机器学习第二十六周周报 ARIMA & Clustering model
文章目录
- week26 ARIMA & Clustering model
- 摘要
- Abstract
- 一、龙格库塔方法
- 二、文献阅读
-
- 1. 题目
- 2. abstract
- 3. 网络架构
-
- 3.1 ARIMA模型
- 3.2 K-means聚类
- 3.3 评估标准
- 4. 文献解读
-
- 4.1 Introduction
- 4.2 创新点
- 4.3 实验过程
-
- 4.3.1 数据来源
- 4.3.2 使用ARIMA模型预测
- 4.3.3 K-means聚类分析和相关性分析
- 4.3.4 联合ARIMA模型与聚类算法
- 4.4 结论
- 三、Hadoop基础
-
- 1.基础知识
-
- 1.1 Hadoop简介
- 1.2 各核心组件功能
- 1.3 其他相关框架
- 2. 完全分布式运行模式
-
- 2.1 虚拟机准备
- 2.2 编写集群分发脚本xsync
- 2.3 集群配置
- 四、BiLSTMCNN
-
- 1. 任务要求
- 2.实验结果
- 3.实验代码
- 小结
- 参考文献
week26 ARIMA & Clustering model
摘要
本文主要讨论ARIMA模型和Clustering模型。本文简要介绍了龙格库塔方法。其次本文展示了题为Application of Time Serial Model in Water Quality Predicting的论文主要内容。该文提出一种结合自回归积分移动平均(ARIMA)和聚类模型的水质预测方法。以某流域水质监测数据为样本,选取水质总磷(TP)指数作为预测对象。实验表明,与ARIMA水质预测方法相比,该方法具有更高的精度。然后,本文简要阐述了Hadoop的大致框架与其完全分布式运行模式的大致部署。最后,本文使用pytorch实现BiLSTMCNN并使用序列数据训练该模型。
注:由于项目需要大数据相关技术,故学习该内容,深度学习实验在第四部分
Abstract
This article mainly discusses the ARIMA model and the clustering model. This article provides a brief introduction to the Runge-Kutta method(1, 2, 4). Secondly, this paper presents the main content of the paper entitled Application of Time Serial Model in Water Quality Predicting. This paper proposes a water quality prediction method combining Autoregressive Integral Moving Average (ARIMA) and clustering model. This paper takes the water quality monitoring data of a river basin as a sample, selects the total phosphorus index (TP) index of water quality as the prediction object. Experiments show that the proposed method has higher accuracy than the ARIMA water quality prediction method. Then, this article briefly describes the general framework of Hadoop and its general deployment of a fully distributed operating model. Finally, this article uses pytorch to implement BiLSTMCNN and train the model with sequence data.
一、龙格库塔方法
Runge-Kutta方法就是一种高精度的经典的解常微分方程的单步方法。


二、文献阅读
1. 题目
题目:Application of Time Serial Model in Water Quality Predicting
作者:Jiang Wu, Jianjun Zhang, Wenwu Tan, Hao Lan, Sirao Zhang, KeXiao, Li Wang,
Haijun Lin, Guang Sun and Peng Guo
链接:https://www.techscience.com/cmc/v74n1/49798/html
期刊:Computers, Materials & Continua
tip:本文使用的ARIMA模型已经在以往文章中略有介绍
2. abstract
该文提出一种结合自回归积分移动平均(ARIMA)和聚类模型的水质预测方法。以某流域水质监测数据为样本,选取水质总磷(TP)指数作为预测对象。实验表明,与ARIMA水质预测方法相比,该方法具有更高的精度,其平均绝对误差(MAE)、均方误差(MSE)和平均绝对百分比误差(MAPE)分别降低了44.6%, 56.8% 和 45.8%。
This paper proposes a method of predicting water quality which combines Auto Regressive Integrated Moving Average (ARIMA)and clusteringmodel was proposed in this paper. By taking
the water quality monitoring data of a certain river basin as a sample, the water quality Total Phosphorus (TP) index was selected as the prediction object. Compared with the ARIMA water quality prediction method, experiments showed that the proposed method has higher accuracy, and its Mean Absolute Error (MAE), Mean Square Error (MSE), and Mean Absolute Percentage Error (MAPE) were respectively reduced by 44.6%, 56.8%, and 45.8%.
