记录使用python网络爬虫下载小说
记录使用python网络爬虫下载小说
在学习python的过程中,不可避免在互联网上看到各种各样的关于pytho网络爬虫的文章,视频,某站某微上不少打着卖课的幌子过度夸大了python爬虫,总的来说,python爬虫是一种更省时省力的获取信息的途径,可能对我而言,因为某些事确实懒得动手去做,但是爬虫也没有那么无所不能。希望大家擦亮眼睛,不要上当受骗!
这次想尝试记录一下使用python爬取网络小说的一次经历,不喜勿喷!
1、背景介绍
小说网站,“新笔趣阁”:(仅做测试)
https://www.quge9.cc/
2、爬虫步骤
要想把大象装冰箱,总共分几步?
要想爬取数据,总共分几步?
爬虫其实很简单,可以大致分为三个步骤:
- 发起请求:我们需要先明确如何发起 HTTP 请求,获取到数据。
- 解析数据:获取到的数据乱七八糟的,我们需要提取出我们想要的数据。
- 保存数据:将我们想要的数据,保存下载。
发起请求,我们 用requests 就行
解析数据工具有很多,比如xpath、Beautiful Soup、正则表达式等。我们这次使用Beautiful Soup来解析数据进行爬取。
保存数据,就是常规的文本保存。
3、小试牛刀
我们先看下《在数据世界搞基建》小说的第一章内容。
URL:https://www.quge9.cc/book/32493/
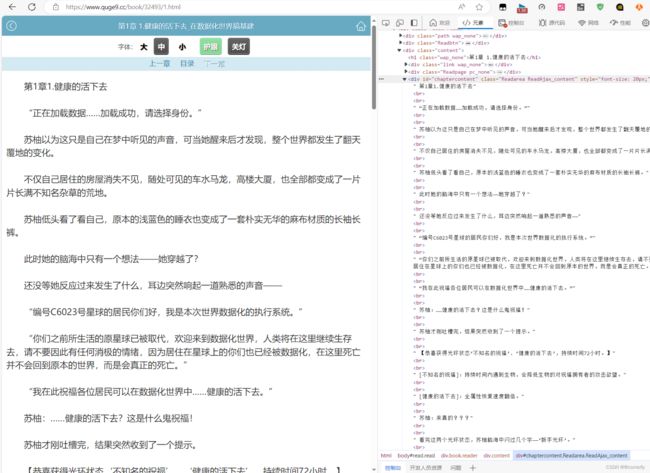
我们使用右键,点击检查或者使用F12就可以轻松地获取了 HTML 信息,里面有我们想要的小说正文内容,但是也包含了一些其他内容,我们并不关心 div 、br 这些 HTML 标签。
或者是我们写一个request请求来查看一下页面的html信息;
from urllib import request
from bs4 import BeautifulSoup
response = request.urlopen('https://www.quge9.cc/book/32493/1.html')
print(response.read().decode('utf-8'))
和我们直接F12的效果是一样的
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0, user-scalable=no">
<meta http-equiv="mobile-agent" content="format=html5; url=https://m.quge9.cc/book/32493/1.html"/>
<meta http-equiv="mobile-agent" content="format=xhtml; url=https://m.quge9.cc/book/32493/1.html"/>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"/>
<meta name="renderer" content="webkit|ie-comp|ie-stand"/>
<meta name="format-detection" content="telephone=no"/>
<title>在数据化世界搞基建_第1章 1.健康的活下去_新笔趣阁</title>
<meta name="keywords" content="在数据化世界搞基建,第1章 1.健康的活下去"/>
<meta name="description" content="新笔趣阁提供了随风叶落最新创作的科幻小说《在数据化世界搞基建》干净清爽无错字的文字章节:第1章 1.健康的活下去 在线阅读。"/>
<link rel="stylesheet" href="/css/style.css"/>
<script type="text/javascript" src="https://apps.bdimg.com/libs/jquery/1.8.3/jquery.min.js"></script>
<script type="text/javascript" src="/js/compc.js?v=1.23"></script>
<script type="text/javascript" src="/js/read.js?v=1.23"></script>
</head>
<body id="read" class="read">
<div class="header_wap pc_none">
<a class="home" href="javascript:history.go(-1);"><svg class="lnr lnr-chevron-left-circle"><use xlink:href="#lnr-chevron-left-circle"></use></svg></a>
<span class="title">第1章 1.健康的活下去_在数据化世界搞基建</span>
<a class="user" href="/"><svg class="lnr lnr-home"><use xlink:href="#lnr-home"></use></svg></a>
</div>
<div class="header_top"></div>
...
