用通俗易懂的方式讲解:使用 MongoDB 和 Langchain 构建生成型AI聊天机器人
想象一下:你收到了你梦寐以求的礼物:一台非凡的时光机,可以将你带到任何地方、任何时候。
你只有10分钟让它运行,否则它将消失。你拥有一份2000页的PDF,详细介绍了关于这台时光机的一切:它的历史、创造者、构造细节、操作指南、过去的用户,甚至还有一种回到过去的方法。
现在的问题是:如何从这份详尽的文档中提取有价值的信息,在10分钟的时间内激活时光机?
这时,你的超级英雄登场:一款由生成式AI驱动的聊天机器人。你向它提供时光机手册,提出问题,然后见证检索增强生成(RAG Gen AI)的魔力。
文章目录
-
- 通俗易懂讲解大模型系列
- 技术交流&资料
- 由RAG驱动的生成型AI聊天机器人是什么?
- MongoDB Atlas Vector Search的强大之处
- Langchain在构建智能聊天机器人中的角色
-
- 上下文感知
- 推理能力
- 逐步指南:实施您自己的聊天机器人
- 结论
通俗易懂讲解大模型系列
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:一文讲清大模型 RAG 技术全流程
-
用通俗易懂的方式讲解:如何提升大模型 Agent 的能力?
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:使用 LangChain 和大模型生成海报文案
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:对 embedding 模型进行微调,我的大模型召回效果提升了太多了
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:使用 LlamaIndex 和 Eleasticsearch 进行大模型 RAG 检索增强生成
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
-
用通俗易懂的方式讲解:使用Llama-2、PgVector和LlamaIndex,构建大模型 RAG 全流程
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了大模型技术交流群,本文完整代码、相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流
由RAG驱动的生成型AI聊天机器人是什么?
由RAG(检索增强生成)技术驱动的生成式AI聊天机器人是我们要讨论的主题。生成式AI聊天机器人具有即时创建响应的不可思议能力。然而,直接使用像chatGPT这样的模型生成的答案也面临一些挑战:
- 幻觉:
- 大型语言模型可能会创造关于实际不存在的事件、角色或地点的文本。
- 它们可能提供不真实或具有误导性的信息。
- 无法访问私人信息:
- 直接生成的答案可能无法访问您的私人信息。
- 回答过于笼统:
- 响应可能过于笼统,不具体于零售、金融、制造等特定领域。
为了解决这些挑战,我们转向RAG,或称检索增强生成。RAG是一个AI框架,旨在从外部知识库中获取准确和最新的事实。在大型语言模型(LLMs)生成过程中,RAG在提供上下文和理解方面发挥着至关重要的作用。
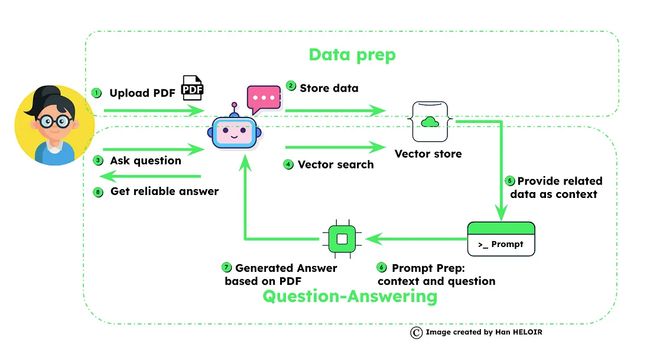
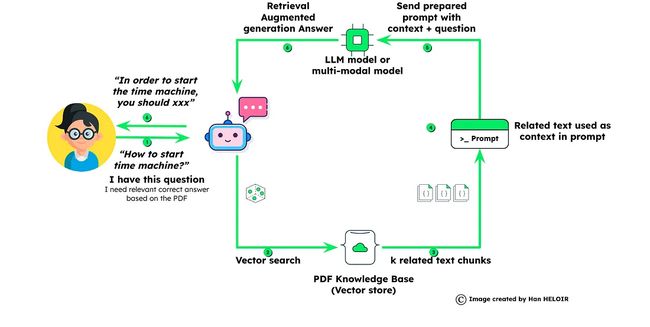
RAG-powered Chatbot的高级概述如下:
第一部分:数据准备
- 我们收集必要的数据,包括私人或领域特定信息,并将其存储在矢量存储中。
第二部分:RAG的运作
- 利用RAG,我们使用存储在矢量存储中的数据来获取精确和相关的答案。
这个两部分的过程不仅有助于减少LLM模型中的幻觉,还确保聊天机器人能够提供准确和上下文相关的响应。请在下一节加入我们,深入探讨RAG在我们的AI聊天机器人冒险中的作用!
