【JavaEE】文件操作——IO手术刀剖析
文章目录
- 一、文件
-
- 1.认识文件
- 2.文件的分类
- 3.树型结构组织目录
- 4.文件路径
- 二、Java 中操作文件
-
- 1.文件系统的操作
- 2.文件内容的操作
-
- 2.1.InputStream
- 2.2.利用 Scanner 进行字符读取
- 2.3.OutputStream
- 三、案例分析
-
- 1.案例一:查找文件并删除
- 2.案例二:普通文件的复制
- 3.案例三:扫描指定目录
- 四、最后
一、文件
1.认识文件
我们平时所说的文件一般都是存储在硬盘上的普通文件,比方说以.txt、.jpg、.mp4、.rar等等结尾结尾的文件都可以认为是普通文件,它们都是在硬盘上存储的。

实际上,在计算机中,文件可能更多的是一个广义的概念,不仅仅包括普通文件,还可以包含目录(把目录称为目录文件),这里的目录我们一般称为文件夹。

在我们的操作系统中,还会使用文件来描述一些其他的硬件设备或者软件资源。比如说网卡,操作系统中就把网卡这样的硬件设备给抽象成一个文件,这样就给我们进行网络编程带来了很大便利,我们要通过网卡来接受数据,直接就按照读文件的代码一写就可以了;想通过网卡来发送数据,通过写文件代码一写就可以了。这样的好处就是简化了开发。此外,还比如我们的显示器,键盘,操作系统中也会把这些硬件设备视为文件。因此,我们在这里谈到的文件是一个更加广义的概念。
那么接下来,本篇文章谈到的文件主要是针对普通文件来讨论的。
普通文件是保存在硬盘上的,我们从存储数据的介质上来区分,硬盘可分为机械硬盘(Hard Disk Drive, HDD)和固态硬盘(Solid State Disk, SSD),机械硬盘采用磁性碟片来存储数据,而固态硬盘通过闪存颗粒来存储数据。
图片来源于网络:

机械硬盘是如何工作的呢?
机械硬盘一旦通电,那么里面的盘片就会告诉运转(常见转速是 7200 r/min)。磁头就在盘片上找到对应的数据。所以机械硬盘在读取或写入数据时,非常害怕晃动和磕碰。另外,因为机械硬盘的超高转速,如果内部有灰尘,则会造成磁头或盘片的损坏,所以机械硬盘内部是封闭的,如果不是在无尘环境下,则禁止拆开机械硬盘。
受限于机械 硬盘的硬件结构,盘片转速越高,读写就越快,但是由于工艺的限制,盘片的转速也不能无限高。当前机械硬盘的读写速度已经有10年停滞不前了,如今的机械硬盘往往往大容量方向发展。这里的读写速度就内存的读写速度慢3-4个数量级。
为了解决这个读写速度的问题,我们后面又有了固态硬盘,简称为SSD,固态硬盘的的硬件结构与机械硬盘截然不同。
(图片来自网络)

固态硬盘和机械硬盘对比主要有以下一些特点,如下图所示。
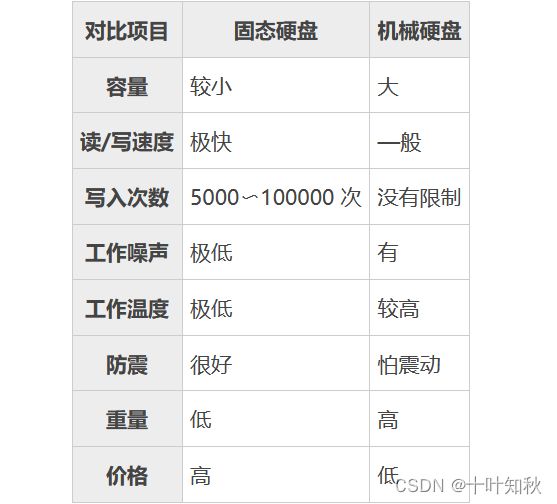
这篇文章讨论的硬盘也是以机械硬盘为主,因为在企业中使用的服务器还是以机械硬盘为主。
2.文件的分类
从编程的角度来看,我们主要把文件分成两类:
- 文本文件
- 二进制文件
文本文件里面存放的是字符,但是本质上也是存放的是字节,但是文本文件中,相邻的字节在一起正好能构成一个个字符,它们之间是相关联的。
二进制文件中,存储的是字节这里与文本文件不一样的是字节与字节之间没有什么必然联系。
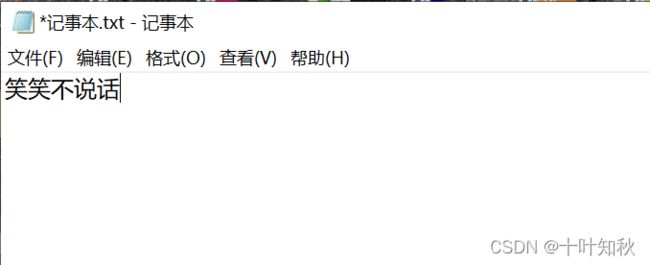
那么,我们该如何去判定一个文件是文本文件还是二进制文件呢?简单粗暴的方法是通过记事本打开,如果打开之后是乱码的就是二进制,如果不是则是文本文件。
像下面用记事本打开之后是正常的,则是文本文件。
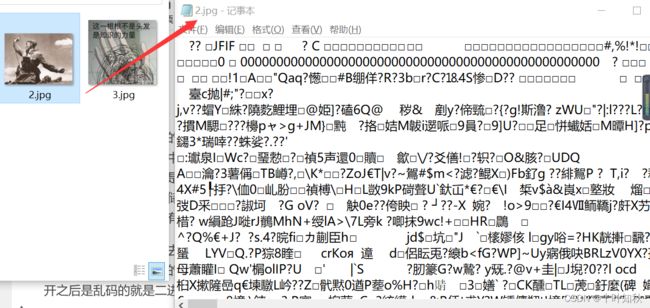
