.工号 DESC
查询员工数目超过 10 人的职位
一旦GROUP BY以后就不不能使用WHERE了,只能用HAVING
SELECT 职位,COUNT(*) 人数
FROM gyb
GROUP BY 职位
HAVING 人数>10查询出工资前三名的员工。
SELECT *
FROM
gyb LEFT JOIN gzb
ON gyb.工号=gzb.工号
ORDER BY 工资 DESC
LIMIT 3;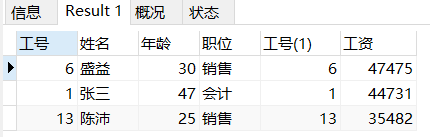
窗口函数
创建数据
USE damiao_sql;
CREATE TABLE score_1 (
cid varchar(4),
sname varchar(4),
score int
);
insert into score_1 (cid, sname, score) values ('001', '张三', 78);
insert into score_1 (cid, sname, score) values ('001', '李四', 82);
insert into score_1 (cid, sname, score) values ('002', '赵六', 90);
insert into score_1 (cid, sname, score) values ('001', '王五', 62);
insert into score_1 (cid, sname, score) values ('002', '赵红', 76);
insert into score_1 (cid, sname, score) values ('002', '李丽', 59);
insert into score_1 (cid, sname, score) values ('001', '张帅', 56); 
窗口函数有 over 关键字,指定函数执行的范围,可分为三部分:
1)分组子句(partition by)
2)排序子句(order by)
3)窗口子句(rows)
窗口函数的语法:<函数名> over (partition by <分组的列> order by <排序的列> rows between <起始行> and <终止行>)
PARTITION BY 分组
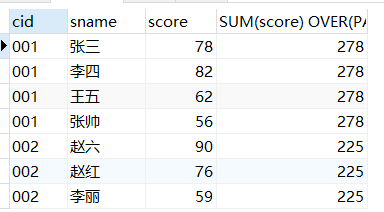
按照cid进行分组求分数之和
SELECT *,SUM(score) OVER(PARTITION BY cid) FROM score_1;
什么情况下我们需要使用窗口函数呢?
窗口函数就是一种稍微复杂一点的聚合函数GROUP BY
这种聚合函数进行聚合的标准是:排序、分组、筛选出某个区间数据。其他情况,只调用原始数据不在数据基础上做进一步计算的情况下的时候,不需要使用窗口函数。
窗口函数OVER必须搭配计算函数如SUM() COUNT()来使用,没有函数的情况下 单独使用窗口函数是会报错的。就像你单独使用GRUPBYU但是不加计算的函数也会报错的一样

-

此时你就要问了:为啥放着好好的GROUP BY不用,非要用窗口函数的PARTITION呢?
因为:GROUP BY只能输出 分组后经过SUM() COUNT() MAX() MIN()等函数处理后的得到的一个结果,并无法让分组前的那些列和前面这些结果一起显示

你可以看到可以拿到分组后的的这些函数的计算结果
SELECT cid,SUM(score) FROM score_1
GROUP BY cid;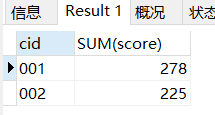
但是一旦你尝试将分组后的结果和分组前的这些列(除了分组标准那一列以外)放在一起的时候,你就无法实现,会报错

-

所以如果你想把分组计算前和分组计算后的结果放在一起,那么你就要使用窗口函数的PARTITION
SELECT *,SUM(score) OVER(PARTITION BY cid) FROM score_1;
FROM score_1;果真分组前和分组后的都在同一行了
窗口函数这里的分组其实是(1)分组标准那一列完全相同的放在一起,001一起,002一起(2)其次是前面函数SUM()计算的这个值是同一组内计算一个,而不是全体放在一起计算

如果不想分组呢?
那就写PARTITION BY NULL
SELECT *, SUM(score) OVER(PARTITION BY NULL) FROM score_1;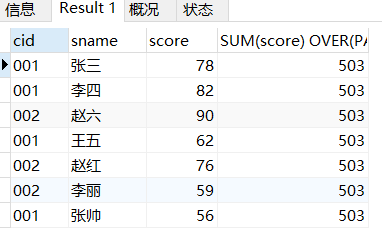
当然更简单的是OVER里面啥也不写就不分组了
SELECT *,SUM(score) OVER() FROM score_1; 
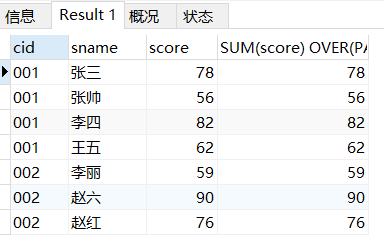
PARTITION BY和GROUP BY一样也可以用多列作为分组标准,两列中的每种组合作为一个小组单独计算
SELECT *,SUM(score) OVER(PARTITION BY cid,sname) FROM score_1;这个时候你会发现001并不再继续被归为一类(001的这些的SUM的分数都是不相同的),而是001张三,001张帅这种cid和sname的组合被归为一个GROUP来单独计算SUM()
ORDER BY 排序
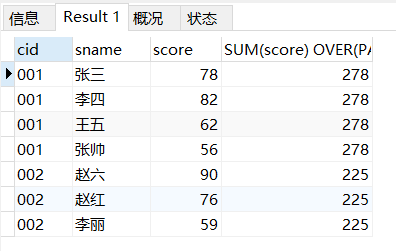
ORDER BY之前
SELECT *,SUM(score) OVER(PARTITION BY cid) FROM score_1;score这一列的顺序是乱的,不是升序也不是降序
ORDER BY 以后,同一个GROUP内score是升序。但是SUM()也变了计算方式从同一个组一个分数变成的升序累积求和
SELECT *,SUM(score) OVER(PARTITION BY cid ORDER BY score) FROM score_1;
但是这种PARTITION BY和ORDER BY的搭配使用的SUM() 的值不是简单的累积求和
如果你在同一个GROUP里面score的分数完全相同,此时就是不是简单的累积求和了,是同一个分数段的SUM完全一致。相当于在前面PARTITION这个分组的基础上根据排序的位置再分一个组,这个排序位置相同的数据再用SUM求和
SELECT *,SUM(score) OVER(PARTITION BY cid ORDER BY score) FROM score_1;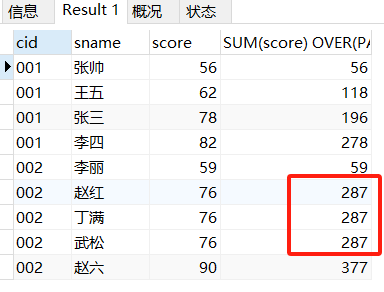
ROWS滑动窗口
N PRECEDING——这一行之后取多少行
N FOLLOWING——这一行之后取多少行
UNBOUNDED PRECEDING——代表了分组中的第一行
UNBOUNDED FOLLOWING——代表了分组中的最后一行
CURRENT ROW——当前行
NAME |
------------
Aaron| <-- Unbounded Preceding
Andrew|
Amelia|
James|
Jill|
Johnny| <-- 1st preceding row
Michael| <-- Current row
Nick| <-- 1st following row
Ophelia|
Zach| <-- Unbounded Following创建一批可以演示后面这些组合效果的数据表
CREATE TABLE score_c(
name VARCHAR(4),
dep VARCHAR(1),
score int);
INSERT INTO score_c VALUES
('路含蕊','A',1),
('蒙问筠','A',2),
('卢采南','A',3),
('甘映菱','A',4),
('江夜梦','A',5),
('尉迟霞文','A',6),
('俞慧美','A',7),
('裴晏','A',8),
('莫献','A',9),
('邬忆安','A',10),
('纪智志','B',11),
('陆芳蔼','B',12),
('鹿涵涤','B',13),
('戚罗','B',14),
('貊初夏','B',15),
('戎清涵','B',16),
('任迎夏','B',17),
('古晴雪','B',18),
('吴迎海','B',19),
('盛湘君','B',20)
五个关键词有下面这些种组合方式
前1行到后3行 ROWS BETWEEN 1 PRECEDING AND 3 FOLLOWING
上面1行+下面3行+当前行
SELECT *,SUM(score) OVER(
ROWS BETWEEN
1 PRECEDING
AND
3 FOLLOWING) SW
FROM score_c;

