深度学习|RCNN&Fast-RCNN
1.RCNN
2014年提出R-CNN网络,该网络不再使用暴力穷举的方法,而是使用候选区域方法(region proposal method)创建目标检测的区域来完成目标检测的任务,R-CNN是以深度神经网络为基础的目标检测的模型 ,以R-CNN为基点,后续的Fast R-CNN、Faster R-CNN模型都延续了这种目标检测思路。
1.1RCNN算法流程
RCNN的流程如下图所示:
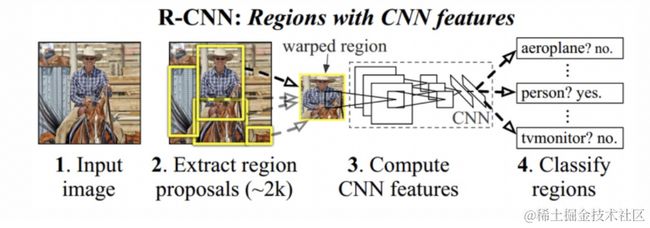
步骤是:
- 候选区域生成:使用选择性搜索(Selective Search)的方法找出图片中可能存在目标的侯选区域
- CNN网络提取特征:选取预训练卷积神经网网络(AlexNet或VGG)用于进行特征提取。
- 目标分类:训练支持向量机(SVM)来辨别目标物体和背景,对每个类别,都要训练一个二元SVM。
- 目标定位:训练一个线性回归模型,为每个辨识到的物体生成更精确的边界框。
1.1.1 候选区域生成
选择性搜索(SelectiveSearch,SS)中,使用语义分割的方法,它通过在像素级的标注,把颜色、边界、纹理等信息作为合并条件,多尺度的综合采样方法,划分出一系列的区域,这些区域要远远少于传统的滑动窗口的穷举法产生的候选区域。

SelectiveSearch在一张图片上提取出来约2000个侯选区域,需要注意的是这些候选区域的长宽不固定。 而使用CNN提取候选区域的特征向量,需要接受固定长度的输入,所以需要对候选区域做一些尺寸上的修改。
1.1.2CNN网络提取特征
采用预训练模型(AlexNet或VGG)在生成的候选区域上进行特征提取,将提取好的特征保存在磁盘中,用于后续步骤的分类和回归。

1.全连接层的输入数据的尺寸是固定的,因此在将候选区域送入CNN网络中时,需进行裁剪或变形为固定的尺寸,在进行特征提取。
2.预训练模型在ImageNet数据集上获得,最后的全连接层是1000,在这里我们需要将其改为N+1(N为目标类别的数目,例如VOC数据集中N=20,coco数据集中N=80,1是加一个背景)后,进行微调即可。
3.利用微调后的CNN网络,提取每一个候选区域的特征,获取一个4096维的特征,一幅图像就是2000x4096维特征存储到磁盘中。
1.1.3目标分类(SVM)
假设我们要检测猫狗两个类别,那我们需要训练猫和狗两个不同类别的SVM分类器,然后使用训练好的分类器对一幅图像中2000个候选区域的特征向量分别判断一次,这样得出[2000, 2]的得分矩阵,如下图所示:
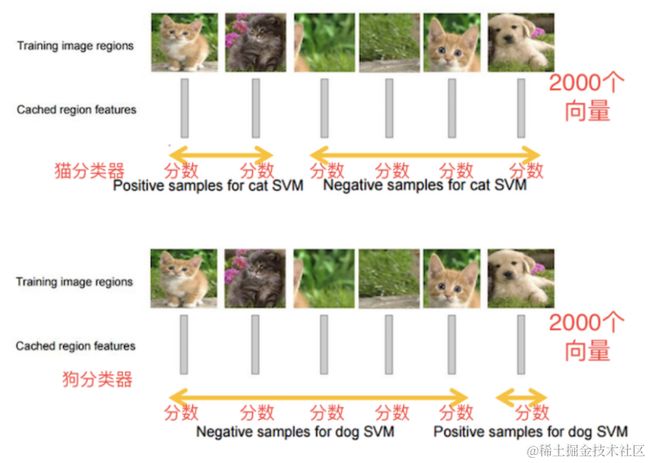
对于N个类别的检测任务,需要训练N(目标类别数目)个SVM分类器,对候选区域的特征向量(4096维)进行二分类,判断其是某一类别的目标,还是背景来完成目标分类。
为什么采用SVM,而不是使用softmax
SVM的性能主要受支持向量的影响,而已softmax为代表的逻辑回归考虑全局数据的同时分类超平面也会收到每一个样本的干扰。