 假如我们用记事本打开一张图片,可以看到的是一堆乱码,这个就是二进制文件。
假如我们用记事本打开一张图片,可以看到的是一堆乱码,这个就是二进制文件。
&emdp; 类似的,在我们日常使用的.txt、.c、.java 等都属于文本文件;而.doc、.ppt、.exe、.zip、.class等都属于二进制文件。
3.树型结构组织目录
在计算机中,保存和管理文件是通过操作系统中的“系统文件”这样的模块来负责的。在文件系统中,一般通过“树形”结构来组织磁盘上的目录与文件。这里的“树形”不是二叉树型,而是分叉树。
(下图来源于网络)
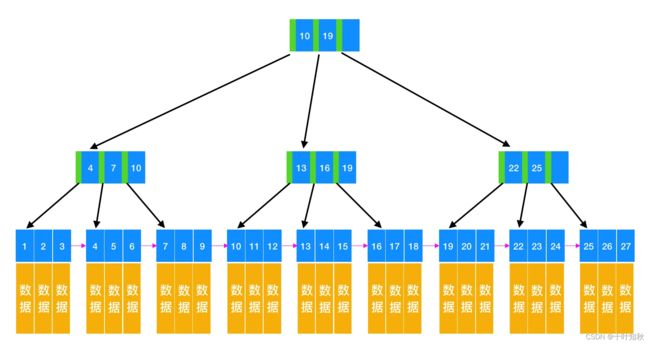
整体的文件系统,大概就像上图中的树形结构。如果是一个普通文件,就是树的叶子结点;如果是一个目录文件,目录中就可以包含子树,这个目录就是非叶子节点;这棵树每个节点的子树都可以有N个,这就是一个N叉树。
对应的,在操作系统中,就通过“路径”这样的概念来描述一个具体文件/目录的位置。
4.文件路径
路径的两种描述,一是绝对路径,二是相对路径。
- 绝对路径:以盘符开头(盘符:C盘、D盘…),比如说:‘C:\Program Files\Java\jdk1.8.0_192\bin\jabswitch.exe’。
- 相对路径:以 . 或者 . . 开头的。其中 . 表示当前路径, . . 表示路径的父目录(上级路径)。
相对路径必须得要有一个基准目录,然后相对路径就从这个基准目录出发,按照对应的路径找到对应的文件。比如说我们以’C:\Program Files\Java\jdk1.8.0_192\bin’为基准目录,需要找到jabswitch.exe。那么就 './jabswitch.exe’就可以了。此处的 . 就表示当前目录(基准目录)。
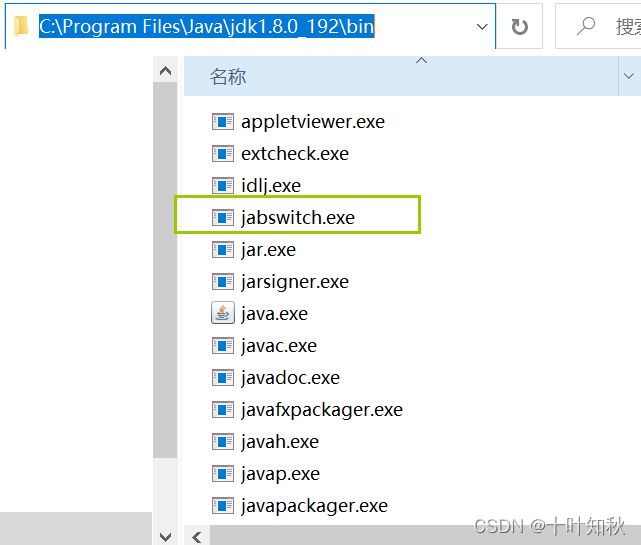
比如还是以’C:\Program Files\Java\jdk1.8.0_192\bin’为基准,需要找到src.zip文件,而这个文件位于’C:\Program Files\Java\jdk1.8.0_192\bin’的上一层目录。而 . . 就表示此时的基准目录的上一层,那么我们就可以通过以下方式找到src.zip文件,‘. ./src.zip’,此时表示先去基准目录的上一层目录’C:\Program Files\Java\jdk1.8.0_192’,然后再从’C:\Program Files\Java\jdk1.8.0_192’这个路径寻找到 src.zip 文件。
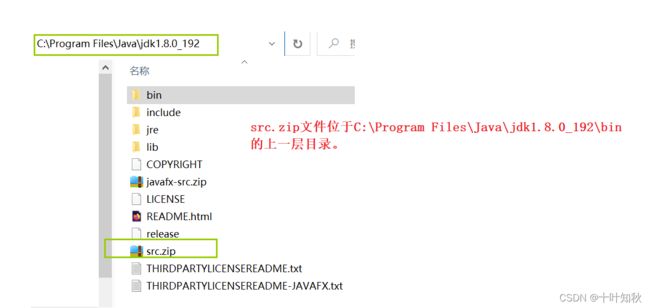
这里需要注意的是,如果基准目录不同,那么定位到同一目录的相对路径也就不一样了。例如
- 以’C:\Program Files\Java\jdk1.8.0_192’路径为基准,去找javac.exe,相对路径就是:‘./bin/java.exe’。
- 以’C:\Program Files\Java’路径为基准,去找Javac.exe,相对路径则为:‘./jdk1.8.0_192/bin/javac.exe’。
总结:
(1)相对路径就是以当前文件为基准进行一级级目录指向被引用的资源文件。
../ 表示当前文件所在的目录的上一级目录
./ 表示当前文件所在的目录(可以省略)
/ 表示当前站点的根目录(域名映射的硬盘目录)
(2)绝对路径是指文件在硬盘上真正存在的路径。
例如:'C:\Program Files\Java\jdk1.8.0_192\bin\jabswitch.exe'
二、Java 中操作文件