你可以逐行算一下,SW的每一行都是 CURRENT ROW+前1行+后3行 加在一起
1 PRECEDING 表示的是排除当前行之外,前面的1行
3 FOLLOWING表示的是排除当前行之外的,后面的3行
BETWEEN 1 PRECEDING AND 3 FOLLOWING ,毕竟是BETWEEN AND,自然会把前面1行和后面3行之间的CURRENT ROW 也包含进去
所以BETWEEN 1 PRECEDING AND 3 FOLLOWING包含了5行,由下面三部分组成
(1)CURRENT ROW前面1行
(2)CURRENT ROW后面3行
(3)CURRENT ROW这一行本身
这里依然是一样的,BETWEEN A AND B,这个A必须在B的上面和前面,否则就会报错
下面这样倒过来写,就会报错
SELECT *,SUM(score) OVER(
ROWS BETWEEN
3 FOLLOWING
AND
1 PRECEDING) SW
FROM score_c;
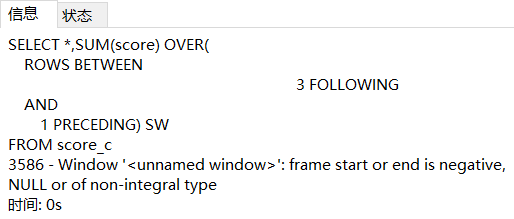
向前无数行到向后2行 ROWS BETWEEN UNBOUNDED PRECEDING AND 2 FOLLOWING
从"最靠前的"第1行
从第一行到当前行+当前行+向后2行
SELECT *,SUM(score) OVER(
ROWS BETWEEN
UNBOUNDED PRECEDING
AND
2 FOLLOWING) SW
FROM score_c; 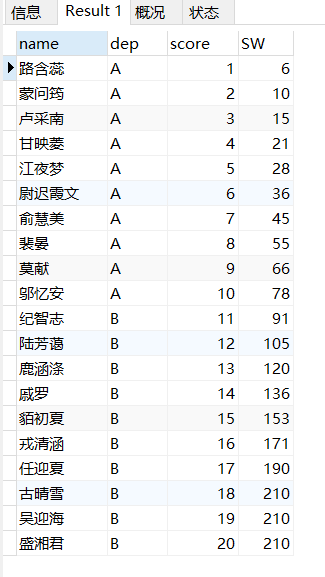
从前3行到向后无数行 ROWS BETWEEN 3 PRECEDING AND UNBOUNDED FOLLOWING
“最靠后的”最后1行
从向前3行+当前行+当前行到最后一行
SELECT *,SUM(score) OVER(
ROWS BETWEEN
3 PRECEDING
AND
UNBOUNDED FOLLOWING) SW
FROM score_c;
向前2行到当前行 ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
SELECT
*,SUM(score) OVER(
ROWS
BETWEEN 2 PRECEDING
AND
CURRENT ROW) 滑动窗口求和
FROM score_c;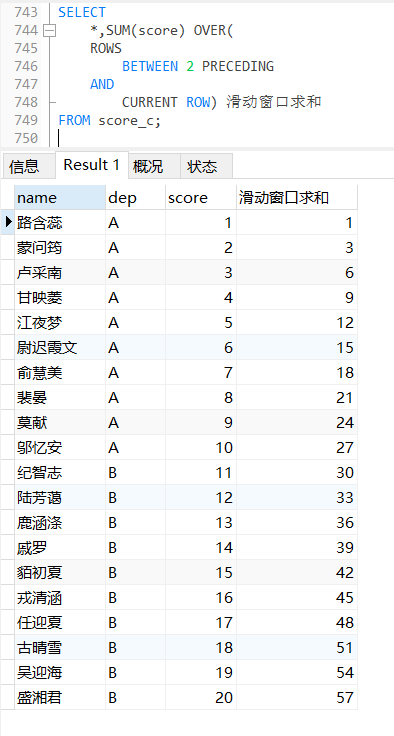
这个有简便写法,直接写ROWS 2 PRECEDING,效果是一样,和前者等价
其实这里的BETWEEN 和 AND CURRENT ROW这两个东西可以省去不写,直接写 ROWS 2 PRECEDING
至于为什么可以省略,省略的规则是什么,后面会集中介绍
SELECT *,SUM(score) OVER(
PARTITION BY dep
ROWS 2 PRECEDING) 滑动窗口求和
FROM score_c; 
向前无数行到当前行 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
从向前3行,推广到向前无数行
其实就是从前往后的累积求和
SELECT *,SUM(score) OVER(
ROWS BETWEEN
UNBOUNDED PRECEDING
AND
CURRENT ROW)SW
FROM score_c; 
其实这里的BETWEEN 和 AND CURRENT ROW这两个东西可以省去不写,直接写UNBOUNDED PRECEDING
至于为什么可以省略,省略的规则是什么,后面会集中介绍
SELECT *,SUM(score) OVER(ROWS UNBOUNDED PRECEDING)SW FROM score_c;效果和上面完全一样,没有区别

CURRENT ROW配合升序或降序ORDER BY求和,会有下面这样一个特别的功能,即使同一个排序位次的数据就不会是同一个SUM值,而是会累积到这一行的累计值
没有使用CURRENT ROW的时候升序求和是下面这个样子
SELECT *,SUM(score) OVER(
PARTITION BY cid
ORDER BY score)
FROM score_1;此时同一个排序位次的76,都会共享一个相同的SUM()值

但是你一旦用了CURRENT ROW以后,就不会让同一个排序位次共享同一个SUM值了,而是会累计求和 ,同样都是76每向下多一行的一位置都会多加上一个76
SELECT *,SUM(score) OVER(
PARTITION BY cid
ORDER BY score
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
FROM score_1;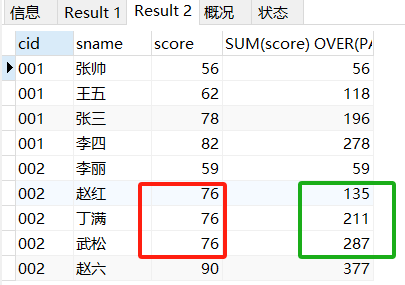
从当前行到向后2行 ROWS BETWEEN CURRENT ROW AND 2 FOLLOWING
SELECT *,SUM(score) OVER(
PARTITION BY dep
ROWS
BETWEEN CURRENT ROW
AND 2 FOLLOWING) 滑动窗口
FROM score_c;
此时切记不能模仿前面的ROWS 2 PRECEDING 简写为2 FOLLOWING,否则会报错,原因后面会集中解释
SELECT *,SUM(score) OVER(ROWS 2 FOLLOWING) SW FROM score_c; 
但是你要记得ROWS BETWEEN AND 只能从前往后,从上往下,不能“从后往前”,不能“从下往上”,否则就不符合语法,就会报错
下面这个就是从后往前,从下到上,就报错了
SELECT *,SUM(score) OVER(
PARTITION BY dep
ROWS BETWEEN
2 FOLLOWING
AND
CURRENT ROW) 滑动窗口
FROM score_c;报错信息我看不懂,但是就是告诉你,不能从后往前

当前行,向后无数行ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
从后往前的一个累积求和
SELECT *,SUM(score) OVER(
ROWS BETWEEN
CURRENT ROW
AND
UNBOUNDED FOLLOWING) SW
FROM score_c; 
窗口无限宽,宽到包括所有行, 从"最靠前的"第1行到“最靠后的”最后1行 ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
UNBOUNDED 与PRECEDING 、联用的时候意思是无限多个,也就是N取无穷大,意思就是向前取无数多行,N大到可以取到表格的第一行,也就是“最靠前”的意思
UNBOUNDED 与FOLLOWING 联用的时候意思还是无限个,也就是N取无穷大,意思就是向后取无数多行,N大到可以取到表格的最后一行,是“最靠后”的意思
SELECT *,SUM(score) OVER(
ROWS BETWEEN
UNBOUNDED PRECEDING
AND
UNBOUNDED FOLLOWING)SW
FROM score_c;所以从头到尾求和,就是直接求某一列的和,其实相当于窗口覆盖整个数据,相当于没有用窗口函数。
所以可以不写

一般这种情况是默认不写的
下面这句默认不写的和上面的效果是一样的
SELECT *,SUM(score) OVER() SW FROM score_c;
效果完全一样吧

窗口无限窄,窄到只有当前行,单独使用CURRENT ROW,窗口窄到只取当前这一行
单独写CURRENT ROW,只写CURRENT ROW。只是语法上是个滑动窗口,实际上这个窗口没有在滑动,就是当前这一行的值
SELECT *,SUM(score)OVER(
ROWS CURRENT ROW)
FROM score_c;
____
ROWS两个特例的解释:ROWS N PRECEDING, ROWS UNBOUNDED PRECEDING
ROWS什么情况下不需要写BETWEEN AND?
ROWS N PRECEDING
和
ROWS UNBOUNDED PRECEDING
如果在ROWS 后面不用BETWEEN...AND... ,而是直接在ROWS 后面加 N PRECEDING或者UNBOUNDED PRECEDING。比如下面这两句命令,都是可以正常运行的没有报错的
SELECT *,SUM(score) OVER(ROWS UNBOUNDED PRECEDING) SW FROM score_c;
SELECT *,SUM(score) OVER(ROWS 2 PRECEDING) SW FROM score_c; 
但是这种写法,MySQL数据库会在N PRECEDING或者UNBOUNDED PRECEDING前后补两个东西,如下, 补的东西是如下括号里这两个东西
ROWS (BETWEEN) N PRECEDING (AND CURRENT ROW)
ROWS (BETWEEN) UNBOUNDED PRECEDING (AND CURRENT ROW)
因为MySQL系统默认补充了 BETWEEN 和AND CURRENT ROW 才不会报错
但是 ROWS N FOLLOWING和 ROWS UNBOUNDED FOLLOWING都是会报错的,原因下面我会解释一下、
ROWS N FOLLOWING报错
SELECT *,SUM(score) OVER(ROWS 2 FOLLOWING) SF FROM score_c;
加上CURRENT ROW以后就不报错了
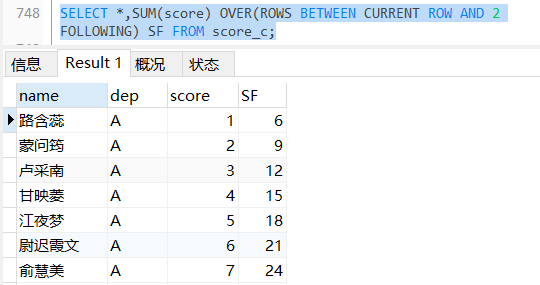
ROWS UNBOUNDED FOLLOWING 报错
SELECT *,SUM(score) OVER(ROWS UNBOUNDED FOLLOWING) SF FROM score_c;
加上CURRENT ROW以后就不报错了

