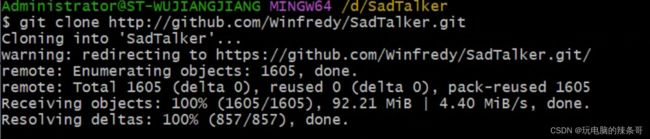
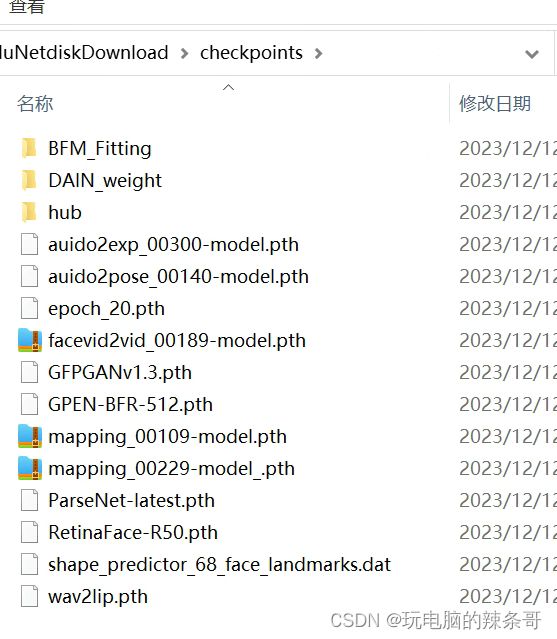
- 什么是证书吊销列表?CRL 解释
WoTrusSSL
sslhttps
数字证书是安全在线互动的支柱,用于验证身份和确保加密通信。但是,当这些证书被盗用或滥用时,必须立即撤销它们以维持信任。这就是证书撤销列表(CRL)的作用所在。CRL由证书颁发机构(CA)维护,对于识别和撤销已撤销的证书,防止其造成危害至关重要。在本指南中,我们将探讨什么是CRL、它们如何运作以及为什么它们对网络安全至关重要。什么是证书吊销列表(CRL)?证书吊销列表(CRL)是证书颁发机构(CA)
- 驱动程序为什么要做 WHQL 认证?
GDCA SSL证书
网络协议网络
驱动程序进行WHQL(WindowsHardwareQualityLabs)认证的核心价值在于解决兼容性、安全性和市场准入三大关键问题,具体必要性如下:️一、规避系统拦截,保障驱动可用性消除安装警告未认证的驱动在安装时会触发Windows的红色安全警告(如“无法验证发布者”),甚至被系统强制拦截。通过WHQL认证的驱动获得微软数字签名,用户可无阻安装。满足系统强制要求Windows1
- JSON 与 AJAX
Auscy
jsonajax前端
一、JSON(JavaScriptObjectNotation)1.数据类型与语法细节支持的数据类型:基本类型:字符串(需用双引号)、数字、布尔值(true/false)、null。复杂类型:数组([])、对象({})。严格语法规范:键名必须用双引号包裹(如"name":"张三")。数组元素用逗号分隔,最后一个元素后不能有多余逗号。数字不能以0开头(如012会被解析为12),不支持八进制/十六进制
- C++ 11 Lambda表达式和min_element()与max_element()的使用_c++ lamda函数 min_element(
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。需要这份系统化的资料的朋友,可以添加戳这里获取一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!intmain(){vectormyvec{3,
- 基于定制开发开源AI智能名片S2B2C商城小程序的社群游戏定制策略研究
说私域
人工智能小程序游戏
摘要:本文聚焦社群游戏定制领域,深入探讨以社群文化和用户偏好为导向的定制策略。通过分析互动游戏活动、社群文化塑造等关键要素,结合定制开发开源AI智能名片S2B2C商城小程序的技术特性,提出针对性游戏定制方案。研究旨在提升社群用户参与度与游戏体验,为社群游戏发展提供理论支持与实践指导。关键词:社群游戏定制;定制开发开源AI智能名片S2B2C商城小程序;社群文化;用户偏好一、引言在数字化社交蓬勃发展的
- 算法学习笔记:17.蒙特卡洛算法 ——从原理到实战,涵盖 LeetCode 与考研 408 例题
在计算机科学和数学领域,蒙特卡洛算法(MonteCarloAlgorithm)以其独特的随机抽样思想,成为解决复杂问题的有力工具。从圆周率的计算到金融风险评估,从物理模拟到人工智能,蒙特卡洛算法都发挥着不可替代的作用。本文将深入剖析蒙特卡洛算法的思想、解题思路,结合实际应用场景与Java代码实现,并融入考研408的相关考点,穿插图片辅助理解,帮助你全面掌握这一重要算法。蒙特卡洛算法的基本概念蒙特卡
- LeetCode算法题:电话号码的字母组合
吱屋猪_
算法leetcodejava