Java中的操作文件,主要包含两类操作:
- 文件系统的操作
- 文件内容的操作
1.文件系统的操作
文件相关的操作:通过“文件资源管理器”能够完成的一些功能:
- 列出目录中有哪些文件
- 创建文件
- 删除文件
- 创建目录
- 重命名文件
- …
文件资源管理器是啥?下图这个东西就是一个文件资源管理器。
那么具体我们是如何操作的呢?在Java中提供了一个File类,这个File类描述了一个文件/目录,通过这个对象就可以完成上述操作。File类的构造方法,能够传入一个路径,来指定一个文件,这个路径可以是绝对路径,也可以是相对路径。构造好对象之后,就可以通过下面的方法来完成一些具体的操作。
通过代码演示:
(1)通过绝对路径进行定位
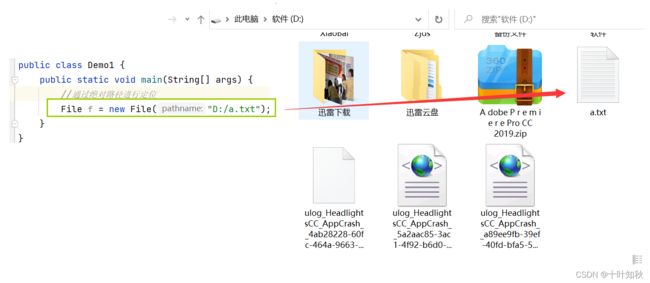
(2)通过相对路径进行定位。

我们上面说过,谈到相对路径,我们需要先明确一个“基准路径”。那么对于上面图片的代码中,我们的“基准路径”是啥?实际上,从代码中是看不出来的,这个“基准路径”是由运行这个的Java程序来确定,不同的运行Java程序的方式,基准路径就不一样。一般来说我们会有以下情况:
(1)如果是通过命令行的方式,例如’java.Demo1’ ,这种方式来进行,此时执行命令所在的路径就是基准路径。
比如我们打开一个cmd,打一个java,基准路径就是‘C:\Users\Administrator.DESKTOP-6LVQU9V>’。具体通过哪个目录去运行这个路径,基准路径就是哪个目录。
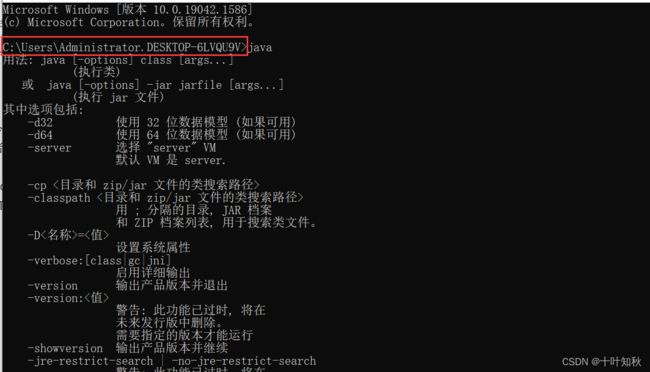
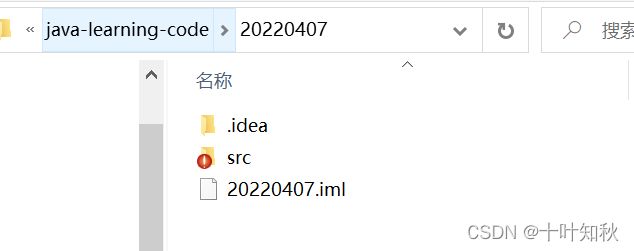
(2)如果通过IDEA的方式来运行程序,此时基准路径就是当前java项目所在的路径。比如我们刚刚的Java项目的基准路径就是下图的目录。

(3)把Java代码打包成war包,放到tomcat上运行,这种情况下基准路径就是tomcat的bin目录。
上面的三种情况,我们目前最重要的是搞明白第二点。
下面演示我们File类中的一些方法:
(1)观察 get 系列相对路径与绝对路径使用的特点和差异。
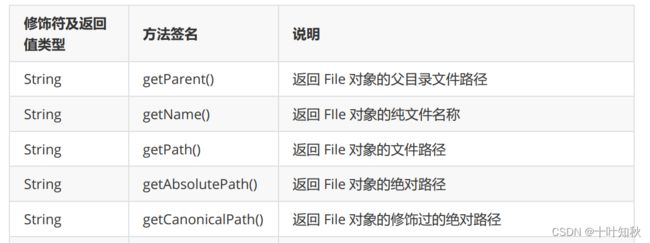
public class Demo1 {
public static void main(String[] args) throws IOException {
//通过绝对路径进行定位
File f = new File("D:/a.txt");
System.out.println(f.getParent());//获取到文件的父目录
System.out.println(f.getName());//获取到文件名
System.out.println(f.getPath());//获取到文件路径,就是构造file的时候指定的路径
System.out.println(f.getAbsoluteFile());//获取到绝对路径
System.out.println(f.getCanonicalPath());//获取到绝对路径
System.out.println("===============");
//通过相对路径定位
File f2 = new File(".a.txt");
System.out.println(f2.getParent());//获取到文件的父目录
System.out.println(f2.getName());//获取到文件名
System.out.println(f2.getPath());//获取到文件路径,就是构造file的时候指定的路径