对于没有写BETWEEN AND 的 ROWS语句,会在你写的 ROWS以后的东西 前加BETWEEN , 后面加 AND CURRENT ROW,加完以后就变成下面这样了
ROWS BETWEEN 2 FOLLOWING AND CURRENT ROW
ROWS BETWEEN UNBOUNDED FOLLOWING ADN CURRENT ROW
但是这样的语句,是不符合MySQL语法的,那就是只能从上到下、从前往后,不能从后往前。因此语法错误,遭遇报错
窗口函数

和你说一下,除了上面那些聚合函数,其他的任何函数都是只能用在OVER()窗口函数,脱离了OVER()窗口函数单独用是无法用的,会报错
SUM()
计算同一个班级每个学生占学生总分的比重
SELECT
sname 姓名,
score 分数,
SUM(score) OVER(PARTITION BY cid) 班级总分,
cid 班级,
score/SUM(score) OVER(PARTITION BY cid) 占比
FROM score_1;
计算同一个班级成绩不低于他的分数之和
SELECT
cid,sname,score,SUM(score)
OVER(
PARTITION BY cid
ORDER BY score DESC
)累积分数
FROM score_1;排序类 RANK() DENSE_RANK() ROW_NUMBER()
ROW_NUMBER() 同一个分数的会根据先后排出不同的顺序
SELECT *,ROW_NUMBER()
over(
PARTITION BY cid
ORDER BY score DESC) '不可并列排名'
FROM score_1;下面这三个76分,完全相同的分数,却被排名成了 2 3 4

RANK()同一个分数排名序号相同,都是2。相同的这几个分数以后的就跳到从5开始
SELECT
*,RANK()
OVER(
PARTITION BY cid
ORDER BY score DESC) '跳跃可并列排名'
FROM score_1; 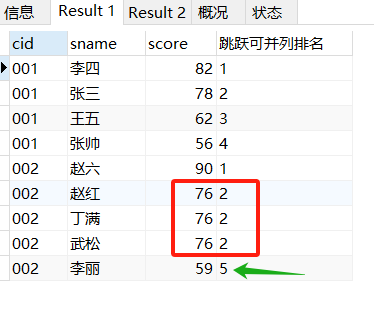
同一个分数段排名相同,都2,但是后面的分数从3开始。
SELECT *,DENSE_RANK()
OVER(
PARTITION BY cid
ORDER BY score DESC) '连续并列排名'
FROM score_1;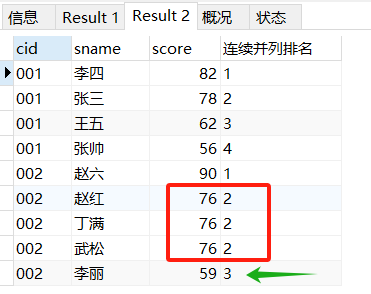
RANK()以及另外两个函数,他们这个三个函数的括号里是不往里面写参数的,也就是不往里面传参。
你一旦像下面这样把排序标准的那一列放进RANK()函数里面了,就会报错
SELECT *,RANK(score) OVER () ranking FROM sc;
真正按照哪一列作为标准进行排序,是在OVER()窗口函数里面用ORDER BY来规定
如果你忘记把排序的那一列写进ORDER BY ,就会每一行单独排名,那么每一行都和自己比,就都是第一名
SELECT *,RANK() OVER() FROM sc; 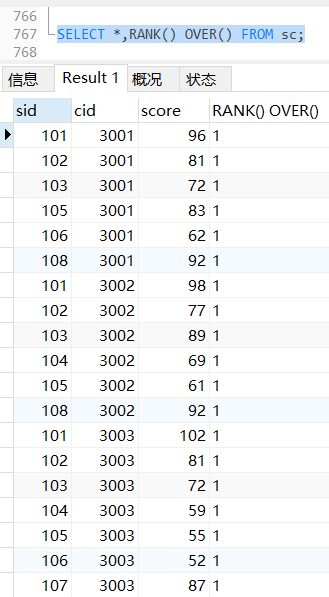
RANK函数还有一个经常的误解,就是RANK函数里是否可以使用ROWS BETWEEN AND 来让每一行在限定的窗口范围内排出这一行的名次
SELECT *,RANK() OVER(
ORDER BY score
ROWS BETWEEN
1 PRECEDING
AND
1 FOLLOWING) 排序
FROM score_rank;滑动窗口加了个寂寞,加上去了,和没加的排序是完全一样的

这种理解是不对的。这说明你还没有对RANK这个函数配合ORDER BY使用的 结果过程有深入的理解
RANK函数是无法脱离ORDER BY来使用的,一旦一起使用,就已经把score这一列从1排到16这样排好了
即使你再加上ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING.按道理升序排列,前一个是第1名,后一个是第3名,这一行应该排第2名,但是并没有把所有的行都排成第2名,而是用的原来的顺序
这就说明ROWS BETWEEN AND在配合RANK() ORDER BY使用的时候,是完全失效的
跨行偏移LAG LEAD
每一个GROUP向下偏移的一格
SELECT
*,LAG(score,1)
OVER(
PARTITION BY cid
ORDER BY score DESC)
FROM score_1;
每个GROUP向上偏移一格
SELECT
*,LEAD(score,1)
OVER(
PARTITION BY cid
ORDER BY score DESC)
FROM score_1;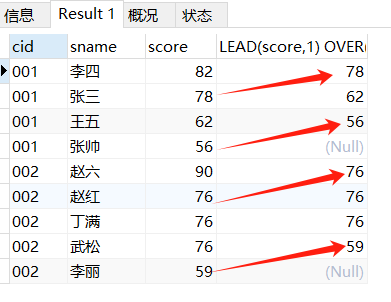
LAG/LEAD 函数 参数 1:比较的列 参数 2: 偏移量 参数 3:找不到时显示的默认值
第三个参数就是 上移下移空出来的那个NULL应该用什么来填充
SELECT *,
LEAD(score,1,0)
OVER(
PARTITION BY cid
ORDER BY score DESC)
FROM score_1; 
Window AS 窗口函数的别名
窗口函数可以这样写
你可以不用,但是你得知道有这种写法,别人这样写你得知道是什么意思
其实就是给窗口函数这一系列的限定条件起一个别名,这样就可以把这一大坨东西放在结尾,不影响你阅读了解整段命令的意思。
SELECT *,RANK() OVER 窗口函数的别名 AS 'rank' FROM score_1
window 窗口函数的别名 (窗口函数OVER里面的内容);
SELECT *,RANK() OVER t1 AS 'rank' FROM score_1
window t1 AS (ORDER BY score DESC);统计出每门课cid上成绩最高的前三名
sc数据是这样的
首先分组进行排序
SELECT *,RANK() OVER t1 AS 'rank' FROM sc
window t1 AS (PARTITION BY cid ORDER BY score DESC); 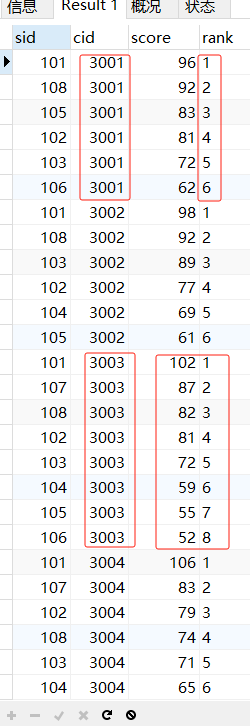
限定 只要每门课的前三名
这个时候如果你直接在后面加WHERE或者HAVING的话就会报错
SELECT *,RANK() OVER t1 AS 'rank' FROM sc
window t1 AS (PARTITION BY cid ORDER BY score DESC)
WHERE rank<=3; 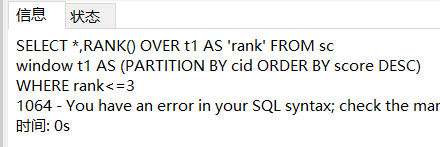
这个时候你需要把前面这一串放进FROM里面再加限定条件,其实就是嵌套
SELECT * FROM(
SELECT *,RANK() OVER(PARTITION BY cid ORDER BY score DESC) 排名 FROM sc) t1
WHERE 排名<=3;但是你要注意嵌套的这一层FROM(这一大片必须起一个代称,如果你不起代称,就会报错)

