论文精读--ResNet
ResNet论文
撑起计算机视觉半边天的ResNet【论文精读】_哔哩哔哩_bilibili
Abstract
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers—8× deeper than VGG nets [41] but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions , where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
翻译:
深度神经网络更难训练。我们提出了一个残差学习框架,以简化比以前使用的网络深度大得多的网络的训练。我们明确地将层重新表述为参考层输入的学习残差函数,而不是学习未参考的函数。我们提供了全面的经验证据,表明这些残差网络更容易优化,并且可以从相当大的深度中获得精度。在ImageNet数据集上,我们评估了深度高达152层的残差网络——比VGG网络深度8倍[41],但仍然具有较低的复杂性。这些残差网络的集合在ImageNet测试集上的误差达到3.57%。该结果在ILSVRC 2015分类任务中获得第一名。我们还介绍了100层和1000层的CIFAR-10分析。
表征的深度对于许多视觉识别任务至关重要。仅由于我们的极深表示,我们在COCO对象检测数据集上获得了28%的相对改进。深度残差网络是我们参加ILSVRC & COCO 2015竞赛的基础1,我们还在ImageNet检测、ImageNet定位、COCO检测和COCO分割的任务中获得了第一名。
总结:
提出的残差网络在加深层数时,也保持了较低的计算复杂性,获得了多个任务的第一名
Introduction
Deep convolutional neural networks have led to a series of breakthroughs for image classification. Deep networks naturally integrate low/mid/highlevel features and classifiers in an end-to-end multilayer fashion, and the “levels” of features can be enriched by the number of stacked layers (depth). Recent evidence reveals that network depth is of crucial importance, and the leading results on the challenging ImageNet dataset all exploit “very deep” models, with a depth of sixteen to thirty. Many other nontrivial visual recognition tasks have also greatly benefited from very deep models.
翻译:
深度卷积神经网络在图像分类方面取得了一系列突破。深度网络以端到端的多层方式自然地集成低/中/高级特征和分类器,并且特征的“级别”可以通过堆叠层的数量(深度)来丰富。最近的证据表明网络深度是至关重要的,在具有挑战性的ImageNet数据集上的领先结果都利用了“非常深”模型,深度为16到30。许多其他重要的视觉识别任务也极大地受益于非常深度的模型。
总结:
深度是非常重要的,不同深度的层会得到不同level的特征
Driven by the significance of depth, a question arises: Is learning better networks as easy as stacking more layers? An obstacle to answering this question was the notorious problem of vanishing/exploding gradients, which hamper convergence from the beginning. This problem, however, has been largely addressed by normalized initialization and intermediate normalization layers , which enable networks with tens of layers to start converging for stochastic gradient descent (SGD) with backpropagation.
翻译:
在深度的重要性的驱使下,一个问题出现了:学习更好的网络就像堆叠更多的层一样简单吗?回答这个问题的一个障碍是臭名昭著的梯度消失/爆炸问题,这从一开始就阻碍了收敛。然而,这个问题已经通过规范化初始化层和中间规范化层得到了很大程度的解决,这使得具有数十层的网络能够开始收敛具有反向传播的随机梯度下降(SGD)。
When deeper networks are able to start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly. Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error, as reported in and thoroughly verified by our experiments. Fig. 1 shows a typical example.