System.out.println(f2.getAbsoluteFile());//获取到绝对路径
System.out.println(f2.getCanonicalPath());//获取到绝对路径
}
}
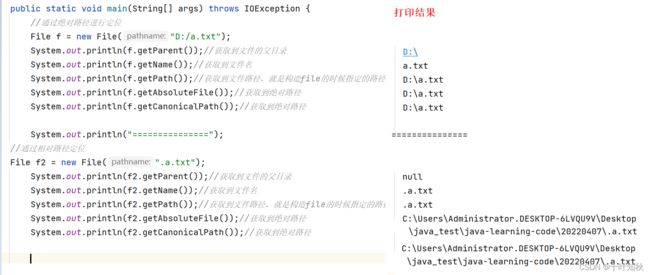
细心的同学会发现上面用的这个\,而我们有时却用这个/。那么" / " 读作“斜杠”, " \ "读作 “反斜杠”。 Windows由于使用斜杠/作为DOS命令提示符的参数标志了,为了不混淆,所以采用反斜杠\作为路径分隔符。所以目前Windows系统上的文件浏览器都是用反斜杠\作为路径分隔符。随着发展,DOS系统已经被淘汰了,命令提示符也用得很少,斜杠和反斜杠在大多数情况下可以互换,没有影响。
总结:
-
统一用正斜杠"/",Windows和Linux都能识别。
-
网络路径(浏览器地址栏网址)使用 正斜杠/;
-
Windows文件浏览器上使用 反斜杠\;
-
Windows本地路径既能使用正斜杠,也能使用反斜杠。
-
出现在htm url()属性中的路径,指定的路径是网络路径,所以必须使用 正斜杠/;
引用自:彻底理解斜杠和反斜杠的区别,建议去食用,更详细更全。
输入的时候"/" 与 " \ " 系统都能识别,但是windows默认输出的是" \ "。
(2)判断文件的操作
public class Demo2 {
public static void main(String[] args) {
//绝对路径
File f = new File("d:a.txt");
System.out.println(f.exists());//判定是否存在
System.out.println(f.isDirectory());//判定是否是目录
System.out.println(f.isFile());//判定是否是文件
System.out.println("---------------------");
//相对路径
File f2 = new File(".a.txt");
System.out.println(f2.exists());//判定是否存在
System.out.println(f2.isDirectory());//判定是否是目录
System.out.println(f2.isFile());//判定是否是文件
}
}
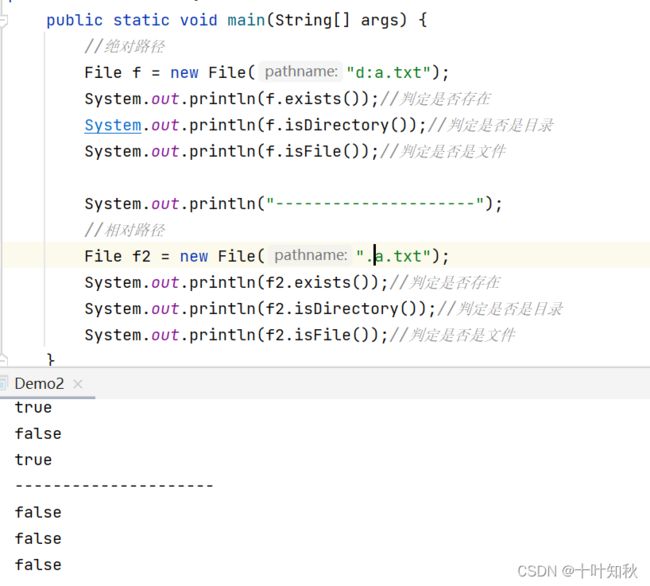
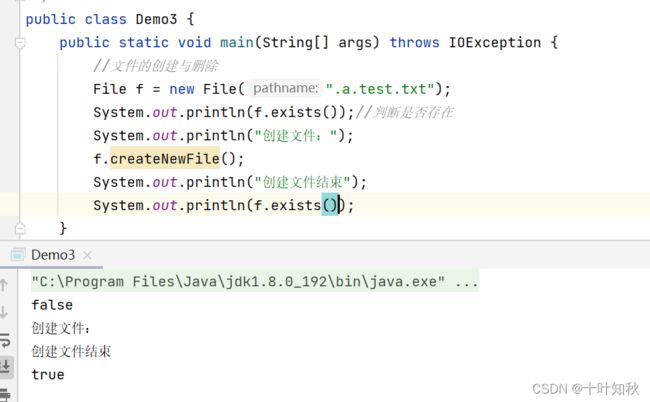
(3)目录创建与删除
public class Demo3 {
public static void main(String[] args) throws IOException {
//文件的创建与删除
File f = new File(".a.test.txt");
System.out.println(f.exists());//判断是否存在
System.out.println("创建文件:");
f.createNewFile();
System.out.println("创建文件结束");
System.out.println(f.exists());
}
}
public class Demo4 {
public static void main(String[] args) {
File f = new File(".test.txt");
f.delete();//删除文件
}
}