WITH AS 多个字句取别名
如果一整句查询中多个子查询都需要使用同一个子查询的结果,那么就可以用 with as,将共用的
子查询提取出来,加个别名。后面查询语句可以直接用,对于大量复杂的 SQL 语句起到了很好的
优化作用。
注意:
相当于一个临时表,但是不同于视图,不会存储起来,要与 select 配合使用。
同一个 select 前可以有多个临时表,写一个 with 就可以,用逗号隔开,最后一个 with 语句
不要用逗号。
with 子句要用括号括起来。
含义和上面那个一样,但是写法不同
WITH t AS
(SELECT *,ROW_NUMBER() OVER(PARTITION BY cid ORDER BY score DESC)
AS 'ranking'
FROM sc)
SELECT * FROM t WHERE ranking<=3;
找出每门课成绩都高于平均分的学生
高于平均分,这个不能说算一列平均分出来,然后把分数和平均分进行对比,只保留下来高的。这样整列的对比是会报错的
WITH avg_s AS
(SELECT AVG(score) OVER(PARTITION BY cid) AS avg_col FROM sc)
SELECT * FROM sc WHERE score > avg_s.avg_col;
上面这个报错教给我们这样一个规律,那就是SQL里只能拿着一列和一个数字比,但是不能整个一列和另一列比较
既然无法直接对比两列,那么可以算两列的差,然后只取差大于零的即可
首先我们把每个人和平均分之间的差距算出来
WITH t1 AS(
SELECT *,AVG(score) OVER(PARTITION BY cid) AS score_avg FROM sc)
,
t2 AS(SELECT *,score - score_avg AS score_diff FROM t1)
SELECT * FROM t2
这个时候你要问了我为什么不直接加个WHERE和HAVING把大于零的部分筛选出来不久行了?
你错了,题目是让你把所有课程分数都高于平均分 的 学生筛出来。而你上面筛出来的是每个学生考的分数大于平均分的那些
你需要的是使用MIN()函数先把每个人的最低分选出来,然后把最低分大于零的筛选出来
WITH t1 AS(
SELECT *,AVG(score) OVER(PARTITION BY cid) AS score_avg FROM sc)
,
t2 AS(SELECT *,score - score_avg AS score_diff FROM t1)
SELECT * FROM t2
WHERE score_diff > 0;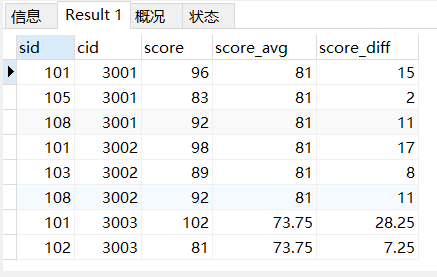
所以此时你先用GROUP BY按照学生分组,然后再在同一个组内再求最小值
WITH AS 的写法
WITH t1 AS(
SELECT *,AVG(score) OVER(PARTITION BY cid) AS score_avg FROM sc)
,
t2 AS(SELECT *,score - score_avg AS score_diff FROM t1)
SELECT sid FROM t2 GROUP BY sid HAVING MIN(score_diff)>0; t1的作用是把均分算出来
t2的作用是吧每个人的分数和均分之间的差算出来
最后一步从t2中取数据,把每个GROUP里面最低分大于0的筛选出来,就是所有分数都高于平均分的这个群体
MIN(score_diff)配合前面的GROUP BY sid,算的是每一个学生的所有科目的最低分
关于这个WITH AS这个东西里面变量是如何引用的,我解释一下
t1中算出的score_avg,然后这个均分被和score做了减法 然后放进了t2里面。然后再从t2中取出你想要的 大于均分那些人的名单
SELECT FROM 嵌套写法
要拿到的是学生的学号,所以上来就写sid
SELECT sid FROM(
SELECT *,score - AVG(score) OVER(PARTITION BY cid) AS score_diff FROM sc) t1
GROUP BY sid
HAVING MIN(score_diff) > 0;
这里你要注意,这句话里面的GROUP BY sid这句话

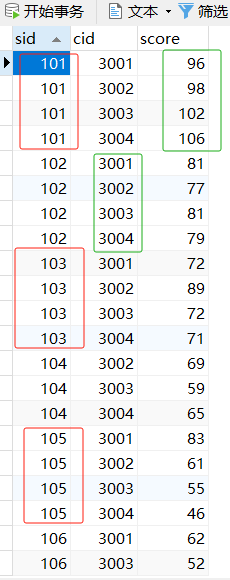
sc这个表长成这样 ,cid是不同的班级,sid是每个学生的学号,score里面是 这个学生、这门课的分数
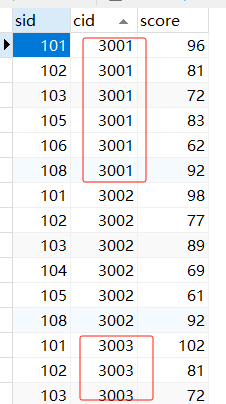
你的这个GROUP BY是按照学生sid来分组以后,你的SELECT必须特别注意,这种分组的情况下,你SELECT只有2种选择
(1)要么是sid这一列以外的其他列的 SUM() MAX() MIN() RANK() 这些一个sid组经过这些函数计算的结果
(2)要么是sid这一列本身。
我把这两种选择都放进一个表里了你可以看看
SELECT sid,AVG(score),MAX(cid),MIN(cid) FROM(
SELECT *,score - AVG(score) OVER(PARTITION BY cid) AS score_diff FROM sc) t1
GROUP BY sid
HAVING MIN(score_diff) > 0;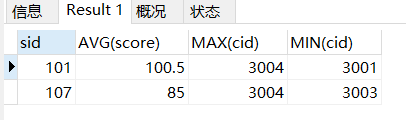
一旦你的SELECT超出了我上面说的这些这两个类别,比如说你GROUP BY的是sid,但是你SELECT选择了 其他列比如cid,就会报下面这个错误


