Django中的一些小配置
文章目录
- 官网
- 一、安装后的setting配置
-
- 静态资源配置
-
- templates配置
- static(注意最后的逗号,数据类型是元组)
- 二、有关于ORM
-
- 表的迁移
- ORM模型类的创建
-
- 添加 mysqlclient
- 基本
- 创建model时的一切类...
- 关于__str__
-
- 设定一下数据库表名,和复数
- 对象(数据库字段)
- 参数(字段类型以及外键)
- 1.常用操作
- 2.进阶(Q, F查询)
- 一对多/多对多数据操作
-
- 一对多
-
- model
- 多对多
-
- model:
- 增加
- 查询
- 修改
- 删除
- Django数据库事务操作
-
- 回滚、保证数据原子性
-
- 方法一
- 方法二:
- 三、celery+redis实现django定时任务
-
- 部分启动命令
- 文件配置
-
- 依赖包版本
- 文件目录
- setting配置
- celery配置文件(setting同级目录)
- project >init.py(主目录下的init文件)
- 在创建的app里面添加tasks.py文件
- 三、 Django中将本地图片文件路径映射网络路径
-
-
-
- 我们平成使用静态图片路径的时候是不是在render返回的网页中使用本地的图片(绝对路径或相对路径)
- 那么,怎么可以用浏览器直接通过url访问图片呢
-
- setting配置
- url配置(project的主url)
-
- 导入模块
- 下面这个才是重要的,通过url访问就是这个
- views视图函数:
-
- 先解析一下:
-
- 四、 登陆状态验证
-
- 前端存储
- 五、Django REST FRAMEWORK
-
- 环境
- 认证模块(token)
-
- models
- views(视图)
- urls
- auth文件
- 全局引用
- rest_restframework禁用身份验证和授权
-
- setting.py里面添加配置
- 六 跨域问题
-
- 常见跨域错误提示(前端出现)
- cors库解决get、post请求跨域问题
-
- 导包
- setting设置
-
- 注册app
- 添加中间件
- 处理跨域
- 跨域允许的操作
- 跨域允许的请求头
- 七、django后端接口调用远程摄像头
-
- 下载依赖包
- 引用
- 接口实现
-
- 单一摄像头
- 多摄像头
- 八、Django在中间件添加
-
- 1.日志中间件和ip访问频率中间件
- 2、setting设置
- 2、用户权限验证
- 九、django中使用Redis缓存
-
- 一、安装redis
- 二、系统配置
-
- 我用的是redis,就用下面的配置就行(我这里主要是记录ip访问记录,记录条数可能多,但是数据量不大)
- 使用本地内存
- 使用本地文件
- 缓存使用
官网
https://docs.djangoproject.com/zh-hansdjango官方文档
用到django和vue
提示:以下是本篇文章正文内容,下面案例可供参考
一、安装后的setting配置
静态资源配置
templates配置
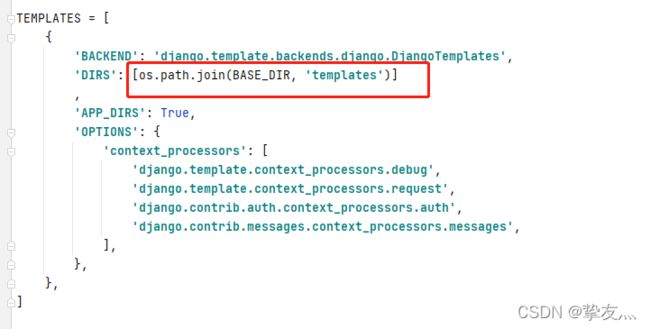
static(注意最后的逗号,数据类型是元组)
STATICFILES_DIRS = ( os.path.join(BASE_DIR, "static"), )
欧克,这样基本配置就好了
二、有关于ORM
表的迁移
生成表结构
python manage.py makemigrations app01
迁移
python manage.py migrate app01
ORM模型类的创建
添加 mysqlclient
import pymysql
pymysql.install_as_MySQLdb()
基本

创建model时的一切类…
关于__str__
就是返回对象,易于查找
def __str__(self):
# 返回所属类和内存地址
return str(self.id)
设定一下数据库表名,和复数
class Meta:
# 定义表名(要不在迁移表之后会有django或者应用前缀)
db_table = "userinfo"
# 定义在管理后台显示的名称
verbose_name = '用户信息表'
# 定义复数时的名称(去除复数的s)
verbose_name_plural = verbose_name
对象(数据库字段)
- 自增长:
- AutoField(一般用做id,无需用户自己添加)
- 不够用就用BigAutoField
- int类型:
- IntegerField
- BigIntegerField
- 二进制字段:
- :BinaryField
- 布尔类型:
- :BooleanField
- NullBooleanField 允许为空
- 整形:
- 五个字节正数 : PositiveSmallIntegerField
- 六个字节的正负数 : SmallIntegerField
- 十个字节的正数 : PositiveIntegerField
- 十个字节 :IntegerField
- 二十个字节 : BigIntegerField
- 字符串类型:
- 需要指定字符串最大长度 : CharField
- 不需要指定(多长都行):TextField
- 时间类型:
- 年月日 :DateField
- 年月日时分秒 : DateTimeField
- 一段时间 : DurationField
- 浮点数:
- 不用指定小数点后几位 : FloatField
- 需要指定 :DecimalField
- 邮箱:
- EmailField
- 图片
- ImageField
- 一对多外键
- 参数要写上附表的类名 : ForeignKey
- 必须要加on_delelte参数
- 多对多
- 参数要写上附表的类名: ManyToManyField
等等…
参数(字段类型以及外键)
- 所有字段都有的
- 1.更改字段名:db_colum=” “
- 2.设置主键:primary_key=True,默认为False
- 3.给字段设置别名(备注):verbose_name=” “