(4)mkdir() 的时候,如果中间目录不存在,则无法创建成功; mkdirs() 可以解决这个问题
public class Demo5 {
public static void main(String[] args) {
File f = new File("./aaa");
f.mkdir();//创建对应的目录
System.out.println(f.isDirectory());
}
}
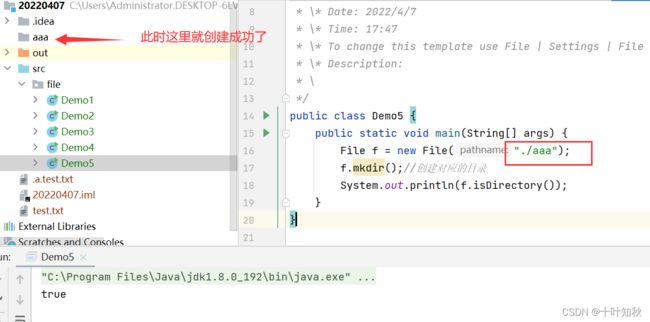
public class Demo5 {
public static void main(String[] args) {
File f = new File("./aaa/bbb/ccc/ddd");
f.mkdirs();//创建多级目录
System.out.println(f.isDirectory());
}
}

(5)返回目录 
public class Demo6 {
public static void main(String[] args) {
File f = new File("./");
System.out.println(Arrays.toString(f.list()));//打印出目录内容的操作
}
}
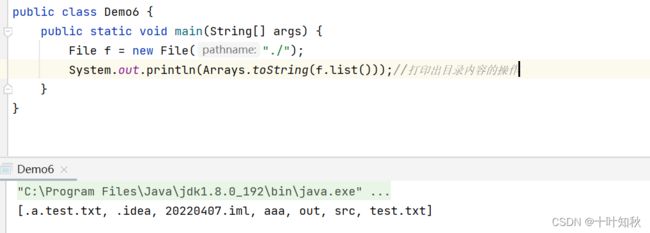
public class Demo6 {
public static void main(String[] args) {
File f = new File("./");
System.out.println(Arrays.toString(f.listFiles()));//打印出目录内容的操作
}
}
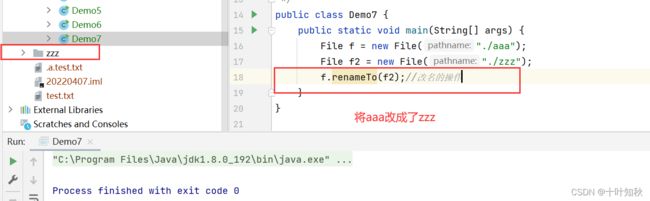
 (6)观察文件重命名
(6)观察文件重命名
public class Demo7 {
public static void main(String[] args) {
File f = new File("./aaa");
File f2 = new File("./zzz");
f.renameTo(f2);//改名的操作
}
}
2.文件内容的操作
文件内容的操作大致可分为以下四点:
- 打开文件
- 读文件
- 写文件
- 关闭文件
上述的操作不是通过一个类来完成的,而是通过一组类来完成的。按照文件操作的内容,分成了两个系列:
- 字节流对象,针对二进制文件,以字节为单位进行读写。针对字节流对象的读操作,我们使用的是InputStream;针对写操作,我们提供的是OutputStream
- 字符流对象:针对文本文件,以字符为单位进行读写.怎对字符流对象的读操作,我们使用的是Reader,写操作使用的是Writer
以上的InputStream,OutputStream,Reader,Writer都是抽象类,我们实际使用的往往是它们的子类,因此不能直接new,而是使用继承。那么它们对应的子类又有FileInputStream , FileOutputStream , FileReader , FileWriter。它们二者的区别如下:

2.1.InputStream
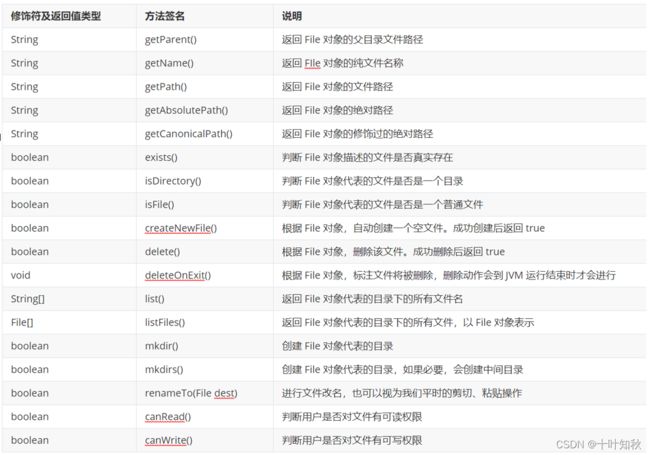
InputStream 的方法:InputStream 只是一个抽象类,要使用还需要具体的实现类。关于 InputStream 的实现类有很多,基本可以认为不同的输入设备都可以对应一个 InputStream 类,我们现在只关心从文件中读取,所以使用 FileInputStream.
