STM32H7解决DMA伪双缓存中的出现Cache问题
文章目录
- 一、前言背景
- 二、原理概述
-
- (一)Cache 概述
- (二)DMA双缓存原理
- (三)环形FIFO的数据类型
- 三、部分CubeMX配置和核心代码实现
-
- (一)Cache和MPU配置
- (二)环形FIFO数据类型的实现
- (三)ADC双缓冲中CPU拷贝的两种思路
- 参考资料
一、前言背景
由于STM32H7的教程较少,以及LL库的教程较少,笔者就将自己的一些微薄见解发表于此,还望网友多多包涵。本笔记也参考了不少资料和文章,笔者只是拾人牙慧的小屁孩。
笔者在STM32H7在使用DMA时出现了数据不对的情况,于是了解了Cache,MPU等,以下将会从一个笔者的Demo案例(利用DMA的半、满中断进行双缓存的ADC传输)中深入浅出地了解这个事情。
二、原理概述
(一)Cache 概述
随着工艺和设计的演进,CPU 计算性能其实发生了翻天覆地的变化,但是DRAM存储性能的发展没有那么快。所以造成了一个问题,存储限制了计算的发展。容量与速度不可兼得。
以 STM32H7 为例,主频是 400多MHz,除了 TCM 和 Cache 以 400多MHz工作,其它 AXI SRAM,SRAM1,SRAM2 等都是以 200多MHz 工作。数据缓存 D-Cache 就是解决 CPU加速访问 SRAM。当然,I-Cache也就是指令缓存,也是同样类似的道理。
那么缓存究竟是什么呢?
这里我们就不得不讨论到局部性原理——即一个元素一旦被访问到,很可能在短时间再次被访问到(时间局部性)和一个元素周围的元素很有可能会接下来被访问到(空间局部性)。
举两个例子,就任意明白了:
时间局部性:
int a = 10;
for (int i = 0; i < 5; ++i) {
printf(a);
}
空间局部性:
int buffer[5];
for (int i = 0; i < 5; ++i) {
printf(buffer[i]);
}
而反观我们读取数据这一个过程:

这其中CPU通过一个特定的地址访问内存,内存响应这一请求,将内存返回。不过,存储器(Memory)离CPU越远,容量越大,通常速度越慢。(有得有失嘛)这就造成了速度差,而CPU若继续等待全部数据返回之后再进行下一语句,则就体现不出CPU高速的优点了。于是,我们有了缓存(Cache)。
当CPU需要访问的数据在Cache正好有,那么我们就不需要再去Memory慢慢等了,直接从缓存来得到数据,这学术上就叫CacheHit(击中)。
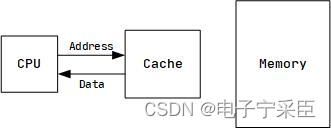
当然,不可能什么事情都如此的巧妙,如果Cache中没有所需数据,则重新回到Memory中获取。这学术上叫CacheMiss(丢失)。
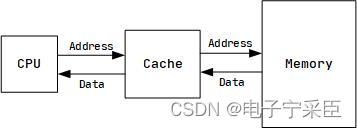
当然,写操作和读操作大同小异。
现在让我们回到STM32H7的数据手册中,这是关于Cache和MPU(内存保护单元,一般搭配Cache使用)的配置:
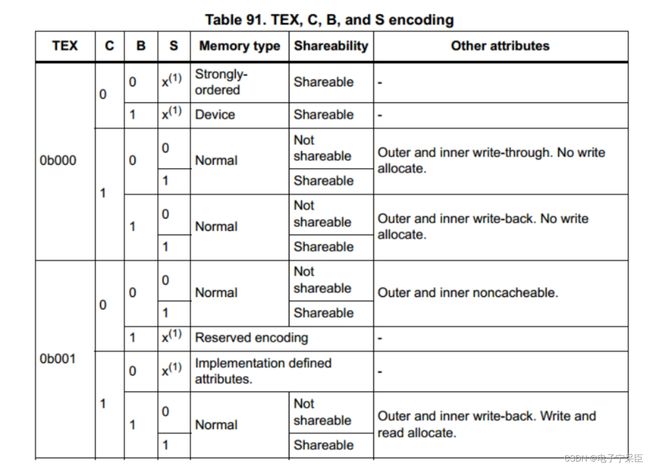 MPU 可以配置的三种内存类型:
MPU 可以配置的三种内存类型:
- Normal memory:CPU 以最高效的方式加载和存储字节、半字和字,对于这种内存区,CPU 的加载或存储不一定要按
照程序列出的顺序执行。 - Device memory:对于这种类型的内存区,加载和存储要严格按照次序进行,这样是为了确保寄存器按照正确顺序设置。
- Strongly ordered memory: 程序完全按照代码顺序执行,CPU 需要等待当前的加载/存储指令执行完毕后才执行下一条指令。这样会导致性能下降。
这些都对应着Cache支持的四种策略:

- 如果配置为Non-cacheable:
那就是正常的读写,无Cache。 - 如果配置为Write through,read allocate,no write allocate:
如果 CPU 要写的 SRAM 区数据在 Cache 中已经开辟了对应的区域,那么会同时写到 Cache 里面和SRAM 里面;如果没有,就用到配置 no write allocate 了,意思就是 CPU 会直接往 SRAM 里面写数据,而不再需要在 Cache 里面开辟空间了。
所以它叫no write allocate,就是讲的CacheMiss时,就不需要Cache再中转一下了,直接去SRAM了。