- 4.字段的唯一键属性:unique=True,设置之后,这个字段的没一条记录的每个值是唯一的
- 5.允许字段为空:null=True(数据库中字段可以为空),blank=True(网页 - 表单提交内容可以为空),切记不可以将null设置为Fasle的同时还把blank设 - 置为True。会报错的。
- 6.给字段建立索引:db_index=True
- 7.在表单中显示说明:help_text=” “
- 8.字段值不允许更改:editable=False,默认是True,可以更改。
- 9 .auto_now # 创建时,自动生成时间
-
- auto_now_add # 更新时,自动更新为当前时间
- 时间和字符串类型
- CharField 类型
- 设置字符串的长度 : max_length
- DateField 类型
- unique_for_date=True:这个字段的时间必须唯一
- auto_now=True:对这条记录内容更新的时间
- auto_now_add=True:插入这条记录的时间
- max_digits=6, decimal_places=2:前者表示整数和小数总共多少数,后者表示小数点的位数
- CharField 类型
- 对照:
- choice:它是一种以列表 / 元组的型式,里面嵌套着少数几个小元组的方式,表示一种对应关系
choice参数详解 - 关系型字段
- 设置外键管理字段(该字段添加在附表,pimary指定的是主表字段)to_field=‘sect_id’
ORM基本配置与方法
数据操作(增/删/改/查)
1.常用操作
-
all():查询所有的结果
示例:
publisher = models.Publisher.objects.all() #查询所有的出版社信息 -
get():
publisher = models.Publisher.objects.get(id = 1) # get查询数据不存在时会保错 -
filter():
publisher = models.Publisher.objects.filter(id = 1) #不存在的时候返回一个空的Queryset 不会报错
publisher = models.Publisher.objects.filter(id = 1)[0] #就算查询的结果只有一个 返回的也是一个Queryset 列表 要用索引的方式取出第一个元素 -
exclude():
publisher = models.Publisher.objects.exclude(id = 1) #排除掉id等于1的数据 -
alues():
publisher = models.Publisher.objects.values(“name”,“type”) #返回一个Queryset对象 里面全是字典 为空的话 默认查出所有数据 -
values_list():
publisher = models.Publisher.objects.values_list(“name”) # 返回一个Queryset对象 里面全是列表为空的话 默认查出所有数据 -
order_by():
publisher = models.Publisher.objects.all().order_by(“time”) #根据xxx排序 -
reverse(): #反转
publisher = models.Publisher.objects.all().order_by(“time”) .reverse() #只能对有序的Queryset 进行反转
count(): 返回Queryset中对象的数量
publisher = models.Publisher.objects.all().count() -
frist(): 返回Queryset中第一个对象
publisher = models.Publisher.objects.all().frist() -
last():返回Queryset中最后一个对象
publisher = models.Publisher.objects.all().last()
- exists(): 查询表中是否有数据 有就返回True 没有就是False
publisher = models.Publisher.objects.exists()
2.进阶(Q, F查询)
from django.db.models import Q
print(Book.objects.filter(Q(id=3))[0]) # 因为获取的结果是一个QuerySet,所以使用下标的方式获取结果
print(Book.objects.filter(Q(id=3)|Q(title="Go"))[0]) # 查询id=3或者标题是“Go”的书
print(Book.objects.filter(Q(price__gte=70)&Q(title__startswith="J"))) # 查询价格大于等于70并且标题是“J”开头的书
print(Book.objects.filter(Q(title__startswith="J") & ~Q(id=3))) # 查询标题是“J”开头并且id不是3的书
print(Book.objects.filter(Q(price=70)|Q(title="Python"), publication_date="2017-09-26")) # Q对象可以与关键字参数查询一起使用,必须把普通关键字查询放到Q对象查询的后面
# 查询user表中weight大于height的数据
models.User.objects.filter(F(weight__gt=F("height")))
# 将user表中所有的age增加5
models.User.objects.update(age=F("age")+5)
# 将所有数据name字段末尾加个“好帅”
# 在操作字符类型的数据的时候 , F不能够直接做到字符串的拼接 需要借助Concat模块和Value模块
from django.db.models.functions import Concat
from django.db.models import Value
models.User.objects.update(name=Concat(F("name"), Value("好帅")))
