记忆化搜索--递归优化
你真的懂记忆化搜索吗
Hello!我是C风,在Java学习之余,算法也不能落下了,数据结构与算法是编程的灵魂,我之前已经分享过循环赛和八皇后问题;这里我们再来看看这个有趣的题目,题目可能很简单,但是我们仅仅以此当作模板来看学习深搜和记忆化搜索。
呵呵,有一天我做了一个梦,梦见了一种很奇怪的电梯。大楼的每一层楼都可以停电梯,而且第ii层楼(1<= i <= N)(1≤i≤N)上有一个数字K_i(0 \le K_i \le N)K**i(0≤K**i≤N)。电梯只有四个按钮:开,关,上,下。上下的层数等于当前楼层上的那个数字。当然,如果不能满足要求,相应的按钮就会失灵。例如:3, 3 ,1 ,2 ,53,3,1,2,5代表了K_i(K_1=3,K_2=3,…)K**i(K1=3,K2=3,…),从11楼开始。在11楼,按“上”可以到44楼,按“下”是不起作用的,因为没有-2−2楼。那么,从AA楼到BB楼至少要按几次按钮呢?如果不能到达,就输出-1;
看看输入与输出
5 1 5 3 3 1 2 5 //输出--3
这里我们可以参考分治法,这里我们就不要再用for循环了,直接把两种情况放一起就好了,也就是我们可以自动回溯,而不用手动回溯了。
在这里我先犯了经验主义错误,就是因为之前的搜索树的子节点都是大于2,所以我们经常使用的是for循环来遍历所有的子节点所以我写成了这样
for (int i = 0; i <= 1; i++)//0代表上,1代表下
{
if (i == 0)
{
arr[0] = floor;
floor += arr[floor];//我们记录下来这个数
cnt++;
DFS(num, bFloor, arr, floor);
floor -= arr[arr[0]];
cnt--;
}
else{
arr[0] = floor;
floor -= arr[floor];
cnt++;
DFS(num, bFloor, arr, floor);
floor += arr[arr[0]];
cnt--;
}
}
这里其实就不需要再这样子遍历之后手动回溯,其实我这里表达的就是一直上之后就下,这就是一课二叉树嘛,所想想二叉树那里,直接把两个子节点建立放一起的,所以两个子节点的问题都应该这样。
DFS(num, bFloor, arr,floor + arr[arr[0]]);
DFS(num, bFloor, arr, floor - arr[arr[0]]);
就这样子,它就可以自动执行了,表达的意思和上面的for循环一样。
但这样子我们就发现效率不高了,因为比如我之前到过3楼这个地方,当时就计算过从3楼到目标楼要几步到达,所以我们现在执行到这里就不需要再重复解决了
所以我们可以发现一个共性,就是简单的递归都有可能出现像斐波拉契数列一样的重复解决问题,斐波拉契数列里我们计算到某个子问题就会出现重复解决的问题
由斐波拉契数列来总结简单递归,记忆化搜索,动态规划dp
所以我接下来我就要先来将思想总结理解了之后,我再直接写出电梯问题的最优解;
首先我们先介绍一下简单的背景,就是F(n) = F(n-1) + F(n -2);而且F1 = F2 = 1;然后我们想得到第n项的值
那我们就先来说一下简单递归的解法,首先我们解决递归分治问题就是要画出搜索树,而所谓的DFS其实就是深度优先遍历,就是将其中的一个子问题先解决完,之后再解决下一个子问题,所以我们这里也可以画出现在这个递归问题的搜索树
递归问题就是先假设解决子问题
Step1:画出问题求解的搜索数(分治问题就按照问题规模划分子问题)关键
斐波拉契数列:就是以n为根结点,n-1,与n - 2 为子节点,这个的状态非常清晰,不需要分析,-----一直重复下去,直到1,2为止,递归分治为一体,最优解的合并
奇怪的电梯 P1135: 就是以起始楼层为根节点,上up 和下 down 组成两个不同的子节点,子节点还是由up和down组成,,,一直到遍历到目标楼层或者超出边界为止
我分析错了!!???采药问题 P1408: 就是所有的结点为某个根节点的子节点,然后子节点的子节点就是该子节点后面位置的数(这类题的显著特点就是子节点,根节点关系是由位置位置决定) 与此类似的还有之前的P1036,选数问题,也就是数据是连续储存再容器中的。