3. 网络架构
单变量VS多变量时间序列数据
时间序列是按时间顺序排列的数据集合。这些数据可以在任何时间间隔(例如,每秒、每分钟、每小时、每天、每月、每年等)观察和收集。举个例子,如果每天在同一时间测量体重并记录下来,那么你就有了一个关于体重的时间序列数据。时间序列数据的一个关键特性是其有序性,即数据点之间的顺序非常重要。
时间序列数据可以分为单变量数据和多变量数据,这取决在每个时间点观察的变量的数量。时间序列预测的本质就是利用历史数据预测未来数据走向。
单变量时间序列只涉及一个变量随时间的变化。这个变量在每个时间点都有一个观察值。单变量时序数据是指每个时间点对应一个标签值,时间是影响该标签唯一的自变量。在单变量时间序列预测中,只依赖一个变量的历史数据来预测该变量的未来值。
多变量时间序列涉及到两个或更多的变量随时间的变化。在每个时间点,这些变量都有观察值。在多变量时间序列中,时间是影响标签变化的因素之一,除了时间之外,往往还有别的决定性因素、或同样重要的因素和时间共同作用、影响着标签。在多变量时间序列预测中,不仅仅使用一个变量的历史数据,还会使用其他变量的历史数据来预测某个变量的未来值,并且这些变量之间的关系并不是一一对应的,因此,在处理多变量时间序列数据时,需要分析不同变量之间的相互影响,以及这些影响如何随时间变化。
3.1 ARIMA模型
ARIMA模型用于预测和分析非平稳序列。它具有三个重要参数:p、d 和 q。 p是自回归项的阶数,表示当前序列值与前p个序列值相关,d表示非平稳序列的最小差分阶数,一般为一阶。如果阶数太高,会导致时间序列失去自相关性,因此不能使用自回归项。 q 是移动平均项的阶数,表示当前序列值与 q 个先前历史值的预测误差相关。其模型结构为:
f t = ϕ 0 + ϕ 1 f t − 1 + ϕ 2 f t − 2 + ⋯ + ϕ p f t − p + ϵ t + θ 1 ϵ t − 1 + θ 2 ϵ t − 2 + ⋯ + θ q ϵ t − q (1) f_t = \phi_0+\phi_1f_{t-1}+\phi_2f_{t-2}+\dots+\phi_pf_{t-p}+\epsilon_t+\theta_1\epsilon_{t-1}+\theta_2\epsilon_{t-2}+\dots+\theta_q\epsilon_{t-q} \tag{1} ft=ϕ0+ϕ1ft−1+ϕ2ft−2+⋯+ϕpft−p+ϵt+θ1ϵt−1+θ2ϵt−2+⋯+θqϵt−q(1)
式中,前半部分为自回归部分,非负整数p为自回归阶数, ϕ 0 , … , ϕ p \phi_0,\dots,\phi_p ϕ0,…,ϕp为自回归系数。后半部分是移动平均线部分,其中非负整数 q 为移动平均阶数, θ 1 , … , θ q \theta_1,\dots,\theta_q θ1,…,θq为移动平均系数。 ϵ t \epsilon_t ϵt表示均值为零的白噪声随机误差序列。用ARIMA模型拟合时间序列数据有几个基本步骤,主要包括构建数据的时间序列图、执行适当的数据转换、模型排序、参数估计、模型诊断和模型选择。
3.2 K-means聚类
K-means 算法是一种简单的迭代方法,用于将给定数据集划分为用户指定数量的簇 k,通过选取样本中的 k 个点作为初始 k 个簇代表或“质心”来初始化簇 k。这些初始质心是从数据集中随机选择的,并且每个簇中的数据的特征在某种意义上是相似的。
K-means将整个样本集分为k组,同一组内的样本之间的距离最小。计算距离的方法有很多种,最常见的是欧拉距离。假设 x = ( x 1 , x 2 , x 3 , … , x n ) x = (x_1 , x_2, x_3,\dots , x_n) x=(x1,x2,x3,…,xn) 和 y = ( y 1 , y 2 , y 3 , … , y n ) y = (y_1, y_2, y_3,\dots , y_n) y=(y1,y2,y3,…,yn) 是 n 维实向量,则欧拉公式为:
d = ∑ i = 1 n ∣ x i − y i ∣ 2 (2) d = \sqrt{\sum_{i=1}^n|x_i-y_i|^2} \tag{2} d=i=1∑n∣xi−yi∣2(2)

3.3 评估标准
常用来检验模型预测精度的指标有MAE、MSE和MAPE
MAE是绝对误差的平均值,更能反映预测误差值的实际情况。其计算公式为:
M A E = 1 n ∑ j = 1 n ∣ z − z j ∣ (3) MAE=\frac1n\sum_{j=1}^n|z-z_j|\tag{3} MAE=n1j=1∑n∣z−zj∣(3)
MSE即均方误差,是指参数的预测值与实际值之差平方的期望值。 MSE评估数据的波动性。
M S E = 1 n ∑ j = 1 n ( z − z j ) 2 (4) MSE=\frac1n\sum_{j=1}^n(z-z_j)^2\tag{4} MSE=n1j=1∑n(z−zj)2(4)
MAPE 是平均绝对百分比误差。 MAPE值越小,模型的预测精度越高。
KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: …-z_j}z|\tag{5}
4. 文献解读
4.1 Introduction