不过也存在问题,在写 CacheHit 的情况下,这个方式的优点是 Cache 和 SRAM 的数据同步更新了,没有多总线访问造成的数据一致性问题。缺点也明显,Cache 在写操作上无法有效发挥性能。
如果 CPU 要读取的 SRAM 区数据在 Cache 中已经加载好,就可以直接从 Cache 里面读取。如果没有,就用到配置 read allocate 了,意思就是在 Cache 里面开辟区域,将 SRAM 区数据加载进来,后续的操作,CPU 可以直接从 Cache 里面读取,从而时间加速。M7 内核只要开启了 Cache,read allocate 就是开启的。
不过需要注意的是,如果 CacheHit 的情况下,DMA 写操作也更新了 SRAM 区的数据,CPU 直接从 Cache里面读取的数据就是错误的。
就好比刻舟求剑(笔者奇怪的比喻又增加了 ૮(˶ᵔ ᵕ ᵔ˶)ა )。 - 如果配置为Write back,read allocate,no write allocate:
如果 CPU 要写的 SRAM 区数据在 Cache 中已经开辟了对应的区域,那么会写到 Cache 里面,而不会立即更新SRAM;如果没有,就用到配置 no write allocate 了,意思就是 CPU 会直接往 SRAM 里面写数据,而不再需要在 Cache 里面开辟空间了。
这次策略存在的问题是,如果 CacheHit 的情况下,此时仅 Cache 更新了,而 SRAM 没有更新,那么 DMA 直接从 SRAM 里面读出来的就是错误的。 - 如果配置为Write back,read allocate,write allocate:
如果 CPU 要写的 SRAM 区数据在 Cache 中已经开辟了对应的区域,那么会写到 Cache 里面,而不会立即更新 SRAM;如果没有,就用到配置 write allocate 了,意思就是 CPU 写到往 SRAM 里面的数据,会同步在 Cache 里面开辟一个空间将 SRAM 中写入的数据加载进来,如果此时立即读此 SRAM 区,那么就会有很大的速度优势。
这次策略存在的问题是,如果 CacheHit 的情况下,此时仅 Cache 更新了,而 SRAM 没有更新,那么 DMA 直接从 SRAM 里面读出来的就是错误的。
其中,对于读操作,只有在第 1 次访问指定地址时才会加载到 Cache,而写操作的话,可以直接写到内存中(write-through 模式)或者放到 Cache 里面,后面再写入(write-back 模式)。
如果采用的是 Write back,Cache line 会被标为 dirty,等到此行被 evicted 时(evicted是指将缓存中的某一行数据从缓存中移除或淘汰的过程),才会执行实际的写操作,将 Cache Line 里面的数据写入到相应的存储区。
Cache 命中是访问的地址落在了给定的 Cache Line 里面,所以硬件需要做少量的地址比较工作,以检查此地址是否被缓存。如果命中了,将用于缓存读操作或者写操作。如果没有命中,则分配和标记新行,填充新的读写操作。如果所有行都分配完毕了,Cache 控制器将支持 eviction 操作。根据 Cache Line 替换算法,一行将被清除 Clean,无效化 Invalid 或者重新配置。
这对应了Cache 支持的 4 种基本操作,使能,禁止,清空和无效化。Clean 清空操作是将 Cache Line 中标记为 dirty 的数据写入到内存里面,而无效化 Invalid 是将 Cache Line 标记为无效。
清除 Clean,无效化 Invalid的区别:
- Clean的操作通常涉及将缓存行中被标记为dirty的数据写回到主存RAM中。dirty的数据是指缓存中的数据已被修改,与主存中的数据不同步。通过执行 Clean 操作,是将 Cache Line 中标记为 dirty 的数据写入到相应的存储区。
- Invalid 的操作通常涉及将缓存行标记为无效,表示该行中的数据已经过时或者无效。Invalid 将数据 Cache 无效化,无效化的意思是将 Cache Line 标记为无效,全部都写入到相应的存储区。这样Cache 空间就都腾出来了,可以加载新的数据。
(二)DMA双缓存原理