采药 P1048 :这其实和奇怪的电梯一样的分析,我们分析的是当前结点的可能状态,而数的划分之类的都是划分成的子问题,之后合并起来,这里当我们遇到一株草药,我们考虑的问题是我采不采的问题,就像电梯我是上还是下,还有选数问题也是我选不选的问题,我可以选也可以不选,所以这其实都是子节点只有两个的搜索,根结点就是第一株草药,最后的就是最后一株草药,选数问题也是第一个数为根节点,最后一个为最后一层,用for循环就掩盖了这个分析,所以当时虽然过了,但想不明白为什么过了,这和八皇后是差不多的,,结束条件就是我选或者不选之后到达边界。之前我那种分析其实也是这样,只是没有理顺,只有那种明确的和位置之类有关的才是考虑位置之类的,比如我们的过河卒,它的子问题就是左和上
八皇后问题:和采药一样,是以每个皇后为一层,每个皇后的状态就是放在8个位置其中的一个,所以根节点就是第一个皇后,每个皇后8中状态,就是8个子节点,结束就是超出层号。
数的划分P1025,自然数的拆分P2404:对于每个数它有几种划分的状态就有几个子节点,都是以输入数为根节点,从1开始到其一半的数都是其根节点,之后都是,直到1为止(P1025是层数为3为止)
所以分析的关键就是判断状态,8皇后是放的位置,电梯是上下,采药和选数是采不采,选不选;树的划分是划分的种类,而不是一概而论,死板求解,递归是层次分明的结构树
Step2: 判断递归结束条件
像斐波拉契数列就是到1,2结束了,其他的我们也说了,就是超出题目边界就结束了
说过递归结束条件,递归语句和回溯语句;一般只有两个子问题就不用for循环遍历儿子结点,大于2个就使用for循环来遍历子问题。
对于斐波拉契数列来说,如果不用记录数组F,会这样写,但是我们来一个标准化流程的话,就会使用一个额外的容器之类的来记录这个值,比如8皇后问题中的Load[]来记录位置,cnt辅助记录次数
public static int DFS(int n)
{
if(n < 3)
{
return 1;
}
else return DFS(n-1) + DFS(n-2);
}
那我们就会将这个简单递归写成这样
static int[] F = new int[201];//成员变量要在类的里面
public static void DFS(int n)
{
if(n < 3)
{
F[n] = 1;
return;
}
DFS(n-1);//解决第一个子问题,解决第二个子问题
DFS(n-2);
F[n] = F[n-1] + F[n-2];//合并子问题
}
所以这也就是一种分治的思想,解决所有子问题,之后合并子问题最优解,比如我们的自然数的拆分也是,1,2,3分别拆分后几个子问题的拆分合起来就是原问题最优解,所以就本身包含分治的思想;那里的合并就是在循环中实现了,因为找完第一个子问题将最优解打印出来了,所有的都打印出来就是原问题的最优解
基础递归(暴力搜索)
那我们再通过简单递归实现草药问题和楼梯问题,都是二叉树,就直接将两个子节点放一块写出来,这和二叉树是一样的,我们之前就说到过,二叉树那里回溯也是自动进行的,加了for循环的才可能要手动回溯防止污染
public static void medicine(int num,int lefttime,int pos,int allvalue)//写的手确定变量就问:变化的是什么,进入子问题后那些量改变了,那就是株的位置,所剩时间都在变
{//还有就是我们所采药的价值在变,先不要一股脑设置类变量
if(lefttime < 0)//这里可以把这个加到2子结点,因为就是因为2子节点采了才会超的,这样就不用了进这个子节点了
{
return;
}
if(pos == num + 1)//之前就先只写变量,现在就知道还要传入什么了
{
sumva = max(sumva,allvalue);
return;
}
medicine(num,lefttime,pos+1,allvalue);//第一个子节点,不采草药
medicine(num,lefttime- time[pos],pos+1,allvalue+ value[pos]);//第二个子节点,采草药,类变量不需要传
}//我们直接将变量传入当不满足条件回溯时,它就自动回溯了,不需要像8皇后手动,主要是那里太多结点,不方便
public static void medicine(int num,int lefttime,int pos,int allvalue)//写的手确定变量就问:变化的是什么,
{//还有就是我们所采药的价值在变,现在没有sumva也就不该有allvalue,不然怎么比呢?