翻译:
当更深的网络能够开始收敛时,一个退化问题就暴露出来了:随着网络深度的增加,精度趋于饱和(这可能不足为奇),然后迅速退化。出乎意料的是,这种退化不是由过拟合引起的,在适当深度的模型上添加更多的层会导致更高的训练误差,这一点在我们的实验中得到了充分的证实。图1是一个典型的例子。
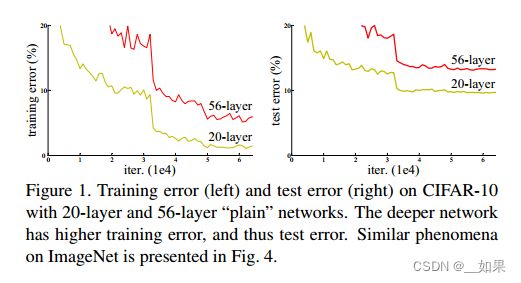
总结:
当层数由20层变为56层时,可以看到不仅是test的loss变大了,train上的loss也比20层的大,说明深层网络会带来精读的衰退,且不是由过拟合引起的
The degradation (of training accuracy) indicates that not all systems are similarly easy to optimize. Let us consider a shallower architecture and its deeper counterpart that adds more layers onto it. There exists a solution by construction to the deeper model: the added layers are identity mapping, and the other layers are copied from the learned shallower model. The existence of this constructed solution indicates that a deeper model should produce no higher training error than its shallower counterpart. But experiments show that our current solvers on hand are unable to find solutions that are comparably good or better than the constructed solution (or unable to do so in feasible time).
翻译:
(训练精度的)退化表明,并非所有系统都同样容易优化。让我们考虑一个较浅的体系结构和它的更深的对应物,它在上面添加了更多的层。通过构造更深的模型存在一个解决方案:添加的层是身份映射,其他层是从学习的较浅模型复制的。这种构造解的存在表明,较深的模型不会比较浅的模型产生更高的训练误差。但实验表明,我们现有的求解器无法找到与构建的解决方案相当或更好的解决方案(或者无法在可行时间内做到这一点)。
总结:
一个浅层网络对应的深层网络理应变得更好(可以学出全1层),但实际上SGD做不到
In this paper, we address the degradation problem by introducing a deep residual learning framework. Instead of hoping each few stacked layers directly fit a desired underlying mapping, we explicitly let these layers fit a residual mapping. Formally, denoting the desired underlying mapping as H(x), we let the stacked nonlinear layers fit another mapping of F(x) := H(x)−x. The original mapping is recast into F(x)+x. We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.
翻译:
在本文中,我们通过引入深度残差学习框架来解决退化问题。我们不是希望每几个堆叠层直接符合期望的底层映射,而是明确地让这些层符合残差映射。形式上,将期望的底层映射表示为H(x),我们让堆叠的非线性层适合F(x)的另一个映射:= H(x) - x。原始映射被重铸为F(x)+x。我们假设优化残差映射比优化原始的、未引用的映射更容易。在极端情况下,如果一个恒等映射是最优的,将残差推至零要比用一堆非线性层拟合一个恒等映射容易得多。

总结:
为了使浅层网络对应的深层网络效果变得更好,让浅层网络基础上增加的网络不再学习H(x),而是学习H(x) - x,也就是学习浅层中学到的东西与真实的东西之间的差异,最后的输出为差异+x
The formulation of F(x) +x can be realized by feedforward neural networks with “shortcut connections” (Fig. 2).
Shortcut connections are those skipping one or more layers. In our case, the shortcut connections simply perform identity mapping, and their outputs are added to the outputs of the stacked layers (Fig. 2). Identity shortcut connections add neither extra parameter nor computational complexity. The entire network can still be trained end-to-end by SGD with backpropagation, and can be easily implemented using common libraries (e.g., Caffe ) without modifying the solvers.
翻译:
F(x) + x的表达式可以通过具有“快捷连接”的前馈神经网络来实现(图2)。
快捷连接是那些跳过一个或多个层的连接。在我们的例子中,快捷连接只是执行身份映射,它们的输出被添加到堆叠层的输出中(图2)。身份快捷连接既不增加额外的参数,也不增加计算复杂度。整个网络仍然可以通过反向传播的SGD进行端到端训练,并且可以使用通用库(例如Caffe)轻松实现,而无需修改求解器。
总结:
+x不会增加任何参数,不会提高计算复杂度,且网络是易于训练的
We present comprehensive experiments on ImageNet to show the degradation problem and evaluate our method. We show that: 1) Our extremely deep residual nets are easy to optimize, but the counterpart “plain” nets (that simply stack layers) exhibit higher training error when the depth increases; 2) Our deep residual nets can easily enjoy accuracy gains from greatly increased depth, producing results substantially better than previous networks.
