python入门篇09- 文件基础相关操作及异常捕获
全文目录,一步到位
- 1.前言简介
-
- 1.1 专栏传送门
- 2. python基础使用
-
- 2.1 python的文件相关操作
-
- 2.1.1 打开文件
- 2.1.2 读写 有个指针 每次都会继续读
- 2.1.3 `readline()` 读取一行
- 2.1.4 `readlines()`全部读取
- 2.1.5 close()文件关闭
- 2.1.6 `write()`文件的写入
- 2.1.7 `write()`文件的追加
- 2.2 try catch异常捕获
-
- 2.1.1基本捕获语法
- 2.1.2 捕获指定(多个)异常
- 2.1.3 捕获多个异常
- 2.1.4 全部异常捕获
- 2.1.5 如果没有异常 则继续走else执行
- 2.1.6 finally 必定执行逻辑
- 2.1.7 异常具有传递性
- 2.3 模块定义及使用
-
- 2.3.1 导包方法一:
- 2.3.2 导包方法二:
- 2.4 引用自定义模块
-
- 2.4.1 准备工作
- 2.4.2 引用自定义模块(一)
- 2.4.3 引用自定义模块(二)
- 2.4.4 ps: 引用模块指定名称细节注意
- 2.4.5 `__all__`变量的使用
- 2.4.6 查看`__all__`是否会对`直接import`模块有影响
- 2.4.7` __init__`.py使用方式
- 3. 基础语法`总结案例`
-
- 3.1 (案例一)查看数据的重复次数
-
- 3.1.0 案例数据准备
- 3.1.1 方法一:
- 3.1.2 方法二:
- 3.2 (案例二) 控制台输入信息写入文件
-
- 3.2.1 方法一:
- 3.2.2 方法二:
- 3.3 (案例三) python包的创建与使用
-
- 3.3.0 准备工作
- 3.3.1 使用方法一: import
- 3.3.2 使用方法二: from + import
- 3.3.3 使用方法三: from 包.模块 import 方法
- 3.3.4 测试__init__.py的影响
- 4. 文章的总结与预告
-
- 4.0 总结几个python生态的三方库
- 4.1 本文总结
- 4.2 下文预告
1.前言简介
之前文章将python基础语法
同时也与java对比其中的写法区别
1.1 专栏传送门
===> 传送门: python基础
2. python基础使用
2.1 python的文件相关操作
2.1.1 打开文件
open(file_name,mode,encoding)
- 参数一: (文件名(具体路径)
- 参数二: 打开模式
- 参数三: 编码集
file = open("pzy.txt", mode='r', encoding='utf-8')
print(type(file)) # 2.1.2 读写 有个指针 每次都会继续读
read(字节数量)读取文件 多次read 会继续上一次的位置进行读取(也就是继续读)
2.1.3 readline() 读取一行
(如果上面指针到最后了 读取的数据就会为空列表)
file.seek(0)# 将指针回归到初始位置 不受上面程序影响
lines = file.readline()
print(type(lines)) # 查看每行数据
for line in file:
print(type(line)) # 2.1.4 readlines()全部读取
使用如下
lines = file.readlines()
print(type(lines)) # 2.1.5 close()文件关闭
ps: 线程休眠方法
sleep(秒)
使用如下
lines = file.readlines()
print(type(lines)) # 2.1.6 write()文件的写入
文件 不存在:创建 存在:覆盖 (w写 r读 a追加)
方法一:
# 方法一:
t = open("pzy1.txt", mode='w', encoding='utf-8')
t.write("pzy1 !!!")
# t.flush() # 写close不写也可以
t.close()
方法二:
这种不需要close
with open("pzy1.txt", mode='w', encoding='utf-8') as file:
file.write("pzy pzy!!!")