题目描述:给定一个仅包含数字2-9的字符串,返回所有它能表示的字母组合。答案可以按任意顺序返回。给出数字到字母的映射如下(与电话按键相同)。注意1不对应任何字母。2->"abc"3->"def"4->"ghi"5->"jkl"6->"mno"7->"pqrs"8->"tuv"9->"wxyz"例如,给定digits="23",返回["ad","ae","af","bd","be","bf","cd
- 基于开源AI智能名片链动2+1模式与S2B2C商城小程序的渠道选择策略研究
说私域
人工智能小程序
摘要:在数字化商业环境下,品牌与产品的渠道选择对其市场推广和运营成功至关重要。本文聚焦于如何依据自身品牌和产品特性,结合开源AI智能名片链动2+1模式与S2B2C商城小程序,运用科学的渠道选择方法,慎重挑选1-2个适宜平台,集中资源发力并取得成绩后再拓展其他渠道。通过理论分析与案例研究,探讨该策略的有效性和可行性,为企业渠道布局提供参考。关键词:渠道选择;开源AI智能名片;链动2+1模式;S2B2
- 小林渗透入门:burpsuite+proxifier抓取小程序流量
ξ流ぁ星ぷ132
小程序web安全安全性测试网络安全安全
目录前提:代理:proxifier:步骤:bp证书安装bp设置代理端口:proxifier设置规则:proxifier应用规则:结果:前提:在介绍这两个工具具体实现方法之前,有个很重要的技术必须要大概了解才行---代理。代理:个人觉得代理,简而言之,就是在你和服务器中间的一个中间人,来转达信息。那为什么要代理呢,因为这里的burpsuite要抓包,burpsuite只有做为中间代理人才可以进行拦截
- 零信任落地难题:安全性与用户体验如何两全?
粤海科技君
安全零信任终端安全网络安全iOA
在零信任架构的实施过程中,平衡安全性与用户体验是企业数字化转型的核心命题。这一挑战的本质在于:既要通过「永不信任,持续验证」的安全机制抵御新型攻击,又要避免过度验证导致的效率损耗。一、矛盾根源:安全与体验的天然张力零信任的“永不信任”原则,本质上要求对每一次访问都进行动态评估,但这与用户对“便捷、流畅”的诉求存在天然冲突。例如:频繁的身份验证(如每次登录都需短信验证码)会打断工作节奏,某制造企业统
- 数字孪生技术为UI前端注入新活力:实现产品设计的沉浸式体验
ui设计前端开发老司机
ui
hello宝子们...我们是艾斯视觉擅长ui设计、前端开发、数字孪生、大数据、三维建模、三维动画10年+经验!希望我的分享能帮助到您!如需帮助可以评论关注私信我们一起探讨!致敬感谢感恩!一、引言:从“平面交互”到“沉浸体验”的UI革命当用户在电商APP中翻看3D家具模型却无法感知其与自家客厅的匹配度,当设计师在2D屏幕上绘制汽车内饰却难以预判实际乘坐体验——传统UI设计的“平面化、静态化、割裂感”
- NGS测序基础梳理01-文库构建(Library Preparation)
qq_21478261
#生物信息生物学
本文介绍Illumina测序平台文库构建(LibraryPreparation)步骤,文库结构。写作时间:2020.05。推荐阅读:10W字《Python可视化教程1.0》来了!一份由公众号「pythonic生物人」精心制作的PythonMatplotlib可视化系统教程,105页PDFhttps://mp.weixin.qq.com/s/QaSmucuVsS_DR-klfpE3-Q10W字《Rg
- AI音乐模拟器:AIGC时代的智能音乐创作革命
lauo
人工智能AIGC开源前端机器人