if(pos == num + 1)
{
sumva = max(sumva,allvalue);
return;
}
medicine(num,lefttime,pos+1,allvalue);//第一个子节点,不采草药
if(lefttime >= time[pos])
{//时间够才采,不够就不进入递归了,就像八皇后一样,满足条件才进入子节点
medicine(num,lefttime- time[pos],pos+1,allvalue + value[pos]);
}
}
第一个结点是不采草药,所以我们就先一直执行不采,然后执行采最后一株草药,之后时间减少采倒数第二个草药,就这样慢慢回溯的,所以是time时间内采集后pos个草药的收益。
100 5
77 92
22 22
29 87
50 46
99 90
133
执行了 32次
当1000组数据时,就超时了,就是因为重复执行的问题
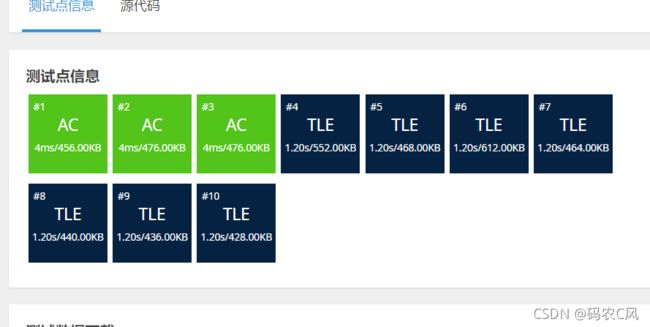
可以看到条件非常清晰,比我之前思绪混乱时的要清楚的多,但还是只是简单的递归,这种递归有个问题,比如我采集草药的时候,不采该草药及以后的都已经解决过了,就出现重复解决的问题,我们必须要避免这种情况,还有就是电梯问题也是我们已经算过从第m楼到目标楼要几步,但是我们每次计算都重复计算了,想想斐波拉契数列就知道了。
所以优化的方式确定了,就是想办法如果我发现采集后几个采药的最优解已经解决,那我就不再去算这个东西了。好,明确了点在那里我们就先想一下怎么去除外不变量sumva。
记忆化搜索
我们先来想一下这个如果不依靠外部参数sumva怎么解决,那我们返回值就要来表示我们的结果,就是在time时间采集后pos株草药所需要的时间。我们要先理解上面的过程,就是我们先走第一个结点,一直都不采,直到最后一株草药,这时我们采它,判定时间大就放回不采,回到倒数第2株;如果可以采,就会采了;然后第2株也是这样子来判定;
public static int medicine(int num,int lefttime,int pos)//写的手确定变量就问:变化的是什么,这里区分的就是变量,而不是随意写的,这里的因变量是lefttime和pos,所以我们的记录位置就是
{//还有就是我们所采药的价值在变,现在没有sumva也就不该有allvalue,不然怎么比呢?
