【MySQL进阶】SQL优化
文章目录
- SQL 优化
-
- 主键优化
-
- 数据组织方式
- 页分裂
- 页合并
- 主键设计原则
- insert优化
- order by优化
- group by优化
- limit优化
- count优化
SQL 优化
主键优化
数据组织方式
- 在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表

- 在InnoDB引擎中,数据行是记录在逻辑结构 page 页中的,而每一个页的大小是固定的,默认16K。 那也就意味着, 一个页中所存储的行也是有限的,如果插入的数据行row在该页存储不小,将会存储 到下一个页中,页与页之间会通过指针连接。
页分裂
每个页的大小书固定的,页可以为空,也可以填充一半,也可以填充100%,每个页包含了2-N行数据(如果一行数据过大,会行 溢出),根据主键排列
- 按主键自增的方式插入数据。
①. 从磁盘中申请页, 主键顺序插入
②. 第一个页没有满,继续往第一页插入
③. 当第一个也写满之后,再写入第二个页,页与页之间会通过指针连接

④. 当第二页写满了,再往第三页写入
- 主键乱序插入效果
①. 假如1#,2#页都已经写满了,存放了如图所示的数据
②. 此时再插入id为50的记录,就会发生页分裂。因为需要顺序存储,按照顺序,应该存储在47之后,
但是该页已经满了,则需要新申请一个3#页,将1#页后一半的数据,移动到3#页,然后在3#页,插入50。
重新设置链表指针
上述现象就叫做页分裂,是比较耗费性能的。
页合并
假如表中已有数据的索引结构(叶子节点)如下:
当我们对已有数据进行删除时,具体的效果如下:
当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间
变得允许被其他记录声明使用。
当页中删除的记录达到 MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前
或后)看看是否可以将两个页合并以优化空间使用。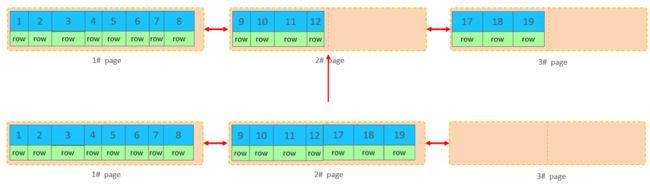
上述现象就叫做页合并
主键设计原则
- 满足业务需求的情况下,尽量降低主键的长度。
- 插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键。
- 尽量不要使用UUID做主键或者是其他自然主键,如身份证号。
- 业务操作时,避免对主键的修改。
insert优化
如果我们需要一次性往数据库表中插入多条记录,可以从以下四个方面进行优化
- 优化方案一:批量插入数据
- 假如一条一条的插入数据,每次插入数据,都需要建立连接,很费时间
- 优化方案二:手动控制事务
- MySQL默认执行一条语句提交一次事务,耗时
- 优化方案三:主键顺序插入
- 因为 InnoDB 类型的表是按照主键的顺序保存的,所以将导入的数据按照主键的顺序排列,可以有效的提高导入数据的效率。
- 主键是否连续对性能影响不大,只要是递增的就可以,比如雪花算法产生的 ID 不是连续的,但是是递增的,因为递增可以让主键索引尽量地保持顺序插入,避免了页分裂,因此索引更紧凑。
- 优化方案四:关闭唯一性校验。
- 在导入数据前执行 SET UNIQUE_CHECKS=0,关闭唯一性校验;导入结束后执行 SET UNIQUE_CHECKS=1,恢复唯一性校验,可以提高导入的效率。
如果一次性需要插入大批量数据(比如: 几百万的记录),使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令进行插入。操作如下:
-- 客户端连接服务端时,加上参数 -–local-infile
mysql –-local-infile -u root -p
-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
-- 执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/sql1.log' into table tb_user fields terminated by ',' lines terminated by '\n' ;