水质预测对于水资源和环境的规划和管理具有重要意义。单一的ARIMA模型很难全面有效地处理河流水质的非线性变化,需要与其他算法相结合。K-means算法是聚类分析中基于分区的算法。它具有思想简单、易于实现、效果好的特点,被广泛应用于机器学习等领域。本文提出一种结合ARIMA和聚类模型的水质预测方法。以某流域水质监测数据为样本,选取水质TP指数作为预测对象。
首先对样本数据进行清洗、平稳分析和白噪声分析。其次,根据贝叶斯信息准则(BIC)原理选择合适的参数,并利用ARIMA获得趋势分量特征进行水质预测。再次,采用K-means聚类方法分析监测水场降水量与TP指数的关系,计算降水量对水质变化的随机增量特征。最后结合趋势分量特征和随机增量特征计算出水质预测结果。
4.2 创新点
- 结合时序预测模型与聚类算法对水质进行预测
- 分别对两部分进行实验,并验证了其优越性
4.3 实验过程
4.3.1 数据来源
数据来源于某流域2019年1月1日至2020年12月31日的水质数据,共有16876行数据,主要9个指标,分别是水温、pH、溶解氧、电导率、浊度、高锰酸盐指数、氨氮氮、TP 和总氮。九个指标的尺寸如下表
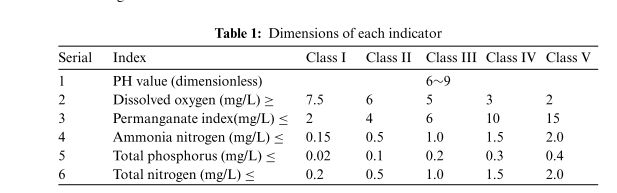
其中,高锰酸盐指数、氨氮、总磷和总氮每4小时采集一次,其他5项指标每小时采集一次。选择TP指数作为研究对象。 2019年至2020年爬取的原始数据如下表,其中水质数据存在部分缺失值。
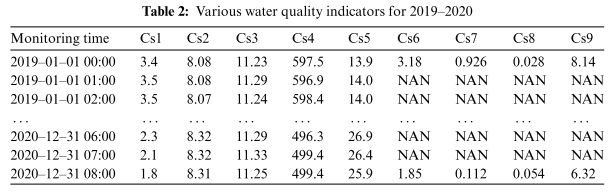
通过使用线性插值来处理缺失值。缺失数据处理流程如下图所示

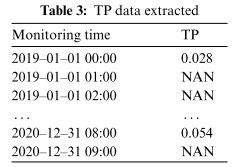
首先导入2019-2020年TP数据如上表,然后重命名列名和索引,之后确定缺失值,根据是否存在缺失值来填写数据。最后计算TP的日均值,结果如下表
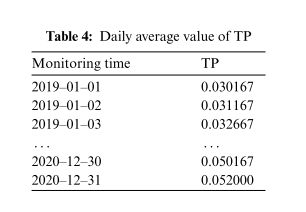
4.3.2 使用ARIMA模型预测
ARIMA建模主要包括平稳性检验、白噪声检验、参数确定和模型预测等几个步骤。
2020年数据集中选取2020年7月1日至2020年11月9日的数据。选择该时段的数据是因为需要与后续章节中预测模型所使用的数据集保持一致,形成对比,预测2020年11月10日至2020年11月19日的TP指标。时间序列图2020年7月1日至2020年11月9日总磷含量见下图

平稳性检验:为了进一步判断该序列是否稳定,采用严格的统计检验方法Augmented Dickey-Fuller(ADF)系数来判断。当前数据的ADF系数为:p =1.975175e−6 ,说明这段时间的数据是平稳数据,所以这段时间的数据不需要进行差分计算。自相关函数(ACF)可以粗略判断序列是否平稳。随着延迟阶数的增加,平稳序列的自相关系数将很快衰减到零。 ACF图如下图所示,可以粗略判断该序列是平稳序列。

白噪声检测:主要是根据p值的大小来判断是否是随机序列。白噪声检测结果为: p = 2.59492822e−12 ,表明数据为非白噪声,可以通过 ARIMA 建模。
参数确定:为了确定p、q值,将使用BIC,其计算公式为:
B I C = − 2 ln ( L ) + k ln ( n ) (6) BIC=-2\ln(L)+k\ln(n) \tag{6} BIC=−2ln(L)+kln(n)(6)
其中 k 是模型参数的数量,n 是样本的数量,L 是似然函数。
通过设置p和q的最大值和最小值,然后遍历不同的p和q,得到BIC热图,如下图所示。根据最小BIC原则,选择p=1和q=0。此时BIC为-566.11,其值最小。
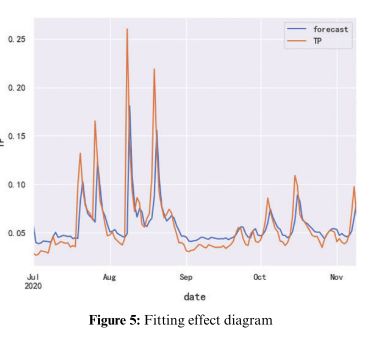
利用得到的ARIMA(1,0,0)模型对数据进行拟合,拟合结果如下图所示,可以看出该模型对数据的拟合取得了良好的效果。
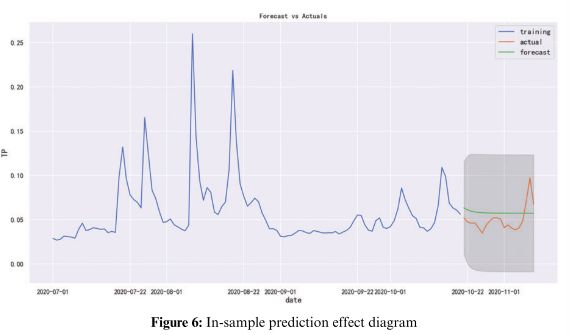
以2020年7月1日至2020年10月20日的数据为训练集,2020年10月21日至2020年11月9日的数据为测试集,使用ARIMA(1,0,0)模型预测TP指数,结果如下图所示,可以看出样本数据的预测效果比较可信,置信区间为95%。
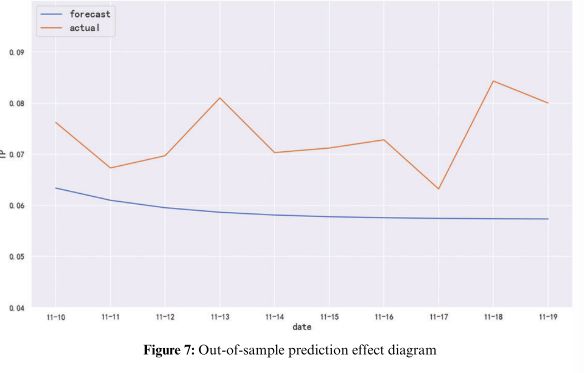
最后利用该模型进行样本外预测,预测结果如下图所示。可以看出,该模型无法准确预测实际数据的变化趋势,因此ARIMA模型对本期数据的预测效果较为不理想。
常用的评价指标MAE、MSE、MAPE,结果如下表

从评价指标也可以看出,利用ARIMA模型预测TP指数,其预测精度不高。这是因为ARIMA模型仅提取水质变化的趋势分量特征,而无法提取随机变化特征。为此,拟分析降水监测对TP指标的随机影响,提取TP变化的随机特征。
4.3.3 K-means聚类分析和相关性分析
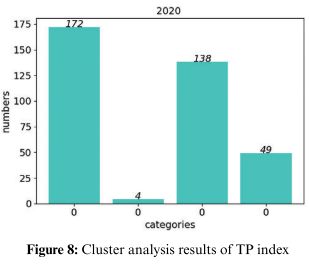
对2020年TP数据进行了聚类分析,结果如上图所示。
通过聚类分析可以看出,TP数据大部分时间分布在0.02~0.065之间,但也有少量数据分布在该范围之外。故还有其他因素影响了TP指标数据的走势。因此进一步分析检测水域附近将于对TP指数的影响。
为了验证假设,根据统计年鉴(http://tjj.xa.gov.cn/)爬取的降雨数据,流域附近七个地区2019年的降雨数据如下表所示。并将每月的TP总和添加到表尾
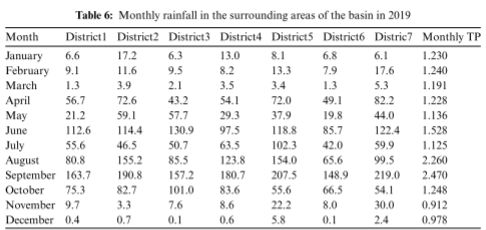
