kafka核心原理及数据积压问题
1 kafka的分片和副本机制
何为分片? 分片有什么用呢?
分片: 分片是对topic的一种划分操作, 通过分片 kafka可以实现对消息数据分布式的存储
作用:
1- 提供读写效率
2- 解决单台节点存储容量有限的问题
注意: 分片数量与集群的节点数量是没有关系的 分片数量可以构建多个
何为副本? 副本有什么用呢?
副本: 副本是针对的每一个topic下每一个分片, 可以将分片的数据通过副本方式存储多份
作用: 提高数据可靠性, 避免数据的丢失
注意: 副本的数量最多和节点的数量是相等的, 一般副本为1~3个 副本越多会导致数据大量的冗余存储, 同时影响写入的效率
2 kafka的消息存储和查询机制
2.1 存储机制

1- 在每个分片中, 数据都是以分文件的形式来存储的
2- 每个文件的片段都是由二个核心文件构成的, 一个是log文件 一个是index文件
log文件: 存储的真实消息数据
index文件: 是log文件的索引文件, 用于加快查询log消息
文件名: 表示当前这个文件片段是从那个消息偏移量开始存储数据 一个消息偏移量表示一条消息
3- 消息默认是达到168小时后 就会被kafka自动删除, kafka在删除的时候, 校验log文件的最后修改时间,因为kafka仅仅是临时存储
相关的配置:
log.retention.hours=168 (168小时 7天)
log.segment.bytes=1073741824 (1GB)
index文件中存储了什么?
在index文件中, 主要是存储每个消息的偏移量在log文件中对应的物理偏移量
例如共计有五条消息数据: hello kafka wo hen hao 1 2 3
hello kafkawo hen hao123
index文件: 消息偏移量 物理偏移量
0 11
1 21
2 22
3 23
4 24
2.2 查询机制

查询流程:
1- 确定消息在那个片段中: 第二个
2- 查询index文件, 这个偏移量数据在log文件的那个偏移量上
3- 查询log文件 按照顺序查找方案, 遍历对应位置, 将对应范围内数据获取到即可
磁盘查询策略: 顺序查找 和 随机查找 那个效率快呢? 一定是顺序查询
3. kafka如何保证消息不丢失
3.1 生产者如何保证数据不丢失
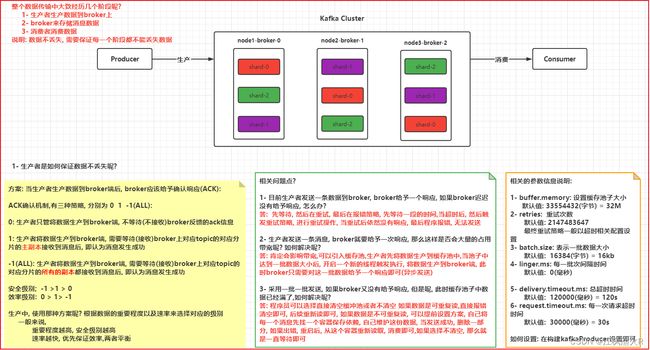
ack机制:
方案: 当生产者生产数据到broker端后, broker应该给予确认响应(ACK):ACK确认机制,有三种策略, 分别为 0 1 -1(ALL):
0: 生产者只管将数据生产到broker端, 不等待(不接收)broker反馈的ack信息
1: 生产者将数据生产到broker端, 需要等待(接收)broker上对应topic的对应分片的主副本接收到消息后, 即认为消息发生成功
-1(ALL): 生产者将数据生产到broker端, 需要等待(接收)broker上对应topic的对应分片的所有的副本都接收到消息后, 即认为消息发生成功
安全级别; -1 >1 > 0
效率级别: 0 > 1> -1
生产中, 使用那种方案呢? 根据数据的重要程度以及速率来选择对应的级别
一般来说,
重要程度越高, 安全级别越高
速率越快, 优先保证效率,两者平衡
相关的问题:
相关问题点?
1- 目前生产者发送一条数据到broker, broker给予一个响应, 如果broker迟迟没有给予响应, 怎么办?
答: 先等待, 然后在重试, 最后在报错策略, 先等待一段的时间,当超时后, 然后触发重试策略, 进行重试操作, 当重试后依然没有响应, 最后程序报错, 无法发送
2- 生产者发送一条消息, broker就要给予一次响应, 那么这样是否会大量的占用带宽呢? 如何解决呢?
