数据挖掘实战-基于机器学习的电商文本分类模型

♂️ 个人主页:@艾派森的个人主页
✍作者简介:Python学习者
希望大家多多支持,我们一起进步!
如果文章对你有帮助的话,
欢迎评论 点赞 收藏 加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验步骤
4.1数据探索
4.2数据预处理
4.3文本归一化
4.4特征工程
4.5训练模型
1.项目背景
随着电子商务的蓬勃发展,电商平台上产生了海量的文本数据,包括商品描述、用户评价、客服对话等。这些文本数据包含了丰富的信息,对于电商企业而言,能够充分挖掘这些信息将有助于提升用户体验、优化产品推荐、改进客户服务等方面。然而,由于文本数据的复杂性和庞大数量,传统的人工处理方式已经难以满足需求,因此利用机器学习技术对电商文本进行自动分类成为一项具有重要意义的研究任务。
电商文本分类模型的研究对于实现自动化、智能化的电商运营管理具有重要意义。通过将文本数据划分到不同的类别,可以实现对商品的自动分类、用户评价的情感分析、客户问题的自动解答等应用,为电商企业提供更高效、精准的运营决策支持。
在实际应用中,电商文本数据的特点包括语言风格多样、信息噪声较大、时效性强等,传统的基于规则的文本处理方法难以应对这些挑战。因此,利用机器学习技术,特别是深度学习方法,对电商文本进行自动分类成为一种更为有效的解决方案。通过构建和训练电商文本分类模型,可以更好地处理大规模、高维度的文本数据,从而提高分类的准确性和效率。
2.数据集介绍
数据集来源于Kaggle,原始数据集共有50425条,2个变量,变量解释如下:
label:文本的标签类型。
text:文本内容。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验步骤
4.1数据探索
## 导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
import spacy
nlp = spacy.load("en_core_web_lg")
# 加载数据
data = pd.read_csv('ecommerceDataset.csv',header=None)
data.columns =['label','text']
data.head()
统计缺失值
data.isnull().sum()
统计重复值
data.duplicated().sum()
数据描述性统计
data.describe()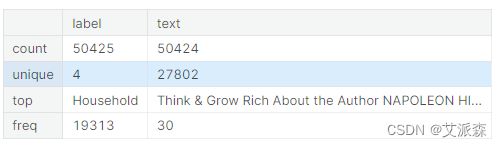
4.2数据预处理
# 删除缺失值
data.dropna(inplace=True)
# 删除重复值
data.drop_duplicates(inplace=True)## 标签在数据集中的分布
sns.countplot(x='label',data=data,palette='Blues')
plt.xlabel(' ')
plt.ylabel('Count')
plt.title('Target Distribution')
plt.show()
4.3文本归一化
文本归一化:它是为了在各种NLP任务中使用而对文本进行清理和预处理的过程。
过程包括几种技术,它们是:
- 情况下归一化
- 标点符号删除
- 停止词删除
- 阻止/词元化
- 标记
- 将缩写和同义词转换为其完整形式
每种技术都有其优点(降低维数,加快过程)和缺点(即信息丢失)。
## 删除标点符号
import string
def remove_punct(text):
punctuations =string.punctuation
mytokens = ''.join(word for word in text if word not in punctuations)
return mytokens## 删除停用词
from spacy.lang.en.stop_words import STOP_WORDS
def remove_stopwords(text):
stop_words = spacy.lang.en.stop_words.STOP_WORDS
mytokens = [word for word in text if word not in stop_words]
return mytokens## 标记化+词形化
nlp.max_length = 19461259
def tokenization(text):
token = nlp(text)
## lemma
token = [word.lemma_ for word in token]
## convert tokens into lower case
token = [ word.lower() for word in token]
return tokendef text_norm(text):
punct_text = remove_punct(text)
tokens = tokenization(punct_text)
