【python】—— 字符串详解
目录
(一)字符串的常用操作
(二)格式化字符串
2.1 占位符
2.2 f-string
2.3 格式化函数format()
(三)字符串的编码和解码
3.1 字符串编码
3.2 字符串解码
3.3 处理异常
(四)数据处理操作
4.1 字符串的拼接
4.2 字符串的去重
(五)小结
(一)字符串的常用操作
在Python中,字符串是一种不可变的序列类型,用于表示文本数据。字符串是由字符组成的,可以包含字母、数字、特殊字符等。
- len(): 返回字符串的长度
str = "Hello, World!"
length = len(str)
print(length) # 输出:13- lower() 和 upper(): 分别将字符串转换为小写和大写
str = "Hello, World"
print(str.lower()) # 输出:hello, world
print(str.upper()) # 输出:HELLO, WORLD-
capitalize() :将字符串的第一个字符转换为大写,并返回新字符串
str = "hello, world"
print((str.capitalize())) #输出: Hello, world- strip()、lstrip() 和 rstrip(): 去除字符串两端、左端或右端的空格或指定字符
str = " Hello, World "
print(str.strip()) # 输出:"Hello, World"
print(str.lstrip()) # 输出:"Hello, World "
print(str.rstrip()) # 输出:" Hello, World"- find() 和 index(): 查找子字符串在字符串中的位置
str = " Hello, World "
print(str.find("World")) # 输出:10
print(str.index("World")) # 输出:10- replace(): 替换字符串中的子字符串
str = "Hello, World"
print(str.replace("World","Hello")) # 输出:Hello, Hello- center():将字符串居中,并使用指定字符(默认为空格)填充两侧的空白部分,使得字符串长度为指定宽度,并返回新字符串
str = "Hello,World"
print(str.center(20,'-')) # 输出:----Hello,World------ upper() 和 lower():将字符串中所有字母都转换成大写或者小写,并返回新字符串
str = "Hello,World"
print(str.upper()) # 输出:HELLO,WORLD
print(str.lower()) # 输出:hello,world-
isupper() 和 islower():判断字符串中所有字母是否都是大写或者小写,并返回相应的布尔值。
str = "Hello,World"
print(str.isupper()) # 输出:False
print(str.islower()) # 输出:False(二)格式化字符串
在Python中,格式化字符串是指将变量的值插入到字符串中,以方便输出。Python提供了三种主要的格式化字符串的方式:

2.1 占位符
位置参数格式化是通过占位符
%实现的。可以在字符串中使用占位符%表示待插入的变量,然后使用元组作为参数,将元组中的变量传递给占位符.
- 示例如下:
name = "zhangsan"
age = 20
formatted_string = "My name is %s and I am %d years old." % (name, age)
print(formatted_string)输出展示:

其次在占位符%后面,可以用以下字符指定数据类型和格式:
%d:整数类型%f:浮点数类型%s:字符串类型%x:十六进制整数类型
2.2 f-string
f-string 是Python 3.6及以上版本新增的一种字符串格式化方式。在f-string 中,可以在字符串前加上字母
f,然后在字符串中使用花括号{}表示待插入的变量。
- 示例如下:
name = "zhangsan"
age = 20
print(f"My name is {name} and I'm {age} years old.")输出展示:

2.3 格式化函数format()
可以使用字符串的
format()方法将变量值插入到字符串中。在字符串中,可以使用一对花括号{}表示待插入的变量,然后使用format()方法将变量传递给花括号。
- 示例如下:
name = "zhangsan"
age = 20
print("My name is {} and I'm {} years old.".format(name, age))输出展示:

(三)字符串的编码和解码
首先大家需要理解为什么需要进行编码和解码操作:

【解释说明】
- 在Python中,字符串的编码和解码涉及到将文本数据转换为字节数据(编码)以及将字节数据转换回文本数据(解码);
- 符串的编码和解码是指将字符串与字节之间相互转换的过程。编码是将字符串转换为字节序列,而解码是将字节序列转换为字符串。
3.1 字符串编码
将字符串转换为字节序列称为编码。在Python中,常用的字符串编码方式包括ASCII、UTF-8、UTF-16等
- 在Python中,字符串默认使用UTF-8编码 (在解码时,可能会遇到无法解码的字节序列,可以使用
errors参数处理)