翻译:
我们在ImageNet上进行了全面的实验,以显示退化问题并评估我们的方法。我们发现:1)我们的极深残差网络很容易优化,但对应的“普通”网络(简单地堆叠层)在深度增加时表现出更高的训练误差;2)我们的深度残差网络可以很容易地从深度大大增加中获得精度增益,产生的结果比以前的网络好得多。
总结:
残差连接打爆简单堆叠
Similar phenomena are also shown on the CIFAR-10 set, suggesting that the optimization difficulties and the effects of our method are not just akin to a particular dataset.We present successfully trained models on this dataset with over 100 layers, and explore models with over 1000 layers.
翻译:
类似的现象也出现在CIFAR-10集上,这表明我们的方法的优化困难和效果并不仅仅类似于特定的数据集。我们在超过100层的数据集上展示了成功训练的模型,并探索了超过1000层的模型。
On the ImageNet classification dataset, we obtain excellent results by extremely deep residual nets. Our 152layer residual net is the deepest network ever presented on ImageNet, while still having lower complexity than VGG nets. Our ensemble has 3.57% top-5 error on the ImageNet test set, and won the 1st place in the ILSVRC 2015 classification competition. The extremely deep representations also have excellent generalization performance on other recognition tasks, and lead us to further win the 1st places on: ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation in ILSVRC & COCO 2015 competitions. This strong evidence shows that the residual learning principle is generic, and we expect that it is applicable in other vision and non-vision problems.
翻译:
在ImageNet分类数据集上,我们使用极深残差网获得了很好的结果。我们的152层残差网络是迄今为止在ImageNet上呈现的最深的网络,但其复杂度仍低于VGG网络。我们的集合在ImageNet测试集上的前5名错误率为3.57%,并在ILSVRC 2015分类大赛中获得第一名。极深表征在其他识别任务上也有出色的泛化性能,并使我们在ILSVRC & COCO 2015竞赛中,在ImageNet检测、ImageNet定位、COCO检测和COCO分割方面进一步获得第一名。这有力地证明了残差学习原理是通用的,我们期望它能适用于其他视觉和非视觉问题。
Related Work
Residual Representations
In image recognition, VLAD is a representation that encodes by the residual vectors with respect to a dictionary, and Fisher Vector can be formulated as a probabilistic version of VLAD. Both of them are powerful shallow representations for image retrieval and classification. For vector quantization, encoding residual vectors is shown to be more effective than encoding original vectors.
In low-level vision and computer graphics, for solving Partial Differential Equations (PDEs), the widely used Multigrid method reformulates the system as subproblems at multiple scales, where each subproblem is responsible for the residual solution between a coarser and a finer scale. An alternative to Multigrid is hierarchical basis preconditioning, which relies on variables that represent residual vectors between two scales. It has been shown that these solvers converge much faster than standard solvers that are unaware of the residual nature of the solutions. These methods suggest that a good reformulation or preconditioning can simplify the optimization.