因此svm和cnn训练过程中正负样本标准不同(svm的正样本的IOU比较高),在少样本训练中,我们在模型训练是,采用SVM可以将IOU设置的更大,提高模型精度。
1.1.4
通过选择性搜索获取的目标位置不是非常的准确,实验证明,训练一个线性回归模型在给定的候选区域的结果上去预测一个新的检测窗口,能够获得更精确的位置。修正过程如下图所示:

通过训练一个回归器来对候选区域的范围进行一个调整,这些候选区域最开始只是用选择性搜索的方法粗略得到的,通过调整之后得到更精确的位置,如下所示:

绿色为GT,红色为候选区域,蓝色为新的检测区域
1.1.5
使用选择性搜索的方法从一张图片中提取2000个候选区域,将每个区域送入CNN网络中进行特征提取,然后送入到SVM中进行分类,并使用候选框回归器,计算出每个候选区域的位置。 候选区域较多,有2000个,需要剔除掉部分检测结果。 针对每个类,通过计算IOU,采取非最大值抑制NMS的方法,保留比较好的检测结果
1.2RCNN总结
1、训练阶段多,训练耗时: 微调CNN网络+训练SVM+训练边框回归器。
2、预测速度慢: 使用GPU, VGG16模型处理一张图像需要47s。
3、占用磁盘空间大:5000张图像产生几百G的特征文件。
4、数据的形状变化:候选区域要经过缩放来固定大小,无法保证目标的不变形
2.Fast RCNN模型
考虑到R-CNN存在的问题,2015年提出了一个改善模型:Fast R-CNN。 相比于R-CNN, Fast R-CNN主要在以下三个方面进行了改进:
1、提高训练和预测的速度
R-CNN首先从测试图中提取2000个候选区域,然后将这2000个候选区域分别输入到预训练好的CNN中提取特征。由于候选区域有大量的重叠,这种提取特征的方法,就会重复的计算重叠区域的特征。在Fast-RCNN中,将整张图输入到CNN中提取特征,将候选区域映射到特征图上,这样就避免了对图像区域进行重复处理,提高效率减少时间。
2、不需要额外的空间保存CNN网络提取的特征向量
RCNN中需要将提取到的特征保存下来,用于为每个类训练单独的SVM分类器和边框回归器。在Fast-RCNN中,将类别判断和边框回归统一使用CNN实现,不需要在额外的空间存储特征。
3、不在直接对候选区域进行缩放
RCNN中需要对候选区域进行缩放送入CNN中进行特征提取,在Fast-RCNN中使用ROIpooling的方法进行尺寸的调整。
2.1 算法流程
Fast_RCNN的流程如下图所示:
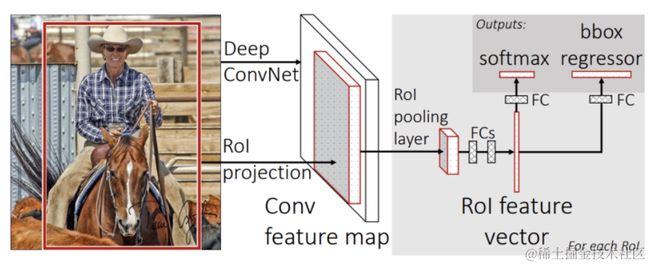
1、候选区域生成:使用选择性搜索(Selective Search)的方法找出图片中可能存在目标的侯选区域,只需要候选区域的位置信息
2、CNN网络特征提取:将整张图像输入到CNN网络中,得到整副图的特征图,并将上一步获取的候选区域位置从原图映射到该特征图上
3、ROIPooling: 对于每个特征图上候选框,RoI pooling层从特征图中提取固定长度的特征向量每个特征向量被送入一系列全连接(fc)层中。
4、目标检测:分两部分完成,一个输出各类别加上1个背景类别的Softmax概率估计,另一个为各类别的每一个类别输出四个实数值,来确定目标的位置信息。
其中候选区域和CNN网络特征提取与RCNN相同,下面不予介绍
2.1.1 ROI Pooling
候选区域从原图映射到特征图中后,进行ROIpooling的计算,如下图所示:
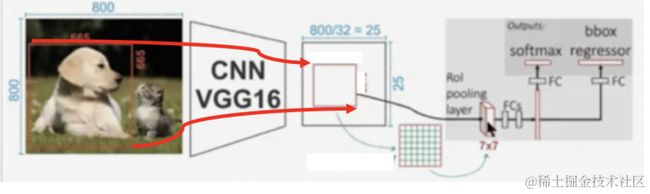
ROI Pooling层使用最大池化将输入的特征图中的任意区域(候选区域对应的区域)内的特征转化为固定的×的特征图,其中和是超参数。 对于任意输入的ℎ×的候选区域,将其分割为×的子网格,每个子网格的大小为:(h/H) x (w/W),取每个子网格中的最大值,送入后续网络中进行处理。