AI音乐模拟器:AIGC时代的智能音乐创作革命引言:AIGC浪潮下的音乐创作新范式在数字化转型的浪潮中,人工智能生成内容(AIGC)正在重塑各个创意领域。音乐产业作为创意经济的重要组成部分,正经历着前所未有的变革。据最新市场研究数据显示,全球AI音乐市场规模预计将从2023年的5.8亿美元增长到2030年的26.8亿美元,年复合增长率高达24.3%。这一快速增长的市场背后,是AI音乐技术正在打破传
- Topview Avatar 2深度实测:AI数字人带货的新高度,还是又一个营销噱头?
神码小Z
AI工具人工智能
在AI数字人赛道越来越卷的今天,各家产品都在宣传自己的"独门秘技"。最近,TopviewAI推出的Avatar2引起了我的注意——号称突破了产品尺寸限制,实现了"万物皆可带"。作为一个经常需要制作营销视频的内容创作者,我决定亲自上手测试一番,看看这款工具是否真的像宣传的那样强大。TopviewAvatar2是什么?革命性升级还是渐进式改良?TopviewAvatar2是TopviewAI推出的第二
- .NET中的强名称和签名机制
.NET中的强名称(StrongName)和签名机制是.NETFramework引入的一种安全性和版本控制机制。以下是关于.NET中强名称和签名机制的详细解释:强名称定义:强名称是由程序集的标识加上公钥和数字签名组成的。程序集的标识包括简单文本名称、版本号和区域性信息(如果提供的话)。作用:强名称主要用于确保程序集的唯一性和完整性。通过签发具有强名称的程序集,可以确保名称的全局唯一性,防止名称冲突
- Python 爬虫实战:视频平台播放量实时监控(含反爬对抗与数据趋势预测)
西攻城狮北
python爬虫音视频
一、引言在数字内容蓬勃发展的当下,视频平台的播放量数据已成为内容创作者、营销人员以及行业分析师手中极为关键的情报资源。它不仅能够实时反映内容的受欢迎程度,更能在竞争分析、营销策略制定以及内容优化等方面发挥不可估量的作用。然而,视频平台为了保护自身数据和用户隐私,往往会设置一系列反爬虫机制,对数据爬取行为进行限制。这就向我们发起了挑战:如何巧妙地突破这些限制,同时精准地捕捉并预测播放量的动态变化趋势
- .NET中的安全性之数字签名、数字证书、强签名程序集、反编译
hezudao25
NET.netassembly加密算法referenceheader
本文将探讨数字签名、数字证书、强签名程序集、反编译等以及它们在.NET中的运用(一些概念并不局限于.NET在其它技术、平台中也存在)。1.数字签名数字签名又称为公钥数字签名,或者电子签章等,它借助公钥加密技术实现。数字签名技术主要涉及公钥、私钥、非对称加密算法。1.1公钥与私钥公钥是公开的钥匙,私钥则是与公钥匹配的严格保护的私有密钥;私钥加密的信息只有公钥可以解开,反之亦然。在VisualStud
- GoView 强势入驻 GitCode:拖拽低代码,打造高颜值数据大屏
GitCode 代码君
gitcode低代码开源
信息可视化时代,数字大屏日益成为展示核心KPI、运营状态、监控预警的主流形式。然而,用传统方式开发一个定制化数字大屏需要解决多少问题?1.繁复的数据源集成,各种不同的协议和格式……2.让人晕头转向的可视化逻辑,调动艰难的样式、布局、动画,和往往难以统一的风格3.牵一发而动全身的代码结构,就想换个主题色结果开启的全局CSS大冒险……现在,一个开源项目即可搞定上述问题——拖拽式低代码数字可视化平台Go
- 如何对.NET应用程序进行数字签名
溪源More
服务器linux网络运维