翻译:
在图像识别中,VLAD是对字典进行残差向量编码的表示,Fisher Vector可以表示为VLAD的概率版本。它们都是图像检索和分类的强大浅层表示。对于矢量量化,残差矢量编码比原始矢量编码更有效。
在低级视觉和计算机图形学中,为了求解偏微分方程(PDEs),广泛使用的Multigrid方法将系统重新表述为多尺度的子问题,其中每个子问题负责粗尺度和细尺度之间的残差解。Multigrid的替代方案是分层基础预处理,它依赖于表示两个尺度之间残差向量的变量。已经证明,这些解算器比不知道解的残差性质的标准解算器收敛得快得多。这些方法表明,良好的重新配方或预处理可以简化优化过程。
总结:
讲述视觉相关方面的残差研究,但是未涉及到机器学习方面,毕竟是发在CVPR上的文章。Residual在机器学习或统计中用得更多,线性模型最早的写法就是不断靠residual迭代的;gradient boosting也是通过残差学习,把一些弱的分类器叠加成一个强的分类器
Shortcut Connections
Practices and theories that lead to shortcut connections have been studied for a long time. An early practice of training multi-layer perceptrons (MLPs) is to add a linear layer connected from the network input to the output. A few intermediate layers are directly connected to auxiliary classifiers for addressing vanishing/exploding gradients. The papers of propose methods for centering layer responses, gradients, and propagated errors, implemented by shortcut connections. An “inception” layer is composed of a shortcut branch and a few deeper branches.
翻译:
导致快捷连接的实践和理论已经研究了很长时间。训练多层感知器(mlp)的早期实践是添加一个连接网络输入和输出的线性层。一些中间层直接连接到辅助分类器,用于寻路消失/爆炸梯度。一些论文提出了通过快捷连接实现层响应、梯度和传播误差居中的方法。一个“启始”层由一个快捷分支和几个更深的分支组成。
Concurrent with our work, “highway networks” present shortcut connections with gating functions.
These gates are data-dependent and have parameters, in contrast to our identity shortcuts that are parameter-free.
When a gated shortcut is “closed” (approaching zero), the layers in highway networks represent non-residual functions. On the contrary, our formulation always learns residual functions; our identity shortcuts are never closed, and all information is always passed through, with additional residual functions to be learned. In addition, high-way networks have not demonstrated accuracy gains with extremely increased depth (e.g., over 100 layers).
翻译:
与我们的工作同时进行的是,“高速公路网络”与门控功能提供了快捷连接。
这些门是数据依赖的,有参数,而我们的身份快捷方式是无参数的。
当一条门控捷径“关闭”(接近零)时,公路网中的层表示非残差函数。相反,我们的公式总是学习残差函数;我们的身份快捷键永远不会关闭,所有的信息总是通过,还有额外的残余函数需要学习。此外,高速公路网络在深度极大增加(例如,超过100层)的情况下,并没有显示出准确性的提高。
总结:
shortcut connections在之前用的也比较多,但之前的工作相对复杂一些,而resnet的加法是最简单的
Deep Residual Learning
Network Architectures
We have tested various plain/residual nets, and have observed consistent phenomena. To provide instances for discussion, we describe two models for ImageNet as follows.
翻译:
我们已经测试了各种平原/残留网,并观察到一致的现象。为了提供讨论的实例,我们如下描述ImageNet的两个模型
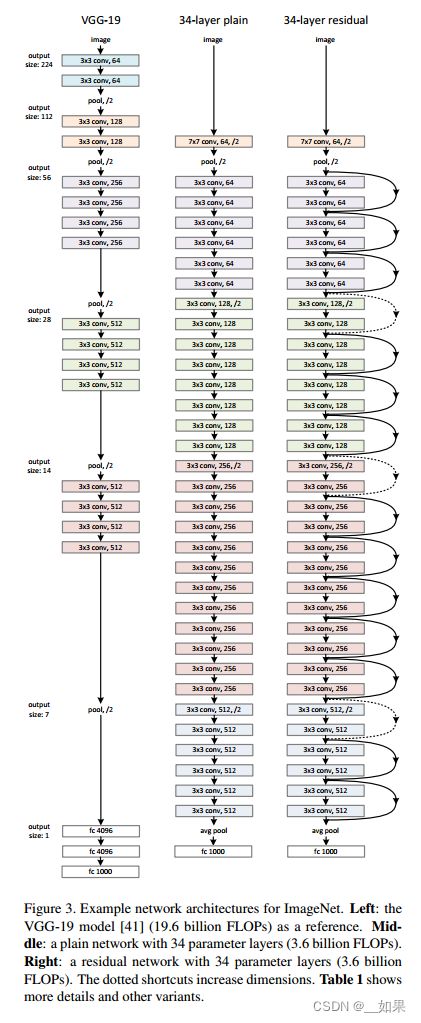
Plain Network
Our plain baselines (Fig. 3, middle) are mainly inspired by the philosophy of VGG nets (Fig. 3, left). The convolutional layers mostly have 3×3 filters and follow two simple design rules: (i) for the same output feature map size, the layers have the same number of filters; and (ii) if the feature map size is halved, the number of filters is doubled so as to preserve the time complexity per layer. We perform downsampling directly by convolutional layers that have a stride of 2. The network ends with a global average pooling layer and a 1000-way fully-connected layer with softmax. The total number of weighted layers is 34 in Fig. 3 (middle).