会报错的原因其实很好理解。你以sid学号进行分组那么101对应了4个分数,你如果SELECT score的话,电脑怎么知道你要的是101对应的这个四个分数中的哪一个呢?只能输出一个数字的情况下,当然是要么输出小组的名字sid这一个数字,又或者你给一个整合的标准 SUM也好、COUNT()也好、MAX()也好总之搞一个函数把这4个数字通过某种计算整合成一个数字输出即可。
窗口函数作业
目前有这样一个数据
USE damiao_sql;
CREATE TABLE sal (
empno varchar(4),
ename varchar(10),
hire_date varchar(10),
salary int,
dept_no varchar(2) );
insert into sal (empno, ename, hire_date, salary, dept_no) values ('001','Adam', '2018-03-01', 10000, 'A');
insert into sal (empno, ename,hire_date, salary, dept_no) values ('002', 'Bill', '2021-03-01', 12000,'A');
insert into sal (empno, ename, hire_date, salary, dept_no) values('003', 'Cindy', '2016-03-01', 15000, 'A');
insert into sal (empno, ename,hire_date, salary, dept_no) values ('004', 'Danny', '2020-03-01', 50000,'A');
insert into sal (empno, ename, hire_date, salary, dept_no) values('005', 'Eason', '2020-03-01', 40000, 'B');
insert into sal (empno, ename,hire_date, salary, dept_no) values ('006', 'Fred', '2018-03-01', 15000,'B');
insert into sal (empno, ename, hire_date, salary, dept_no) values('007', 'Gary', '2017-03-01', 8000, 'B');
insert into sal (empno, ename,hire_date, salary, dept_no) values ('008', 'Hugo', '2020-03-01', 5000,'B');
①求出每个部门工资最高的前三名员工
这个题逻辑很简单,(1)先按照部门进行分组,(2)然后按照工资salary在每个组内排序,降序排序(3)添加限定条件,只保留每个组的前三名
我们先不做前三名的筛选,只把分组和排序做出来
分组用PARTITION BY
排序用RANK()配合ORDER BY 来实现
SELECT *,RANK() OVER(
PARTITION BY dept_no
ORDER BY salary)
FROM sal;
这里容易出错的这个点,在限定条件这里。
有的人会误把OVER()窗口函数中的 ROWS BETWEEN 用在这里,
但是其实你是没法用ROWS BETWEEN AND的。你说吧你想怎么用?
前三行,这个ROWS BETWEEN AND你怎么写?降序排列,ROWS BETWEEN UNBOUNDED PRECEDING AND 写什么呢?
从开头开始取就是UNBOUNDED PRECEDING,向后3行如何表示呢?3 FOLLOWING吗?
可是BETWEEN UNBOUNDED PRECEDING AND 3 FOLLOWING表示的是从最前面那一行(第一行)到现在这一行(CURRENT ROW)然后再往下取3行,所以一共有N+1+3行,并不是取了3行
并且你需要知道OVER()里面写的这个BETWEEN AND并不是RANK函数计算后再用一个取值范围做二次筛选,这个BETWEEN AND恰好是在RANK出结果以前,设定这个RANK该如何计算。所以你选错了,想对RANK计算结果进行二次筛选应该用HAVING 或 WHERE 而不是 BETWEEN AND
再给你补充一点,使用RANK 函数,这个时候你再同时使用BETWEEN AND 无论你BETWEEN 和AND 这两个写什么对最后的结果都不会造成任何影响。也就是说使用RANK()窗口函数的情况下,再叠加使用BETWEEN AND,无论BETWEEN AND 里面加什么都是无效的。
如果你不信的话,我们来展示一下,对于SUM()这个函数来说 ROWS BETWEEN AND就是起作用的
不加ROWS BETWEEN的时候,是依照salary的顺序从前向后累积求和
SELECT *,SUM(salary) OVER(
ORDER BY salary)
FROM sal;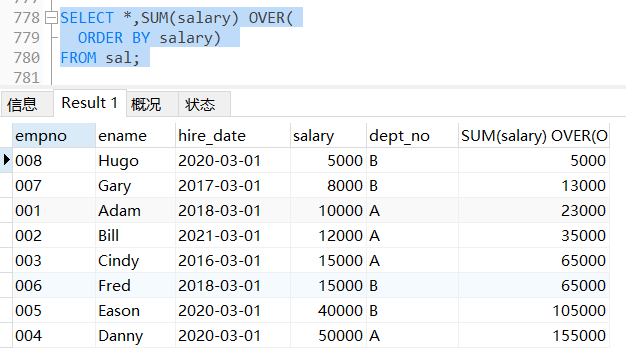
一旦按照你的要求加上BETWEEN AND, SUM()的时候计算当前行到最后一行,也就计算出一个从下而上的累计求和
这证明了一点 ROWS BETWEEN在SUM()等RANK()以外的其他函数都是有限定计算范围的作用的
SELECT *,SUM(salary) OVER(
ORDER BY salary
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
FROM sal; 
但是一旦到了RANK,ROWS BETWEEN AND就完全失效了
使用ROWS BETWEEN之前是按照salary这一列排序
SELECT *,RANK() OVER(
PARTITION BY dept_no
ORDER BY salary)
FROM sal; 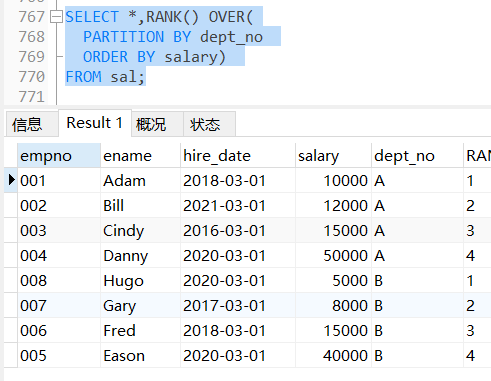
但是即使是你加上了ROWS BETWEEN的限定,让计算RANK()的时候每一行都的RANK按照当前行到最后一行这范围来排序,
按道理每一行到最后一行的排序,当前行应该都是排第1,
但是排名仍然没有任何区别,还是按照salary这一列来排的,这就说明用RANK()的时候使用BETWEEN AND是完全无效的
SELECT *,RANK() OVER(
PARTITION BY dept_no
ORDER BY salary
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
FROM sal; 
下面我们去加限定条件,把么个部门分前三名筛选出来,前三名以外的,比如第四名,就筛选掉
常见的错误是下面这种,直接用HAVING来限定
SELECT *,RANK() OVER(
PARTITION BY dept_no
ORDER BY salary)
AS ranking FROM sal
HAVING ranking <=3; 
这里报错的原因是下面这样:你试图在计算ranking这一列之前,就对ranking进行筛选.
人家还没制造出ranking这一列,在没有这一列之前就引用它、使用它,当然会报错
但是你也不要误解并不是所有的函数都不可以在计算结果出来前就加WHERE或HAVING。其实只有窗口函数这几个,如RANK()需要拿到结果后用SELECT再嵌套一层
窗口函数,比如聚合函数,就是可以同时计算、同时又用这个计算值来筛选。但是窗口函数这些都是不能的,需要先计算,再从另一个字句中引用来使用
加HAVING 之前
SELECT SUM(salary) ss FROM sal GROUP BY dept_no HAVING ss>70000; 
加HAVING以后,没有报错,可以实现过滤
SELECT SUM(salary) ss FROM sal GROUP BY dept_no HAVING ss>70000; 
既然RANK函数需要先拿到结果再筛选,你此时就要用SELECT 嵌套SELECT. 一个SELECT RANK()拿到结果以后,再外面套一层SELECT 用限定条件,把想要的筛选出来
方法1:SELECT FROM 里面套一个SELECT
这里注意必须给字句起别名alias否则会报错
SELECT * FROM(
SELECT *,RANK() OVER(PARTITION BY dept_no ORDER BY salary) AS ranking FROM sal
) AS subquery
WHERE ranking<=3; 
方法2:WITH 字句名 AS(RANK计算的过程的那个SELECT) SELECT * FROM 前面那个字句
FROM后面的东西不变,把这个东西用WITH AS 写在的前面
WITH subquery AS
(
SELECT *,RANK() OVER(PARTITION BY dept_no ORDER BY salary) AS ranking FROM sal
)
SELECT * FROM subquery WHERE ranking<=3; 
②计算这些员工的工资占所属部门总工资的百分比
SELECT *,salary/SUM(salary) OVER(PARTITION BY dept_no) AS per_in_dp FROM sal;

③对各部门员工的工资进行从小到大排序,排名前 30%为低层,30%-80%为中层,高于 80%
为高层,并打上标签
(S1)计算这些员工的工资占所属部门总工资的百分比
SELECT *,salary/SUM(salary) OVER(PARTITION BY dept_no) AS per_in_dp FROM sal; 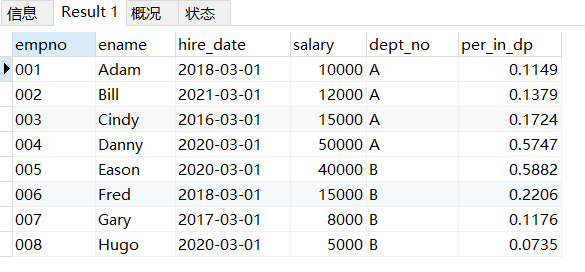
对各部门员工的工资进行从小到大排序,排名前 30%为低层,30%-80%为中层,高于 80%为高层,并打上标签
(S2)需要把这个比例做一个累积求和(salary自UNBOUNDING PRECEDING 到CURRENT ROW做累积求和,再除以部门的SUM)
SELECT *,
SUM(salary) OVER(
PARTITION BY dept_no
ORDER BY salary
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
/
SUM(salary) OVER(PARTITION BY dept_no)
AS fir_per
FROM sal;
(S3)用CASE WHEN 对累积求和这个进行分类赋值
排名前 30%为低层,30%-80%为中层,高于 80%为高层,并打上标签
写CASE WHEN 的时候经常会犯下面这个错误。那就是对窗口函数计算得出的这一列,在当前这个SELECT语句就调用。
这样会报错,是因为任何使用OVER函数计算出来的列,不能立刻调用,必须外面多嵌套一层SELECT进行调用
SELECT *,
SUM(salary) OVER(PARTITION BY dept_no ORDER BY salary ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
/
SUM(salary) OVER(PARTITION BY dept_no)
AS fir_per,
CASE
WHEN fir_per<=0.2 THEN '高层'
WHEN fir_per>0.2 AND fir_per<=0.7 THEN '中层'
WHEN fir_per>0.7 THEN '低层'
END 工资等级
FROM sal;
这里会报错的原因是:在使用窗口函数OVER()计算一个东西的过程里,当这个SELECT语句没结束的时候,这个窗口函数计算出来的东西就会算不出来。
一个东西你还没算出来,你就引用他,自然会报错
这里说明不只是RANK这种窗口函数独有的函数,不能在SELECT前引用数据
就连SUM这种本身是聚合函数的函数,用了OVER()窗口函数以后,SELECT这句结束以后 才能用里面的数据,不能同时拿