MongoDB Atlas Vector Search的强大之处
-
其与现有MongoDB数据库的无缝集成使其成为对已经使用MongoDB进行数据管理的组织的自然延伸。这确保了在不需要进行大规模系统改造的情况下,可以顺利过渡到矢量存储。
-
MongoDB Atlas专为处理大规模、运营关键的应用而设计,展示了其强大性和可靠性。这在数据准确性和可用性至关重要的应用程序中变得特别关键,其横向扩展的能力确保了效率。
-
MongoDB Atlas在处理多样化的数据类型和结构方面的灵活性使其成为容纳矢量嵌入复杂性的理想选择。
-
作为企业级别,MongoDB Atlas拥有高标准的安全性,可以在多个云中使用,并且是完全托管的。这确保组织可以信赖它进行安全、可靠和高效的运营。
有了MongoDB Atlas,组织可以自信地存储和检索嵌入,释放其应用程序的AI的全部潜力。其企业级特性使其成为那些寻求不仅性能而且健壮安全性和管理能力的人的可靠选择。
Langchain在构建智能聊天机器人中的角色
LangChain是一个用于语言模型驱动应用程序的强大框架,在构建智能聊天机器人方面具有颠覆性的作用。以下是LangChain脱颖而出的一些关键点:
上下文感知
LangChain使应用程序,特别是聊天机器人,能够根据来自各种来源的上下文信息,如提示说明和历史交互,进行理解和响应。
推理能力
该框架赋予应用程序有效推理的能力,使它们能够根据提供的上下文做出明智的决策。
主要组件:
LangChain库:
具有各种组件的Python和JavaScript库,具有接口和集成。
将组件组合成链和代理的基本运行时,其中包括聊天机器人等现成的实现。
LangChain是您可能采用的一个关键选择,用于开发具有上下文感知、推理能力和对信息的高效访问的智能聊天机器人。随着我们深入探讨LangChain的机制,展示其在构建尤其是与MongoDB一起在企业环境中打造尖端对话AI应用程序方面的娴熟技能,请继续关注。
逐步指南:实施您自己的聊天机器人
通过本指南,您将获得以下收益:
- 对RAG聊天机器人创建工作流程的清晰理解。
- 熟练运用LangChain的主要功能,并利用MongoDB的本机集成。
- 访问一个用户友好的UI,支持PDF上传,并通过Gradio轻松提问。
此外,您的应用程序界面将包含两个选项卡:一个用于上传PDF文件,另一个用于提问。
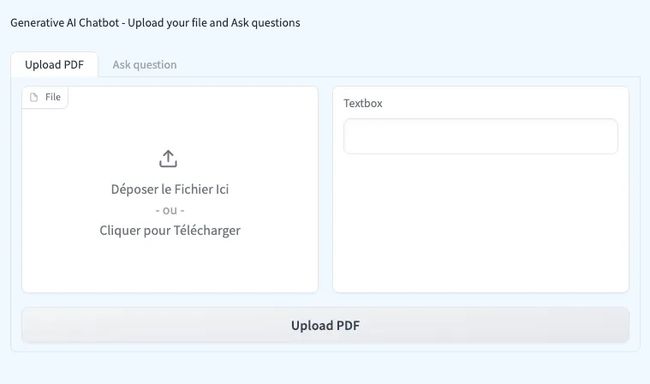
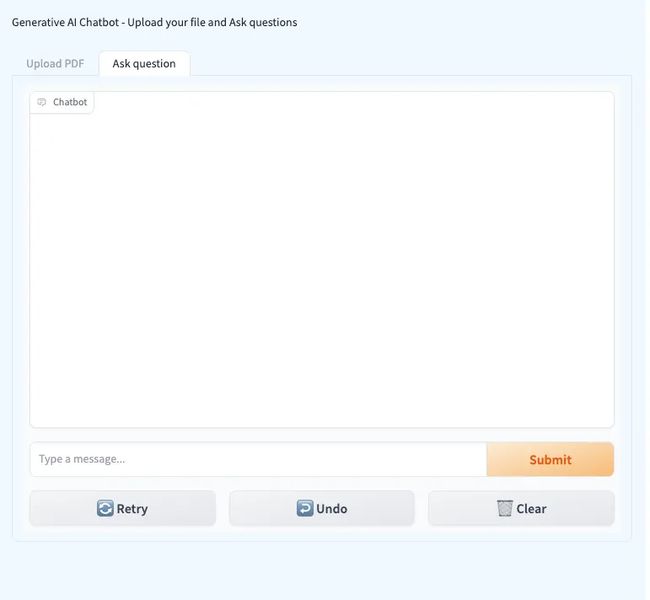
正如之前提到的,聊天机器人创建过程包含两个部分。初始步骤致力于建立知识库:
数据/PDF处理工作流程

加载数据
初始步骤涉及获取用于问答的必要数据。这可以通过从网页或PDF文档中提取信息来实现。
数据块
一旦获取数据,它会被分割成易处理的块。这确保了信息的高效处理。
生成嵌入
每个分段块都经历嵌入过程。这种转换将文本转换为适合分析的数值表示。
MongoDB 矢量存储
生成的嵌入找到了它们在MongoDB中的家园,在那里它们被存储以便在问答阶段快速检索。
检索增强生成问答工作流程
问题嵌入:
当用户提出问题时,会生成该特定问题的嵌入。这一步为将问题与存储在MongoDB Atlas中的数据进行比较做准备。
检索相似块:
利用MongoDB的矢量搜索功能,系统检索与第一部分中准备的最符合提出问题的相关数据块。
通过上下文创建和问题准备提示:
检索到的数据块和用户的问题被合并,以创建全面的上下文。该上下文作为为大型语言模型(LLM)制定查询的基础。
通过RAG进行定制答案生成:
装备了提供的上下文的LLM模型生成定制的答案,该答案特定于用户的问题和数据集。这确保了个性化和准确的响应。
现在让我们详细讲解代码:
导入库并设置环境
import os
import re
from openai import OpenAI
import time
from dotenv import load_dotenv
from pymongo import MongoClient
from langchain.chat_models import ChatOpenAI
from langchain.schema import AIMessage, HumanMessage