- 当然也可以使用gbk进行编码操作:

3.2 字符串解码
将字节序列转换为字符串称为解码。在Python中,可以使用
decode()方法将字节序列解码为字符串。
- 解码UTF-8编码的字节序列:
str = "你好"
encoded_str = str.encode(errors='replace') #默认是utf-8,因为utf-8中文占3个字节
print(encoded_str)
#1.使用bytes->str操作
print(bytes.decode(encoded_str,'utf-8'))
#2.解码utf-8编码的字节序列
str2 = b'\xe4\xbd\xa0\xe5\xa5\xbd'
print(str2.decode('utf-8'))输出展示:

- 解码gbk编码的字节序列:
str = "你好"
gbk_str = str.encode('gbk',errors='replace') #因为gbk中文占2个字节
print(gbk_str)
#1.使用bytes->str操作
print(bytes.decode(gbk_str,'gbk'))
#2.解码gbk编码的字节序列
str2 = b'\xc4\xe3\xba\xc3'
print(str2.decode('gbk'))3.3 处理异常
- 1.当处理异常时 errors = replace 时,会替换成 ?

- 2.当处理异常时 errors = ignore 时,编译器会忽略报错的情况
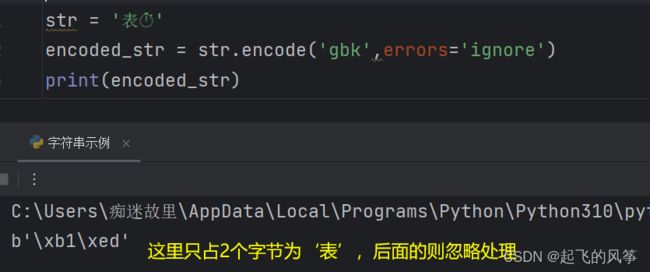
- 3.当处理异常时 errors = strict时,编译器会报错

【小结】
- 在进行字符串编码和解码时,需要确保使用相同的编码方式。
- 如果尝试使用错误的编码方式对字节序列进行解码,会引发
UnicodeDecodeError错误。 - 如果尝试使用错误的编码方式对字符串进行编码,会引发
UnicodeEncodeError错误。
(四)数据处理操作
4.1 字符串的拼接
- 使用直接拼接的方法:
print('hello''world')- 可以使用
+运算符将两个字符串连接起来:
str1 = "Hello"
str2 = "World"
print(str1 + str2)- 也可以使用字符串的
join()方法:
str1 = "Hello"
str2 = "World"
print("".join([str1,str2]))- 使用格式化字符串进行拼接操作:
str1 = "Hello"
str2 = "World"
# 使用格式化字符串拼接的三种方法
print('%s%s' % (str1,str2))
print(f'{str1}{str2}')
print('{0}{1}'.format(str1,str2))4.2 字符串的去重
- 可用通过字符串拼接以及not in操作达到去重效果:
str = "helloworldhelloabcgdfoefpa"
#1.字符串拼接以及not in
new_str_1 = ""
for item in str:
if item not in new_str_1:
new_str_1 += item #拼接操作
print(new_str_1)- 可用通过索引 + not in操作 :
str = "helloworldhelloabcgdfoefpa"
#2.索引 + not in操作
new_str_2 = ""
for i in range(len(str)):
if str[i] not in new_str_2:
new_str_2 += str[i]
print(new_str_2)- 还可以通过集合去重+列表排序:
str = "helloworldhelloabcgdfoefpa"
#3.通过集合去重+列表排序
new_str_3 = set(str)
lst = list(new_str_3)
lst.sort(key=str.index)
print(''.join(lst))输出结果如下:

(五)小结
Python字符串是不可变序列,在Python中通过一对单引号或双引号来表示。字符串可以进行切片和索引等操作,常见的字符串方法很多,大家会用即可!!