正确的写法
(1) SELECT嵌套
对各部门员工的工资进行从小到大排序,排名前 30%为低层,30%-80%为中层,高于 80%为高层,并打上标签
SELECT *,CASE
WHEN fir_per>0.8 THEN "高层"
WHEN fir_per>0.3 THEN '中层'
ELSE '低层'
END 等级
FROM
(
SELECT *,
SUM(salary) OVER(PARTITION BY dept_no ORDER BY salary DESC ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
/
SUM(salary) OVER(PARTITION BY dept_no)
AS fir_per
FROM sal
) AS subquery; 
(2)WITH AS 写法
WITH subquery AS(
SELECT *,
SUM(salary) OVER(PARTITION BY dept_no ORDER BY salary DESC ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
/
SUM(salary) OVER(PARTITION BY dept_no)
AS per
FROM sal)
SELECT
*,
CASE
WHEN per>=0.8 THEN '高层'
WHEN per>=0.3 THEN '中层'
ELSE '低层'
END 等级
FROM subquery; 
④统计每年入职总数以及截至本年累计入职总人数(本年总入职人数 + 本年之前所有年的
总入职人数之和)
首先你需要从hire_date这一列取出年份,
SELECT *,YEAR(hire_date) AS year FROM sal;然后按照年份来PARTITION BY 然后在ORDER BY 最后COUNT(*)
但是YEAR()这个函数的结果,不能当场生产当场使用,而是需要生产完,外面多嵌套一层SELECT才能把生产出来的数据取出使用
下面这句会报错
SELECT *,
YEAR(hire_date) AS year,
COUNT(year) OVER(PARTITION BY year) AS y_count
FROM sal;
方法1:WITH AS 嵌套
先把每一个年份的 出现次数 数出来
WITH subquery AS
(
SELECT *,YEAR(hire_date) AS year FROM sal
)
SELECT *,COUNT(*) OVER(PARTITION BY year) FROM subquery; 
但是这里你不能简单的把y_count自顶向下累积求和,因为这样出现2次的2018年会被数成出现4次
所以需要新建一列,让每一行都是1,然后再用累积求和。
语法是下面这么写,新建一列这一列全是1
-- 添加新列
ALTER TABLE your_table_name
ADD new_column_name INT;
-- 更新新列的所有值为1
UPDATE your_table_name
SET new_column_name = 1;但是为了计算一个东西,修改原始数据是不值得的。可以考虑下面这种,在SELECT的时候临时添加一列全是1的一列,然后再累积求和
语法是下面这样写
SELECT column1, column2, 1 AS new_column_name
FROM your_table_name;
用起来这样写
WITH subquery AS
(
SELECT *,YEAR(hire_date) AS year FROM sal
)
SELECT *,
COUNT(*) OVER(
PARTITION BY year
ORDER BY year)
AS y_count,
1 AS one
FROM subquery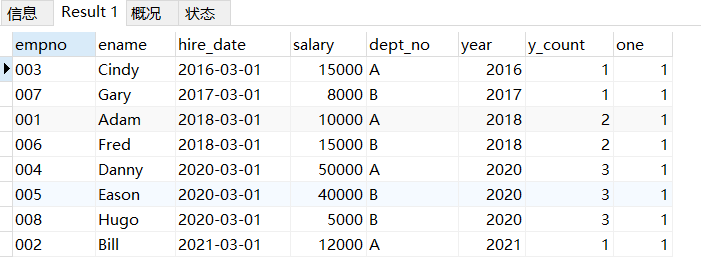
后续求和。如果你希望同一个排名的所有行共用一个求和SUM数据,那么使用SUM()搭配OVER()窗口函数里的ORDER BY即可实现同位次共享
这里SUM()配合ORDER 以后,默认的是自顶向下累计求和(完全不需要ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW来做自上而下的累积求和,特别巧妙,且完美契合这里的需求
SELECT *,SUM(one) OVER(ORDER BY year) AS cy_count_cum FROM
(
WITH subquery AS
(
SELECT *,YEAR(hire_date) AS year FROM sal
)
SELECT *,COUNT(*) OVER(PARTITION BY year ORDER BY year) AS y_count,1 AS one
FROM subquery
) as sub1 
方法2:GROUP BY
这个地方最适合的是直接用GROUP BY ,这样就避免了2个的数据同时出现两个2(不需要建立叫one的这一列)
这里不同于RANK()以及使用了窗口函数的SUM(), SELECT这一次本身就是可以当场调用,不用SELECT外面再套一层壳,才能调
SELECT *,SUM(y_count) OVER(ORDER BY year) AS cum_y_c FROM
(
WITH sub1 AS
(
SELECT *,YEAR(hire_date) AS year FROM sal
)
SELECT year,COUNT(*) AS y_count FROM sub1 GROUP BY year
-- ORDER BY year # 不加这句ORDER BY的话,年份的顺序是乱的
-- 但是这句ORDER BY其实不用写,因为上面做SUM的时候,窗口函数里面就有ORDER BY,做按次序累积求和的基础上连带排名也做了
) AS sub1
;1, 连续问题:找出这张表中所有的连续 3 天登录用户
数据是下面这样
CREATE TABLE Log ( user_id varchar(2), login_date date );
INSERT INTO Log (user_id,login_date) VALUES
('A', '2022-09-02'),
('A','2022-09-03'), ('A', '2022-09-04'), ('B', '2021-11-25'), ('B',
'2021-12-31'), ('C', '2022-01-01'), ('C', '2022-04-04'), ('C',
'2022-09-03'), ('C', '2022-09-05'), ('C', '2022-09-04'), ('A',
'2022-09-03'), ('D', '2022-10-20'), ('D', '2022-10-21'), ('A',
'2022-10-03'), ('D', '2022-10-22'), ('D', '2022-10-23'), ('B',
'2022-01-04'), ('B', '2022-01-05'), ('B', '2022-11-16'), ('B',
'2022-11-17');
(S1) 把同一天,同一个用户点击 的重复数据去重
DISTINCT 单独用 确实可以把非重复的用户ID筛选出来,是下面这样
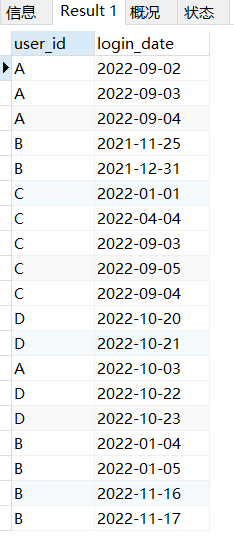
SELECT DISTINCT user_id FROM log;
但是SELECT DISTINCT和其他列一起中的时候,重复的用户ID还是保留
SELECT DISTINCT user_id, login_date FROM log;下图中你可以看到user_id中有很多重复的 A B C
但是你此时要问 加了一个DISTINCT,下面这两句话的区别是什么?
SELECT DISTINCT user_id, login_date FROM log;SELECT user_id, login_date FROM log;
我在这里要打破各位的一个错误观念:
DISTINCT 放在user_id之前,并不是说只让user_id保留不重复的项,但是login_date就可以保留重复的项、不去重。
DISTINCT 放在user_id和login_date之前,的真实含义是,让user_id和login_date二者的组合 取不重复的。
不信的话你给user_id和login_date分别加一个DISTINCT,你的目的肯定是想同时对user_id和login_date进行去去重,只保留非重复、独一无二的项。下面就这样写了,会报错 。
SELECT DISTINCT user_id, DISTINCT login_date FROM log; 
首先这不符合SQL的语法。其次对两列同时去重,是不现实的,user_id和login_date非重复的两项可能根本不在同一行,你如何组织这个表格呢?自然会报错。
所以说,如果DISTINCT的用法只有两种
(1)DISTINCT后面有一列的话,让后面那一列只保留不重复的行
(2)DISTINCT后面有非常多列,别管是2列、3列或更多,统统只保留这些列的不重复的组合log
SELECT user_id, login_date FROM log;
SELECT DISTINCT user_id, login_date FROM log;下面我们来对比一下这两句话,看看加了DISTINCT以后哪一行被去重删掉了,表格各项的顺序有没有变化
其实这一步的作用就是,把那些同一天、同一个用户登录的这些重复信息去重掉,避免同一个用户一天登录了两次被算作登录了2天

但是这里有个让我不太理解的事情
只是加了了一个DISTINCT 为什么筛选出的连续3日登录的人数反而少了,没有了A?
这是为什么呢?
明明加个DISTINCT,取出的数据少了一行,为什么最后统计出的3日连续登录的人反而没有了A。并且A还确实是连续3日登录的用户。
正确答案,加了DISTINCT的用法
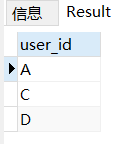
with
t1 as ( select distinct user_id, login_date from log ) ,
t2 as ( select *, row_number() over (partition by user_id order by login_date) as rn from t1 ) ,
t3 as ( select *, DATE_SUB(login_date, interval rn day) as sub from t2 )
select distinct user_id from t3 group by user_id, sub
having count(user_id) >= 3;出来结果是正确的,确实是A C D是连续3日登录的用户,B不是
不加DISTINCT的错误写法,A这个3日连续登录用户被吞掉了,没有显示出来。也不知道是为啥。
with
t1 as ( select user_id, login_date from log ) ,
t2 as ( select *, row_number() over (partition by user_id order by login_date) as rn from t1 ) ,
t3 as ( select *, DATE_SUB(login_date, interval rn day) as sub from t2 )
select distinct user_id from t3 group by user_id, sub
having count(user_id) >= 3; 
(S2)下一步针对每个用户的每次点击按照时间顺序排序,第一次点击就排第1,第二次点击就排第2
正确的写法
with
t1 as ( select distinct user_id, login_date from log ) ,
t2 as ( select *, row_number() over (partition by user_id order by login_date) as rn from t1 ) ,
t3 as ( select *, DATE_SUB(login_date, interval rn day) as sub from t2 )
select distinct user_id from t3 group by user_id, sub
having count(user_id) >= 3;我想知道,如果不写ORDER BY会怎样?
不加ORDER BY的话是原始表格每行什么顺序就是什么顺序,加了ORDER BY虽然对 ROW_NUMBER()这个函数没有影响,但是加了ORDER BY,行与行之间的顺序会按照时间顺序来排列
当我问你这个问题你时候,你觉得我很可笑、简直rediculous。你写ROW_NUMBER()这个函数就是为了排出个1 2 3 4 5 ,排个序,不指定按照哪行来排序,这电脑怎么排?会报错吧?不会的。如果你不指定按照哪行排序,就会把每个GROUP里面数据按照在原始表格上的相对顺序来进行排序,给排个号。
不加ORDER BY,按照表格的原始顺序来
WITH
t1 as ( select distinct user_id, login_date from log )
select *, row_number() over (partition by user_id) as rn from t1;加了ORDER BY以后,所有的行 按照login_date 升序排列
WITH
t1 as ( select distinct user_id, login_date from log )
select *, row_number() over (partition by user_id order by login_date) as rn from t1; 我们这个数据集比较特别,大多数的数据是按照访问先后从上往下排列的,但是用户C点击数据是9月5号在上面,9月4号在下面,日期顺序如果是乱的(不是早一些的时间在上面,晚一些的时间在下面),我们又怎么通过日期判断这个人是否有三天的登录是连续的呢?
所以ROW_NUMBER()排序的时候必须指定login_date时间这一列按顺序排列,否则后面就无法判断连续3天登录