It is worth noticing that our model has fewer filters and lower complexity than VGG nets (Fig. 3, left). Our 34layer baseline has 3.6 billion FLOPs (multiply-adds), which is only 18% of VGG-19 (19.6 billion FLOPs).
翻译:
我们的普通基线(图3,中间)主要受到VGG网原理的启发(图3,左)。卷积层大多具有3×3滤波器,并遵循两个简单的设计规则:(i)对于相同的输出特征图大小,各层具有相同数量的滤波器;(ii)如果特征图大小减半,则滤波器的数量增加一倍,以保持每层的时间复杂度。我们通过步长为2的卷积层直接执行下采样。网络以一个全局平均池化层和一个带有softmax的1000路全连接层结束。图3(中)加权层总数为34层。
值得注意的是,我们的模型比VGG网络具有更少的过滤器和更低的复杂性(图3,左)。我们的34层基线有36亿FLOPs(乘加),仅为VGG-19(196亿FLOPs)的18%。
Residual Network
Based on the above plain network, we insert shortcut connections (Fig. 3, right) which turn the network into its counterpart residual version. The identity shortcuts (Eqn.(1)) can be directly used when the input and output are of the same dimensions (solid line shortcuts in Fig. 3). When the dimensions increase (dotted line shortcuts in Fig. 3), we consider two options: (A) The shortcut still performs identity mapping, with extra zero entries padded for increasing dimensions. This option introduces no extra parameter; (B) The projection shortcut in Eqn.(2) is used to match dimensions (done by 1×1 convolutions). For both options, when the shortcuts go across feature maps of two sizes, they are performed with a stride of 2.
翻译:
在上述平面网络的基础上,我们插入快捷连接(图3,右),将网络转换为对应的残差版本。当输入和输出维度相同时(图3中的实线快捷方式),可以直接使用标识快捷方式(Eqn.(1))。当维度增加时(图3中的虚线快捷方式),我们考虑两种选择:(A)快捷方式仍然执行标识映射,增加维度时填充额外的零项。这个选项不引入额外的参数;(B) Eqn.(2)中的投影快捷方式用于匹配维度(通过1×1卷积完成)。对于这两个选项,当快捷键跨越两个大小的特征映射时,它们的步幅为2。
总结:
如果我们把一个输出通道数翻两倍,那么输入的高和宽通常会被减半。所以在用1x1卷积时,同样会使步幅为2,使高宽和通道上都能匹配上
Implementation
Our implementation for ImageNet follows the practice in [21, 41]. The image is resized with its shorter side randomly sampled in [256; 480] for scale augmentation [41].
A 224×224 crop is randomly sampled from an image or its horizontal flip, with the per-pixel mean subtracted [21]. The standard color augmentation in [21] is used. We adopt batch normalization (BN) [16] right after each convolution and before activation, following [16]. We initialize the weights as in [13] and train all plain/residual nets from scratch. We use SGD with a mini-batch size of 256. The learning rate starts from 0.1 and is divided by 10 when the error plateaus, and the models are trained for up to 60 × 104 iterations. We use a weight decay of 0.0001 and a momentum of 0.9. We do not use dropout [14], following the practice in [16].