2.1.7 write()文件的追加
with open("pzy1.txt", mode='a', encoding='utf-8') as file:
file.write("+ pzy pzy!!! \n123")
2.2 try catch异常捕获
处理python程序
运行中的异常
java是RuntimeException可以throw或者try catch finally/lombok注解/全局异常处理等等
2.1.1基本捕获语法
try与except, 代码如下
try:
t = open("D:/pzy.txt", "r", encoding="utf-8")
except:
print("出现异常, 因为文件不存在")
t = open("D:/pzy.txt", "w", encoding="utf-8")
2.1.2 捕获指定(多个)异常
捕获指定的异常 ZeroDivisionError NameError
try:
print(1/0)
print(name)
except ZeroDivisionError as e:
print(f"分母不能是0,{e}") # 变量未被定义,division by zero
except NameError as e:
print(f"变量未被定义,{e}")
2.1.3 捕获多个异常
2.1.2方法的
简化版本
try:
print(1 / 0)
except (ZeroDivisionError, NameError) as e:
print(f"分母不能是0,{e}") # 变量未被定义,division by zero
2.1.4 全部异常捕获
Exception任意异常捕获
try:
print(1 / 0)
except Exception as e:
print("任意异常捕获~~~")
2.1.5 如果没有异常 则继续走else执行
else逻辑
try:
print("hello pzy")
except Exception as e:
print("任意异常捕获~~~")
else:
print("没有异常")
2.1.6 finally 必定执行逻辑
(比如
关流操作)不管是否正确执行 都需要关闭流
try:
print(1 / 0)
except ZeroDivisionError as e:
print("任意异常捕获~~~")
else:
print("没有异常")
finally:
print("我是必然执行的")
2.1.7 异常具有传递性
test03-> test02 ->test01 一层层传递
def test01():
print("方法一开始")
num = 1 / 0
print("方法一结束")
def test02():
print("方法二开始")
test01()
print("方法二结束")
def test03():
print("方法三开始")
test02()
print("方法三结束")
test03()
2.3 模块定义及使用
简介: module模块 = python文件, 以.py结尾, 模块能定义函数 类和变量, 同时能包含可执行代码
2.3.1 导包方法一:
from 包 import 方法 as 别名
- 仅要time模块下的
sleep功能- as 可以给sleep
起别名
- 表示
全部
from time import sleep as pzy
print("程序开始~~~")
sleep(5)
pzy(5)
print("程序结束~~~")
2.3.2 导包方法二:
import 包 as 别名 : 导包
(时间)[整包]
import time as pzy
print("程序开始~~~")
# time.sleep(5)
pzy.sleep(5)
print("程序结束~~~")
2.4 引用自定义模块
2.4.1 准备工作
如上图所示: 依次创建两个文件 pzy_module.py和 pzy_module2.py
文件一:
# 数字相加
def add(a, b):
print(a + b)
# 数字相减
def sub(a, b):
print(a - b)
# 数字相乘
def multiply(a, b):
print(a - b)
# 数字相除
def divide(a, b):
print(a - b)
# python中的main方法 在if条件中
# java是必须有main方法 而python可以没有main方法执行
# __name__ 是python的内置变量名 运行就会被标记为__main__
if __name__ == '__main__':
add(1, 2) # 3
文件二:
"""
自定义模块module
"""
# 数字相加
def add(a, b):
print("我是假的add, 我在module2中")
print(a + b)
# 数字相减
def sub(a, b):
print("我是假的sub, 我在module2中")
print(a - b)
2.4.2 引用自定义模块(一)
2.4.1中的包进行引用
import pzy_module as pzy
pzy.add(1, 2)
2.4.3 引用自定义模块(二)
2.4.1中的包进行引用
from pzy_module import sub
sub(2, 1)
2.4.4 ps: 引用模块指定名称细节注意
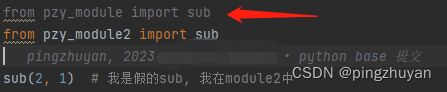
两个module
方法名相同时, 后面的直接覆盖方法:
这里只执行了module2方法 1是灰色的
from pzy_module import sub
from pzy_module2 import sub
sub(2, 1) # 我是假的sub, 我在module2中
python代码图示
2.4.5 __all__变量的使用
设置可以对外的方法:
__all__ = ["add", "sub", "multiply"]
"""
自定义模块module
1. 函数定义及引用
2. __main__ 变量使用: 可用于函数测试
3. __all__ 变量使用: 可以用于all测试
"""
# 设置可以访问的函数名
__all__ = ["add", "sub", "multiply"]
# 数字相加
def add(a, b):
print(a + b)
# 数字相减
def sub(a, b):
print(a - b)
# 数字相乘
def multiply(a, b):
print(a - b)
# 数字相除
def divide(a, b):
print(a - b)
这时候试试四个方法 看看哪个不能使用了
ps: (只对*有影响)
from pzy_module import *