答: 肯定会影响带宽,可以引入缓存池,生产者先将数据生产到缓存池中,当池子中达到一批数据大小后, 开启一个新的线程触发执行, 将数据生产到broker端, 此时broker只需要对这一批数据给予一个响应即可(异步发送)
3- 采用一批一批发送, 如果broker又没有给予响应, 但是呢, 此时缓存池子中数据已经满了,如何解决呢?
答: 程序员可以选择直接清空缓冲池或者不清空 如果数据是可重复读,直接报错清空即可, 后续重新读即可, 如果数据是不可重复读, 可以提前设置方案, 自己将每一个消息先找一个容器保存依赖, 自己维护这份数据, 当发送成功, 删除一部分, 如果出错, 重启后, 从这个容器重新读取, 消费即可,如果选择不清空, 那么就是一直等待即可
相关参数:
相关的参数信息说明:
1- buffer.memory: 设置缓存池子大小
默认值: 33554432(字节) = 32M
2- retries: 重试次数
默认值: 2147483647
最终重试策略一般以超时相关配置设置
3- batch.size: 表示一批数据大小
默认值: 16384(字节) = 16kb
4- linger.ms: 每一批次间隔时间
默认值: 0(毫秒)
5- delivery.timeout.ms: 总超时时间
默认值: 120000(毫秒) = 120s
6- request.timeout.ms: 每一次请求超时时间
默认值: 30000(毫秒) = 30s
如何设置: 在构建kafkaProducer设置即可
通过代码如何实现同步的发送模式和异步的发送方案:
同步方式:
from kafka import KafkaProducer
from kafka.errors import KafkaError
if __name__ == '__main__':
print("演示python的kafka API: 生产者的同步发送模式")
# 1- 创建kafkaProducer对象
producer = KafkaProducer(
bootstrap_servers=['node1:9092','node2:9092','node3:9092'],
acks=-1
)
# 2- 执行生产操作 同步方案
future = producer.send('test01','我爱我的祖国'.encode('UTF-8')) # 默认是异步的
try:
record_metadata = future.get() # 同步发送模式, 当发送失败(已经重试完成)后
# 如果发送成功的
print(record_metadata.topic)
print(record_metadata.partition)
print(record_metadata.offset)
except KafkaError:
print(KafkaError)
finally:
producer.close()
异步方式:
import time
from kafka import KafkaProducer
from kafka.errors import KafkaError
if __name__ == '__main__':
print("演示python的kafka API: 生产者的异步发送模式")
# 1- 创建kafkaProducer对象
producer = KafkaProducer(
bootstrap_servers=['node1:9092', 'node2:9092', 'node3:9092'],
acks=-1,
linger_ms=5000
)
# 2 执行发送数据: 异步方式
# 异步无返回值方案
#producer.send('test01', '昨天是建军节... 东部战区启动了...'.encode('UTF-8')) # 默认就是异步方式
#producer.flush()
# 异步有返回值方案
future = producer.send('test01', '昨天是建军节... 东部战区启动了...'.encode('UTF-8')) # 默认就是异步方式
# 表示当底层每一批数据发送成功后, 都会调用此函数: add_callback
def on_send_success(record_metadata):
print(record_metadata.topic)
print(record_metadata.partition)
print(record_metadata.offset)
# 表示当底层发送一批数据失败了, 就会调度此函数: add_errback
def on_send_error(excp):
print(excp)
future.add_callback(on_send_success).add_errback(on_send_error)
# 为了演示效果, 不使用flush 而是采用休眠的方式
#time.sleep(1000000)
3.2 broker端如何保证数据不丢失
broker可以将每个分片副本设置为多个, 提高数据的可靠性同时还需要生产端将ack设置为-1
3.3 消费端如何保证数据不丢失

流程:
1- 消费者首先会连接kafka集群, 从kafka集群准备获取消息数据
2- kafka集群接收到信息后, 首先会根据group_id 查询上一次消费到了那个消息的偏移量
3- 如果没有找到消息偏移量, 默认从当前位置开始消费,之前消息就默认不处理不关心
4- 如果找到了上一次的消费位置,那么就从记录的消费偏移量位置继续消费数据即可
5- 消费者消费完数据后, 会把消费后偏移量信息提交给broker
消费者偏移量信息保存:
请问消费者消费的偏移量信息是记录在哪里的呢?
