2021年10月广东强网杯,CRYPTO的RSA AND BASE?
2021年10月广东强网杯,CRYPTO的RSA AND BASE?
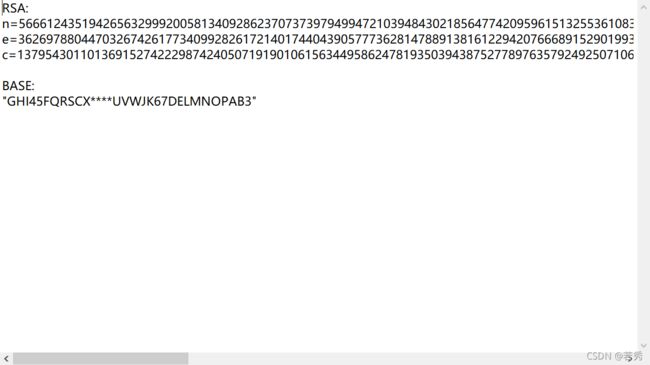
下载附件,是一个txt文件,打开,发现RSA密文和类似base32的变码表,也符合题目暗示:
.
.
RSA题目照例先用CTF-RSA-TOOL工具跑一下,发现跑得出来:

.
.
这应该是一层的flag,而且看起来像base32的四个等号,联想题目和TXT文件中后面的BASE码,可以猜出是BASE32变码的加密,而且还有4位未知:

.
.
.
(这里积累第一个经验)
首先通过和密文以及传统base32的码表对比可以发现缺了2 T Y Z四个字母,这四个字母共有24种排列组合,可以用下面代码求出排列组合:
list1=['2','T','Z','Y']
len1=len(list1)
list2=[]
w=""
for i in list1:
for j in list1:
if j!=i:
for k in list1:
if k!=j and k!=i:
for l in list1:
if l !=k and l !=j and l !=i:
w=i+j+k+l
list2.append(w)
print(list2)
print(len(list2))
.
结果:

.
.
(这里积累第二个经验)
然后就是获取BASE32的编码实现来替换码表了,由于我在网上找不到base32的python编码实现,而且我也不会GO语言,没法直接替换封装函数码表,所以我用了我广州羊城杯的BabySmc技巧,通过下标对应来转为传统的base32密文。
下标对应法,这就要了解base32加密解密的本质了。
base32加密是5*8变8*5,获取的5个8位数对应着0~32内的范围,而base32的基本字符表ABCDEFGHIJKLMNOPQRSTUVWXYZ234567不过是0~32范围内对应的映射下标而已。
解密的时候也是用每个加密字符在0 ~32范围的数来拆分解密,关键就是这个解密时的5位数是怎么找的呢?是通过base32.index('加密字符')来找对应的0 ~ 32的下标。
所以加密字符表单的作用只是用来根据下标来映射5位数的0~32的范围而已,本质是0 ~64的下标。
那么我们就可以通过一一对应的方法来把题目中新的加密表单的下标来对应原生的base32加密下标了,因为base32在线解密工具只能通过base32.index('加密字符')来找0 ~ 32的下标。
脚本如下,注意抽出'='来,并且在最后要把'='加上去,因为base32解密必须是8的倍数。
import base64
#key1="GHI45FQRSCX****UVWJK67DELMNOPAB3" #少了2TYZ
key1="GHI45FQRSCX" #变形表单1
key2="UVWJK67DELMNOPAB3" #变形表单2
base32="ABCDEFGHIJKLMNOPQRSTUVWXYZ234567" #传统表单
key3="TCMDIEOH2MJFBLKHT2J7BLYZ2WUE5NYR2HNG" #变形密文
list1=['2TZY', '2TYZ', '2ZTY', '2ZYT', '2YTZ', '2YZT', 'T2ZY', 'T2YZ', 'TZ2Y', 'TZY2', 'TY2Z', 'TYZ2', 'Z2TY', 'Z2YT', 'ZT2Y', 'ZTY2', 'ZY2T', 'ZYT2', 'Y2TZ', 'Y2ZT', 'YT2Z', 'YTZ2', 'YZ2T', 'YZT2']
secret=""
for i in list1:
key4=key1+i+key2 #最终变形表单
#print(key4)
for m in key3:
g=key4.index(m)
secret+=base32[g]
secret+='===='
print(secret)
print(base64.b32decode(secret))
secret=""
结果:

.
.
.
总结:
1:
(这里积累第一个经验)
首先通过和密文以及传统base32的码表对比可以发现缺了2 T Y Z四个字母,这四个字母共有24种排列组合,可以用下面代码求出排列组合
list1=['2','T','Z','Y']
len1=len(list1)
list2=[]
w=""
for i in list1:
for j in list1:
if j!=i:
for k in list1:
if k!=j and k!=i:
for l in list1:
if l !=k and l !=j and l !=i:
w=i+j+k+l
list2.append(w)
print(list2)
print(len(list2))
2:
(这里积累第二个经验)
然后就是获取BASE32的编码实现来替换码表了,由于我在网上找不到base32的python编码实现,而且我也不会GO语言,没法直接替换封装函数码表,所以我用了我广州羊城杯的BabySmc技巧,通过下标对应来转为传统的base32密文。
.
下标对应法,这就要了解base32加密解密的本质了。
base32加密是5*8变8*5,获取的5个8位数对应着0~32内的范围,而base32的基本字符表ABCDEFGHIJKLMNOPQRSTUVWXYZ234567不过是0~32范围内对应的映射下标而已。
.
解密的时候也是用每个加密字符在0 ~32范围的数来拆分解密,关键就是这个解密时的5位数是怎么找的呢?是通过base32.index('加密字符')来找对应的0 ~ 32的下标。
.
所以加密字符表单的作用只是用来根据下标来映射5位数的0~32的范围而已,本质是0 ~64的下标。
.
那么我们就可以通过一一对应的方法来把题目中新的加密表单的下标来对应原生的base32加密下标了,因为base32在线解密工具只能通过base32.index('加密字符')来找0 ~ 32的下标。
.
脚本如下,注意抽出'='来,并且在最后要把'='加上去,因为base32解密必须是8的倍数。
解毕!敬礼!