HDFS监控方法以及核心指标
文章目录
- 1. 监控指标采集
- 2. 核心告警指标
-
- 2.1 nn核心指标
- 2.1 dn核心指标
- 2.3 jn核心指标
- 2.4 zkfc核心指标
- 3. 参考文章
探讨hdfs的监控数据采集方式以及需要关注的核心指标,便于日常生产进行监控和巡检。
1. 监控指标采集
监控指标的采集方式使用promethues + jmx_prometheus_javaagent的方式进行,当hdfs的nn/dn启动时带起jmx_prometheus_javaagent,jmx_prometheus_javaagent会采集相关的指标,并通过promethues协议暴露出来。本文探讨hdfs的nn和dn的采集监控方式,yarn集群后续会进行相关文章更新。
1, jmx_prometheus_javaagent的下载地址,可以在github中获取下载地址,本文的下载包是jmx_prometheus_javaagent-0.20.0.jar
2,将jmx_prometheus_javaagent-0.20.0.jar上传到hdfs的部署路径中(如/usr/local/hadoop/jmx/jmx_prometheus_javaagent-0.20.0.jar)
3,配置nn和dn的采集指标,由于本文只是实例,因此可以使用如下配置
root@Master:/usr/local/hadoop/jmx# cat datanode.yaml
startDelaySeconds: 0
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false

4, 将jmx_prometheus_javaagent-0.20.0.jar配置到启动参数中
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
# 添加如下配置
# nn配置,通过30002端口暴露指标
export HADOOP_NAMENODE_OPTS="$HDFS_NAMENODE_OPTS -javaagent:/usr/local/hadoop/jmx/jmx_prometheus_javaagent-0.20.0.jar=10000:/usr/local/hadoop/jmx/namenode.yaml"
# dn配置,通过30003端口暴露指标
export HADOOP_DATANODE_OPTS="$HDFS_DATANODE_OPTS -javaagent:/usr/local/hadoop/jmx/jmx_prometheus_javaagent-0.20.0.jar=30003:/usr/local/hadoop/jmx/datanode.yaml"
5, 启动nn和dn
cd /usr/local/hadoop/sbin
# 启动或者重启nn
./hadoop-daemon.sh start namenode
# 启动或者重启dn
./hadoop-daemon.sh start datanode
6,查看相关进程和端口,确认相关的指标暴露
# 查看namenode进程,应该有jmx_prometheus_javaagent相关参数被带起
ps -ef|grep namenode
ps -ef|grep datanode
# 查看端口情况
netstat -ntlp|grep 300

小技巧:
由于版本问题,有时候一直搞不明白,yarn使用的是哪个一个配置(/usr/local/hadoop/etc/hadoop/hadoop-env.sh中注释的是HDFS_NAMENODE_OPTS,但实际使用的是HDFS_DATANODE_OPTS)容易搞晕。
可以到/usr/local/hadoop/libexec/hadoop-functions.sh文件中打印输出配置,以判断具体是哪个变量。
vim /usr/local/hadoop/libexec/hadoop-functions.sh