2019年流域降雨时段集中在8-10月,各月TP总和在同一时期也处在较高水平。因此,分析TP数据与降雨数据的相关性就显得尤为必要。
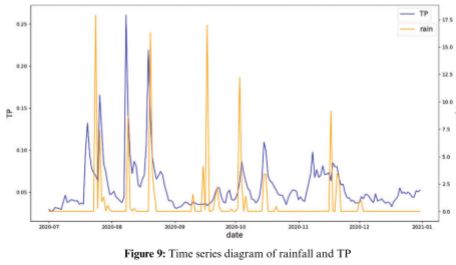
将2020年7月至2020年12月的降雨数据与TP数据叠加,时间序列图如下图所示。降雨数据是从降雨统计中下载的网站(http://www.wheata.cn/)。根据时间序列图可以看出,当降雨量增加时,TP值也随之增加。
通过对2019年月降雨增量数据与月TP增量数据进行相关性分析,得到相关性得分为0.82,回归线如图10所示,其一阶方程为: y = − 0.0359 + 0.00699 x y=-0.0359+0.00699x y=−0.0359+0.00699x
根据相关分析可以看出,降雨增量与TP增量之间存在较强的相关性。
4.3.4 联合ARIMA模型与聚类算法
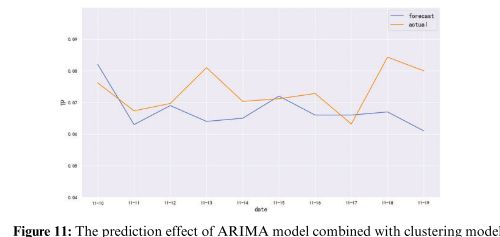
由于降雨量会影响TP指数,因此数据集的选择需要考虑降雨量数据。利用ARIMA模型结合聚类模型对2020年11月10日至2020年11月19日的数据进行预测,预测结果如上图所示。TP指数的预测值与这段时间内的实际数据。
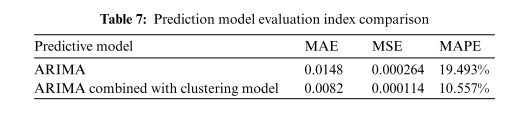
为了进一步分析该模型的预测效果,利用常用的评价指标MAE、MSE、MAPE对ARIMA模型的预测结果进行分析,结果如上表所示。从表中可以看出,与ARIMA模型相比,MAE值从0.0148下降到0.0082,MSE从0.000264下降到0.000114,MAPE从19.493%下降到10.557%。因此,ARIMA模型结合聚类模型的预测效果更加准确,预测误差更小。因此对于水质的预测具有较大的实际意义。
4.4 结论
针对TP数据变化的趋势性和随机性,结合ARIMA模型和聚类模型,提出一种基于趋势成分和随机增量特点的ARIMA模型和聚类模型相结合的水质预测方法。实验结果表明,其预测精度明显高于单一ARIMA模型。但该模型也存在一些不足。在预测TP指数时,还必须需要准确的降雨数据。
三、Hadoop基础
由于项目需要大数据相关技术,故学习该内容,深度学习实验在第四部分
1.基础知识
1.1 Hadoop简介
Hadoop是一个高可靠的(reliable),规模可扩展的(scalable),分布式(distributed computing)的开源软件框架。它能够作为简单的编程模型来处理存储于集群上的大数据集。
Hadoop是Apache基金会的一个开源项目,是一个提供了分布式存储和分布式计算功能的基础架构平台。可以应用于企业中的数据存储,日志分析,商业智能,数据挖掘等。
hadoop包含的模块:
- Hadoop common:提供一些通用的功能支持其他hadoop模块。
- Hadoop Distributed File System:即分布式文件系统,简称HDFS。主要用来做数据存储,并提供对应用数据高吞吐量的访问。
- Hadoop Yarn:用于作业调度和集群资源管理的框架。
- Hadoop MapReduce:基于yarn的,能用来并行处理大数据集的计算框架。
1.2 各核心组件功能
hdfs:数据切分,多副本,容错等机制都是Hadoop底层已经设计好的,对用户透明,用户不需要关系细节。只需要按照对单机文件的操作方式,就可以进行分布式文件的操作。如文件的上传,查看,下载等。
yarn:全称是Yet Another Resource Negotiator,负责整个集群资源的管理和调度。例如对每个作业,分配CPU,内存等等,都由yarn来管理。它的特点是扩展性,容错性,多框架资源统一调度。很多应用都可以运行在yarn之上,由yarn统一进行调度。
MapReduce:一个分布式计算框架,是GoogleMapReduce的克隆版。和HDFS、Yarn类似,也具有扩展性和容错性的特点,还将具有海量数据离线处理的特点:能够处理的数据量大,但并不是实时处理,具有较大的延时性。
以下为wordcount的mapreduce过程,mapping进行映射,reduce汇总,相同单词分发至一个节点上进行求和,最终汇总至master得到最后结果。
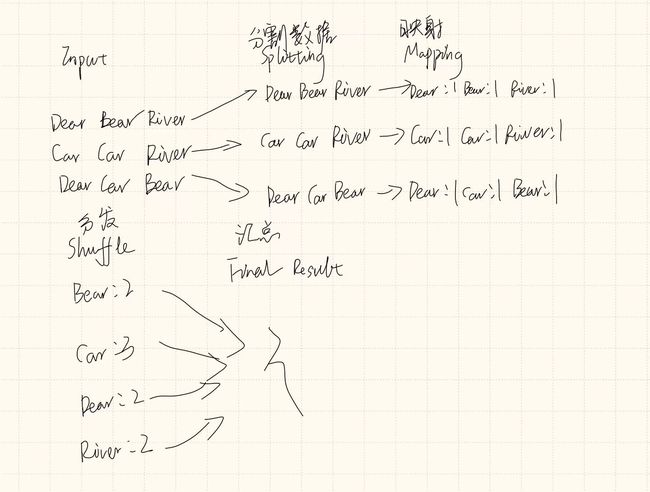
1.3 其他相关框架
Hive 处理的是海量结构化日志数据的统计问题。它定义了一种类似SQL的语言Hive QL,借助于hive引擎能将其转换为MapReduce作业并提交到集群上进行运算。hive适用于离线处理。相比之下,SQL的门槛就低得多
Mahout是一个机器学习算法库,实现了很多数据挖掘的经典算法,帮助用户很方便地创建应用程序。
Pig可以将脚本任务转换为MapReduce作业,同样是适用于离线分析。
Oozie是一个工作流调度引擎,用来处理具有依赖关系的作业调度。类似的框架有Azkaban,airflow等。
Zookeeper:分布式协调服务,“动物园管理员”角色,是一个对集群服务进行管理的框架,如维护故障切换等。
Flume:日志收集框架。将多种应用服务器上的日志,统一收集到HDFS上,这样就可以使用hadoop进行处理
Sqoop:提供关系型数据库与HDFS数据相互传输的功能。
Hbase:面向列存储的数据库。适用于实时快速查询的场景。
除此之外,还有spark,kafka,flink,redis等新兴的一些实用框架。