使用ROI Pooling层替换预训练网络中最后的池化层,并将并将超参,设置为和网络第一个全连接兼容的值,例如VGG16,设==7。
2.1.2 为什么Fast-RCNN又采用全连接形式,而不是SVM
1.RCNN中需要将提取到的特征保存下来,用于为每个类训练单独的SVM分类器和边框回归器。在Fast-RCNN中,将类别判断和边框回归统一使用CNN实现,不需要在额外的空间存储特征。
下面观点,属于个人理解,仅供参考
2.在CRNN中全连接层的输入数据的尺寸是固定的,因此在将候选区域送入CNN网络中时,需进行裁剪或变形为固定的尺寸,在进行特征提取。
而在Fast-RCNN中,我们候选区并没有裁剪或变形,只是等比例的缩放,保存了更多特征,以此我们对求IOU以及对图像的定位更加精准,这使得SVM与全连接的差距缩小,但因为svm针对支持向量敏感,我们数据准确提升带来的影响,并不能显著提升SVM,反而极大的促进了全连接Softmax的准确度。
故以上两个理由,Fast-RCNN采用全连接SoftMax替代了SVM。
2.2模型训练
R-CNN中的特征提取和检测部分是分开进行的,Fast R-CNN提出一个高效的训练方法:多任务训练
Fast R-CNN有两种输出:
- 一部分输出在K+1个类别上的离散概率分布(每个候选区域),通常,通过全连接层的K+1个输出上的Softmax来计算概率值。
- 另一部分输出对于由K个类别中的每一个检测框回归偏移。
将上面的两个任务的损失函数放在一起:

2.3模型总结
Fast R-CNN是对R-CNN模型的一种改进:
- CNN网络不再对每个候选区域进行特征提取,而是直接对整张图像进行出路,这样减少了很多重复计算。
- 用ROI pooling进行特征的尺寸变换,来满足FC全连接层对输入数据尺度的要求。
- 将目标的回归和分类统一在一个网络中,使用FC+softmax进行目标分类,使用FC Layer进行目标框的回归。
在Fast R-CNN中使用的目标检测识别网络,在速度和精度上都有了不错的结果。不足的是,其候选区域提取方法耗时较长,而且和目标检测网络是分离的,并不是端到端的,在2016年又提出了Faster-RCNN模型用于目标检测,在接下来的课程中我们着重介绍Faster-RCNN网络的原理与实现。
在线教程
- 麻省理工学院人工智能视频教程 – 麻省理工人工智能课程
- 人工智能入门 – 人工智能基础学习。Peter Norvig举办的课程
- EdX 人工智能 – 此课程讲授人工智能计算机系统设计的基本概念和技术。
- 人工智能中的计划 – 计划是人工智能系统的基础部分之一。在这个课程中,你将会学习到让机器人执行一系列动作所需要的基本算法。
- 机器人人工智能 – 这个课程将会教授你实现人工智能的基本方法,包括:概率推算,计划和搜索,本地化,跟踪和控制,全部都是围绕有关机器人设计。
- 机器学习 – 有指导和无指导情况下的基本机器学习算法
- 机器学习中的神经网络 – 智能神经网络上的算法和实践经验
- 斯坦福统计学习

人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用
这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。