一对多/多对多数据操作
一对多
在一对多的关系中,ForeignKey字段应该放在"多"的一方的表中。在这个例子中,一个班级可以有多个学生,每个学生只属于一个班级,因此应该在学生表中添加ForeignKey字段来表示与班级表的关联关系。
model
from django.db import models
class Author(models.Model):
name = models.CharField(max_length=50)
class Article(models.Model):
title = models.CharField(max_length=100)
content = models.TextField()
author = models.ForeignKey(Author, on_delete=models.CASCADE)
ps: Publish:表一;Book表二
方式1:
publish_obj=Publish.objects.get(nid=1)
book_obj=Book.objects.create(title="钢铁是怎样炼成的",publishDate="2012-12-12",price=100,publish=publish_obj)
方式2:
book_obj=Book.objects.create(title="钢铁是怎样炼成的",publishDate="2012-12-12",price=100,publish_id=1)
多对多
model:
class Author(models.Model):
name = models.CharField(max_length=32)
books = models.ManyToManyField(Book)
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5 , decimal_places=2)
详情url
增加
# 增加数据
方法1、
步骤1 ,先得到一个Book对象
book_obj = Book.objects.get(id=1)#获取一个书籍的对象,有可能是多个作者写的,是一个集合对象
步骤2 :获取1个或2个以上author对象
author1 = Author.objects.get(id=1)
author2 = Author.objects.get(id=2)
步骤3: 把author1,和author2 添加到 book_obj 对象中,使用add方法,书对象关联的作者表,添加2个作者对象
#book表与author表绑定关系,把2个作者对象添加到,关联到Book对象
book_obj.authors.add(author1,author2)
方法2:多对多关系的创建,获取所有的对象集合,添加 ,记得用 * 号,把列表拆开,一个个的获取对象
#先获取一个book对象,
book_obj = Book.objects.get(id=1)
#方法2 ,把所有的author加到book对象中
author_list = Author.objects.all()
book_obj.authors.add(*author_list)
查询
#看下authors对象
book_obj = Book.objects.get(id=1)#获取一个书籍的对象,有可能是多个作者写的,是一个集合对象,
#获取id=1 这本书的作者集合对象,类似列表结构
print(book_obj.authors) #gu_orm.Author.None ,是id=1的这本书,没有作者,所以得到一个None
#如果给Book和author绑定了关系,添加值,就会得到一个Queryset集合,
print(book_obj.authors.all())
修改
#修改数据
book_obj.authors.set([1,2,3])
删除
解除关联关系
clear() : 清除所有的关系
remove() : 删除指定的关系
#解除关联关系
book_obj.authors.clear()#解除了书与作者的所有关系,
#指定删除Book与作者的关系,先获取要解除关联的对象,然后用remove的方法,
author = Author.objects.get(name = 'alex')
book_obj.authors.remove(author)
Django数据库事务操作
回滚、保证数据原子性
方法一
from django.db import transaction
# 创建保存点
save_id = transaction.savepoint()
# 回滚到保存点
transaction.savepoint_rollback(save_id)
# 提交从保存点到当前状态的所有数据库事务操作
transaction.savepoint_commit(save_id)
# 重置用于生成唯一保存点ID的计数器
clean_savepoints(using = None)
# 这些函数中的每一个都接受一个using参数,该参数是数据库的名称。如果using未提供参数,则# 使用"default"默认数据库。
详情
方法二:
在ORM中,可以使用 transaction.atomic() 方法来处理事务。atomic()方法将一组数据库操作包装在一个事务中,并确保这些操作要么全部成功,要么全部失败回滚。如果事务失败,则所有对数据库的操作将会被回滚到初始状态。
实例:
from django.db import transaction
from myapp.models import MyModel
try:
with transaction.atomic():
# 这里是需要进行事务处理的代码
obj1 = MyModel.objects.create(name="John")
obj2 = MyModel.objects.create(name="Tom")
obj3 = MyModel.objects.create(name="Alice")
# 如果这里发生异常,则事务将回滚到初始状态,上面创建的对象将会被删除
raise ValueError("Oops! Something went wrong...")