很多DMA接收的教程、例子,基本是使用了DMA传输完成中断来接收数据。实质上这是存在风险的,当DMA传输数据完成,CPU开始拷贝DMA通道buf数据,如果此时串口继续有数据进来,DMA继续搬运数据到buf,就有可能将数据覆盖,因为DMA数据搬运是不受CPU控制的,即使你关闭了CPU中断。
严谨的做法需要做双缓存,CPU和DMA各自一块内存交替访问,即"乒乓缓存” :
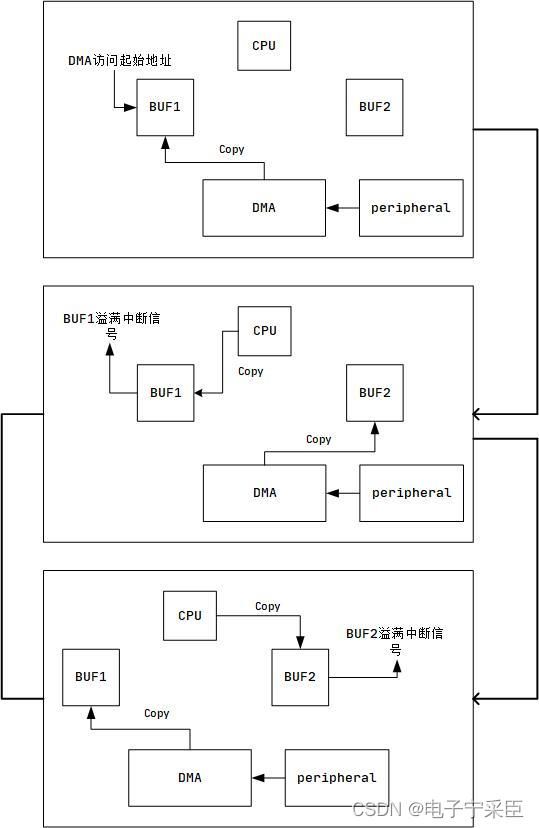
- DMA先将数据搬运到BUF1,搬运完成通知CPU来拷贝BUF1数据。
- DMA将数据搬运到BUF2,与CPU拷贝BUF1数据不会冲突。
- BUF2数据搬运完成,通知CPU来拷贝BUF2数据。
- 执行完第三步,DMA返回执行第一步,一直循环。
当然也可以利用DMA半满中断实现伪装双缓存功能,只要将BUF空间开辟大一点即可:

- DMA将数据搬运完成BUF的前一半时,产生“半满中断”,CPU来拷贝BUF前半部分数据。
- DMA继续将数据搬运到buf的后半部分,与CPU拷贝BUF前半部数据不会冲突。
- BUF后半部分数据搬运完成,触发“溢满中断”,CPU来拷贝BUF后半部分数据。
- 执行完第三步,DMA返回执行第一步,一直循环。
(三)环形FIFO的数据类型
背景原理
在笔者的Demo中,涉及ADC的数据存放问题,如果直接存放在DMA的BUF中,依旧可能存在BUF被刷新覆盖的问题。于是想到除了硬件层面的缓冲区(Cache、硬件FIFO等),在软件层面也设计一个环形缓冲区。(环形缓冲区,顾名思义就是一段循环使用的一段内存。通过写指针向“空白内存”(未写入过或者已经被读出的内存)写入数据并记录,读指针从已写的内存读取数据并记录,当指针访问到内存最后一个位置时,再折回第一个内存位置,达到循环效果。)
要求是先进先出(选择使用FIFO),且重复使用(使用环形结构)。
注意事项
- 环形缓冲区本质是“生产者消费者”模型,必须先有生产(写)后有消费(读),不可提前消费(读);
- 注意程序效率问题,如果读效率过低,导致“生产”过剩,从而覆盖未读出的数据,导致出错,此时需增加环形缓冲区内存大小或者优化代码效率;
- 单一线程访问时是安全的,多线程访问时,为保证数据安全性必须加互斥锁机制;
应用场合
在笔者的Demo中,ADC采集数据后利用DMA传输数据:
DMA中断—>数据接收(接收的DMABUF)—>写入环形缓冲区—>数据处理线程读取环形缓冲区—>处理有效数据。
当然,笔者还给出了一种思路:
DMA中断—>数据接收(接收的DMABUF)—>标志位置位
主循环—>如果标志位置位—>写入环形缓冲区—>数据处理线程读取环形缓冲区—>处理有效数据。
三、部分CubeMX配置和核心代码实现
(一)Cache和MPU配置
笔者使用STM32CubeMX工具进行配置来生成代码,十分的方便。
首先是MPU的配置和Cache的配置:
Cache选择全部开启(I-Cache和D-Cache),然后配置MPU:
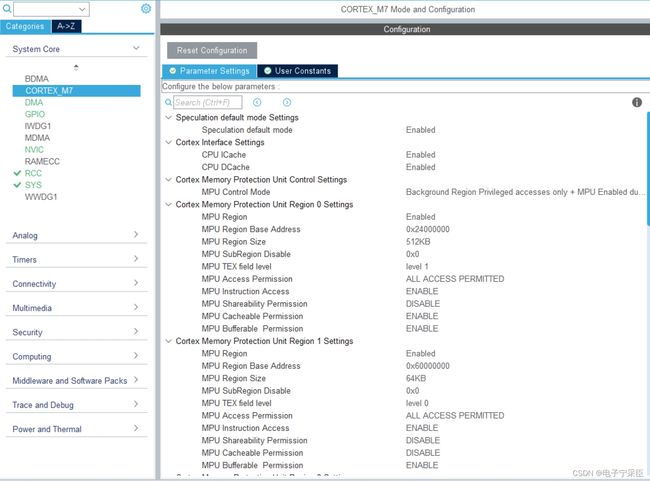
其任务为:
- 配置AXI SRAM (地址为0x24000000,大小512KB)的 MPU 属性为
Write back, Read allocate,Write allocate。 - 配置 FMC 扩展 IO (地址为0x60000000,大小64KB)的 MPU 属性为
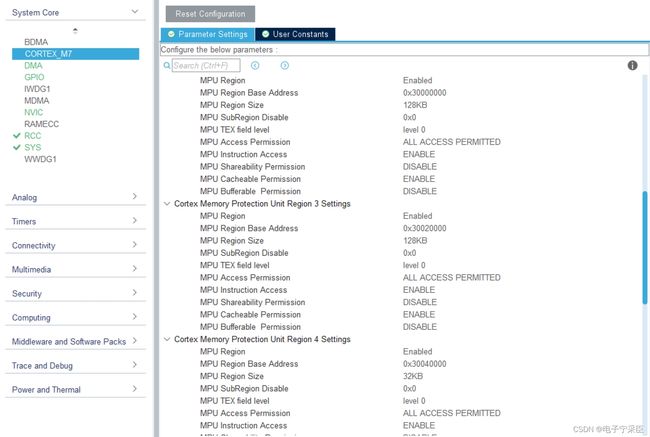
Device或者Strongly Ordered。 - 配置 SRAM1 (地址为0x30000000,大小128KB)的属性为
Write through, read allocate,no write allocate。 - 配置 SRAM2 (地址为0x30020000,大小128KB)的属性为
Write through, read allocate,no write allocate。 - 配置 SRAM3 (地址为0x30040000,大小32KB)的属性为
Write through, read allocate,no write allocate。 - 配置 SRAM4 (地址为0x38000000,大小64KB)的属性为
Write through, read allocate,no write allocate。
为了方便我们以后更好地为内存规划其物理地址,我们改写STM32H743VITX_FLASH.ld:
/* Highest address of the user mode stack */