In testing, for comparison studies we adopt the standard 10-crop testing [21]. For best results, we adopt the fullyconvolutional form as in [41, 13], and average the scores at multiple scales (images are resized such that the shorter side is in f224; 256; 384; 480; 640g).
翻译:
我们对ImageNet的实现遵循[21,41]中的实践。在[256]中随机采样图像的短边,重新调整图像大小[256; 480]用于扩大规模。
从图像或其水平翻转中随机采样224×224裁剪,并减去每像素平均值[21]。使用[21]中的标准颜色增强。我们在每次卷积之后和激活之前采用批归一化(BN)[16]。我们像[13]中那样初始化权重,并从头开始训练所有的plain/residual网络。我们使用SGD的小批量大小为256。学习率从0.1开始,当误差趋于平稳时除以10,模型的训练次数可达60 × 104次。我们使用0.0001的权重衰减和0.9的动量。遵循文献[16]的做法,我们没有使用dropout[14]。
在测试中,我们采用标准的10种作物测试进行比较研究[21]。为了获得最佳效果,我们采用了[41,13]中的全卷积形式,并在多个尺度上平均得分(图像被调整大小,使较短的一边为{224;256;384;480;640})。
总结:
把短边随机地采样到256、480,随机的好处是在剪裁成224x224使随机性多一点;测试时也随机抽取10个
介绍了ResNet的实现细节
Experiments
ImageNet Classification
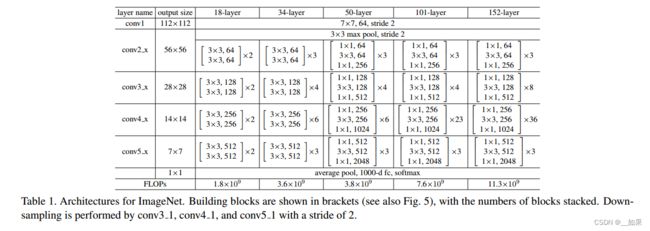
不同深度网络结构比较,从50层开始每个残差块中多一个1x1的卷积
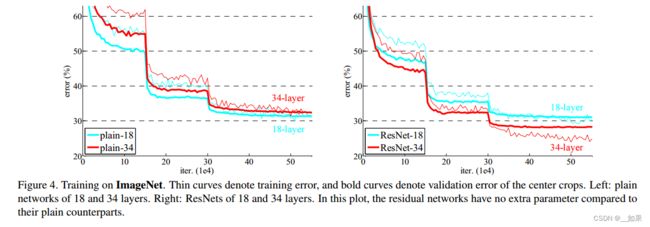
可以看出有残差连接收敛会快一些
断崖式下降是因为 lr*0.1
Identity vs. Projection Shortcuts
We have shown that parameter-free, identity shortcuts help with training. Next we investigate projection shortcuts (Eqn.(2)). In Table 3 we compare three options: (A) zero-padding shortcuts are used for increasing dimensions, and all shortcuts are parameterfree (the same as Table 2 and Fig. 4 right); (B) projection shortcuts are used for increasing dimensions, and other shortcuts are identity; and (C) all shortcuts are projections.
Table 3 shows that all three options are considerably better than the plain counterpart. B is slightly better than A. We argue that this is because the zero-padded dimensions in A indeed have no residual learning. C is marginally better than B, and we attribute this to the extra parameters introduced by many (thirteen) projection shortcuts. But the small differences among A/B/C indicate that projection shortcuts are not essential for addressing the degradation problem. So we do not use option C in the rest of this paper, to reduce memory/time complexity and model sizes. Identity shortcuts are particularly important for not increasing the complexity of the bottleneck architectures that are introduced below.