2. 完全分布式运行模式
2.1 虚拟机准备
-
克隆三台客户机:一台作为主机,其余两台为从机
-
ip示例如下
-
主机名称 IP 地址 master 192.168.217.130 slave1 192.168.217.131 slave2 192.168.217.132
-
-
每台机器分别修改
/etc/hosts文件,将每个机器的hostname和ip对应- vim /etc/hosts
- 192.168.217.130 master
192.168.217.131 slave1
192.168.217.132 slave2
-
虚拟机环境配置
-
修改克隆虚拟机的静态ip
-
vim /etc/sysconfig/network-scripts/ifcfg-网卡名称
- 终端上输入 ifconfig 或 ip addr,找出网卡名称
-
将 BOOTPROTO=dhcp 改成 BOOTPROTO=static、ONBOOT=no 改成 ONBOOT=yes
-
并在文件尾部添加以下内容
-
IPADDR=192.168.217.129 NETMASK=255.255.255.0 GATEWAY=192.168.217.2 DNFS1=192.168.217.2
-
-
重启网关服务
systemctl restart network
-
修改主机名
-
关闭防火墙
systemctl stop firewalldsystemctl disable firewalld:禁止开机启动- 关闭Selinux:
vim /etc/sysconfig/selinux:将 SELINUX=enforcing 改成 SELINUX=disabled
-
安装jdk
-
将安装包传递至虚拟机
-
创建java文件夹
-
将jdk解压至该目录下
-
配置环境变量
-
vim /etc/profile -
# JAVAHOME export JAVA_HOME=/usr/local/java/jdk1.8.0_151 export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$PATH:$JAVA_HOME/bin
-
-
source /etc/profile
-
-
检验安装是否成功
-
-
2.2 编写集群分发脚本xsync
- scp(secure copy)安全拷贝
该部分用于实现服务器与服务器之间的数据拷贝,scp -r source target
- rsync(remote synchronize)远程同步工具
rsync 主要用于备份和镜像,rsync -rvl source target
-
集群分发脚本
-
在
/usr/local/bin目录下创建xsync文件,vim xsync#!/bin/bash #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0)); then echo no args; exit; fi #2 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname #3 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 获取当前用户名称 user=`whoami` #5 循环 for i in master slave1 slave2 do echo "****************** $i *********************" rsync -rvl $pdir/$fname $user@$i:$pdir done -
修改文件权限,
chmod 777 xsync -
调用脚本形式:
xsync file
-
2.3 集群配置
- 集群部署规划
| - | master | slave1 | slave2 |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
-
配置集群
-
配置core-site.xml
-
<configuration> <property> <name>fs.defaultFSname> <value>hdfs://master:9000value> property> <property> <name>hadoop.tmp.dirname> <value>/hadoop/hadoop-2.7.7/data/tmpvalue> property> configuration>
-
-
hdfs配置
-
配置hadoop-env.sh
# The java implementation to use. export JAVA_HOME=/usr/local/java/jdk1.8.0_151 -
配置hadoop-env.sh
<configuration> <property> <name>dfs.replicationname> <value>3value> property> <property> <name>dfs.namenode.secondary.http-addressname> <value>slave2:50090value> property> configuration>
-
-
yarn配置文件
-
配置yarn-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_151 -