except ValueError as e:
# 在这里处理异常,或者抛出异常由上层代码处理
print(e)
三、celery+redis实现django定时任务
redis启动
注意:在Windows下,如果不指定 -P gevent,celery收到任务但不执行,也就是说不会有任务执行结果。gevent并行库有一个替代的方案是eventlet,也可以 -P eventlet。如果使用eventlet,需要pip install eventlet
部分启动命令
redis-server.exe redis.windows.conf
低版本celery启动worker
celery -A Orm_Mysql worker -l info # Orm_Mysql 是项目名称
高版本
celery -A RepliceProject worker -l info -P eventlet
celery启动beat(发送任务)
celery -A Orm_Mysql beat -l info
文件配置
依赖包版本
有两个选择
这一个直接运行worker和beat,没事
python 3.6
celery==5.0.5
django==3.1.4
django-celery-beat==2.2.0
redis==4.1.0
billiard==3.6.4.0 # 重要
这里因为安装的celery版本有点高,不支持Windows,所以使用eventlet启动,发送任务时一样的
celery==5.2.3
Django==3.2.10
django-celery-beat==2.2.1
eventlet==0.33.0
文件目录

setting配置
# 配置celery
CELERY_BROKER_URL = 'redis://localhost:6379/0' # Broker配置,使用Redis作为消息中间件
CELERY_RESULT_BACKEND = 'redis://localhost:6379/0' # BACKEND配置,这里使用redis
CELERY_RESULT_SERIALIZER = 'json' # 结果序列化方案
celery配置文件(setting同级目录)
# 将下一个版本中更新的内容导入到当前版本中
from __future__ import absolute_import, unicode_literals
import os
from celery import Celery
from celery.schedules import crontab
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'SW.settings') # 设置django环境 Orm_Mysql是project名称
app = Celery('SW') # 还有这里
app.config_from_object('django.conf:settings', namespace='CELERY') # 使用CELERY_ 作为前缀,在settings中写配置
app.autodiscover_tasks() # 发现任务文件每个app下的task.py
# 声明定时任务
app.conf.beat_schedule = {
u'shuiwu_v1_tasks_count_water_yield_task': { # 水量计算
"task": "shuiwu_v1.tasks.count_water_yield_task",
"schedule": crontab(minute=0, hour=0), # 凌晨12点
},
u'shuiwu_v1_tasks_count_water_cost_task': { # 水费计算
"task": "shuiwu_v1.tasks.count_water_cost_task",
"schedule": crontab(minute=20, hour=0), # 凌晨12点20分
},
u'shuiwu_v1_tasks_update_garbage_fees_task': { # 更新用户垃圾处理费
"task": "shuiwu_v1.tasks.update_garbage_fees_task",
# "schedule": crontab(minute=20, hour=0, day_of_week=6), # 每周日凌晨12点20分
"schedule": crontab(), # 每分钟
},
}
project >init.py(主目录下的init文件)
ps: 写不写都行
# 将下一个版本中更新的内容导入到当前版本中
from __future__ import absolute_import, unicode_literals
from .config_celery import app as celery_app
__all__ = ['celery_app']
# 底下两行是配置pymysql的
import pymysql
pymysql.install_as_MySQLdb()
在创建的app里面添加tasks.py文件
from __future__ import absolute_import, unicode_literals
import os
import django
from celery import shared_task
from loguru import logger
import time
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'SW.settings')
django.setup()
from shuiwu_v1.methods.method_timed_task import count_water_yield, count_water_cost, update_garbage_fees_start
logger.add(sink='shuiwu_v1/logs/tasks_water_cost.log', encoding='utf-8', rotation='1 days')
# TODO : 计算水量
@shared_task
def count_water_yield_task():
start_time = time.time()
logger.info("开始计算水量!")
count_water_yield()
logger.info("计算水量结束!")
end_time = time.time()
execution_time = end_time - start_time
logger.info("水量计算执行时间:{} 秒".format(execution_time))
# TODO : 计算水费
@shared_task
def count_water_cost_task():
start_time = time.time()
logger.info("开始计算水费!")
count_water_cost()
logger.info("计算水费结束!")
end_time = time.time()
execution_time = end_time - start_time
logger.info("水费计算执行时间:{} 秒".format(execution_time))
# TODO : 更新用户垃圾处理费-开始函数
@shared_task
def update_garbage_fees_task():
start_time = time.time()
logger.info("开始更新用户垃圾处理费!")
update_garbage_fees_start()
logger.info("更新用户垃圾处理费结束!")