我们可以为我们的程序进行数字签名,这样就可以证明该程序的作者是可信的.首先为了签名程序,我们需要先创建一个证书.证书是由证书颁发机构(CA)颁发的,CA是受信任的第三方机构,它可以为我们颁发证书.当然我们也可以自己创建证书.接下来简单介绍下如何利用OpenSSL工具创建证书.创建证书下载openssl安装包并安装,推荐下载最新64位版本.打开命令行,输入openssl,如果提示Openssl不是内
- 程序员必看!如何破解数据篡改与逆向工程的双重困境
深盾科技
程序员创富c#
作为一名程序员,你是否曾遇到过这样的噩梦?辛苦开发的程序,数据被篡改,代码被轻易破解,所有的努力瞬间化为泡影!别怕,今天就来教你如何绝地反击,让黑客们望而却步!数据篡改:黑客的“拿手好戏”在程序开发中,数据安全性是重中之重。然而,黑客们却总能找到漏洞,篡改传输中的数据,导致程序运行出错,甚至引发严重的安全问题。那么,如何才能防止数据被篡改呢?数字签名:数据安全的“守护神”数字签名是一种基于密码学的
- JVM与Spring Boot核心解析
AIHacksCash
Java场景面试宝典JavaJVMSpringBoot
我是廖志伟,一名Java开发工程师、《Java项目实战——深入理解大型互联网企业通用技术》(基础篇)、(进阶篇)、(架构篇)清华大学出版社签约作家、Java领域优质创作者、CSDN博客专家、阿里云专家博主、51CTO专家博主、产品软文专业写手、技术文章评审老师、技术类问卷调查设计师、幕后大佬社区创始人、开源项目贡献者。拥有多年一线研发和团队管理经验,研究过主流框架的底层源码(Spring、Spri
- .NET 程序的强名称签名与安全防护技术干货
深盾科技
安全
在.NET开发领域,保障程序的安全性和完整性至关重要。强名称签名和有效的安全防护措施是实现这一目标的关键手段。下面将详细介绍.NET程序的强名称签名以及相关的安全防护方法。一、什么是强名称签名强名称签名是.NET框架提供的一种安全机制,其主要作用是唯一标识程序集、验证程序集的完整性以及解决版本冲突问题。它本质上是通过加密技术为程序集创建数字签名,确保程序集在分发和运行过程中的安全性。二、签名文件要
- iOS 多个线程对数组操作(遍历,插入,删除),实现一个线程安全的NSMutabeArray
//联系人:石虎QQ:1224614774昵称:嗡嘛呢叭咪哄一、概念1.含义:@synchronized(self){}//这个其实就是一个加锁。如果self其他线程访问,则会阻塞。这样做一般是用来对单2.重写构造方法@interfaceSHSafetyArray:NSObject{@privateNSMutableArray*_mutableArray;//声明数组}//遍历加锁-(void)m
- 视频分析:让AI看懂动态画面
随机森林404
计算机视觉音视频人工智能microsoft
引言:动态视觉理解的革命在数字信息爆炸的时代,视频已成为最主要的媒介形式。据统计,每分钟有超过500小时的视频内容被上传到YouTube平台,而全球互联网流量的82%来自视频数据传输。面对如此海量的视频内容,传统的人工处理方式已无法满足需求,这正是人工智能视频分析技术大显身手的舞台。视频分析技术赋予机器"看懂"动态画面的能力,使其能够自动理解、解释甚至预测视频中的内容,这一突破正在彻底改变我们与视
- 基于Python的智能公示信息监控爬虫系统开发实战
Python爬虫项目
2025年爬虫实战项目python爬虫开发语言音视频搜索引擎scrapy
摘要本文详细介绍了如何使用Python构建一个高效的公示信息监控爬虫系统。系统采用最新技术栈,包括异步爬取、智能解析、反反爬策略等,能够自动监控各类政府网站、企业公示平台的更新信息。文章从系统设计到具体实现,提供了完整的代码示例和详细的技术解析,帮助读者掌握大规模公示信息采集的核心技术。关键词:Python爬虫、公示监控、信息采集、异步爬取、智能解析1.引言在数字化时代,各类公示信息(如政府采购、