配置yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> <property> <name>yarn.resourcemanager.hostnamename> <value>slave1value> property> <property> <name>yarn.log-aggregation-enablename> <value>truevalue> property> <property> <name>yarn.log-aggregation.retain-secondsname> <value>604800value> property> configuration>
-
-
MapReduce 配置文件
-
配置mapred-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_151 -
配置 mapred-site.xml
<configuration> <property> <name>mapreduce.framework.namename> <value>yarnvalue> property> <property> <name>mapreduce.jobhistory.addressname> <value>master:10020value> property> <property> <name>mapreduce.jobhistory.webapp.addressname> <value>master:19888value> property> configuration>
-
-
-
在集群上分发配置好的 Hadoop 目录
xsync /hadoop/
四、BiLSTMCNN
1. 任务要求
定义了一个名为BiLSTMCNN的PyTorch模型,它是一个结合了双向长短时记忆网络(Bi-LSTM)和卷积神经网络(CNN)的模型。本文将使用从网络上爬取的序列信息作为数据集进行训练
2.实验结果
训练的最终结果如下

3.实验代码
网络结构
import torch
import torch.nn as nn
# 定义一个 BiLSTMCNN 类,继承自 PyTorch 的 nn.Module 类
class BiLSTMCNN(torch.nn.Module):
def __init__(self, config=None):
super(BiLSTMCNN, self).__init__()
# 根据配置选择 RNN 单元类型(RNN、LSTM、GRU)
if config.cell_type == 'RNN':
rnn_cell = nn.RNN
elif config.cell_type == 'LSTM':
rnn_cell = nn.LSTM
elif config.cell_type == 'GRU':
rnn_cell = nn.GRU
else:
raise ValueError("Unrecognized RNN cell type: " + config.cell_type)
# 定义模型的各个层
self.token_embedding = nn.Embedding(config.vocab_size, config.embedding_size)
self.rnn = rnn_cell(config.embedding_size, config.hidden_size, config.num_layers,
batch_first=True, bidirectional=True)
self.cnn = nn.Conv2d(2, config.out_channels, [config.kernel_size, config.hidden_size])
self.max_pool = nn.AdaptiveMaxPool2d((1, 1))
self.classifier = nn.Sequential(nn.Linear(config.out_channels, config.num_classes))
def forward(self, x, labels=None):
"""
:param x: [batch_size, src_len]
:param labels: [batch_size, tgt_len]
:return: logits: [batch_size, src_len, vocab_size]
"""
# 词嵌入层,将输入文本序列中的每个词编码为密集的词嵌入向量
x = self.token_embedding(x) # [batch_size, src_len, embedding_size]
# 双向循环神经网络层
x, _ = self.rnn(x) # [batch_size, src_len, 2 * hidden_size]
# 维度调整
x = torch.reshape(x, (x.shape[0], x.shape[1], 2, -1)) # [batch_size, src_len, 2 , hidden_size]
x = x.transpose(1, 2) # [batch_size, 2, src_len, hidden_size]
# 二维卷积层
x = self.cnn(x) # [batch_size, out_channels, src_len - kernel_size + 1, 1]