我想知道这里为什么一定要用t1这个子句,为什么不能不用子句,把两个子句合并成一个来用呢?
就是我想从原来这样写
with
t1 as ( select distinct user_id, login_date from log )
select *, row_number() over (partition by user_id order by login_date) as rn from t1改成下面这样写,不用子句,一句话搞定
SELECT
DISTINCT user_id,login_date,ROW_NUMBER() OVER(
PARTITION BY user_id
ORDER BY login_date)
AS rn
FROM log;答案是不能
这里我说不能最大的原因是因为DISTINCT这个关键字。如果这里用的不是DISTINCT,而是SLELCT user_id,login_date 这样的话,你计算ROW_NUMBER()的时候 不需要再外面套一个子句,直接调用即可
前者是在用户ID和登录时间这个组合上去重,然后在去重的基础上,再把每个用户,每次登录的排序的序号排出来
后者是兼顾 用户ID 登录时间 和 每个用户的时间排序上每次点击 都排序 排上一个数字,后者追求的是三者组合的 unique唯一性。后者会比前者多几行。因为本来用户ID和登录时间完全相同的两行,因为排序用的ROW_NUMBER() 相同的东西多排了一个序号而被判定为一种新的组合而被保留下来了
这样我们就平白无故的多了两行学生ID一样,登录时间一样,同一天的数据,但是只是排序数字不同的一行。这样会导致某些连续2天登录,当时其中一天登录了2次的人被判定为连续2天登录就出错了

(S3)t3这句话是为了标记哪些用户是连续多天访问
通过时间差这个东西
每个用户最早一次访问被排序为1,第二次访问被排序为2
只需要通过所有的访问日期减去 排序 号码数,就能算出 这一天之前 序号数 天 之前那天是 哪一天
因为时间是排序过的,是连续的,不可能出现 上面一个 之前那天 是 11月24日, 下面一个是10月1号
因此只需要统计 前 序号数 天 的那个日期数量是否大于2个即可
with
t1 as ( select distinct user_id, login_date from log ) ,
t2 as ( select *, row_number() over
(partition by user_id
order by login_date)
as rn
from t1 )
select *,
DATE_SUB(login_date, interval rn day)
as sub
from t2 DATE_SUB()这个函数怎么用我再解释一下
日期减法,就是这么用
DATE_SUB(一个日期或日期这一列, INTERVAL 具体的数字或者一列数字 DAY)
DATE_SUB('2023-01-01', INTERVAL 7 DAY)
INTERVAL表示间隔,必须写。DAY的话是减去的单位,可以是月MONTH,也可以是年YEAR
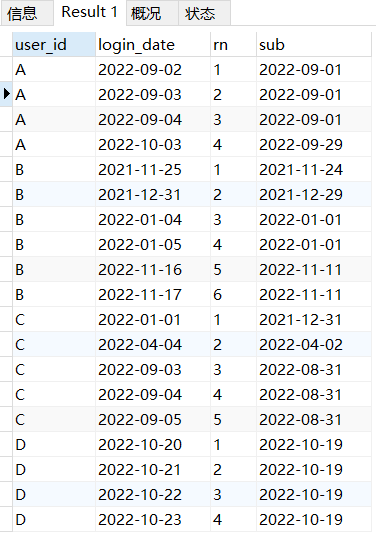
(S4)上面sub这一列,日期相同的说明他们就是连续N天访问的,下一步只需要把连续访问超过3天的过滤出来即可
WITH
# (S1)先把一天登录多次的数据去掉
t1 AS (SELECT DISTINCT user_id,login_date FROM log),
# (S2)所有的行按照升序排列来组织,所有对于每个用户的访问,按照时间顺序 打上排序的序号。后面会用这个序号做计算,辨别出连续几日登录了
# 因为上一步已经去重看了,所以不存在并列排名的,这里用ROW_NUMNBE()、RANK()、DENSE_RANK()效果都是一样的
t2 AS (SELECT *,ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY login_date) AS ranking FROM t1),
# (S3) 让每一个访问日期login_date减去 前面的排名,后面以减去 剩下的日期为准 ,有几个相同的日期,就是连续登录几天
t3 AS(SELECT *,DATE_SUB(login_date, INTERVAL ranking DAY) AS fir_day FROM t2),
# (S4)把同一个 减去剩下的日期 进行分组,统计每个GROUP元素个数大于3个的user_id和次数
t4 AS(SELECT *,COUNT(fir_day) OVER(PARTITION BY fir_day,user_id) AS cum_log_d FROM t3)
SELECT * FROM t4 WHERE cum_log_d>=3;
你注意上面这个t4里面 不管是这里用的PARTITION BY还是之前答案用的GROUP BY都是必须同时囊括fir_day和user_id的,因为极有可能,其他用户的 “之前的时间” 和这个用户是一样的,而被误分到同一类里面。这样同一个时间的不同用户被归类为一类了,
因为t1已经去重了,所以不存在并列排名的,这里用ROW_NUMNBE()、RANK()、DENSE_RANK()效果都是一样的
RANK()、DENSE_RANK()替代ROW_NUMBER()你试试
换上 RANK()
WITH
# (S1)先把一天登录多次的数据去掉
t1 AS (SELECT DISTINCT user_id,login_date FROM log),
# (S2)所有的行按照升序排列来组织,所有对于每个用户的访问,按照时间顺序 打上排序的序号。后面会用这个序号做计算,辨别出连续几日登录了
# 因为上一步已经去重看了,所以不存在并列排名的,这里用ROW_NUMNBE()、RANK()、DENSE_RANK()效果都是一样的
t2 AS (SELECT *,RANK() OVER(PARTITION BY user_id ORDER BY login_date) AS ranking FROM t1),
# (S3) 让每一个访问日期login_date减去 前面的排名,后面以减去 剩下的日期为准 ,有几个相同的日期,就是连续登录几天
t3 AS(SELECT *,DATE_SUB(login_date, INTERVAL ranking DAY) AS fir_day FROM t2),
# (S4)把同一个 减去剩下的日期 进行分组,统计每个GROUP元素个数大于3个的user_id和次数
t4 AS(SELECT *,COUNT(fir_day) OVER(PARTITION BY fir_day,user_id) AS cum_log_d FROM t3)
SELECT * FROM t4 WHERE cum_log_d>=3;
效果完全一样

换上DENSE_RANK()
WITH
# (S1)先把一天登录多次的数据去掉
t1 AS (SELECT DISTINCT user_id,login_date FROM log),
# (S2)所有的行按照升序排列来组织,所有对于每个用户的访问,按照时间顺序 打上排序的序号。后面会用这个序号做计算,辨别出连续几日登录了
# 因为上一步已经去重看了,所以不存在并列排名的,这里用ROW_NUMNBE()、RANK()、DENSE_RANK()效果都是一样的
t2 AS (SELECT *,DENSE_RANK() OVER(PARTITION BY user_id ORDER BY login_date) AS ranking FROM t1),
# (S3) 让每一个访问日期login_date减去 前面的排名,后面以减去 剩下的日期为准 ,有几个相同的日期,就是连续登录几天
t3 AS(SELECT *,DATE_SUB(login_date, INTERVAL ranking DAY) AS fir_day FROM t2),
# (S4)把同一个 减去剩下的日期 进行分组,统计每个GROUP元素个数大于3个的user_id和次数
t4 AS(SELECT *,COUNT(fir_day) OVER(PARTITION BY fir_day,user_id) AS cum_log_d FROM t3)
SELECT * FROM t4 WHERE cum_log_d>=3;效果完全一样