- Tomcat:Java Web应用的幕后英雄
互联网动态分析
tomcat
在当今数字化浪潮中,Java作为一门成熟且广泛应用的编程语言,支撑着无数企业级应用和互联网服务的稳定运行。而在JavaWeb开发领域,Tomcat无疑是一个举足轻重的存在,它宛如一位默默耕耘的幕后英雄,为众多Web应用提供了可靠的运行环境。Tomcat的起源与发展Tomcat的故事始于1999年,当时SunMicrosystems(后被Oracle收购)与Apache软件基金会合作,旨在为Java
- 线性代数同济教材每一部分的现实意义
ZhuBin365
其它算法
一、行列式(Determinants)的现实意义:不仅仅是数字,而是“尺度”和“特性”行列式虽然计算结果是一个数值,但它绝不是一个孤立的数字,它在现实世界中代表着“尺度”和“特性”的重要信息:现实意义核心:“衡量变化的能力”和“判定系统特性”“尺度”:衡量体积/面积的缩放比例:在现实世界中,很多变换都会改变物体的形状和大小。行列式就像一个“尺度”,衡量了线性变换对面积(二维)或体积(三维及以上)的
- STM32-DAC数模转换
DAC数模转换:将数字信号转换成模拟信号特性:2个DAC转换器每个都拥有一个转换通道8位或12位单调输出(8位右对齐;12位左对齐右对齐)双ADC通道同时或者分别转换外部触发中断电压源控制部分(外部触发3个APB1;不使用1个APB1)外部触发输出:DAC1-PA4;DAC2-PA5软件设计流程:使能端口以及DAC时钟;设置引脚为模拟输入RCC_APB2PeriphClockCmd(RCC_APB
- 【Android】安卓四大组件之内容提供者(ContentProvider):从基础到进阶
m0_59734531
AndroidandroidJavaContentProvider安卓四大组件
你手机里的通讯录,存储了所有联系人的信息。如果你想把这些联系人信息分享给其他App,就可以通过ContentProvider来实现。。一、什么是ContentProviderContentProvider是Android四大组件之一,负责实现跨应用程序的数据共享与访问,通过统一接口封装数据存储细节,提供标准化操作方式。其中主要功能包括:数据抽象层:将应用内部的数据(如SQLite数据库、文
- 法律科技领域人工智能代理构建的十个经验教训,一位人工智能工程师通过构建、部署和维护智能代理的经验教训来优化法律工作流程的历程。
知识大胖
NVIDIAGPU和大语言模型开发教程人工智能ai
目录介绍什么是代理人?为什么它对法律如此重要?法律技术中代理用例示例-合同审查代理-法律研究代理在LegalTech中使用代理的十个教训-教训1:即使代理很酷,它们也不能解决所有问题-教训2:选择最适合您用例的框架-教训3:能够快速迭代不同的模型-教训4:从简单开始,必要时扩展-教训5:使用跟踪解决方案;您将需要它-教训6:确保跟踪成本,代理循环可能很昂贵-教训7:将控制权交给最终用户(人在环路中
- 安装数据库首次应用
Array_06
javaoraclesql
可是为什么再一次失败之后就变成直接跳过那个要求
enter full pathname of java.exe的界面
这个java.exe是你的Oracle 11g安装目录中例如:【F:\app\chen\product\11.2.0\dbhome_1\jdk\jre\bin】下的java.exe 。不是你的电脑安装的java jdk下的java.exe!