# 最大池化层
x = self.max_pool(x) # [batch_size, out_channels, 1, 1]
# 展平
x = torch.flatten(x, start_dim=1) # [batch_size, out_channels]
# 分类器
logits = self.classifier(x) # [batch_size, num_classes]
if labels is not None:
# 如果提供了标签,计算交叉熵损失
loss_fct = nn.CrossEntropyLoss(reduction='mean')
loss = loss_fct(logits, labels)
return loss, logits
else:
return logits
# 配置模型的超参数
class ModelConfig(object):
def __init__(self):
self.num_classes = 15
self.vocab_size = 8
self.embedding_size = 16
self.hidden_size = 512
self.num_layers = 2
self.cell_type = 'LSTM'
self.cat_type = 'last'
self.kernel_size = 3
self.out_channels = 64
# 主程序入口
if __name__ == '__main__':
config = ModelConfig()
model = BiLSTMCNN(config)
# 生成随机输入和标签
x = torch.randint(0, config.vocab_size, [2, 3], dtype=torch.long)
label = torch.randint(0, config.num_classes, [2], dtype=torch.long)
# 进行前向传播
loss, logits = model(x, label)
# 打印损失和模型输出
print(loss)
print(logits)
训练过程
# 导入必要的库和模块
from transformers import optimization
from torch.utils.tensorboard import SummaryWriter
import torch
from copy import deepcopy
import sys
import logging
import os
from BiLSTMCNN import BiLSTMCNN # 导入自定义的BiLSTMCNN模型
# 导入自定义的TouTiaoNews数据处理工具类
from utils import TouTiaoNews
# 配置模型的超参数
class ModelConfig(object):
def __init__(self):
# 训练超参数
self.batch_size = 256
self.epochs = 50
self.learning_rate = 6e-4
# 模型结构相关超参数
self.num_classes = 15
self.vocab_size = 3000
self.embedding_size = 256
self.hidden_size = 128 # RNN的隐藏层大小
self.num_layers = 1
self.cell_type = 'LSTM'
self.cat_type = 'last'
self.out_channels = 128 # CNN输入通道数
self.kernel_size = 3 # CNN卷积核大小
# 学习率调整策略相关超参数
self.num_warmup_steps = 200
# 模型保存路径和Tensorboard日志路径
self.model_save_path = 'model.pt'
self.summary_writer_dir = "runs/model"
# 设备选择
self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
logging.info("### 将当前配置打印到日志文件中 ")
for key, value in self.__dict__.items():
logging.info(f"### {key} = {value}")
# 训练函数
def train(config):
# 创建TouTiaoNews数据处理对象
toutiao_news = TouTiaoNews(top_k=config.vocab_size,
batch_size=config.batch_size,
cut_words=False)
# 加载训练和验证数据集迭代器
train_iter, val_iter = toutiao_news.load_train_val_test_data(is_train=True)
# 创建BiLSTMCNN模型
model = BiLSTMCNN(config)
# 如果已存在模型参数文件,则加载已有参数进行追加训练
if os.path.exists(config.model_save_path):
logging.info(f" # 载入模型{config.model_save_path}进行追加训练...")