</div>
<script>tj();</script>
</body>
</html>
如何把正文内容从这些众多的 HTML 标签中提取出来呢?
这就需要爬虫的第二步“解析数据”,也就是使用 Beautiful Soup 进行解析。
现在,我们使用一下审查元素方法,查看一下我们的目标页面,你会看到如下内容

不难发现,文章的所有内容都放在了一个名为div的“东西下面”,这个"东西"就是 HTML 标签。HTML 标签是 HTML 语言中最基本的单位。
HTML 标签就像一个个“口袋”,每个“口袋”都有自己的特定功能,负责存放不同的内容。显然,上述例子中的 div 标签下存放了我们关心的正文内容。这个 div 标签是这样的:
<div id="chaptercontent" class="Readarea ReadAjax_content" style="font-size: 20px;">
id 就是 div 标签的属性,content是属性值,一个属性对应一个属性值。
属性是用来区分不同的 div 标签的,因为 div 标签可以有很多,id 可以理解为这个 div 的身份。
这个 id 属性为 content 的 div 标签里,存放的就是我们想要的内容,我们可以利用这一点,使用Beautiful Soup 提取我们想要的正文内容,编写代码如下:
from urllib import request
from bs4 import BeautifulSoup
response = request.urlopen('https://www.quge9.cc/book/32493/1.html')
html = response.read().decode('utf-8')
bs = BeautifulSoup(html,'lxml')
texts = bs.find('div',id='chaptercontent')
print(texts.get_text())
第1章1.健康的活下去 “正在加载数据……加载成功,请选择身份。” 苏柚以为这只是自己在梦中听见的声音,可当她醒来后才发现,整个世界都发生了翻天覆地的变化。 不仅自己居住的房屋消失不见,随处可见的车水马龙,高楼大厦,也全部都变成了一片片长满不知名杂草的荒地。 苏柚低头看了看自己,原本的浅蓝色的睡衣也变成了一套朴实无华的麻布材质的长袖长裤。 此时她的脑海中只有一个想法——她穿越了? 还没等她反应过来发生了什么,耳边突然响起一道熟悉的声音—— “编号C6023号星球的居民你们好,我是本次世界数据化的执行系统。” “你们之前所生活的原星球已被取代,欢迎来到数据化世界,人类将在这里继续生存去,请不要因此有任何消极的情绪,因为居住在星球上的你们也已经被数据化,在这里死亡并不会回到原本的世界,而是会真正的死亡。” “我在此祝福各位居民可以在数据化世界中……健康的活下去。” 苏柚:……健康的活下去?这是什么鬼祝福! 苏柚才刚吐槽完,结果突然收到了一个提示。 【恭喜获得光环状态‘不知名的祝福’、‘健康的活下去’,持续时间72小时。】 [不知名的祝福]:持续时间内遇到生物,会降低生物的对祝福拥有者的攻击欲望。 [健康的活下去]:全属性恢复速度翻倍。 苏柚:来真的??? 看完这两个光环状态,苏柚脑海中闪过几个字——‘新手光环’。 如果再详细一些,那就是‘新手保护光环’。 但凡玩过游戏的都知道,处于新手期,系统总是会给你的角色套上一些buff(光环、状态),来保证新手玩家的游戏体验。 而这个所谓的执行系统给祝福的行为,简直和那些游戏给新手套光环是一模一样的。 所以所谓的‘数据化世界’她是不是可以理解为是将真实世界给变成了一个‘游戏世界’? 为了验证自己的想法,苏柚尝试性的准备呼出游戏面板……结果是既惊讶,又在意料之中的成功了。 确认了这个世界真的被数据化了之后,苏柚还意外的发现了这个数据化世界所参考,或者说是直接套用的游戏原型。 一切都是因为她看见了一个熟悉的logo。 而这个logo和她以前玩过的一款名为‘落日大陆’的全息游戏一模一样。 苏柚其实还不仅仅只是玩过而已,她还是《落日大陆》这款游戏第一个通关的玩家……准确的说,是第一个以‘城主’的身份通关的玩家。 