注意第一次,使用SQL D
- Weblogic Server Console密码修改和遗忘解决方法
bijian1013
Welogic
在工作中一同事将Weblogic的console的密码忘记了,通过网上查询资料解决,实践整理了一下。
一.修改Console密码
打开weblogic控制台,安全领域 --> myrealm -->&n
- IllegalStateException: Cannot forward a response that is already committed
Cwind
javaServlets
对于初学者来说,一个常见的误解是:当调用 forward() 或者 sendRedirect() 时控制流将会自动跳出原函数。标题所示错误通常是基于此误解而引起的。 示例代码:
protected void doPost() {
if (someCondition) {
sendRedirect();
}
forward(); // Thi
- 基于流的装饰设计模式
木zi_鸣
设计模式
当想要对已有类的对象进行功能增强时,可以定义一个类,将已有对象传入,基于已有的功能,并提供加强功能。
自定义的类成为装饰类
模仿BufferedReader,对Reader进行包装,体现装饰设计模式
装饰类通常会通过构造方法接受被装饰的对象,并基于被装饰的对象功能,提供更强的功能。
装饰模式比继承灵活,避免继承臃肿,降低了类与类之间的关系
装饰类因为增强已有对象,具备的功能该
- Linux中的uniq命令
被触发
linux
Linux命令uniq的作用是过滤重复部分显示文件内容,这个命令读取输入文件,并比较相邻的行。在正常情 况下,第二个及以后更多个重复行将被删去,行比较是根据所用字符集的排序序列进行的。该命令加工后的结果写到输出文件中。输入文件和输出文件必须不同。如 果输入文件用“- ”表示,则从标准输入读取。
AD:
uniq [选项] 文件
说明:这个命令读取输入文件,并比较相邻的行。在正常情况下,第二个
- 正则表达式Pattern
肆无忌惮_
Pattern
正则表达式是符合一定规则的表达式,用来专门操作字符串,对字符创进行匹配,切割,替换,获取。
例如,我们需要对QQ号码格式进行检验
规则是长度6~12位 不能0开头 只能是数字,我们可以一位一位进行比较,利用parseLong进行判断,或者是用正则表达式来匹配[1-9][0-9]{4,14} 或者 [1-9]\d{4,14}
&nbs
- Oracle高级查询之OVER (PARTITION BY ..)
知了ing
oraclesql
一、rank()/dense_rank() over(partition by ...order by ...)
现在客户有这样一个需求,查询每个部门工资最高的雇员的信息,相信有一定oracle应用知识的同学都能写出下面的SQL语句:
select e.ename, e.job, e.sal, e.deptno
from scott.emp e,
(se
- Python调试
矮蛋蛋
pythonpdb
原文地址:
http://blog.csdn.net/xuyuefei1988/article/details/19399137
1、下面网上收罗的资料初学者应该够用了,但对比IBM的Python 代码调试技巧:
IBM:包括 pdb 模块、利用 PyDev 和 Eclipse 集成进行调试、PyCharm 以及 Debug 日志进行调试:
http://www.ibm.com/d
- webservice传递自定义对象时函数为空,以及boolean不对应的问题
alleni123
webservice
今天在客户端调用方法
NodeStatus status=iservice.getNodeStatus().