checkpoint = torch.load(config.model_save_path)
model.load_state_dict(checkpoint)
# 使用Adam优化器
optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
# 使用Tensorboard记录训练过程
writer = SummaryWriter(config.summary_writer_dir)
model = model.to(config.device)
max_test_acc = 0
steps = len(train_iter) * config.epochs
# 使用余弦退火学习率调整策略
scheduler = optimization.get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=config.num_warmup_steps,
num_training_steps=steps, num_cycles=2)
# 开始训练
for epoch in range(config.epochs):
for i, (x, y) in enumerate(train_iter):
x, y = x.to(config.device), y.to(config.device)
# 前向传播,计算损失和logits
loss, logits = model(x, y)
optimizer.zero_grad()
loss.backward()
optimizer.step() # 执行梯度下降
scheduler.step()
# 每50个batch打印一次训练信息
if i % 50 == 0:
acc = (logits.argmax(1) == y).float().mean()
logging.info(f"Epochs[{epoch + 1}/{config.epochs}]--batch[{i}/{len(train_iter)}]"
f"--Acc: {round(acc.item(), 4)}--loss: {round(loss.item(), 4)}")
writer.add_scalar('Training/Accuracy', acc, scheduler.last_epoch)
writer.add_scalar('Training/Loss', loss.item(), scheduler.last_epoch)
# 在验证集上评估模型性能
test_acc = evaluate(val_iter, model, config.device)
logging.info(f"Epochs[{epoch + 1}/{config.epochs}]--Acc on val {test_acc}")
writer.add_scalar('Testing/Accuracy', test_acc, scheduler.last_epoch)
# 如果验证准确率超过历史最大值,则保存模型参数
if test_acc > max_test_acc:
max_test_acc = test_acc
state_dict = deepcopy(model.state_dict())
torch.save(state_dict, config.model_save_path)
# 评估函数
def evaluate(data_iter, model, device):
model.eval()
with torch.no_grad():
acc_sum, n = 0.0, 0
for x, y in data_iter:
x, y = x.to(device), y.to(device)
logits = model(x)
acc_sum += (logits.argmax(1) == y).float().sum().item()
n += len(y)
model.train()
return acc_sum / n
# 推理函数
def inference(config, test_iter):
model = BiLSTMCNN(config)
model.to(config.device)
model.eval()
# 如果存在模型参数文件,则加载参数进行推理
if os.path.exists(config.model_save_path):
logging.info(f" # 载入模型进行推理……")
checkpoint = torch.load(config.model_save_path)
model.load_state_dict(checkpoint)
else:
raise ValueError(f" # 模型{config.model_save_path}不存在!")
# 获取测试数据的第一个batch
first_batch = next(iter(test_iter))
with torch.no_grad():
logits = model(first_batch[0].to(config.device))
y_pred = logits.argmax(1)
logging.info(f"真实标签为:{first_batch[1]}")
logging.info(f"预测标签为:{y_pred}")
# 主程序入口
if __name__ == '__main__':
config = ModelConfig()
train(config)
# 推理
# toutiao_news = TouTiaoNews(top_k=config.vocab_size,
# batch_size=config.batch_size,
# cut_words=False)
# test_iter = toutiao_news.load_train_val_test_data(is_train=False)
# inference(config, test_iter)
小结
本周主要了解了龙格库塔方法,该方法用于求解常微分方程,通过点到点的斜率迭代获取各点的斜率,最后联合 y n y_n yn获取 y n + 1 y_{n+1} yn+1。本周阅读的论文将时序模型与聚类算法相结合。其首先单独使用时序模型预测TP指数,效果不佳;然后使用聚类算法进行分析确定了降雨与TP指数之间存在联系;最后联合两种方法进行,并证明了该方法的优越性。
下周将继续阅读环境领域的人工智能相关论文,并继续学习接下来可能使用的数学工具。此外,还计划进一步了解hadoop的完全分布式部署流程
参考文献
[1] Jiang Wu, Jianjun Zhang, Wenwu Tan, Hao Lan, Sirao Zhang, KeXiao, Li Wang,
Haijun Lin, Guang Sun and Peng Guo: Application of Time Serial Model in Water Quality Predicting.[J].DOI: 10.32604/cmc.2023.030703