end_time = time.time()
execution_time = end_time - start_time
logger.info("更新用户垃圾处理费执行时间:{} 秒".format(execution_time))
"""
celery -A SW worker -l info -P eventlet
celery -A SW worker -l error -P eventlet
celery -A SW inspect active
celery -A SW beat -l info
"""
三、 Django中将本地图片文件路径映射网络路径
我们平成使用静态图片路径的时候是不是在render返回的网页中使用本地的图片(绝对路径或相对路径)
那么,怎么可以用浏览器直接通过url访问图片呢
setting配置
# 设置文件上传路径,图片上传、文件上传都会存放在此目录里
MEDIA_URL = '/media/'
MEDIA_ROOT = os.path.join(BASE_DIR, 'media') # 如果边加括号就是元组数据了
# 跨域配置
CORS_ALLOW_CREDENTIALS = True
CORS_ORIGIN_ALLOW_ALL = True
CORS_ORIGIN_WHITELIST = (
"*"
)
url配置(project的主url)
导入模块
# 导入配置文件中的static
from django.conf.urls.static import static
# 导入项目的setting文件
from Orm_Mysql import settings
下面这个才是重要的,通过url访问就是这个
urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)
- ps:这里面的两个值
- 这个是设置映射的文件
- STATIC_URL = ‘/media/’
- os.path.join是获取本地绝对路径
- STATICFILES_DIRS = (os.path.join(BASE_DIR, “templates”), )

views视图函数:
先解析一下:
- request.FILES.get(“file”, None)
- 获取图片的方法(二进制)
- ‘%d.jpg’ % round(time.time() * 1000)
- 将当前时间戳*1000并四舍五入
- os.path.join(settings.MEDIA_ROOT, file_name)
- 这个是拼接路径,前面的 MEDIA_ROOT 是setting中的一个变量,后米娜的file_name是图片名称
- 就是指定图片保存地址
- request.get_host()
- 获取本机地址
def imagesUp(request):
ret = {"errorcode": 1000, "msg": "OK"}
excel_file = request.FILES.get("file", None)
userId = request.POST.get('userId')
if excel_file:
file_name = '%d.jpg' % round(time.time() * 1000)
filepath = os.path.join(settings.MEDIA_ROOT, file_name)
with open(filepath, 'ab') as f:
for chunk in excel_file.chunks():
f.write(chunk)
else:
ret['errorcode'] = 1002
ret['msg']='图片上传失败'
return HttpResponse(json.dumps(ret,ensure_ascii=False))
imgPath = 'http://'+request.get_host()+'/'+settings.MEDIA_ROOT.split('\\')
[-1]+'/'+file_name
# linux
# filePath = 'http://' + request.get_host() + settings.EXCEL_FILE_URL.split('\\')[-1] + '/' + file_name
obj = UserInfo.objects.filter(id=userId)
if len(obj)==0:
ret['errorcode'] =1003
ret['msg'] = '用户不存在'
return HttpResponse(json.dumps(ret,ensure_ascii=False))
obj.update(
headPortrait=imgPath
)
print(imgPath)
return HttpResponse(json.dumps(ret,ensure_ascii=False))
四、 登陆状态验证
能力有限,暂时先这样做,
思路:
- 前端提交账户密码,后端返回token(根据账户密码加密,还有当前时间)
- 前端暂存这个token,每次向后端发起请求时加上这个token
- 后端得到token后解密,对比时间是否超时,然后对比数据库账号密码
前端存储
localStorage是长期存储
- clear 清理
- removeitem 删除
- localStorage.token = “赋值”

五、Django REST FRAMEWORK
环境
- 依赖包
pip install djangorestframework
- setting设置
- app里面新增
'rest_framework',
- app里面新增
认证模块(token)
这个是已经创建了用户,通过用户信息生成token的,创建用户最好再写一个新的views里
models
from django.db import models
# Create your models here.
class UserInfo(models.Model):
"""用户表"""
user_type_choices = (
(1, "普通用户"),
(2, "VIP"),
(3, "SVIP")
)
user_type = models.IntegerField(choices=user_type_choices)
username = models.CharField(max_length=32, unique=True)
password = models.CharField(max_length=64)
class UserToken(models.Model):
"""token表"""
user = models.OneToOneField(to="UserInfo", on_delete=models.CASCADE) # 这是网上的模型,(个人推荐使用逻辑外键)
token = models.CharField(max_length=64)
token_time = models.BigIntegerField(verbose_name="时间戳", null=True)
views(视图)
- 插播一个知识点
- FBV (function base view):基于函数的视图
- CBV(class base view):基于类的视图
# 设置登录类
from django.http import JsonResponse
from rest_framework.views import APIView
from app01.models import UserInfo, UserToken
from djangoProject.auth import md5s
class AuthView(APIView):
@classmethod
# 重写api_view中的post请求,让它(用户登录)不验证token
def post(self, request, *args, **kwargs):
# 设置状态码
res = {"state_code": 200, "msg": None}
# 判断异常
try:
# print(request)
web_data = eval(request.body)
print(web_data)
# 原生_request改写request方法 获取前端表单里面的用户名
username = web_data.get("username")
# 获取前端表单里面的密码
password = web_data.get("password")