| 修饰符及返回值类型 | 方法签名 | 说明 |
|---|---|---|
| int | read() | 读取一个字节的数据,返回的就是读取的字节,返回 -1 代表已经完全读完了 |
| int | read(byte[] b) | 最多读取 b.length 字节的数据到 b 中,返回实际读到的字节数量;-1 代表以及读完了 |
| int | read(byte[] b,int off, int len) | 最多读取 len - off 字节的数据到 b 中,放在从 off 开始,返回实际读到的数量;-1 代表以及读完了 |
| void | close() | 关闭字节流 |
看到上面的返回值,有的同学可能会有疑问:明明是一次返回一个字节,那么返回的不应该是一个byte类型吗?为何返回的是int?
我们知道,一个字节的范围是 0 ~ 255或者说 -128 ~ 127 。如果返回的是byte,本身就是 -128 ~ 127这个范围的,当读出一个-1的时候,我们到底是读到了文件结尾还是说正好是读到一个-1 (oxff) 的字节?为了表示这种非法状态,于是就约定使用 -1 来表示 。因此我们就需要一个比byte 更大范围的数据类型——short或者int。我们采用的是int,short一般很少用,在面临用整数的情况下,一般优先考虑int。 在针对字符流的时候,也会有类似的设定,一次读取一个char,也是使用 int 作为返回值更合适一些,这样可以让字符流与字节流统一起来。
实际上,通过进去查看read()的源码也是要求这样做的。

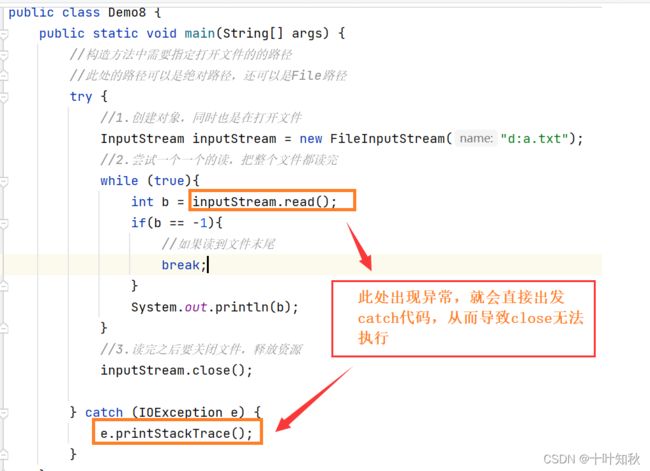
代码演示:
public class Demo8 {
public static void main(String[] args) {
//构造方法中需要指定打开文件的的路径
//此处的路径可以是绝对路径,还可以是File路径
try {
//1.创建对象,同时也是在打开文件
InputStream inputStream = new FileInputStream("d:a.txt");
//2.尝试一个一个的读,把整个文件都读完
while (true){
int b = inputStream.read();
if(b == -1){
//如果读到文件末尾
break;
}
System.out.println(b);
}
//3.读完之后要关闭文件,释放资源
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}

实际上,上面的代码不够完美,因为如果在执行read()的过程中抛出了异常,就可能导致close关闭不了。
那么,我们把close放到finally里面就可以,但是代码完成之后,我们一看,就感觉有点太长了。

实际上,在Java中提供了一个语法:try with resources。
public static void main(String[] args) {
try (InputStream inputStream = new FileInputStream("d:/a.txt")) {
while (true) {
int b = inputStream.read();
if (b == -1) {
break;
}System.out.println(b);
}
} catch (IOException e) {
e.printStackTrace();
}
}
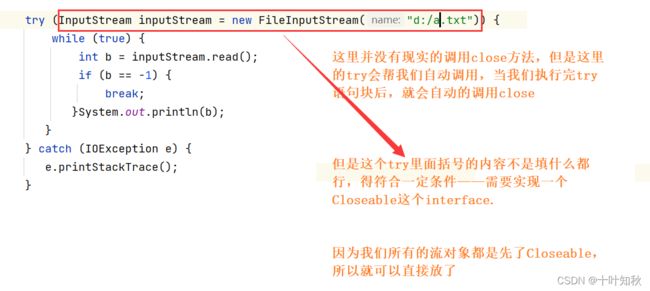
上面的代码都是一次读一个字节的,那么要是一次读若干个,该如何操作?这里需要使用到read的第二个方法。
try (InputStream inputStream = new FileInputStream("d:/test.txt")) {
// 一次读取若干个字节.