add(2, 1)
sub(2, 1)
multiply(2, 1)
# divide(2, 1) # 报错了 不允许使用
2.4.6 查看__all__是否会对直接import模块有影响
结果: 没有影响,
只对from 模块 import *有影响
方法可以正常使用
import pzy_module as zzz
zzz.divide(4, 2)
2.4.7 __init__.py使用方式
只要是创建python的package 默认带这个__init__.py
是python包 同时可以控制import*
具体简介就不写了 大家看看其他文章
传送门: ===>__init__.py的简介 <===
使用请看下面案例3.3.4
3. 基础语法总结案例
3.1 (案例一)查看数据的重复次数
3.1.0 案例数据准备
txt文件 内容如下:
随便写
1今天天气挺好 aaa bbb ccc ddd eee fff
2今天天气不错 aaa bbb ccc ddd eee fff
3今天天气不错 aaa bbb ccc ddd eee fff
4今天天气不错 aaa bbb ccc ddd eee fff
5今天天气不错 aaa bbb ccc ddd eee fff
6今天天气不错 aaa bbb ccc ddd eee fff
7今天天气不错 aaa bbb ccc ddd eee fff
8今天天气不错 aaa bbb ccc ddd eee fff
9今天天气不错 aaa bbb ccc ddd eee fff
3.1.1 方法一:
count = 0
with open("pzy.txt", mode='r', encoding='utf-8') as file
for line in file:
print(f"每行的数据是: {line}")
count += line.count("今天天气")
print(count)
3.1.2 方法二:
with open("pzy.txt", mode='r', encoding='utf-8') as file:
content = file.read()
print(content.count("今天天气"))
3.2 (案例二) 控制台输入信息写入文件
3.2.1 方法一:
方法一: 开启两个流 一个读,条件符合就写 然后
统一flush推送关流
inputStr = input("输入信息: \n")
t = open("caseTest1.txt", mode='w', encoding='utf-8')
with open("caseTest.txt", mode="r", encoding='utf-8') as file:
for line in file:
if line.count(inputStr) > 0:
print(line)
t.write(f"{line}")
t.flush()
3.2.2 方法二:
方法二: 放入
列表中 然后列表遍历存入文件
inputStr = input("输入信息: \n")
list01 = []
with open("caseTest.txt", mode="r", encoding='utf-8') as file:
for line in file:
if line.count(inputStr) > 0:
print(line)
list01.append(line)
with open("caseTest1.txt", mode="w", encoding='utf-8') as file:
for str1 in list01:
file.write(str1)
print("保存结束!")
input("等待!!!")
3.3 (案例三) python包的创建与使用
3.3.0 准备工作
- 新建pzy_package 里面必须有__init__.py
2. 复制pzy_module.py和复制pzy_module2.py
3. 粘贴到pzy_package内
4. 改名(改成任意心动的名字~~~)
3.3.1 使用方法一: import
直接导包方法
import pzy_package.pzy_package_module
import pzy_package.pzy_package_module2
# 模块1
pzy_package.pzy_package_module.divide(4, 2)
# 模块2
pzy_package.pzy_package_module2.add(2, 1)
3.3.2 使用方法二: from + import
from包 import 模块
from pzy_package import pzy_package_module
from pzy_package import pzy_package_module2
pzy_package_module.divide(4, 2)
pzy_package_module2.add(2, 1)
3.3.3 使用方法三: from 包.模块 import 方法
更加细致 用哪个方法import哪个
from pzy_package.pzy_package_module import divide
from pzy_package.pzy_package_module2 import add
divide(4, 2)
add(1, 2)
3.3.4 测试__init__.py的影响
[仅对
from + import *有效] <测试时 请注释掉其他代码>
from pzy_package import *
pzy_package_module.divide(4, 2)
# pzy_package_module2.add(1, 2) # 直接报错了
4. 文章的总结与预告
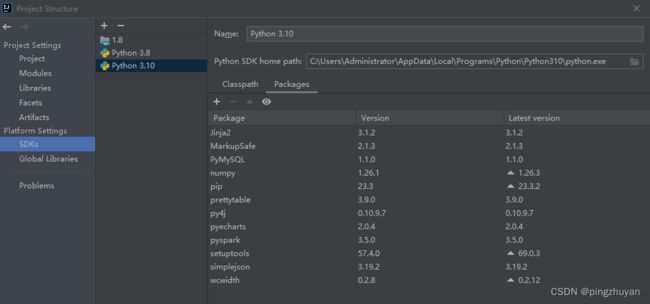
4.0 总结几个python生态的三方库
python程序的生态(三方包)
- 数据分析计算
numpypandas- 大数据计算
pysparkapache-flink包- 图形可视化 matplotlib
pyecharts- 人工智能 tensorflow Scikit-learn pytorch
- web服务
DjangoFlask(轻量) Tornado- 爬虫
Requestsscrapy beautiful-soup
快捷传送门: ===> python总结比较全的三方库简介 <==
4.1 本文总结
本文主要介绍
- 文件的基本操作, 读取与写出
- 导包的不同方式
- 包 模块 方法的区别及使用
- 三方类库总结
4.2 下文预告
传送门: ===> 文件操作的综合案例 <===
作者pingzhuyan 感谢观看