结果NodeStatus的属性都是null。
进行debug之后,发现服务器端返回的确实是有值的对象。
后来发现原来是因为在客户端,NodeStatus的setter全部被我删除了。
本来是因为逻辑上不需要在客户端使用setter, 结果改了之后竟然不能获取带属性值的
- java如何干掉指针,又如何巧妙的通过引用来操作指针————>说的就是java指针
百合不是茶
C语言的强大在于可以直接操作指针的地址,通过改变指针的地址指向来达到更改地址的目的,又是由于c语言的指针过于强大,初学者很难掌握, java的出现解决了c,c++中指针的问题 java将指针封装在底层,开发人员是不能够去操作指针的地址,但是可以通过引用来间接的操作:
定义一个指针p来指向a的地址(&是地址符号):
- Eclipse打不开,提示“An error has occurred.See the log file ***/.log”
bijian1013
eclipse
打开eclipse工作目录的\.metadata\.log文件,发现如下错误:
!ENTRY org.eclipse.osgi 4 0 2012-09-10 09:28:57.139
!MESSAGE Application error
!STACK 1
java.lang.NoClassDefFoundError: org/eclipse/core/resources/IContai
- spring aop实例annotation方法实现
bijian1013
javaspringAOPannotation
在spring aop实例中我们通过配置xml文件来实现AOP,这里学习使用annotation来实现,使用annotation其实就是指明具体的aspect,pointcut和advice。1.申明一个切面(用一个类来实现)在这个切面里,包括了advice和pointcut
AdviceMethods.jav
- [Velocity一]Velocity语法基础入门
bit1129
velocity
用户和开发人员参考文档
http://velocity.apache.org/engine/releases/velocity-1.7/developer-guide.html
注释
1.行级注释##
2.多行注释#* *#
变量定义
使用$开头的字符串是变量定义,例如$var1, $var2,
赋值
使用#set为变量赋值,例
- 【Kafka十一】关于Kafka的副本管理
bit1129
kafka
1. 关于request.required.acks
request.required.acks控制者Producer写请求的什么时候可以确认写成功,默认是0,
0表示即不进行确认即返回。
1表示Leader写成功即返回,此时还没有进行写数据同步到其它Follower Partition中
-1表示根据指定的最少Partition确认后才返回,这个在
Th
- lua统计nginx内部变量数据
ronin47
lua nginx 统计
server {
listen 80;
server_name photo.domain.com;
location /{set $str $uri;
content_by_lua '
local url = ngx.var.uri
local res = ngx.location.capture(
- java-11.二叉树中节点的最大距离
bylijinnan
java
import java.util.ArrayList;
import java.util.List;
public class MaxLenInBinTree {
/*
a. 1
/ \
2 3
/ \ / \
4 5 6 7
max=4 pass "root"
- Netty源码学习-ReadTimeoutHandler
bylijinnan
javanetty
ReadTimeoutHandler的实现思路:
开启一个定时任务,如果在指定时间内没有接收到消息,则抛出ReadTimeoutException
这个异常的捕获,在开发中,交给跟在ReadTimeoutHandler后面的ChannelHandler,例如
private final ChannelHandler timeoutHandler =
new ReadTim
- jquery验证上传文件样式及大小(好用)
cngolon
文件上传jquery验证
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script src="jquery1.8/jquery-1.8.0.
- 浏览器兼容【转】
cuishikuan
css浏览器IE
浏览器兼容问题一:不同浏览器的标签默认的外补丁和内补丁不同
问题症状:随便写几个标签,不加样式控制的情况下,各自的margin 和padding差异较大。
碰到频率:100%
解决方案:CSS里 *{margin:0;padding:0;}
备注:这个是最常见的也是最易解决的一个浏览器兼容性问题,几乎所有的CSS文件开头都会用通配符*来设
- Shell特殊变量:Shell $0, $#, $*, $@, $?, $$和命令行参数
daizj
shell$#$?特殊变量
前面已经讲到,变量名只能包含数字、字母和下划线,因为某些包含其他字符的变量有特殊含义,这样的变量被称为特殊变量。例如,$ 表示当前Shell进程的ID,即pid,看下面的代码:
$echo $$
运行结果
29949
特殊变量列表 变量 含义 $0 当前脚本的文件名 $n 传递给脚本或函数的参数。n 是一个数字,表示第几个参数。例如,第一个
- 程序设计KISS 原则-------KEEP IT SIMPLE, STUPID!