《落日大陆》是这个游戏所在背景的大陆的名字,游戏最初,每个玩家都有很多的身份可以选择,不同的身份有不同的游戏过程和结局。 作为偏爱生存经营基建游戏的苏柚,她自然是果断的选择了与之相关的‘城主’身份开始了游戏,因为城主这个身份的特点就是可以通过收集物资,修筑建筑,招募居民和勇士,建立属于自己的都城。 当然,这都是很久之前的事情了。 这个游戏早在两年前就已经完全消失了,连带着苏柚那个首通城主角色的满级都城的账号也完完全全的消失了。 如果这真的是当时那个游戏,那么苏柚倒也不介意以生命为代价再玩一把。 因为就像是这个执行系统所说的一样,都已经数据化了,与其消极游戏不如想着如何好好的活下去。 正好她当时为了‘一命通关’,一直都只使用了一个存档进行游戏,这导致她做出了许多错误的选择,留下了许多的遗憾。 本来她想弥补这些遗憾,但在她通关游戏后,因为现实生活的事情,将这个游戏放置了一段时间。 等她终于有空闲的时间可以重来时,便得知了游戏公司跑路,游戏永久关服的消息。 …… …… “……让我想想,现在要先准备什么。”既然是老玩家,苏柚自然是对这个游戏十分了解的。 如果她没有记错,自己在睡梦中听见执行系统让自己选择身份,她还以为是自己梦到跑路的游戏公司良心发现,重新回来开游戏,所以她选择的身份还是之前一样的‘城主’身份。 而这个也在她查看自己的个人信息时,得到了确认。 【苏柚】 等级:无 所属:无 身份:建造者 体力: 饥饿: 血量: 状态:正常 技能:无 装备:无 光环:健康的活下去(剩余时间:71小时57分钟49秒) 不知名的祝福(剩余时间:71小时57分钟49秒) …… “这简直和当初的界面一模一样啊……”虽然身份显示的是建造者而不是她所选择的城主,但这不是因为还没建城嘛! 没有城,哪儿来的城主? 等第一个城池建立后,她的身份便会发生改变。 看完个人信息面板,苏柚顺带看了看其他游戏界面,在看到【背包】面板时,她突然愣住了。 这个游戏虽然有新手光环,但并没有新手礼包,可她却在本该空空如也的背包中看见了一个类似令牌的图标。 这个图标很陌生,至少她曾经玩这个游戏时并没有见过这个道具。 不知为何,看着这个图标,苏柚的内心莫名有了一种不太好的预感,伴随着这种不好的预感,她点开图标开始查看这个物品的信息。 【领主令牌】(该物品将在71小时56分钟51秒后消失) 分类:特殊 品质:无 介绍:领主令牌是建立领地的必须道具,对选中区域使用领主令牌并点燃城心火可建立领地。 就在苏柚看完领主令牌的全部信息的同时,一道机械音自她脑海中响起—— 【请在规定时间内建立领地加入数据化世界,超出时间未加入世界,则会被视为游离数据。】 像是仅仅只让苏柚听到这段话话还不够,苏柚眼前出现了一个巨大的窗口,窗口上的文字正是这段内容。 游离数据? 这是什么? 苏柚看着这段话,一下就抓住了重点。 希望没认真看简介的读者请注意,本文无cp。 请收藏本站:https://www.quge9.cc。新笔趣阁手机版:https://m.quge9.cc
『点此报错』『加入书签』
小说正文,已经顺利获取到了。要想下载整本小说,我们就要获取每个章节的链接。我们先分析下小说目录:
URL : https://www.quge9.cc/book/32493/

审查元素后,我们不难发现,所有的章节信息,都存放到了 id 属性为 list 的 div 标签下的 a 标签内,编写如下代码:
from urllib import request
from bs4 import BeautifulSoup
response = request.urlopen('https://www.quge9.cc/book/32493/')
html = response.read().decode('utf-8')
bs = BeautifulSoup(html,'lxml')
#
list = bs.find('div',class_='listmain')
list = list.find_all('a')
print(list)