翻译:
我们已经证明,无参数、标识快捷方式有助于训练。接下来我们研究投影捷径(Eqn.(2))。在表3中,我们比较了三种选项:(A)零填充快捷方式用于增加维度,并且所有快捷方式都是无参数的(与表2和图4右相同);(B)投影快捷键用于增加维数,其他快捷键为恒等;(C)所有的捷径都是投影。
表3显示这三个选项都比普通选项好得多。B略好于A,我们认为这是因为A中的零填充维度确实没有残差学习。C略好于B,我们将其归因于许多(13个)投影捷径引入的额外参数。但A/B/C之间的微小差异表明,投影捷径对于解决退化问题并非必不可少。因此,我们在本文的其余部分不使用选项C,以减少内存/时间复杂性和模型大小。标识快捷方式对于避免增加下面介绍的瓶颈体系结构的复杂性尤为重要。

总结:
介绍当输入输出形状不同时如何做残差连接:填零、投影、所有连接都做投影(输入输出一样时仍可用1x1卷积做一次投影)
Deeper Bottleneck Architectures
Next we describe our deeper nets for ImageNet. Because of concerns on the training time that we can afford, we modify the building block as a bottleneck design4 . For each residual function F, we use a stack of 3 layers instead of 2 (Fig. 5). The three layers are 1×1, 3×3, and 1×1 convolutions, where the 1×1 layers are responsible for reducing and then increasing (restoring) dimensions, leaving the 3×3 layer a bottleneck with smaller input/output dimensions. Fig. 5 shows an example, where both designs have similar time complexity.
翻译:
接下来我们描述ImageNet的深层网络。由于考虑到我们所能负担的培训时间,我们将构建块修改为瓶颈设计4。对于每个残差函数F,我们使用3层而不是2层的堆栈(图5)。这三层是1×1, 3×3和1×1卷积,其中1×1层负责减少然后增加(恢复)维度,使3×3层成为输入/输出维度较小的瓶颈。图5给出了一个例子,其中两种设计具有相似的时间复杂度。
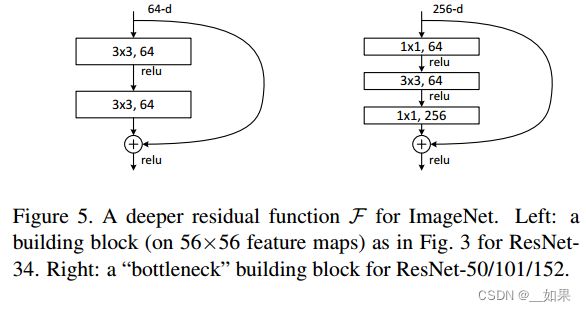
总结:
Resnet到50层及以上时,会引入一个bottleneck的design,利用1x1卷积进行降维和升维,因此计算复杂度不会因为加深而改变
从表一中也可以看出,ResNet34和ResNet50的计算量相差不大
CIFAR-10 and Analysis
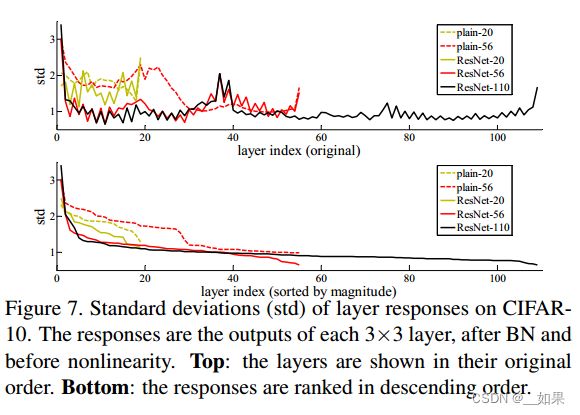
可以看出残差连接的即使模型很深,即出现大量无用层时,能够保持训练的精度,因为后面的层可以几乎练为1