while (true) {
byte[] buffer = new byte[1024];
int len = inputStream.read(buffer);
if (len == -1) {
// 如果返回 -1 说明读取完毕了
break;
}
for (int i = 0; i < len; i++) {
System.out.println(buffer[i]);
}
}
} catch (IOException e) {
e.printStackTrace();
}

相较于第一个方法,第二个方法就使用得比较广泛,因为我们平时每次读磁盘都是比较低效的操作,所以能读多一点就读多一点。
2.2.利用 Scanner 进行字符读取
我们看到了对字符类型直接使用 InputStream 进行读取是非常麻烦且困难的,所以,我们使用一种我们之前比较熟悉的类来完成该工作,就是 Scanner 类.
| 构造方法 | 说明 |
|---|---|
| Scanner(InputStream is, String charset) | 使用 charset 字符集进行 is 的扫描读取 |
import java.io.*;
import java.util.*;
// 需要先在项目目录下准备好一个 hello.txt 的文件,里面填充 "你好中国" 的内容
public class Main {
public static void main(String[] args) throws IOException {
try (InputStream is = new FileInputStream("hello.txt")) {
try (Scanner scanner = new Scanner(is, "UTF-8")) {
while (scanner.hasNext()) {
String s = scanner.next();
System.out.print(s);
}
}
}
}
}
2.3.OutputStream
OutputStream的方法:OutputStream 同样只是一个抽象类,要使用还需要具体的实现类。我们现在还是只关心写入文件中,所以使用 FileOutputStream
| 修饰符及返回值类型 | 方法签名 | 说明 |
|---|---|---|
| void | write(int b) | 写入要给字节的数 |
| void | write(byte[]b) | 将 b 这个字符数组中的数据全部写入 os 中 |
| Int | write(byte[]b, int off,int len) | 将 b 这个字符数组中从 off 开始的数据写入 os 中,一共写 len 个 |
| void | close() | 关闭字节流 |
| void | flush() | 重要:我们知道 I/O 的速度是很慢的,所以,大多的 OutputStream 为了减少设备操作的次数,在写数据的时候都会将数据先暂时写入内存的一个指定区域里,直到该区域满了或者其他指定条件时才真正将数据写入设备中,这个区域一般称为缓冲区。但造成一个结果,就是我们写的数据,很可能会遗留一部分在缓冲区中。需要在最后或者合适的位置,调用 flush(刷新)操作,将数据刷到设备中 。 |
(1)一次写入一个字节的数据
public class Demo9 {
public static void main(String[] args) {
try (OutputStream outputStream = new FileOutputStream("d:/a.txt")){
outputStream.write(97);
outputStream.write(98);
outputStream.write(99);
}catch (IOException e) {
e.printStackTrace();
}
}
}

(2)一次写入多个字节的数据
public class Demo9 {
public static void main(String[] args) {
try (OutputStream outputStream = new FileOutputStream("d:/a.txt")){
byte[] buffer = new byte[]{97,98,99};
outputStream.write(buffer);
}catch (IOException e) {
e.printStackTrace();
}
}
}
【注意】
try (OutputStream outputStream = new FileOutputStream(“d:/a.txt”)).每次按照这种方式打开文件,都会清空文件原有的内容,再从起始位置往后写。如果不想清空内容的话,还有一种追加写的流对象,打开之后不清空,而是从文件末尾继续往后写。
(3)按照字符来读
public class Demo10 {
public static void main(String[] args) {
try (Reader reader = new FileReader("d:/a.txt")){
//按照字符来读
while(true){
char[] buffer = new char[1024];
int len = reader.read(buffer);
if(len == -1){
break;
}
for (int i = 0; i < len; i++) {
System.out.println(i);
}
}
}catch (IOException e){
e.printStackTrace();
}
}
}
(4)按照字符来写
public class Demo11 {
public static void main(String[] args) {
try(Writer writer = new FileWriter("d:/a.txt")){
writer.write("xzy");
}catch (IOException e){
e.printStackTrace();
}
}
}
三、案例分析
1.案例一:查找文件并删除
扫描指定目录,并找到名称中包含指定字符的所有普通文件(不包含目录),并且后续询问用户是否要删除该文件.
package file;
import java.io.File;
import java.io.IOException;
import java.util.Scanner;
public class Demo12 {
public static void main(String[] args) {
//1.先输入要扫描的目录,以及要删除的文件名
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要扫描的路径:");
String rootDirPath = scanner.next();
System.out.println("请输入要删除的文件名:");
String toDeleteName = scanner.next();
File rootDir = new File(rootDirPath);
if(!rootDir.isDirectory()){
System.out.println("输入的扫描路径有误!");
return;
}
//2.遍历目录,把指定目录中的所有文件和子目录都遍历一遍,从而找到要删除的文件
// 通过这个方法来实现递归遍历的操作
scanDir(rootDir,toDeleteName);
}
private static void scanDir(File rootDir,String toDeleteName){
//1.先列出rootDir中都有哪些内容
File[] files = rootDir.listFiles();
if(files == null){
//rootDir是一个空目录
return;
}
//2.遍历当前列出的这些内容,如果是普通文件,就检测文件名是否是要删除的文件
//如果是目录,就递归的进行遍历
for(File f: files){
if(f.isFile()){
//普通文件的清空
if(f.getName().contains(toDeleteName)){
//不要求名字完全一样,只要文件名中包含了关键字即可删除
deleteFile(f);
}
}else if(f.isDirectory()){
//目录递归的进行遍历
scanDir(f,toDeleteName);
}
}
}
private static void deleteFile(File f){
try {
System.out.println(f.getCanonicalPath()+"确认要删除码?");
Scanner scanner = new Scanner(System.in);
String choice = scanner.next();
if(choice.equals("Y") || choice.equals("y")){
f.delete();
System.out.println("文件删除成功");
}else {
System.out.println("文件取消删除");
}
}catch (IOException e){
e.printStackTrace();
}
}
}

2.案例二:普通文件的复制
这里需要用户指定两个路径,一个是原路径(被复制的文件),一个是目标路径(路径生成之后的文件)。具体操作是打开源路径的文件,读取里面的内容,并写入到目标文件中。
/**
* \* Created with IntelliJ IDEA.