from langchain.llms import OpenAI
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import MongoDBAtlasVectorSearch
from langchain.chains import RetrievalQA
from langchain.schema.language_model import BaseLanguageModel
import gradio as gr
此部分包括导入必要的库和模块,用于各种功能,如与MongoDB交互,处理PDF,利用语言模型以及使用Gradio创建用户界面。
设置环境和MongoDB连接
# 从.env文件加载环境变量
load_dotenv(override=True)
# 设置MongoDB连接详细信息
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
MONGO_URI = os.environ["MONGO_URI"]
DB_NAME = "pdfchatbot"
COLLECTION_NAME = "pdfText"
ATLAS_VECTOR_SEARCH_INDEX_NAME = "vector_index"
# 使用API密钥初始化OpenAIEmbeddings
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
# 定义字段名称
EMBEDDING_FIELD_NAME = "embedding"
TEXT_FIELD_NAME = "text"
# 连接到MongoDB
client = MongoClient(MONGO_URI)
db = client[DB_NAME]
collection = db[COLLECTION_NAME]
在这里,加载环境变量,包括OpenAI和MongoDB连接详细信息的API密钥。代码使用API密钥初始化OpenAIEmbeddings并建立与MongoDB的连接。
PDF处理函数
def process_pdf(file,progress=gr.Progress()):
progress(0, desc="Starting")
time.sleep(1)
progress(0.05)
new_string = ""
for letter in progress.tqdm(file.name, desc="Uploading Your PDF into MongoDB Atlas"):
time.sleep(0.25)
loader = PyPDFLoader(file.name)
pages = loader.load_and_split()
# 打印加载的页面
print(pages)
# 将文本分割成文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
docs = text_splitter.split_documents(pages)
# 删除字母之间的单个空格并替换双空格
# docs_cleaned = [re.sub(r'\s+', ' ', doc.replace(' ', '')) for doc in docs]
# 将'Document'对象转换为字符串
docs_as_strings = [str(doc) for doc in docs]
# 使用嵌入设置MongoDBAtlasVectorSearch
vectorStore = MongoDBAtlasVectorSearch(
collection, embeddings, index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME
)
# 将文档插入MongoDB Atlas Vector Search
docsearch = vectorStore.from_documents(
docs,
embeddings,
collection=collection,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