# 根据前端传入数据,查询数据库
obj = UserInfo.objects.filter(username=username, password=password).first()
# 然后进行判断,如果数据库查询为空,则返回1001
if not obj:
# 就发送状态码 1001
res["state_code"] = 1001
# 用户名或者 密码错误
res["msg"] = "用户名或者密码错误"
return JsonResponse(res)
# 不为空 为登陆用户创建一个token
token = md5s(username)
# 存到数据库 存在就更新,不存在就创建
UserToken.objects.update_or_create(user=obj, defaults={"token": token, "token_time": int(time.time())})
# 发送状态码
res["token"] = token
# 告知请求成功
res["msg"] = "请求成功"
# 判断异常
except Exception as e:
print(e)
# 发送状态码
res["state_code"] = 1002
# 请求异常
res["msg"] = "请求异常"
# 返回JsonResponse
return JsonResponse(res)
@api_view(["POST"]) # 添加用户认证
def test_2(request):
res = {"state_code": 200, "msg": None}
return JsonResponse(res)
urls
主程序url
urlpatterns = [
# path('admin/', admin.site.urls),
path('app01/', include('app01.urls'))
]
app模块
urlpatterns = [
path('admin/', admin.site.urls),
path("login", views.AuthView.post),
path("test_2", views.test_2),
]
auth文件
上面的是对比数据库token,后面是生成token(这里使用md5加密,后面用pyjwt)
import datetime
import time
from rest_framework.authentication import BaseAuthentication
from app01.models import UserToken, UserInfo
from rest_framework import exceptions
# 创建一个我的认证类 继承BaseAuthentication方法
class MyAuthtication(BaseAuthentication):
# 设置内置authenticate重写authenticate这个方法
def authenticate(self, request):
# 将用户输入的token用变量接收
token = eval(request.body).get("token")
username = eval(request.body).get("username")
password = eval(request.body).get("password")
obj = UserInfo.objects.filter(username=username, password=password).first()
# 然后进行判断,如果数据库查询为空,则返回1001
if not obj:
raise exceptions.AuthenticationFailed("用户认证失败")
# 然后在数据库进行匹配
token_obj = UserToken.objects.filter(token=token).first()
# 如果认证失败
if not token_obj:
# 就返回失败
raise exceptions.AuthenticationFailed("用户认证失败")
date_new = int(time.time())
datae_sql = int(token_obj.token_time)
t = date_new - datae_sql
# 若表内登陆时间超过10min则自动清除
if t > 60:
token_obj.delete()
raise exceptions.APIException('登陆超时,请重新登陆!')
# 正确就返回用户和token 每次刷新token都不同
# 认证成功,刷新token 时间 在 rest framework内部 会将这两个字段赋值给request,以供后续操作使用
if token_obj:
UserToken.objects.filter(token=token).update(token_time=date_new)
return token_obj, token
# 如果pass 就调用原有的方法
class MyAuthtication_None(BaseAuthentication):
def authenticate(self, request):
pass
# 创建md5函数 继承token模型的user对象
def md5s(user):
# 导入哈希加密
import hashlib
# 导入时间
import time
# 变量名ctime 接收现在的时间转为字符str类型
ctime = str(time.time())
# 将user对象转为字节并用哈希md5加密 变为16进制字符
m = hashlib.md5(bytes(user, encoding="utf-8"))
# 修改并加入时间戳
m.update(bytes(ctime, encoding="utf-8"))
# 并返回
return m.hexdigest()
全局引用
全局使用auth里的对比token方法
APIView
“DEFAULT_AUTHENTICATION_CLASSES"就是各个组件的配置名”
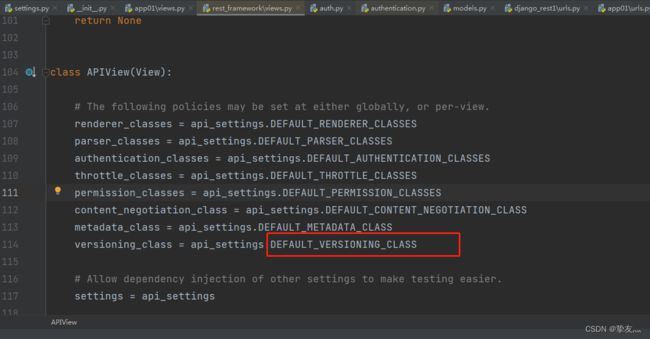
将"DEFAULT_AUTHENTICATION_CLASSES":[设置类的路径]
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': [
# "app01.auth.MyAuthtication", # 全都验证
"app01.auth.MyAuthtication_None", # 直接过
]
}
然后就可以在view视图中加入
authentication_classes = []
偷看的大佬的https://www.jianshu.com/p/9a200956f29b
rest_restframework禁用身份验证和授权
setting.py里面添加配置
ps(默认开启)
# 禁止rest_framework身份验证
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': [],
'DEFAULT_PERMISSION_CLASSES': [],
'UNAUTHENTICATED_USER': None,
'DEFAULT_PARSER_CLASSES': (
'rest_framework.parsers.JSONParser', # 解析json数据包
'rest_framework.parsers.FormParser', # 解析urlencoded数据包
'rest_framework.parsers.MultiPartParser' # 解析from-data数据包
),
}
六 跨域问题
常见跨域错误提示(前端出现)
from origin ‘null’ has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource.
cors库解决get、post请求跨域问题
导包
pip install django-cors-headers
setting设置
注册app
INSTALLED_APPS = [
...
'corsheaders',
...
]
添加中间件
MIDDLEWARE = [
...
'corsheaders.middleware.CorsMiddleware', # 添加跨域中间件,需注意顺序
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
...