* \* User: Administrator
* \* Date: 2022/4/8
* \* Time: 20:56
* \* To change this template use File | Settings | File Templates.
* \* Description:
* \
*/
import java.io.*;
import java.util.Scanner;
public class Demo13 {
public static void main(String[] args) {
// 1. 输入两个路径
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要拷贝的源路径: ");
String src = scanner.next();
System.out.println("请输入要拷贝的目标路径: ");
String dest = scanner.next();
File srcFile = new File(src);
if (!srcFile.isFile()) {
System.out.println("输入的源路径不正确!");
return;
}
// 此处不太需要检查目标文件是否存在. OutputStream 写文件的时候能够自动创建不存在的文件.
// 2. 读取源文件, 拷贝到目标文件中
try (InputStream inputStream = new FileInputStream(src)) {
try (OutputStream outputStream = new FileOutputStream(dest)) {
// 把 inputStream 中的数据读出来, 写入到 outputStream 中
byte[] buffer = new byte[1024];
while (true) {
int len = inputStream.read(buffer);
if (len == -1) {
// 读取完毕
break;
}
// 写入的时候, 不能把整个 buffer 都写进去. 毕竟 buffer 可能是只有一部分才是有效数据.
outputStream.write(buffer, 0, len);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
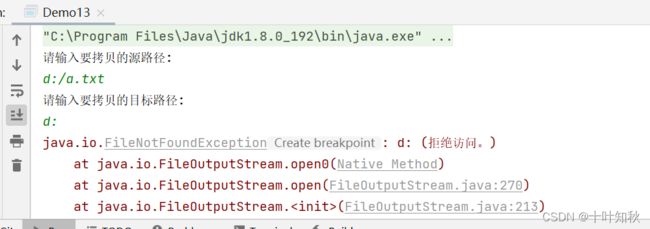
3.案例三:扫描指定目录
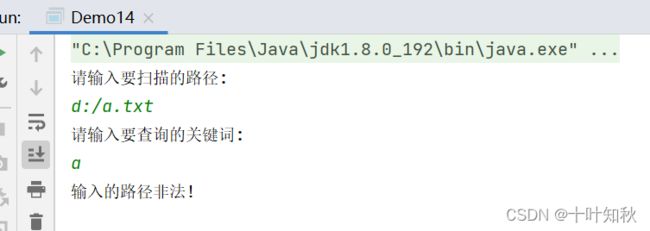
扫描指定目录,并找到名称或者内容中包含指定字符的所有普通文件(不包含目录)。
注意:我们现在的方案性能较差,所以尽量不要在太复杂的目录下或者大文件下实验。
import java.io.*;
import java.util.Scanner;
public class Demo14 {
public static void main(String[] args) throws IOException {
// 1. 输入要扫描的文件路径
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要扫描的路径: ");
String rootDirPath = scanner.next();
System.out.println("请输入要查询的关键词: ");
String word = scanner.next();
File rootDir = new File(rootDirPath);
if (!rootDir.isDirectory()) {
System.out.println("输入的路径非法!");
return;
}
// 2. 递归的进行遍历
scanDir(rootDir, word);
}
private static void scanDir(File rootDir, String word) throws IOException {
// 1. 先列出 rootDir 中都有哪些内容
File[] files = rootDir.listFiles();
if (files == null) {
return;
}
// 2. 遍历每个元素, 针对普通文件和目录分别进行处理.
for (File f : files) {
if (f.isFile()) {
// 针对文件进行内容查找
if (containsWord(f, word)) {
System.out.println(f.getCanonicalPath());
}
} else if (f.isDirectory()) {
// 针对目录进行递归
scanDir(f, word);
}
}
}
private static boolean containsWord(File f, String word) {
// 写代码, 慎重使用缩写!!! 缩写的可读性会比较差. (一些业界常见缩写, 可以用, 不要随便滥用)
StringBuilder stringBuilder = new StringBuilder();
// 把 f 中的内容都读出来, 放到一个 StringBuilder 中
try (Reader reader = new FileReader(f)) {
char[] buffer = new char[1024];
while (true) {
int len = reader.read(buffer);
if (len == -1) {
break;
}
// 把这一段读到的结果, 放到 StringBuilder 中
stringBuilder.append(buffer, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
// indexOf 返回的是子串的下标. 如果 word 在 stringBuilder 中不存在, 则返回下标为 -1
return stringBuilder.indexOf(word) != -1;
}
}
四、最后
江畔何人初见月?江月何年初照人?人生代代无穷已,江月年年望相似。