if(pos == num + 1)
{
return 0;
}
int dfs1,dfs2 = -10000;
dfs1 = medicine(num,lefttime,pos+1);//第一个子节点,不采草药
if(lefttime >= time[pos])
{//时间够才采,不够就不进入递归了,就像八皇后一样,满足条件才进入子节点
dfs2 = medicine(num,lefttime- time[pos],pos+1) + value[pos];
}
return max(dfs1,dfs2);
}
这里我们定义的dfs1和dfs2,要理解每个函数都有这两个量,并且值是不相同的,我们知道两个子问题的最优解不是简单的合并,而是将其进行比较,到底是采了大还是不采大,我们都知道函数调用栈,每个方法创建都会建栈,所以每个子方法都对应一个dfs1和dfs2,这不正是我们想要的结果嘛,我们对于一个子方法就假设子问题都解决了,那就要一步一步执行,那到最后不就是dfs1记录的是不采草药子方法的最优解,dfs2对应的是采草药对应的最优解,所以我们这里就只需要比较输出就好,这就是最后一行代码的用处,并且加if语句可以避免继续进入子方法,减缓效率;那我们就要判断边界该输出什么了,我们进入一个方法,最后一层的时候我们进入了边界,这个时候pos是大于num的,所以它没有什么事,我们直接返回0
我在执行的定义dfs1和dfs2后面加了计数器,构建方法栈之后,只要有dfs1和dfs2进栈就会计数一次
我们既然已经知道子问题已经解决,那我们就要记录下来,因为这里要表示哪个位置的状态,需要的是剩余的时间和后面的草药数量,所以我们就用一个数组来记录这个结果,当我们搜索到这个的时候就不再继续下去了
public static int medicine(int num,int lefttime,int pos)
{//还有就是我们所采药的价值在变,现在没有sumva也就不该有allvalue,不然怎么比呢?
if(used[lefttime][pos] != 0)
{
return used[lefttime][pos];
}
if(pos == num + 1)//该子问题解决了,那我们记录下来
{
//used[lefttime][pos] = 0;
//return used[lefttime][pos];
return 0;//就够了
}
int dfs1,dfs2 = -100000;
dfs1 = medicine(num,lefttime,pos+1);
if(lefttime >= time[pos])
{
dfs2 = medicine(num,lefttime- time[pos],pos+1) + value[pos];
}
used[lefttime][pos] = max(dfs1,dfs2);
return used[lefttime][pos];
}
100 5
77 92
22 22
29 87
50 46
99 90
133
执行了 22次
我们在思考这个代码的时候就直接当作子问题解决,也就是我们直接不进入子方法,所以就可以理解了,dfs1记录不采的数据 ,dfs2记录采的数据,之后再比较大小之后返回就好了。
2614
执行了104637次
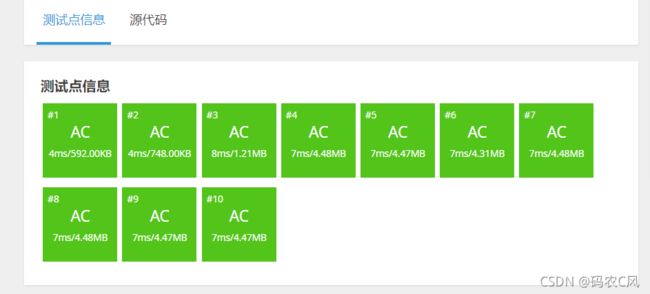
这是我们的1000组数据时输出的结果,执行了104637次才输出结果,而上面的简单递归就输出不了了。
我们先在回顾一下上面的优化过程,我们知道简单递归会有重复执行的麻烦,我们首先是有外部变量辅助记录数据的递归,比如上面的sumva和以前递归里的cnt,之后我们就想能不能够去掉外部变量,之后就使用了两个方法变量dfs1,dfs2就可以了,之后 返回最大的就好了;因为这里我们就知道最优解就两种情况之一。
我们再建立递归的时候就是最开始使用了两个自变量就是lefttime和pos,之后没有sumva就不需要因变量allvalue,所以在同一个pos和lefttime就应该对应相同的,我们就用一个二维数组来记录这两个变量处所对应的值。我们就是使用一个used数组,这个既可以记录它是否使用过,也可以记录数据,当为0时就代表没有用过,就要继续算,从上往下算,然后将值放在里面。