_estack = ORIGIN(AXI_SRAM) + LENGTH(AXI_SRAM); /* end of RAM */
/* Generate a link error if heap and stack don't fit into RAM */
_Min_Heap_Size = 0x2000; /* required amount of heap */
_Min_Stack_Size = 0x1000; /* required amount of stack */
/* Specify the memory areas */
MEMORY
{
DTCMRAM (xrw) : ORIGIN = 0x20000000, LENGTH = 128K
AXI_SRAM (xrw) : ORIGIN = 0x24000000, LENGTH = 512K
SRAM1 (xrw) : ORIGIN = 0x30000000, LENGTH = 128K
SRAM2 (xrw) : ORIGIN = 0x30020000, LENGTH = 128K
SRAM3 (xrw) : ORIGIN = 0x30040000, LENGTH = 32K
SRAM4 (xrw) : ORIGIN = 0x38000000, LENGTH = 64K
ITCMRAM (xrw) : ORIGIN = 0x00000000, LENGTH = 64K
FLASH (rx) : ORIGIN = 0x08000000, LENGTH = 2048K
}
/* ...此处省略修改过程 */
._AXI_SRAM_Area_512KB :
{
. = ALIGN(4);
. = ALIGN(4);
} >AXI_SRAM
._SRAM1_Area_128KB :
{
. = ALIGN(4);
. = ALIGN(4);
} >SRAM1
._SRAM2_Area_128KB :
{
. = ALIGN(4);
. = ALIGN(4);
} >SRAM2
._SRAM3_Area_32KB :
{
. = ALIGN(4);
. = ALIGN(4);
} >SRAM3
._SRAM4_Area_64KB :
{
. = ALIGN(4);
. = ALIGN(4);
} >SRAM4
并定义几个方便的宏:
/* STM32 H7 Memory Address Typedef */
#define __AT_AXI_SRAM_ __attribute__((section("._AXI_SRAM_Area_512KB")))
#define __AT_SRAM1_ __attribute__((section("._SRAM1_Area_128KB")))
#define __AT_SRAM2_ __attribute__((section("._SRAM2_Area_128KB")))
#define __AT_SRAM3_ __attribute__((section("._SRAM3_Area_32KB")))
#define __AT_SRAM4_ __attribute__((section("._SRAM4_Area_64KB")))
#define ALIGN_32B(buf) buf __attribute__ ((aligned (32)))
(二)环形FIFO数据类型的实现
//
// Created by Whisky on 12/30/2023.
//
#ifndef CODE_FIFO_H
#define CODE_FIFO_H
#ifndef __TYPEDEF_LOCK_FUN__
typedef void (*lock_fun)(void);
#endif
template<typename T, uint32_t MAX_SIZE>
class Fifo
{
private:
T buf[MAX_SIZE];
uint32_t size; /* 有效数据大小 */
uint32_t pwriteIndex; /* 写索引 */
uint32_t preadIndex; /* 读索引 */
void (*lock)(void); /* 互斥上锁 */
void (*unlock)(void); /* 互斥解锁 */
public:
Fifo(lock_fun lock = nullptr, lock_fun unlock = nullptr);
~Fifo();