在kafka0.8x版本之前, 这个信息是记录在zookeeper集群上在0.8x以后的版本中, 将信息从zookeeper中迁移到broker上, 通过一个topic来记录即可: __consumer_offsets
此topic有50个分片1个副本
通过这种机制 可以保证数据不丢失, 但是可能存在重复消费的问题
如何提交偏移量信息呢? 手动 | 自动
- 手动方案:
- 除非对偏移量信息需要进行严格把控, 建议自己维护偏移量信息, 进行处理即可
from kafka import KafkaConsumer
if __name__ == '__main__':
# 1- 创建 消费者的实例对象
consumer = KafkaConsumer(
'test01',
bootstrap_servers=['node1:9092','node2:9092','node3:9092'],
group_id='g_01',
enable_auto_commit=False
)
# 2- 获取消息数据
for msg in consumer:
topic = msg.topic
partition = msg.partition
offset = msg.offset
key = msg.key
value = msg.value.decode('UTF-8')
print(f'topic为:{topic}, 分片为:{partition},偏移量为:{offset},消息key为:{key}, 消息value:{value}')
# 手动提交偏移量信息: 当选择手动的时候, 千万丢失以下操作, 否则会导致大量的重复处理
#consumer.commit() # 同步提交
consumer.commit_async() # 异步提交 (推荐)
- 演示自动方案:
from kafka import KafkaConsumer
if __name__ == '__main__':
# 1- 创建 消费者的实例对象
consumer = KafkaConsumer(
'test01',
bootstrap_servers=['node1:9092','node2:9092','node3:9092'],
group_id='g_01',
enable_auto_commit=True, # 是否自动提交偏移量信息
auto_commit_interval_ms=1 # 每搁多次时间, 提交一次偏移量信息
)
# 2- 获取消息数据
for msg in consumer:
topic = msg.topic
partition = msg.partition
offset = msg.offset
key = msg.key
value = msg.value.decode('UTF-8')
print(f'topic为:{topic}, 分片为:{partition},偏移量为:{offset},消息key为:{key}, 消息value:{value}')
介绍一个其他的参数:
auto_offset_reset: 此参数表示当一个新的消费者, 默认从那个偏移量开始读取数据
earliest: 最早的 从第一个偏移量开始读取消息数据
latest: 最新的 只读取从当前时刻最新的数据
4. kafka中生产者的数据分发策略
何为生产者的数据分发机制呢?
当生产者进行生产数据到broker上后, 这条数据只能落在对应topic的某一个分片的副本上, 那么最终落入到哪一个分区呢?这就是分发机制
分发策略有哪些?
1- 随机策略(python API 存在的)
2- 轮询策略(粘性分区策略) (JAVA API存在的)
3- 指定分发策略
4- hash取模策略
5- 自定义分区策略
- 1- 随机策略:
def send(self, topic, value=None, key=None, headers=None, partition=None, timestamp_ms=None):
当在发送数据的时候, 如果只传递了topic 和 value, 那么此时就是采用随机策略
在kafka中, 专门提供了一个默认的分发类: DefaultPartitioner
此类中有一个方法, 绝对了分发到那个分区上:
def __call__(cls, key, all_partitions, available):
"""
Get the partition corresponding to key
:param key: partitioning key
:param all_partitions: list of all partitions sorted by partition ID
:param available: list of available partitions in no particular order
:return: one of the values from all_partitions or available
"""
if key is None:
# 当 key为null的时候, 先判断可用分区中是否有节点, 如果有随机返回一个, 否则从所有的分区中随机返回一个
if available:
return random.choice(available)
return random.choice(all_partitions)
idx = murmur2(key)
idx &= 0x7fffffff
idx %= len(all_partitions)
return all_partitions[idx]
- 2- 指定分发策略
def send(self, topic, value=None, key=None, headers=None, partition=None, timestamp_ms=None):