used[lefttime] [pos]表示的是在剩余lefttime时间里采集后pos个草药的最优解(至于为什么是后,就分析代码吧)
记忆化搜索总结
- 不依赖任何的外部变量(就是由不依赖变量变化过来的)
- 答案以返回值的形式存在,不能以参数形式存在,比如我们的allvalue,因为没有外部变量
- 对于同一组参数,返回值相同(就是简单递归的重复点)我们使用dfs来记录最优解
记忆化搜索与动态规划的关系
记忆化搜索就是dp,只是dp是从树的下面开始算起,记忆化还是和递归深搜一样从上面开始搜索,dp的状态就是我们深搜可能重复的点,dp的状态应该就是在剩余lefttime时间里采集后pos个草药的最优解
dp的状态方程也就是我们记忆化搜索的合并
used[lefttime] [pos] = max(used[lefttime] [pos -1], used[lefttime] - time[pos]]] [pos-1]+ value[pos])
这个状态方程就是从记忆化搜索中提出来的,所以记忆化搜索和没有优化的dp的时间复杂度是一样的
所以记忆化搜索就是动态规划,只是表现形式有一点点区别而已,根据记忆化的参数可以得到dp的状态,写出状态转移方程。只是一个从上想,一个从下想
核心思想
它们的核心都是记录可能出现重复的地方的数据,免去重复计算。
所以写记忆化可以从递归开始优化,最好直接有dfs,就是直接用返回值返回答案。
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int alltime = in.nextInt();
int num = in.nextInt();
for(int i = 1;i <= num;i++)//从1开始的,之前写的8皇后是从0开始的
{
time[i] = in.nextInt();
value[i] = in.nextInt();
}
for(int i = 1;i <= num;i++)// i == pos
{
for(int j = alltime;j >= 0;j--)// j == lefttime
{
if(j > time[i])
{
used[i][j] = max(used[i- 1][j], used[i-1][j- time[i]]+ value[i]);
}
else{
used[i][j] = used[i-1][j];//dp是从后往前推,所以这里pos是递减
}
}
}
System.out.println(used[num][alltime]);
}
这就是递推解法,就是由记忆化搜索得到的,只是记忆化是从第一株草药开始,递推是从后一株草药开始,因为我们的记忆化就开始一直都不采,所以得到我们的结果。
再次实践,奇怪的电梯P1135
我们之前写过非记忆化搜索,现在就直接上手记忆化。
public static int strangeLift(int bFloor,int num,int floor)//变化的就是楼层
{//和采药一样,最优解是两子问题最优解之中的最优解,nowcnt为因变量,栈满了,越界
if(used[floor] != 0)
{
return used[floor];
}
if(floor == bFloor)
{
used[floor] = 0;
return used[floor];
}
int dfs1 = 500,dfs2 = 500;
if(floor + code[floor] <= num)
dfs1 = strangeLift(bFloor,num,floor + code[floor]) + 1;
if(floor > code[floor])
{
dfs2 = strangeLift(bFloor,num,floor - code[floor]) + 1;
}
used[floor] = min(dfs1,dfs2);
if(used[floor] == 500)
{
return -1;
}
return used[floor];
}
所以解决递归问题,我们首先是根据题意画出搜索树,找出状态的变化,将自变量写进参数,之后根据子支写出递归语句,优化时就将其外部变量给去除,设置一个数组记录最优解。
记忆化搜索是解决递归问题的一个重要的手段,是必须要掌握的一个知识点。