uint32_t Put(const T &data);
uint32_t Get(T &data);
uint32_t Puts(T *pData, uint32_t num);
uint32_t Gets(T *pData, uint32_t num);
uint32_t Size(void);
uint32_t Get_FreeSize(void);
void Clear(void);
};
/**
* Constructor,Initialize the queue
*/
template<typename T, uint32_t MAX_SIZE>
Fifo<T,MAX_SIZE>::Fifo(lock_fun Lock_fun, lock_fun Unlock_fun)
:size(0), pwriteIndex(0), preadIndex(0), lock(Lock_fun), unlock (Unlock_fun)
{
}
template<typename T, uint32_t MAX_SIZE>
Fifo<T, MAX_SIZE>::~Fifo() {
size = 0;
pwriteIndex = 0;
preadIndex = 0;
lock = nullptr;
unlock = nullptr;
}
/**
* input one node to buffer
*/
template<typename T, uint32_t MAX_SIZE>
uint32_t Fifo<T,MAX_SIZE>::Put(const T &c)
{
if(Get_FreeSize() == 0)
return 0;
if (lock != nullptr)
lock();
buf[pwriteIndex++] = c;
if (pwriteIndex >= MAX_SIZE)
pwriteIndex = 0;
size++;
if (unlock != nullptr)
unlock();
return 1;
}
/**
* input multi nodes to buffer
*/
template<typename T, uint32_t MAX_SIZE>
uint32_t Fifo<T,MAX_SIZE>::Puts(T *pData, uint32_t num)
{
uint32_t w_size, free_size;
if (num==0)
return 0;
free_size = Get_FreeSize();
if(free_size == 0)
return 0;
if(free_size < num)
num = free_size;
w_size = num;
if (lock != nullptr)
lock();
while(w_size-- > 0)
{
buf[pwriteIndex++] = *pData++;
if (pwriteIndex >= MAX_SIZE)
pwriteIndex = 0;
size++;
}
if (unlock != nullptr)
unlock();
return num;
}
/**
* get one node from buffer
*/
template<typename T, uint32_t MAX_SIZE>
uint32_t Fifo<T,MAX_SIZE>::Get(T &data)
{
if(size == 0)
return 0;
if (lock != nullptr)
lock();
data = buf[preadIndex++];
if (preadIndex >= MAX_SIZE)
preadIndex = 0;
size--;
if (unlock != nullptr)
unlock();
return 1;
}
/**
* get multi nodes from buffer
*/
template<typename T, uint32_t MAX_SIZE>
uint32_t Fifo<T,MAX_SIZE>::Gets(T *pData, uint32_t num)
{
uint32_t r_size, occupy_size;
if (num==0)
return 0;
occupy_size = size;
if(occupy_size == 0)
return 0;
if(occupy_size < num)
num = occupy_size;