7, 验证metrics指标
确定metrics指标暴露出来后,就可以通过prometheus配置target进行指标采集
# 通过promethues协议暴露指标
curl http://localhost:30003/metrics
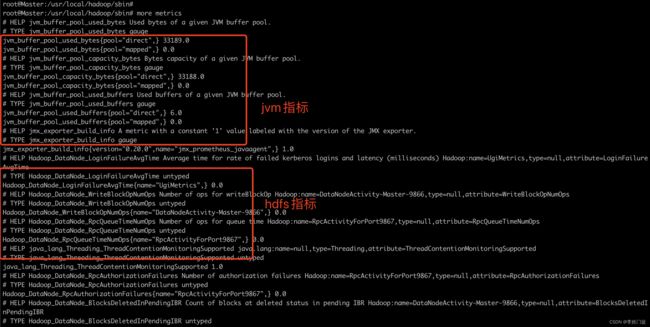
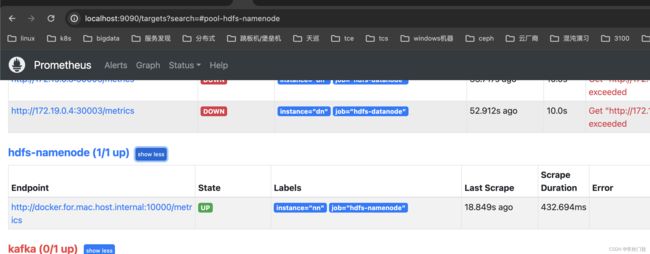
8, 配置prometheus进行指标采集
配置prometheus的指标采集任务
- job_name: hdfs-namenode
static_configs:
- targets: ['172.19.0.2:30002']
labels:
instance: nn
- job_name: hdfs-datanode
static_configs:
- targets: ['172.19.0.2:30003','172.19.0.3:30003','172.19.0.4:30003']
labels:
instance: dn
2. 核心告警指标
hdsf的指标很多,相关的指标含义可以参考 官网文档,本文将摘选出核心的指标,作为hdfs集群的核心监控并配置相关的告警。
不通版本的指标略有差异,但是整体上是一致的
2.1 nn核心指标
| 指标名称 | 指标说明 | 参考值 | 备注 |
|---|---|---|---|
| 进程 | 进程 | 进程存在 == 1 | |
| 主备情况 | State | 1:主,0:备 | 集群必须包含1主1备 |
| MissingBlocks | 缺失数据块 | <= 0 | 块监控 |
| CorruptBlocks | 坏快 | <= 0 | 块监控 |
| UnderReplicatedBlocks | 副本数不够的块数量 | <= 0 | 块监控 |
| NumDeadDataNodes | 已经标记为 Dead 状态的数据节点数量 | <= 0 | 节点监控 |
| ExpiredHeartbeats | 心跳超时节点 | <= 0 | 节点监控 |
| PercentUsed | 系统磁盘使用率 | <= 70 | 根据实际情况调整,清理过期数据获取扩容 |
| TotalFiles | 总文件数量 | 待定 | 指标的合理阈值暂时不明确,还没有遇到相关的问题 |
| TotalBlock | 总块数量 | 待定 | 指标的合理阈值暂时不明确,还没有遇到相关的问题 |
| PendingDataNodeMessageCount | DATANODE 的请求被 QUEUE 在 standby namenode 中的个数 | <= 0 | |
| CallQueueLength | 当前 RPC 处理队列长度 | <= 1000 | 过长的rpc队列会导致nn处理不过来了,注意调优jvm或者线程数量以及客户端的缓存 |
| RpcProcessingTimeAvgTime | RPC请求平均处理时间 | <= 100ms | rpc处理慢和队列长度有一定的关系,也是nn性能差或者压力大导致,需要注意调优jvm或者线程,以及更换nn更好的磁盘,提升磁盘io能力 |
| MemHeapUsedM/MemHeapMaxM | Jvmd堆内内存使用率 | <= 60% |
2.1 dn核心指标
| 指标名称 | 指标说明 | 参考值 | 备注 |
|---|---|---|---|
| 进程 | 进程 | 进程存在 == 1 | |
| BytesWrittenMB | 写入 DN 的字节速率 | 根据机器的网卡带宽调整 | |
| BytesReadMB | 读取 DN 的字节速率 | 根据机器的网卡带宽调整 | |
| VolumeFailures | 磁盘故障次数 | <= 0 | |
| DatanodeNetworkErrors | 网络错误统计 | <= 0 | |
| 磁盘使用率 | <= 70 | ||
| 磁盘await | 磁盘读写的await | <= 1ms | |
| CallQueueLength | 当前 RPC 处理队列长度 | <= 1000 | 过长的rpc队列会导致nn处理不过来了,注意调优jvm或者线程数量以及客户端的缓存 |
| MemHeapUsedM/MemHeapMaxM | Jvmd堆内内存使用率 | <= 60% | |
| HeartbeatsAvgTime | 心跳接口平均时间 | <= 1ms |
2.3 jn核心指标
| 指标名称 | 指标说明 | 参考值 | 备注 |
|---|---|---|---|
| 进程 | 进程 | 进程存在 == 1 | |
| CallQueueLength | 当前 RPC 处理队列长度 | <= 1000 | 过长的rpc队列会导致nn处理不过来了,注意调优jvm或者线程数量以及客户端的缓存 |
| MemHeapUsedM/MemHeapMaxM | Jvmd堆内内存使用率 | <= 60% | |
| HeartbeatsAvgTime | 心跳接口平均时间 | <= 1ms |
2.4 zkfc核心指标
| 指标名称 | 指标说明 | 参考值 | 备注 |
|---|---|---|---|
| 进程 | 进程 | 进程存在 == 1 | |
| MemHeapUsedM/MemHeapMaxM | Jvmd堆内内存使用率 | <= 60% | |
| HeartbeatsAvgTime | 心跳接口平均时间 | <= 1ms |
3. 参考文章
-
如何使用JMX_Expoter+Prometheus+Grafana监控Hadoop集群
-
HDFS 监控指标