答案2
with t1 as ( select distinct user_id, login_date from log ),
t2 as ( select
*,
DATEDIFF(login_date, lag(login_date, 1) over (
partition by user_id
order by login_date))
as diff,
DATEDIFF(
login_date,
lag(login_date, 2)over (partition by user_id order by login_date))
as diff2 from t1
)
select distinct user_id from t2 where diff = 1 and diff2 = 2 group by user_id;(S1) 对 user_id和login_date的组合进行去重,同一用户、同一天只保留一个登录记录
select distinct user_id, login_date from log(S2)把这一天距离上一行时间的日期差 和这一天距离前面2行的日期差算出来
计算日期差用下面这个函数
首先讲解一下DATEDIFF这个函数是怎么用的
SELECT DATEDIFF('2023-01-21', '2023-01-10')两个参数,前面的日期减去后面的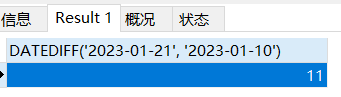
然后再讲讲LAG函数是怎么用的
将时间向下退一个格
SELECT *,lag(login_date, 1) over (
partition by user_id
order by login_date)
FROM log;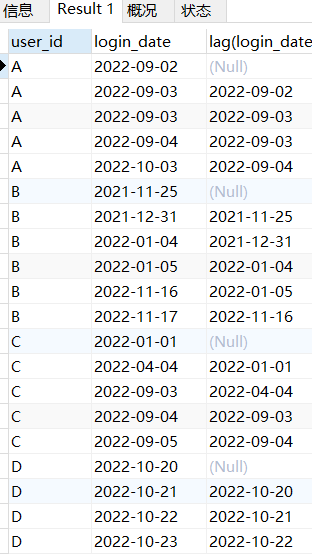
将时间向下退两格
SELECT *,lag(login_date, 2)over (
partition by user_id
order by login_date)
FROM log; 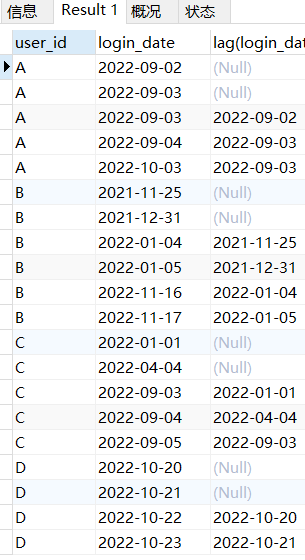
减数 和被减数 都有了下面减一下
with t1 as ( select distinct user_id, login_date from log )
select
*,
# 向下退一格
lag(login_date, 1) over (
partition by user_id
order by login_date)
AS 退一格,
# 第一列:第一天的时间差
DATEDIFF(
login_date,
lag(login_date, 1) over (
partition by user_id
order by login_date)
)
as diff,
# 向下退2格
lag(login_date, 2)over (
partition by user_id
order by login_date)
AS 退两格,
# 第二列:第二天的时间差
DATEDIFF(
login_date,
lag(login_date, 2)over (
partition by user_id
order by login_date)
)
as diff2
from t1 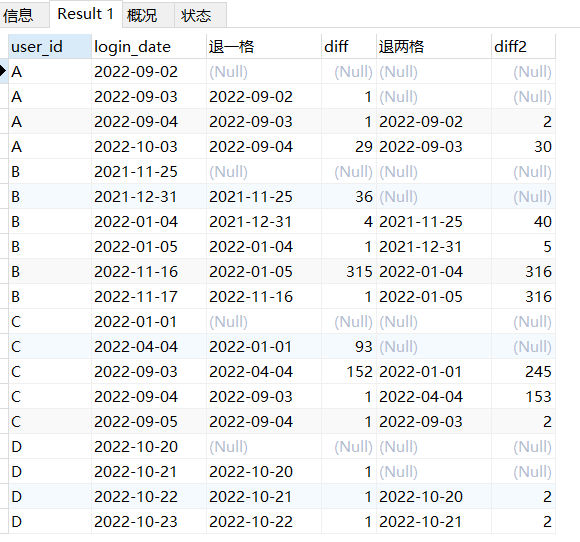
(S3)筛选出连续3天登录的人
前面一格的日期差表示紧邻的两天是连续登录,前面两格的时间是判断这一天和隔一天的时间是否都登录了
只要满足这一天和前一天都登陆了 和这一天和前两天都登陆了,就满足连续3天登录
with t1 as ( select distinct user_id, login_date from log ),
t2 as ( select
*,
DATEDIFF(
login_date,
lag(login_date, 1) over (
partition by user_id
order by login_date))
as diff,
DATEDIFF(
login_date,
lag(login_date, 2)over (partition by user_id order by login_date))
as diff2
from t1
)
select distinct user_id from t2 where diff = 1 and diff2 = 2 group by user_id;
2,统计出连续三次(及以上)为球队得分的球员名单
数据
CREATE TABLE score_3 ( player_id varchar(2), score int, score_time
datetime );
INSERT INTO score_3 (player_id, score, score_time) VALUES ('B3', 1,
'2022-09-20 19:00:14'), ('A2', 1, '2022-09-20 19:01:04'), ('A2', 3,
'2022-09-20 19:01:16'), ('A2', 3, '2022-09-20 19:02:05'), ('A2', 2,
'2022-09-20 19:02:25'), ('B3', 2, '2022-09-20 19:02:54'), ('A4', 3,
'2022-09-20 19:03:10'), ('B1', 2, '2022-09-20 19:03:34'), ('B1', 2,
'2022-09-20 19:03:58'), ('B1', 3, '2022-09-20 19:04:07'), ('A2', 1,
'2022-09-20 19:04:19'), ('B3', 2, '2022-09-20 19:04:31'), ('A1', 2,
'2022-09-20 19:04:51'), ('A1', 2, '2022-09-20 19:05:01'), ('B4', 2,
'2022-09-20 19:05:06'), ('A1', 2, '2022-09-20 19:05:26'), ('A1', 2,
'2022-09-20 19:05:48'), ('B4', 2, '2022-09-20 19:05:58'); 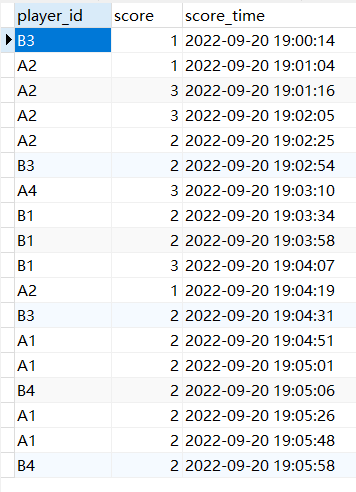
首先我们来看,每次进球得分之间,相差多少秒?
WITH sub1 AS(
SELECT *,
LAG(score_time,1) OVER() AS 退一格
FROM score_3)
SELECT *, score_time-退一格 AS 进球间时差 FROM sub1;
通过看这个时间差,我们得出结论:这个题不能像上面那个题一样,使用
(1)日期减去 时间差 无效(因为时间差是秒,且两次进球之间长则90秒,短则5秒,不是固定的差一天
(2)时间这一列向下推一行和两行,也是无效的因为 进球时间相差也不是固定的一天
答案是下面这段代码
WITH t1 AS( SELECT *,lag(player_id,1) over() AS
'last_one_player',lag(player_id,2) over () AS 'last_two_player' FROM
score_3 ) SELECT DISTINCT player_id FROM t1 WHERE player_id =
last_one_player AND last_one_player=last_two_player
这个题的难点是如何判断这一行和下一行是不是相同的用户id,如何判断连续3行、4行、5行以及更多行是连续的一个人进的球?
我先把每个球员向下推1行和向下推2行,你看看你想到了什么
SELECT
*,
lag(player_id,1) over() AS'last_one_player',
lag(player_id,2) over () AS 'last_two_player'
FROM score_3
答案的思路很简单且巧妙。
这道题的题眼就是,你要对比当前这一行和的球员和之前两行的球员是否是相同,如果是相同的,那么说明这一行是这个球员进的第3个球,也就是这个球员是我们要挑出的那个连续进球3个的球员
通过LAG函数把这一行和之前1行和之前2行放在一起,这样就可以通过简单的player_id=last_one_player AND player_id=last_two_player简单的对比出这一行和之前1行和之前2行是否是同一个球员
WITH
t1 AS(
SELECT
*,
lag(player_id,1) over() AS'last_one_player',
lag(player_id,2) over () AS 'last_two_player'
FROM score_3 )
SELECT DISTINCT player_id
FROM t1
WHERE player_id =last_one_player AND last_one_player=last_two_player 
3. 取出连续区间的开始数字和结束数字
编写 SQL 查询得到 SQL_10表中的连续区间的开始数字和结束数字。按照 start_id 排序。
我们的数据长这样
CREATE TABLE SQL_10 ( log_id int );
INSERT INTO SQL_10 (log_id) VALUES
(1), (2), (3), (7), (8), (10); 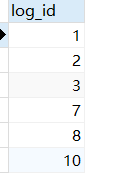
利用 log_id-ranking 如果login_id是连续的那么二者的 差 因为连续的log_id会跟随ranking同步加1 而变得一样
然后再用做差相同的数据进行GROUP BY,再取每个GROUP 的min和max
ranking和log_id - ranking的计算结果展示给你看
SELECT
*,
ROW_NUMBER() over(ORDER BY log_id) AS ranking ,
log_id-(ROW_NUMBER() over(ORDER BY log_id)) as fz
FROM sql_10 如果login_id是连续的 那么二者的 差 因为连续的log_id会跟随ranking同步加1 而变得一样
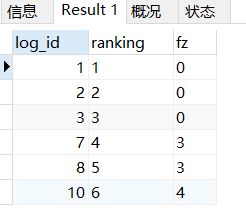
如果login_id是连续的 那么二者的 差 因为连续的log_id会跟随ranking同步加1 而变得一样
然后再用做差相同的数据进行GROUP BY,再取每个GROUP 的min和max ,就是区间的开始和结尾了
WITH t AS (
SELECT
*,
ROW_NUMBER() over(ORDER BY log_id) AS ranking ,
log_id-(ROW_NUMBER() over(ORDER BY log_id)) as fz
FROM sql_10
)
SELECT min(log_id) as s_id ,max(log_id) as e_id
FROM t
GROUP BY fz 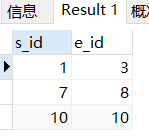
查询本机SQL版本
SELECT VERSION();