[<a href="/book/32493/1.html">第1章 1.健康的活下去</a>, <a href="/book/32493/2.html">第2章 2游离数据</a>, <a href="/book/32493/3.html">第3章 3轻微疲惫</a>, <a href="/book/32493/4.html">第4章 4梅开二度</a>, <a href="/book/32493/5.html">第5章 5.红色浆果</a>, <a href="/book/32493/6.html">第6章 6.砍树从扒皮开始</a>, <a href="/book/32493/7.html">第7章 7.夕阳花</a>, <a href="/book/32493/8.html">第8章 8.浆果食谱</a>, <a href="/book/32493/9.html">第9章 9石头怪</a>, <a href="/book/32493/10.html">第10章 10.神秘生物</a>, <a href="javascript:dd_show()" rel="nofollow"><<---展开全部章节--->></a>, <a href="/book/32493/11.html">第11章 11.交易</a>, <a href="/book/32493/12.html">第12章 12初级箭塔
可以看到章节链接和章节名我们已经提取出来,但是还需要进一步解析,编写如下代码:
from urllib import request
from bs4 import BeautifulSoup
server = 'https://www.quge9.cc'
target = 'https://www.quge9.cc/book/32493/'
response = request.urlopen(target)
html = response.read().decode('utf-8')
books_bs = BeautifulSoup(html,'lxml')
books = books_bs.find('div',class_ = 'listmain')
books = books.find_all('a')
for book in books:
url =book.get('herf')
print(book.string)
print(server + target)
第1章 1.健康的活下去
https://www.quge9.cchttps://www.quge9.cc/book/32493/
第2章 2游离数据
https://www.quge9.cchttps://www.quge9.cc/book/32493/
第3章 3轻微疲惫
https://www.quge9.cchttps://www.quge9.cc/book/32493/
第4章 4梅开二度
https://www.quge9.cchttps://www.quge9.cc/book/32493/
第5章 5.红色浆果
https://www.quge9.cchttps://www.quge9.cc/book/32493/
第6章 6.砍树从扒皮开始
https://www.quge9.cchttps://www.quge9.cc/book/32493/
第7章 7.夕阳花
https://www.quge9.cchttps://www.quge9.cc/book/32493/
第8章 8.浆果食谱
https://www.quge9.cchttps://www.quge9.cc/book/32493/
第9章 9石头怪
https://www.quge9.cchttps://www.quge9.cc/book/32493/
第10章 10.神秘生物
https://www.quge9.cchttps://www.quge9.cc/book/32493/
<<---展开全部章节--->>
https://www.quge9.cchttps://www.quge9.cc/book/32493/
第11章 11.交易
https://www.quge9.cchttps://www.quge9.cc/book/32493/
第12章 12初级箭塔
...