]
处理跨域
CORS_ALLOW_CREDENTIALS = True # 指明在跨域访问中,后端是否支持对cookie的操作。
#跨域增加忽略
CORS_ORIGIN_ALLOW_ALL = True # 允许所有跨域请求
# 添加白名单
# CORS_ORIGIN_WHITELIST = (
# # 'http://*.*.*:*', # 允许所有http跨域
# # 'https://*.*.*:*', # 允许所有https跨域
# 'http://127.0.0.1:8000',
# )
跨域允许的操作
CORS_ALLOW_METHODS = (
‘DELETE’,
‘GET’,
‘OPTIONS’,
‘PATCH’,
‘POST’,
‘PUT’,
‘VIEW’,
)
跨域允许的请求头
CORS_ALLOW_HEADERS = (
‘XMLHttpRequest’,
‘X_FILENAME’,
‘accept-encoding’,
‘authorization’,
‘content-type’,
‘dnt’,
‘origin’,
‘user-agent’,
‘x-csrftoken’,
‘x-requested-with’,
‘Pragma’,
)
这样操作后跨域问题就解决了
大佬链接https://blog.51cto.com/liangdongchang/4998277
七、django后端接口调用远程摄像头
ps: django后端接口调用远程摄像头,将获取到的数据流持续返还前端
下载依赖包
pip install opencv-python numpy
引用
import cv2
from django.http import StreamingHttpResponse
接口实现
单一摄像头
def video_feed(request):
# 定义远程视频地址1679983995036.mp4
# url = "http://<远程IP地址>:<端口号>/<视频流路径>"
url = "http://admin:[email protected]:8081/"
# 定义视频读取器
cap = cv2.VideoCapture(url)
def stream():
while True:
ret, frame = cap.read()
if not ret:
break
# 取值范围:0~100,数值越小,压缩比越高,图片质量损失越严重
ratio = 40
params = [cv2.IMWRITE_JPEG_QUALITY, ratio]
ret, buffer = cv2.imencode('.jpg', frame, params)
# ret, buffer = cv2.imencode('.jpg', frame)
frame = buffer.tobytes()
yield (b'--frame\r\n'
b'Content-Type: image/jpeg\r\n\r\n' + frame + b'\r\n')
# StreamingHttpResponse: 文件内容流式传输
return StreamingHttpResponse(stream(), content_type='multipart/x-mixed-replace; boundary=frame')
多摄像头
ps: 传输摄像头数据用的是流式传输,前端调用用的是img src= “http:ip+port?参数”,get方式。
def video_feed(request):
# 定义远程视频地址1679983995036.mp4
# url = "http://<远程IP地址>:<端口号>/<视频流路径>"
web_data = request.__dict__.get("_request")
site_url = str(web_data).split("=")[-1].replace("'>", "")
# 定义视频读取器
cap = cv2.VideoCapture(url)
def stream():
while True:
ret, frame = cap.read()
if not ret:
break
ret, buffer = cv2.imencode('.jpg', frame)
frame = buffer.tobytes()
yield (b'--frame\r\n'
b'Content-Type: image/jpeg\r\n\r\n' + frame + b'\r\n')
# StreamingHttpResponse: 文件内容流式传输
return StreamingHttpResponse(stream(), content_type='multipart/x-mixed-replace; boundary=frame')
八、Django在中间件添加
1.日志中间件和ip访问频率中间件
middlewares.py文件(自定义文件,名称以及文件位置随便,但要在项目中)
import json
import os
import time
import traceback
from pathlib import Path
from django.utils.deprecation import MiddlewareMixin
from django.http import HttpResponseForbidden
from django.core.cache import cache
from loguru import logger
from datetime import date
dir_path = Path(__file__).resolve().parent.parent
logs_path = os.path.join(dir_path, "logs/")
# 查找日志目录是否存在,不存在则创建
if not os.path.exists(logs_path):
os.makedirs(logs_path)
logger.add(sink=logs_path + "{0}_project.log".format(date.today()), encoding='utf-8', rotation='30 days')
# TODO : 获取IP请求频率
class RequestLimitMiddleware:
def __init__(self, get_response):
self.get_response = get_response
def __call__(self, request):
ip_address = self.get_client_ip(request)
if not ip_address:
ip_address = request.META.get('HTTP_X_REAL_IP', '')
if not ip_address:
ip_address = request.META.get('REMOTE_ADDR', '')
if ip_address:
cache_key = f'request_limit_{ip_address}'
count = cache.get(cache_key, 0)
if count >= 50:
return HttpResponseForbidden('Sorry, you have exceeded the maximum number of requests '
'within a short period of time. Please try again later.')