order by优化
MySQL的排序,有两种方式:
- Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。
- Using index : 通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高。
对于以上的两种排序方式,Using index的性能高,而Using filesort的性能低,我们在优化排序操作时,尽量要优化为 Using index。
测试:目前tb_user只有一个主键索引
- 执行排序SQL
explain select id,age,phone from tb_user order by age, phone
由于age、phone都没有索引,可以看到为Using filesort,需要到内存中重新排序。
- 创建索引
create index idx_user_age_phone_aa on tb_user(age,phone); - 创建索引后,根据age, phone进行升序排序
explain select id,age,phone from tb_user order by age,phone; 
可以看到建立索引之后,再次进行排序查询,就由原来的Using filesort, 变为了 Using index,性能
就是比较高的了。(仍然遵循最左前缀原则)
优化注意以下几点:
A. 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
B. 尽量使用覆盖索引。
C. 多字段排序, 一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)。
- 若索引两个字段都是升序,则排序时两字段升序或降序都会Using index。
- 索引字段的排序规则需要和order by后面字段的排序规则一样。
D. 如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小
group by优化
GROUP BY 也会进行排序操作,与 ORDER BY 相比,GROUP BY 主要只是多了排序之后的分组操作,所以在 GROUP BY 的实现过程中,与 ORDER BY 一样也可以利用到索引
- 分组查询:
DROP INDEX idx_emp_age_salary ON emp;
EXPLAIN SELECT age,COUNT(*) FROM emp GROUP BY age;
 Using temporary:表示 MySQL 需要使用临时表(不是 sort buffer)来存储结果集,常见于排序和分组查询
Using temporary:表示 MySQL 需要使用临时表(不是 sort buffer)来存储结果集,常见于排序和分组查询
- 查询包含 GROUP BY 但是用户想要避免排序结果的消耗, 则可以执行 ORDER BY NULL 禁止排序:
EXPLAIN SELECT age,COUNT(*) FROM emp GROUP BY age ORDER BY NULL;
- 创建索引:索引本身有序,不需要临时表,也不需要再额外排序
CREATE INDEX idx_emp_age_salary ON emp(age, salary); 
- 数据量很大时,使用 SQL_BIG_RESULT 提示优化器直接使用直接用磁盘临时表
limit优化
一个常见的问题是 LIMIT 200000,10,此时需要 MySQL 扫描前 200010 记录并进行排序,仅仅返回 200000 - 200010 之间的记录,其他记录丢弃,查询排序的代价非常大
- 分页查询:
EXPLAIN SELECT * FROM tb_user_1 LIMIT 200000,10;
- 优化方式一:内连接查询,在索引列 id 上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容(id是索引列,查询速度较快)
EXPLAIN SELECT * FROM tb_user_1 t,(SELECT id FROM tb_user_1 ORDER BY id LIMIT 200000,10) a WHERE t.id = a.id;
- 优化方式二:方案适用于主键自增的表,可以把 LIMIT 查询转换成某个位置的查询
EXPLAIN SELECT * FROM tb_user_1 WHERE id > 200000 LIMIT 10; -- 写法 1
EXPLAIN SELECT * FROM tb_user_1 WHERE id BETWEEN 200000 and 200010; -- 写法 2

count优化
在不同的 MySQL 引擎中,count(*) 有不同的实现方式:
- MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高,但不支持事务
- InnoDB 表执行 count(*) 会遍历全表,虽然结果准确,但会导致性能问题
解决方案:
- 计数保存在 Redis 中,但是更新 MySQL 和 Redis 的操作不是原子的,会存在数据一致性的问题
- 计数直接放到数据库里单独的一张计数表中,利用事务解决计数精确问题:
 会话 B 的读操作在 T3 执行的,这时更新事务还没有提交,所以计数值加 1 这个操作对会话 B 还不可见,因此会话 B 查询的计数值和最近 100 条记录,返回的结果逻辑上就是一致的并发系统性能的角度考虑,应该先插入操作记录再更新计数表,因为更新计数表涉及到行锁的竞争,先插入再更新能最大程度地减少事务之间的锁等待,提升并发度
会话 B 的读操作在 T3 执行的,这时更新事务还没有提交,所以计数值加 1 这个操作对会话 B 还不可见,因此会话 B 查询的计数值和最近 100 条记录,返回的结果逻辑上就是一致的并发系统性能的角度考虑,应该先插入操作记录再更新计数表,因为更新计数表涉及到行锁的竞争,先插入再更新能最大程度地减少事务之间的锁等待,提升并发度
count 函数的按照效率排序:count(字段) < count(主键id) < count(1) ≈ count(),所以建议尽量使用 count()
- count(主键 id):InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来返回给 Server 层,Server直接就按行累加(主键不可能为空)
- count(1):InnoDB 引擎遍历整张表但不取值,Server 层对于返回的每一行,放一个数字 1 进去,直接按行累加
- count(字段):如果这个字段是定义为 not null 的话,一行行地从记录里面读出这个字段,直接按行累加;如果这个字段定义允许为 null,那么执行的时候,还要把值取出来,再判断一下,不是 null 才累加。
- count(*):不取值,按行累加。
## update优化 `update course set name = 'javaEE' where name = 'jack' ; `
- 如果name是索引字段,在该行数据上添加行锁。其他线程可以修改其他行数据。
- 如果name不是索引字段或者索引失效了,则直接在该张表上添加表锁。其他线程不可以修改其他行数据。
- 所以where后面的字段尽量添加索引。