Python实战:通过微信小程序,获取Manner Coffee全国门店信息
有公众号读者在后台提问,想要上海 manner 门店信息。
查找数据源
首先常规思路,先去 manner 官网找数据入口,发现只有门店的名称,没有其他信息,字段比较单薄。
其次,官网的门店数据没有及时更新,一些新开的店没有录入。

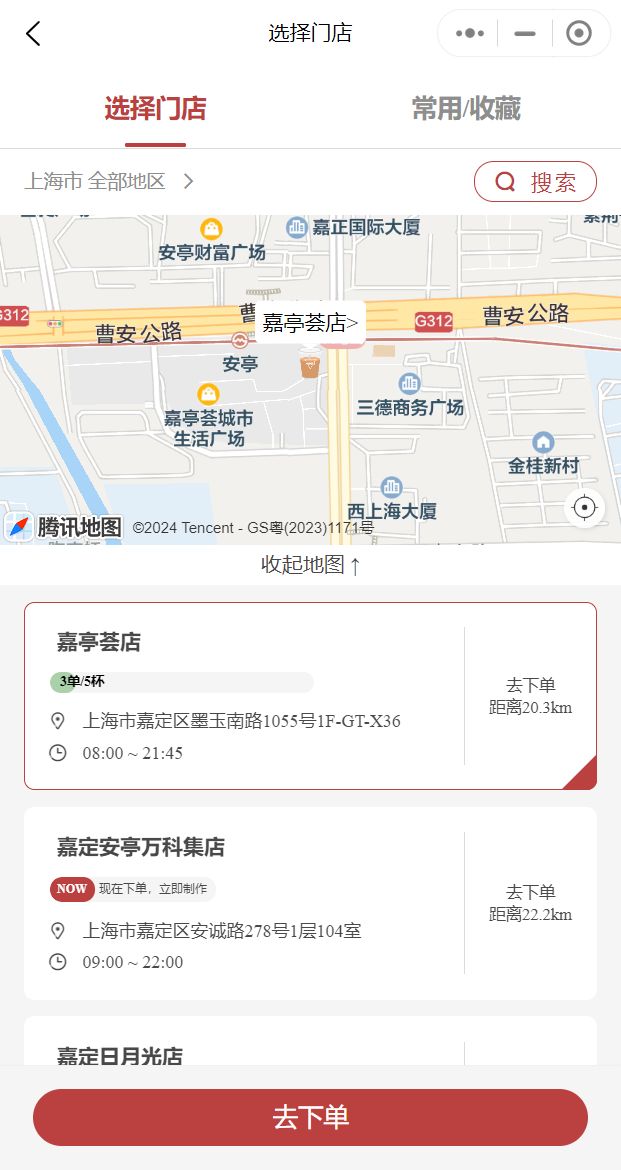
换个思路,去 MannerCoffee 点单小程序找一下数据,小程序截图如下,显示了门店名称、地址、营业时间等信息。
获取数据
借助 Reqable 或 Fiddler、Charles 等抓包工具,抓取小程序的数据。本文使用的是 Reqable 软件。
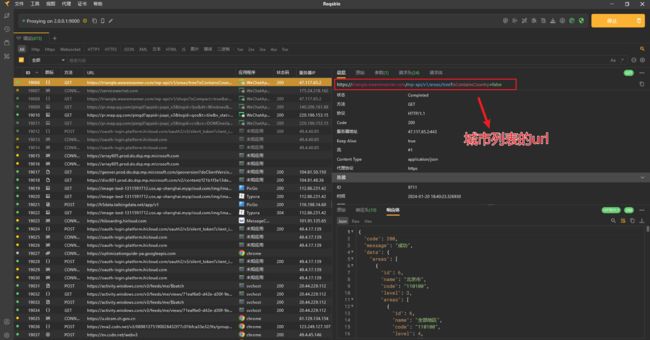
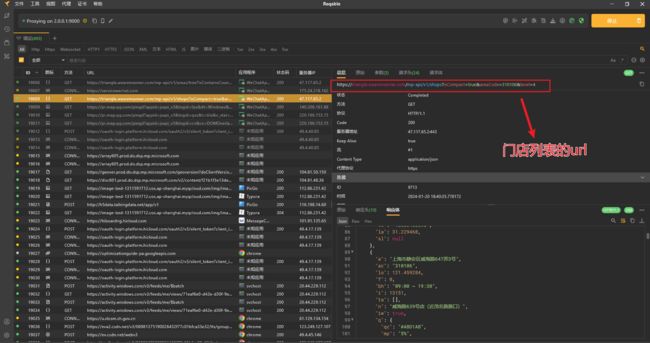
登录电脑端微信,打开 MannerCoffee 小程序,切换不同城市的页面,在 Reqable 中抓到了城市列表 url 和门店列表 url。
获取城市列表
通过抓包工具,获取到城市 url 地址和响应体 response,response 的内容是城市列表。
城市 url 为:https://triangle.wearemanner.com/mp-api/v1/areas/tree?isContainsCountry=false
水平不够,用 Python 的 request 库没能直接爬到数据,可能是小程序数据加密了。有大神会的可以教教我。
先用手工方式,获取到的城市列表保存为 manner_city.json 文件。
解析城市列表
解析保存的 manner_city.json 文件,将所有字段展开,保存为 manner_city.xlsx 文件
import pandas as pd
if __name__ == '__main__':
df = pd.read_json("manner_city.json")
df = pd.json_normalize(df['data']['areas'], meta=['id', 'name', 'code', 'level', 'ab', 'py'], record_path='areas',
record_prefix='areas.',
# meta_prefix='data->',
errors='ignore')
df.to_excel(f"manner_city.xlsx", index=False)
print("保存完成!")
解析后的 manner_city.xlsx 文件如下:


获取门店
类似的,通过抓包工具,获取到门店 url 地址和响应体 response,response 的内容是门店列表。
url 是下面的格式,只有areaCode是变化的参数,其他参数一样,可以方便的构造 url。
https://triangle.wearemanner.com/mp-api/v1/shops?isCompact=true&areaCode=320200&level=4
遇到相同的问题,用 Python 的 request 库没能直接爬到数据,有大神会的可以教教我。
先用手工方式,获取到的门店列表保存为 shanghai_shop.json 文件。
解析门店
解析保存的 shanghai_shop.json 文件,将所有字段展开,保存为 shanghai_shop.xlsx 文件。
门店包含 id、城市编码、门店名称、地址、经纬度、营业时间、是否还在营业、联系电话等字段数据。
import pandas as pd
if __name__ == '__main__':
df = pd.read_json("shanghai_shop.json")
df = pd.json_normalize(df['data'], errors='ignore')
# 输出原始的列名
print(df.columns)
# 列重新排序
df = df.loc[:, ['ac', 'i', 'n', 'a', 'te', 'lo', 'la', 'iw', 'bh', 'sl', 'f',
'q.qc', 'q.mp', 'q.oc', 'q.mc', 'q.wt', 'ta']]
# 部分列重命名
df = df.rename(columns={'a': 'address',
'te': 'telephone',
'ac': 'area_code',
'lo': 'lon',
'la': 'lat',
'n': 'name',
'bh': 'business_hours',
'iw': 'is_work', })
# 输出重新排序,重命名后的列
print(df.columns)
df.to_excel(f"shanghai_shop.xlsx", index=False)
print("保存完成!")


编写脚本
在抓包工具内编写脚本,切换城市,可以将每个城市的门店保存到本地 json 文件。


合并json
通过切换城市,抓包工具的脚本,已经将每个城市的门店 json 保存到本地,通过 Python 代码将这些 json 文件合并,并生成一个 excel 文件。
import pandas as pd
import os
# file_dir 为文件夹路径,修改为你自己的
file_dir = 'C:/Users/stjn_hx/Desktop/百度地图/response/'
file_list = os.listdir(file_dir)
new_list = pd.DataFrame()
for file in file_list:
if file.endswith(".json"):
try:
data = pd.json_normalize(pd.read_json(file_dir + file)['data'])
new_list = pd.concat([new_list, pd.DataFrame(data)])
print("正在合并", file)
except:
print("合并失败", file)
# 将 DataFrame 保存为 excel 文件
# 去除重复数据
new_list = new_list.drop_duplicates('i', inplace=False)
# 输出原始的列名
print(new_list.columns)
# 列重新排序
new_list = new_list.loc[:, ['i', 'n', 'a', 'ac', 'te', 'lo', 'la', 'iw', 'bh', 'sl', 'f',
'q.qc', 'q.mp', 'q.oc', 'q.mc', 'q.wt', 'ta']]
# 部分列重命名
new_list = new_list.rename(columns={'i': 'id',
'a': 'address',
'te': 'telephone',
'ac': 'area_code',
'lo': 'lon',
'la': 'lat',
'n': 'name',
'bh': 'business_hours',
'iw': 'is_work', })
# 输出重新排序,重命名后的列
print(new_list.columns)
num = new_list.shape[0]
new_list.to_excel(f'manner coffee全国门店-{num}个.xlsx', index=False)
print("合并完成!")



这个数据是下午获取到的,从is_work字段来看,全国有 1107 个门店,其中有 911 家营业,剩下的 196 家是休息状态,是不是关店了?
数据分析
今天的重点是获取数据,数据分析可以参考之前的文章,自己尝试吧。
参考文章
地图标记
由于获取到的门店有经纬度信息,还可以在地图上对门店进行标记,生成可视化地图。
在线地图工具https://map.citylabmap.com/
在地图网站,上传门店的 csv 文件,可以生成如下的热力图。

也可以参考之前的文章,使用pyecharts库生成地图。
参考文章
辅助信息
MannerCoffee 公众号发布过的一些文章,可以辅助验证我们获取数据的准确性。
MannerCoffee 公众号 2023 年 10 月 30 日数据显示“MANNER 全国直营第 1000 家,正式开业”。
MannerCoffee 公众号 2023 年 10 月 31 日数据显示“全国第 1100 家直营店,马上来了”。
MannerCoffee 公众号 2023 年 11 月 30 日数据显示“全国直营 1200 家门店,马上来了”。
MannerCoffee 公众号 2023 年 12 月 31 日数据显示“2023 年,MANNER 突破 1200 家全国直营店”。
2024 年还计划发展到全国 2000+店,可见开店速度非常快。
以上数据和本文获取到的数据比对,可能是公众号统计口径不一致,将闭店的数据也统计进门店总数了。也可能是我手动刷新城市,有漏掉的城市没保存下来。




难点:
通过抓包工具,找到了小程序的 url,但是在浏览器里却打不开 url,没能获取信息。
由于数据量小,自己手动十几次抓到了每个 url 的 response,数据量大的情况就不能再手动了。
大神看到这里,有什么好办法,可以教教我。
本文首发在“程序员coding”公众号,欢迎关注与我一起交流学习。
本文数据集已经上传到公众号,后台回复“Manner Coffee”可以自取。