cache.set(cache_key, count + 1, 60)
response = self.get_response(request)
return response
def get_client_ip(self, request):
x_forwarded_for = request.META.get('HTTP_X_FORWARDED_FOR')
if x_forwarded_for:
ip = x_forwarded_for.split(',')[0]
else:
ip = request.META.get('REMOTE_ADDR')
return ip
# TODO : 日志中间件
class OpLogs(MiddlewareMixin):
__exclude_urls = ['index/'] # 定义不需要记录日志的url名单
def __init__(self, *args):
super().__init__(*args)
self.start_time = None # 开始时间
self.end_time = None # 响应时间
self.data = {} # dict数据
def process_request(self, request):
"""
绑定request
"""
self.start_time = time.time() # 开始时间
# 请求IP
x_forwarded_for = request.META.get('HTTP_X_FORWARDED_FOR')
if x_forwarded_for:
# 如果有代理,获取真实IP
re_ip = x_forwarded_for.split(",")[0]
else:
re_ip = request.META.get('REMOTE_ADDR')
# 请求方法
re_method = request.method
path = request.path
try:
header = request.body.decode()
# name = request.user.name
except AttributeError:
header = None
self.data.update(
{'method': re_method, # 请求方法
'path': path, # 请求url
'ip': re_ip, # 请求IP
'header': header # 请求头(登录用户名称等信息)
}
)
logger.info(self.data)
def process_response(self, request, response):
"""
绑定response, 返回结果
"""
# 请求url在 exclude_urls中,直接return,不打印日志
for url in self.__exclude_urls:
if url in self.data.get('path'):
return response
# 获取响应数据字符串(多用于API, 返回JSON字符串)
rp_content = response.content.decode()
self.data['rp_content'] = rp_content
self.data['status_code'] = response.status_code # 响应码
# 耗时
self.end_time = time.time() # 响应时间
access_time = self.end_time - self.start_time
self.data['access_time'] = round(access_time * 1000) # 耗时毫秒/ms
logger.info(str(self.data) + "]\n")
return response
def process_exception(self, request, exception):
"""当请求在发生不可预知的报错的情况下,自动调用"""
url = request.get_full_path()
logger.error("接口:{},出现错误:{}".format(url, traceback.format_exc().__str__()))
return HttpResponseForbidden(json.dumps(dict(code=500, msg="Some thing error")),
content_type="application/json")
2、setting设置
MIDDLEWARE里添加方法类路径
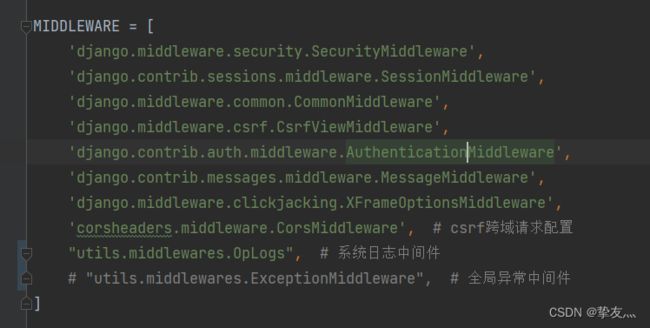
2、用户权限验证
下面是在process_request方法中的一段代码,如果规定前端传输的数据格式,并且将传入的用户信息查询该用户对应权限,就能实现每个用户对每个后端接口是否有访问权限进行判断,无权限直接返回,不进行后续操作

c_test:这是我自定义的一个函数方法,主要负责用户数据的查询任务。
九、django中使用Redis缓存
一、安装redis
第一步肯定是安装redis了,也可以用内存/主数据库(mysql…)或者是文件存储
二、系统配置
还是setting里面
我用的是redis,就用下面的配置就行(我这里主要是记录ip访问记录,记录条数可能多,但是数据量不大)
CACHES = {
'default': {
'BACKEND': 'django_redis.cache.RedisCache', # 引擎
'LOCATION': LOCATION + "0", # 缓存表
'TIMEOUT': 3600*2, # 缓存保存时间 单位秒,默认值300,
'OPTIONS': {
'MAX_ENTRIES': 2000, # 最大缓存数据
'CULL_FREQUENCY': 2, # 缓存条数达到最大值时,删除1/x的缓存数据 max_entries*(1/cull_frequency)
# "PASSWORD": "123", # redis密码
}
}
}
使用本地内存
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.locmem.locMemCache',
'LOCATION': 'unique-snowflake'
}
}
使用本地文件
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache',
'LOCATION': '/var/tmp/django_cache', # 这个是文件夹的路径
# 'LOCATION': 'c:\test\cache', # windows下示例
}
}
缓存使用
from django.core.cache import cache # 引入缓存模块
# cache方法总结
1、存储缓存
使用cache.set(key, value, timeout)来进行缓存
key为缓存的key,value为python对象,timeout为缓存的存储时间(单位s秒),默认为CACHES中的TIMEOUT值,返回值为None
2、获取缓存
使用cache.get(key)来进行缓存的获取
key为缓存时保存使用的key,返回值为key的具体值,如果没有数据则返回None
3、存储缓存-在key不存在时生效
使用cache.add(key, value)进行缓存的存储,只在key不存在时才生效
如果存储成功,返回值为True,如果失败返回值为False
4、若未获取到数据则执行set
使用cache.get_or_set(key, value, timeout)方法来获取数据,如果没有找到数据,则执行set操作来缓存数据
返回值为value
5、批量存储缓存
使用cache.set_many(dict, timeout)方法来批量缓存
dict为key和value的字典,timeout为存储时间(s),返回值为插入不成功的key的数组