final_tokens = remove_stopwords(tokens)
return final_tokens4.4特征工程
在NLP中,特征工程涉及将文本数据转换为数字特征,以便将它们提供给ML模型。
技术:
- N-grams[有助于捕获上下文并有助于提高对模型的文本理解]
- 词类
- 命名实体识别
- 词袋[计数矢量器]
- TF-IDF
- 高级模型的词嵌入
每个技术都是基于任务需求使用的
- 词性标注、NER、解析——用于了解语言的结构
- CV,TF-IDF——有一个很大的语料库,想把它们简化成更少的单词
- 单词嵌入——了解语言的语义
## CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
bow_vectorizer = CountVectorizer(tokenizer=text_norm,max_df=0.9,min_df=2,ngram_range=(1,1))
## TF-IDF Vectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tf_idf = TfidfVectorizer(min_df=2,max_df=0.90,tokenizer=text_norm,ngram_range=(1,1))4.5训练模型
拆分数据集
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,ConfusionMatrixDisplay,confusion_matrix
# train:test = 70:30
X = data['text']
y = data['label']
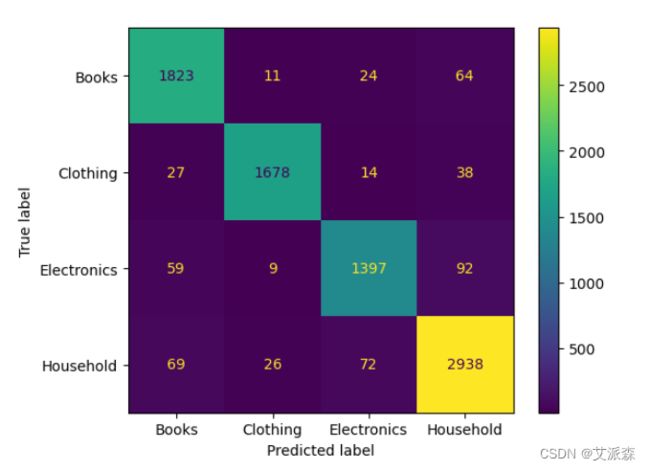
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=7)print("Count Vectorizer + Logistic Regression \n\n ")
## 使用Count Vectorizer创建管道
pipe_bow = Pipeline([('vectorizer', bow_vectorizer),
('classifier', LogisticRegression())])
## 拟合数据
pipe_bow.fit(X_train,y_train)
y_pred_bow = pipe_bow.predict(X_test)
print(classification_report(y_test,y_pred_bow))
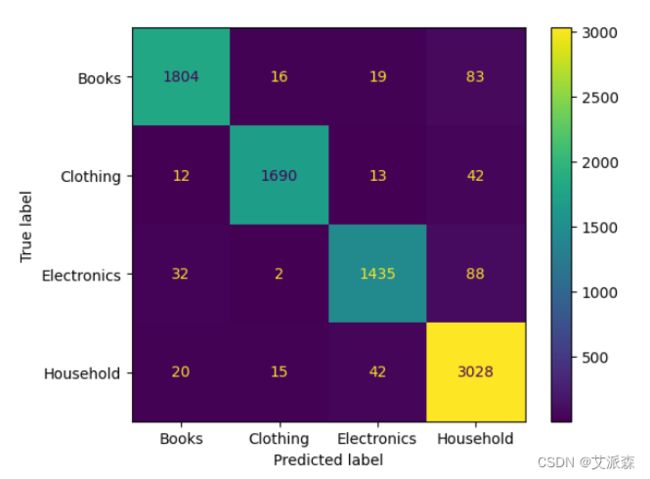
ConfusionMatrixDisplay(confusion_matrix(y_test,y_pred_bow),display_labels=['Books','Clothing','Electronics','Household']).plot()
print("TF_IDF + Logistic Regression \n\n ")
## 使用TF-IDF创建一个管道
pipe_tf = Pipeline([
('vectorizer', tf_idf),
('classifier', LogisticRegression())])
## 拟合数据
pipe_tf.fit(X_train,y_train)
y_pred_tf = pipe_tf.predict(X_test)
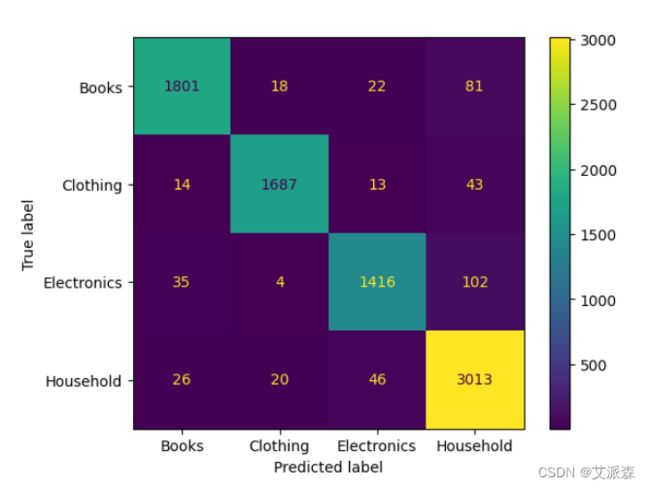
print(classification_report(y_test,y_pred_tf))
ConfusionMatrixDisplay(confusion_matrix(y_test,y_pred_tf),display_labels=['Books','Clothing','Electronics','Household']).plot()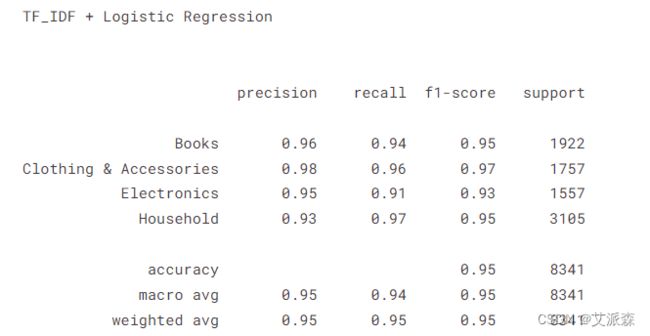
print("TF-IDF + SVM \n\n")
pipe_tf_svm = Pipeline([
('vectorizer', tf_idf),
('classifier', SVC())])
# fit
pipe_tf_svm.fit(X_train,y_train)
y_pred_svm = pipe_tf_svm.predict(X_test)
print(classification_report(y_test,y_pred_svm))
ConfusionMatrixDisplay(confusion_matrix(y_test,y_pred_svm),display_labels=['Books','Clothing','Electronics','Household']).plot()
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
资料获取,更多粉丝福利,关注下方公众号获取