第657章 657摧毁碎片
可以看到,book.get('href') 方法提取了 href 属性,并拼接出章节的 url,使用 book.string 方法提取了章节名。
每个章节的链接、章节名、章节内容都有了。接下来就是整合代码,将内容保存到txt中即可。编写代码如下:
from urllib import request
from bs4 import BeautifulSoup
import time
from tqdm import tqdm
def get_content(target):
response = request.urlopen(target)
html =response.read().decode('utf-8')
bs = BeautifulSoup(html,'lxml')
texts = bs.find('div',id='chaptercontent')
content = texts.text
return content
if __name__ == "__main__":
server = 'https://www.quge9.cc'
target = 'https://www.quge9.cc/book/148830/'
book_name = 'book.docx'
response = request.urlopen(target)
html = response.read().decode('utf-8')
books_bs = BeautifulSoup(html,'lxml')
books = books_bs.find('div',class_='listmain')
books =books.find_all('a')
for book in tqdm(books):
book_name = book.string
url = server + book.get('href')
content = get_content(url)
with open(book_name,'a',encoding='utf-8') as f:
f.write(book_name)
f.write('\n')
f.write('\n'.join(content))
f.write('\n')
但是上面的爬取速度实在感人,还是创建多线程爬取吧,需要使用Python的multiprocessing模块来并行处理多个任务。代码如下
from urllib import request
from bs4 import BeautifulSoup
from multiprocessing import Pool
import sys
server = 'https://www.quge9.cc' # 将server定义在前面
def get_content(target):
response = request.urlopen(target)
html = response.read().decode('utf-8')
bs = BeautifulSoup(html, 'lxml')
texts = bs.find('div', id='chaptercontent')
if texts:
content = texts.text
return content
else:
print(f"Couldn't find 'div' with id 'chaptercontent' in {target}")
return None
def process_book(book):
book_name = book.string
url = server + book.get('href')
print(f"Processing {book_name}: {url}") # 观察进度和异常
content = get_content(url)
if content:
with open(book_name + '.docx', 'a', encoding='utf-8') as f:
f.write(book_name)
f.write('\n')
f.write(content)
f.write('\n')
def main():
sys.setrecursionlimit(10**5)
target = 'https://www.quge9.cc/book/148830/'
response = request.urlopen(target)
html = response.read().decode('utf-8')
books_bs = BeautifulSoup(html, 'lxml')
books = books_bs.find('div', class_='listmain').find_all('a')
# 使用多进程来并行处理书籍
with Pool() as pool:
pool.map(process_book, books)
if __name__ == "__main__":
main()
最终效果如下:
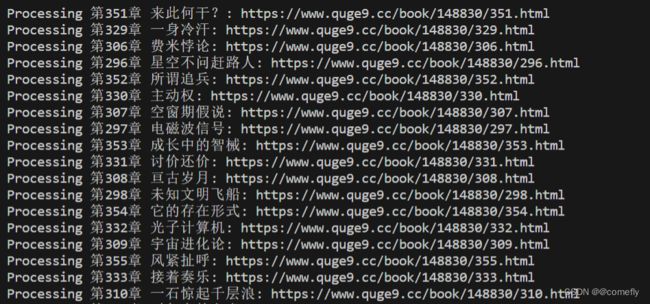
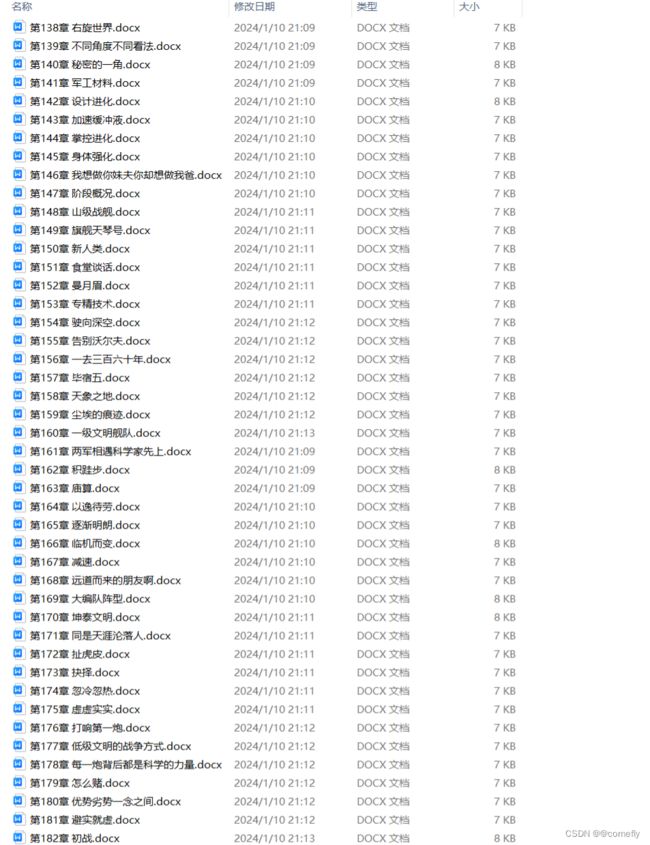
余下的就不截图了,这次是来使用python演示的,总体来说,用python爬取一些资料或内容还是比较方便的。