if (lock != nullptr)
lock();
r_size = num;
while(r_size-- > 0)
{
*pData++ = buf[preadIndex++];
if (preadIndex >= MAX_SIZE)
preadIndex = 0;
size--;
}
if (unlock != nullptr)
unlock();
return num;
}
template<typename T, uint32_t MAX_SIZE>
uint32_t Fifo<T,MAX_SIZE>::Size()
{
return (size);
}
/**
*clear all nodes in buffer
*/
template<typename T, uint32_t MAX_SIZE>
void Fifo<T,MAX_SIZE>::Clear()
{
pwriteIndex = 0;
preadIndex = 0;
size = 0;
}
template<typename T, uint32_t MAX_SIZE>
uint32_t Fifo<T, MAX_SIZE>::Get_FreeSize(void) {
return (MAX_SIZE - size);
}
#endif //CODE_FIFO_H
(三)ADC双缓冲中CPU拷贝的两种思路
这里的两种思路对应着在原理概述中描述环形FIFO两种应用场景:
第一种思路
DMA中断—>数据接收(接收的DMABUF)—>写入环形缓冲区—>数据处理线程读取环形缓冲区—>处理有效数据。
void ADC::Irq_DMA(void) {
// 完成中断,当前 DMA 正在使用缓冲区的前半部分,用户可以操作后半部分。
if(LL_DMA_IsEnabledIT_TC(adc_dma, adc_dma_stream) && PLATFORM_DMA_IsActiveFlag_TC(adc_dma, adc_dma_stream))
{
// SCB_InvalidateDCache_by_Addr 的参数是 byte num: uint16_t -> (ADC_DMA_BUFFER_SIZE / 2 )* 2
SCB_InvalidateDCache_by_Addr((uint32_t *)(&adc_dma_buffer[ADC_DMA_BUFFER_SIZE / 2]), ADC_DMA_BUFFER_SIZE);
bufferADC.Puts((uint16_t *)(&adc_dma_buffer[ADC_DMA_BUFFER_SIZE / 2]), ADC_DMA_BUFFER_SIZE/2);
flag_finished = true;
Platform_DMA_ClearFlag_TC(adc_dma, adc_dma_stream);
}
// 半完成中断,当前 DMA 正在使用缓冲区的后半部分,用户可以操作前半部分。
if(LL_DMA_IsEnabledIT_HT(adc_dma, adc_dma_stream) && PLATFORM_DMA_IsActiveFlag_HT(adc_dma, adc_dma_stream))
{
SCB_InvalidateDCache_by_Addr((uint32_t *)(&adc_dma_buffer[0]), ADC_DMA_BUFFER_SIZE);
bufferADC.Puts((uint16_t *)(&adc_dma_buffer[0]), ADC_DMA_BUFFER_SIZE/2);
Platform_DMA_ClearFlag_HT(adc_dma, adc_dma_stream);
}
}
第二种思路
DMA中断—>数据接收(接收的DMABUF)—>标志位置位
主循环—>如果标志位置位—>写入环形缓冲区—>数据处理线程读取环形缓冲区—>处理有效数据。
void ADC::Irq_DMA(void) {
// 完成中断
if(LL_DMA_IsEnabledIT_TC(adc_dma, adc_dma_stream) && PLATFORM_DMA_IsActiveFlag_TC(adc_dma, adc_dma_stream))
{
// SCB_InvalidateDCache_by_Addr 的参数是 byte num: uint16_t -> (ADC_DMA_BUFFER_SIZE / 2 )* 2