当在发送数据的时候, 如果指定了partition参数, 表示的采用的指定分区的方案, 分区的标号是从0开始
主要此时跟DefaultPartitioner没有任何的关系
- 3- hash取模策略
def send(self, topic, value=None, key=None, headers=None, partition=None, timestamp_ms=None):
当在发送数据的时候, 如果传递了topic 和 value以及key的时候, 那么此时就是采用hash取模策略
在kafka中, 专门提供了一个默认的分发类: DefaultPartitioner
此类中有一个方法, 绝对了分发到那个分区上:
def __call__(cls, key, all_partitions, available):
"""
Get the partition corresponding to key
:param key: partitioning key
:param all_partitions: list of all partitions sorted by partition ID
:param available: list of available partitions in no particular order
:return: one of the values from all_partitions or available
"""
if key is None:
# 当 key为null的时候, 先判断可用分区中是否有节点, 如果有随机返回一个, 否则从所有的分区中随机返回一个
if available:
return random.choice(available)
return random.choice(all_partitions)
# 当key不为null的时候, 表示发送数据的时候, 存在key, 此时采用hash取模策略murmur2()
idx = murmur2(key)
idx &= 0x7fffffff
idx %= len(all_partitions)
return all_partitions[idx]
- 4- 自定义分区策略: 参考DefaultPartitioner 他怎么写你就怎么写
第一步: 创建一个自定义分区类 Mypartition
from __future__ import absolute_import
from kafka.vendor import six
class Mypartition(object):
# 第二步: 创建一个方法: __call__ 传入几个参数: 参数1为key值 参数2 表示所有分区 参数3 可用的分区
@classmethod
def __call__(cls, key, all_partitions, available):
# 第三步: 自定义实现分区策略
# 第四步: 通过return返回相对应分区
return all_partitions[i] 或者 return available[i]
第五步: 将整个分区配置到生产者中:
producer = KafkaProducer(
bootstrap_servers=['node1:9092','node2:9092','node3:9092'],
acks=-1,
partitioner=MyPartition()
)
额外的点:
轮询分发和粘性分区策略: JAVA
轮询策略: 在kafka的老的版本中存在的一种策略方案(2.4版本以下), 当生成数据时候, 只有value没有key的时候, 采用轮询
优点: 可以保证每个分区拿到的数据量基本都是一样的, 因为一个一个轮着进行发送
弊端: 如果采用异步的方式, 意味着数据采用一批一批的方案, 当一批数据到达broker, 由于采用轮询策略, 会将这一批数据拆分为多个批次(与分片数量等同), 分别写入到不同的分片中, 影响效率(重分批以及产生多个ack响应)
粘性分区策略: 在kafka的新的版本中, 存在的一种策略方案(2.4版本及以上), 当生成数据时候, 只有value没有key的时候,采用粘性分区
优点: 在发送数据的时候, 首先会先随机的选择一个分区, 然后尽可能黏上这个分区, 将后续的数据全部发送给这一个分区上 此操作在异步发送中, 效率比较高, 可以保证一批数据都在一个分区上(无需要在分批, 一次响应即可)
弊端: 如果生成批次非常块, 有可能导致大量的数据都发给了同一个分区上
5. kafka的消费者负载均衡机制
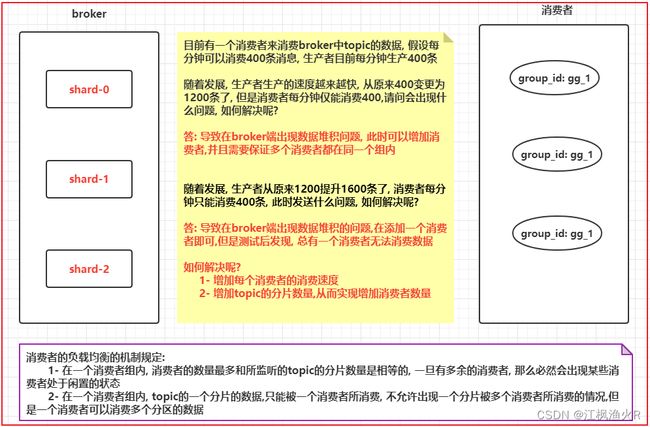
消费者的负载均衡的机制规定:
1- 在一个消费者组内, 消费者的数量最多和所监听的topic的分片数量是相等的, 一旦有多余的消费者, 那么必然会出现某些消费者处于闲置的状态
2- 在一个消费者组内, topic的一个分片的数据,只能被一个消费者所消费, 不允许出现一个分片被多个消费者所消费的情况,但是一个消费者可以消费多个分片的数据
如何实现点对点的消息模型 和 发布订阅的消息模型
点对点: 把监听这个topic的消费者全部都放置在同一个消费者组内容, 这样一个消息必然只能被组内一个消费者所接收到
发布订阅: 将各个消费者放置到不同的组内即可
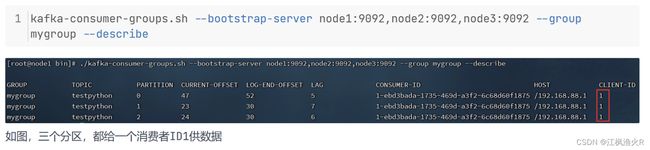
6- 数据积压问题
通过命令查询是否存在积压的:
./kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --group gg_1 --describe