)
return docsearch
定义一个名为process_pdf的函数,用于处理PDF文档,包括加载、分割和存储在MongoDB Atlas中。
查询和显示函数
定义一个名为query_and_display的函数,负责查询MongoDB Atlas Vector Search,检索相关文档,并在控制台中显示结果。
def query_and_display(query,history):
history_langchain_format = []
for human, ai in history:
history_langchain_format.append(HumanMessage(content=human))
history_langchain_format.append(AIMessage(content=ai))
history_langchain_format.append(HumanMessage(content=query))
# 使用嵌入设置MongoDBAtlasVectorSearch
vectorStore = MongoDBAtlasVectorSearch(
collection,
OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY),
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
)
print(query)
# 查询MongoDB Atlas Vector Search
print("---------------")
docs = vectorStore.max_marginal_relevance_search(query, K=5)
llm = OpenAI(openai_api_key=OPENAI_API_KEY, temperature=0)
retriever = vectorStore.as_retriever(
search_type="similarity",
search_kwargs={"k": 5},
)
for document in retriever:
print(str(document) + "\n")
qa = RetrievalQA.from_chain_type(
llm, chain_type="stuff", retriever=retriever
)
retriever_output = qa.run(query)
print(retriever_output)
return retriever_output
Gradio用户界面
with gr.Blocks(css=".gradio-container {background-color: AliceBlue}") as demo:
gr.Markdown("Generative AI Chatbot - Upload your file and Ask questions")
with gr.Tab("Upload PDF"):
with gr.Row():
pdf_input = gr.File()
pdf_output = gr.Textbox()
pdf_button = gr.Button("Upload PDF")
with gr.Tab("Ask question"):
gr.ChatInterface(query_and_display)
pdf_button.click(process_pdf, inputs=pdf_input, outputs=pdf_output)
demo.launch()
设置Gradio用户界面,包括两个选项卡(“上传PDF”和“提问”),并配有相应的输入和输出组件。
结论
总之,我们从新手到由MongoDB和Langchain驱动的聊天机器人英雄的旅程简直是一场奇迹。
通过RAG,我们克服了与大型语言模型相关的挑战,确保了精确和具有上下文相关性的响应。MongoDB Atlas Vector Search是我们可靠的盟友,提供具备企业级准备性的解决方案,具有无缝集成和可扩展性。
这不仅是一个结论;这是一个开始。在您深入研究聊天机器人的过程中,愿您的旅程像那次非凡的时光机骑行一样充满魔力!