SCB_InvalidateDCache_by_Addr((uint32_t *)(&adc_dma_buffer[ADC_DMA_BUFFER_SIZE / 2]), ADC_DMA_BUFFER_SIZE);
flag_finished = true;
Platform_DMA_ClearFlag_TC(adc_dma, adc_dma_stream);
}
// 半完成中断
if(LL_DMA_IsEnabledIT_HT(adc_dma, adc_dma_stream) && PLATFORM_DMA_IsActiveFlag_HT(adc_dma, adc_dma_stream))
{
SCB_InvalidateDCache_by_Addr((uint32_t *)(&adc_dma_buffer[0]), ADC_DMA_BUFFER_SIZE);
flag_halfFinished = true;
Platform_DMA_ClearFlag_HT(adc_dma, adc_dma_stream);
}
}
然后使用在主循环中使用Scan_Data来轮询等待标志位的置位。
bool ADC::Scan_Data(void) {
if (flag_halfFinished)
{
DISABLE_INT();
flag_halfFinished = false;
bufferADC.Puts((uint16_t *)(&adc_dma_buffer[0]), ADC_DMA_BUFFER_SIZE/2);
ENABLE_INT();
}
else if (flag_finished)
{
DISABLE_INT();
flag_finished = false;
bufferADC.Puts((uint16_t *)(&adc_dma_buffer[ADC_DMA_BUFFER_SIZE / 2]), ADC_DMA_BUFFER_SIZE/2);
ENABLE_INT();
return true;
}
return false;
}
CPU搬运了数据到FIFO后,我们只需在FIFO中出队就行了(FIFO自带顺序):
bool ADC::Get_Data(uint16_t *buffer, uint32_t number) {
if(bufferADC.Size() < number)//没有足够长的数据
return false;
else
{
bufferADC.Gets(buffer,number);//数据出队
return true;
}
}
使用案例
这里以第二种思路为例,
实例化对象,注意这里使用的内存是SRAM4 ,它的属性为 Write through, read allocate,no write allocate。其中还需要32位对齐,以方便InvalidateDCache的操作。
ALIGN_32B(__AT_SRAM4_ ADC adc);
初始化它
void ClassInit(void)
{
/* ...省略其他代码 */
adc = ADC(3, 2, 0, 1, channel1);//使用TIM1的通道1的Capture Compare event事件触发的ADC3,其使用的DMA流为DMA2Stream0
}
并使能它
void Init(void)
{
/* ...省略其他代码 */
cout << "Hello World" << '\n';
adc.Start(1000); //采样率1000Hz开启
}
在循环中添加代码
void Loop(void)
{
/* ...省略其他代码 */
if (adc.Scan_Data())
{
adc.Stop();
cout << "ADC is ok\n";
if (adc.Get_Data(buffer, adc.Get_DataSize()))
{
for (int i = 0; i < ADC_DMA_BUFFER_SIZE; ++i) {
cout << i << " " << buffer[i] << '\n';
}
}
}
}
完整工程可见
Github: 笔者的STM32 C++库 持续开发中
参考资料
- B站视频——理解计算机Cache:从块到缓存结构,以及逐步推出映射策略
- 安富莱_STM32-V7开发板_用户手册,含BSP驱动包设计(V3.5)
- 一个严谨的STM32串口DMA发送&接收(1.5Mbps波特率)机制
- 【组件】通用环形缓冲区模块