dcj3sjt126com
unix
翻到一本书,讲到编程一般原则是kiss:Keep It Simple, Stupid.对这个原则深有体会,其实不仅编程如此,而且系统架构也是如此。
KEEP IT SIMPLE, STUPID! 编写只做一件事情,并且要做好的程序;编写可以在一起工作的程序,编写处理文本流的程序,因为这是通用的接口。这就是UNIX哲学.所有的哲学真 正的浓缩为一个铁一样的定律,高明的工程师的神圣的“KISS 原
- android Activity间List传值
dcj3sjt126com
Activity
第一个Activity:
import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;import android.app.Activity;import android.content.Intent;import android.os.Bundle;import a
- tomcat 设置java虚拟机内存
eksliang
tomcat 内存设置
转载请出自出处:http://eksliang.iteye.com/blog/2117772
http://eksliang.iteye.com/
常见的内存溢出有以下两种:
java.lang.OutOfMemoryError: PermGen space
java.lang.OutOfMemoryError: Java heap space
------------
- Android 数据库事务处理
gqdy365
android
使用SQLiteDatabase的beginTransaction()方法可以开启一个事务,程序执行到endTransaction() 方法时会检查事务的标志是否为成功,如果程序执行到endTransaction()之前调用了setTransactionSuccessful() 方法设置事务的标志为成功则提交事务,如果没有调用setTransactionSuccessful() 方法则回滚事务。事
- Java 打开浏览器
hw1287789687
打开网址open浏览器open browser打开url打开浏览器
使用java 语言如何打开浏览器呢?
我们先研究下在cmd窗口中,如何打开网址
使用IE 打开
D:\software\bin>cmd /c start iexplore http://hw1287789687.iteye.com/blog/2153709
使用火狐打开
D:\software\bin>cmd /c start firefox http://hw1287789
- ReplaceGoogleCDN:将 Google CDN 替换为国内的 Chrome 插件
justjavac
chromeGooglegoogle apichrome插件
Chrome Web Store 安装地址: https://chrome.google.com/webstore/detail/replace-google-cdn/kpampjmfiopfpkkepbllemkibefkiice
由于众所周知的原因,只需替换一个域名就可以继续使用Google提供的前端公共库了。 同样,通过script标记引用这些资源,让网站访问速度瞬间提速吧
- 进程VS.线程
m635674608
线程
资料来源:
http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001397567993007df355a3394da48f0bf14960f0c78753f000 1、Apache最早就是采用多进程模式 2、IIS服务器默认采用多线程模式 3、多进程优缺点 优点:
多进程模式最大
- Linux下安装MemCached
字符串
memcached
前提准备:1. MemCached目前最新版本为:1.4.22,可以从官网下载到。2. MemCached依赖libevent,因此在安装MemCached之前需要先安装libevent。2.1 运行下面命令,查看系统是否已安装libevent。[root@SecurityCheck ~]# rpm -qa|grep libevent libevent-headers-1.4.13-4.el6.n
- java设计模式之--jdk动态代理(实现aop编程)
Supanccy2013
javaDAO设计模式AOP
与静态代理类对照的是动态代理类,动态代理类的字节码在程序运行时由Java反射机制动态生成,无需程序员手工编写它的源代码。动态代理类不仅简化了编程工作,而且提高了软件系统的可扩展性,因为Java 反射机制可以生成任意类型的动态代理类。java.lang.reflect 包中的Proxy类和InvocationHandler 接口提供了生成动态代理类的能力。
&
- Spring 4.2新特性-对java8默认方法(default method)定义Bean的支持
wiselyman
spring 4
2.1 默认方法(default method)
java8引入了一个default medthod;
用来扩展已有的接口,在对已有接口的使用不产生任何影响的情况下,添加扩展
使用default关键字
Spring 4.2支持加载在默认方法里声明的bean
2.2
将要被声明成bean的类
public class DemoService {

 next一直往下直到完成(需要一点时间)
next一直往下直到完成(需要一点时间)




 去掉https后面s
去掉https后面s