顺序表查找——顺序查找、有序表查找(多种方法)及次优查找树
查找
- 8.2 顺序表
-
- 8.2.1 顺序表的查找
-
- 基本思想
- 顺序存储结构下的顺序查找算法
- 平均查找长度
- 8.2.2 有序表的折半查找
-
- 折半查找的算法思想
- 折半查找算法
-
- (1)有序表上迭代、递归形式
- (2)二叉搜索树(Binary Search Tree)形式
- (3)查找次数
- 扩充二叉树
- 判定树
- 折半查找的其他方法
-
- 斐波那契查找
- 插值查找
- 静态最优查找树
- 结论
8.2 顺序表
采用顺序存储结构的数据表称为顺序表。顺序表适合作静态查找。
8.2.1 顺序表的查找
基本思想
设有n个数据元素的顺序表,从表的一端(前端或后端)开始,用给定的值依次和表中各数据元素的关键字进行比较,若在表中找到某个数据元素的关键字和给定值相等,则查找成功,给出该数据元素在表中的位置;若查遍整个表,不存在关键字等于给定值的数据元素,则查找失败,给出失败信息。
顺序存储结构下的顺序查找算法
template<class ElemType> int SqSearch(ElemType elem[],int n,ElemType key)
//一般顺序查找比较
{
int i;
for(i=0; i<n && elem[i]!=key ;i++);
if(i<n)
return i;
else
return -1;
}
template<class ElemType> int SqSearch(ElemType elem[],int n)
//使用哨兵elem[0],n的传入的是带上哨兵的长度
{
int i;
for(i=n;elem[i]!=elem[0];i--);
if(i==0)
return -1;
else
return i;
}
- 哨兵优化是对顺序查找的优化,因为每次循环时都需要对i是否越界(i是否小于等于n)作判断。设置一个哨兵,可以解决越界问题。对于查找数字比较大的情况,哨兵的优点更加明显。
- 如果数据元素的数据类型是一个结构体的话,需要在结构体中重载不等于(!=)关系运算。
平均查找长度
- 在等概率(P=1/n)情形下,算法1(不用哨兵)
查找成功的平均查找长度为:ASL=(n-1)/2;
查找失败的平均查找长度为:n+1。 - 在许多情形下数据表中各个数据元素的查找概率是不相等的。这时,可以将数据元素按查找概率的高低,把查找概率高的存放在开始查找的一端,把查找概率低的存放在另一端,从而提高顺序查找的效率。顺序查找的方法比较简单,但查找成功的平均查找长度较长,特别当n较大时查找效率较低。
当然,数据表也可以用链表存储如果顺序表中各个数据元素按关键字从小到大或从大到小有序排列,即为有序表,对有序表进行顺序查找,其查找失败的平均查找长度可减少,因为不需要查遍整个表就能确定表中不存在要找的数据元素。
8.2.2 有序表的折半查找
对有序表通常可用折半查找的方法进行查找。设有n个数据元素按其关键字从小到大的顺序存放在一个顺序表中(开始时,查找区间的下限low-0,上限high=n-1)。
折半查找的算法思想
1)如果查找区间长度小于1(low>high)则表示查找失败,返回-1;否则继续以下步骤。
2)求出查找区间中间位置的数据元素下标mid(mid=(low+high)/2)。
3)用区间中间位置的数据元素的关键字elem[mid]与给定值key进行比较,比较的结果有以下三种可能。
- ①若elem[mid]=key,则查找成功,报告成功信息并返回其下标mid。
- ②若elem[mid]
- ③若elem[mid]>key,则说明如果数据表中存在要找的数据元素,该数据元素一定在mid的左侧。可把查找区间缩小到数据表的前半部分**(high=mid-1)**,再维续进行折半查找(转步骤1)。
在折半查找过程中,每比较一次,如果数据元素的关键字和给定值不相等,则查找区间缩小一半。直到查找区间已缩小到只有一个数据元素,如果仍未找到想要找的数据元素,则表示查找失败。
例如,设有序表为{ 8,11,23 34,39,46,68,71,86},下图展示查找关键字为23的数据元素时的查找过程。
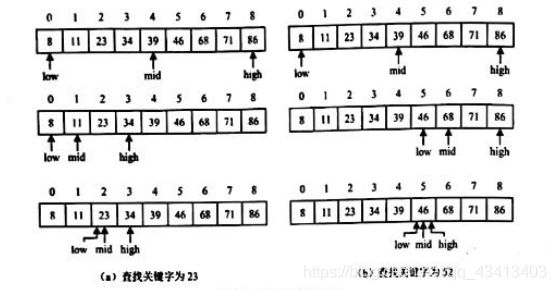
折半查找算法
(1)有序表上迭代、递归形式
//递归算法
template<class ElemType> int BinSearch(ElemType elem[],int low,int high,ElemType key)
{
int mid;
if(low>high)
mid=-1;//查找失败
else
{
mid=(low+high)/2;
if(key<elem[mid])//左半边继续查找
mid=BinSearch(elem,low,mid-1,key);
else if(key>elem[mid])//右半边继续查找
mid=BinSearch(elem,mid+1,high,key);
//两个条件都不满足或者已经调用过,mid就是最后的结果
}
return mid;
}
//非递归算法
template<class ElemType> int BinSearch(ElemType elem[],int n,ElemType key)
{
int low=0,high=n-1;//设置查找到的左右边界
int mid;
while(low<=high)
{
mid=(low+high)/2;
if(key==elem[mid])
return mid;
else if(key<elem[mid])
high=mid-1;
else
low=mid+1;
}
return -1;
}
(2)二叉搜索树(Binary Search Tree)形式
- 构造思路:
在二叉查找树上,每个结点表示有序表中的一个数据元素。设二叉查找树有n个结点,
(1)当n=0时,二叉查找树为空树;
(2)当n≠0时,二叉查找树的根结点是有序表中序号为mid=(n-1)/2的数据元素,根结点的左子树是与有序表 elem[0] ~ elem[mid-1]相对应的二叉查找树,根结点的右子树是与有序表 elem[mid+1] ~ elem[n-1]相对应的二叉查找树。 - 实现
转载自:https://blog.csdn.net/yu876876/article/details/84191178
//二叉搜索树的创建
//递归算法,确定一个根节点,比根节点小的值放左边,比根节点大的值放右边。
#include(3)查找次数
进行插入的关键字与给定值的比较次数正好等于该结点所在的层次号。因此,折半查找成功时所进行的关键字与给定值的比较次数最多为这棵二叉找树的高度。
扩充二叉树
- 对二叉查找树进行扩充,让树中所有结点的空指针都指向一个外部结点(用方框表示,相应原来的数据元素结点称为内结点它们代表了那些进行关键字比较不成功的结点。在此称这样的二叉查找树为扩充二叉树。
- 在扩充二叉树上查找不成功的过程恰好是走了一条从根结点到某个外部结点的路径,而与给定值进行比较的次数则等于该路径上内部结点的个数。例如,在图8-2(b)所示的例子中查找52时,所需的关键字比较次数为3。一般地,对于有n个数据元索的有序表,折半查找所进行的给定值与关键字的比较次数最多为og2(n+1)(上取整,8
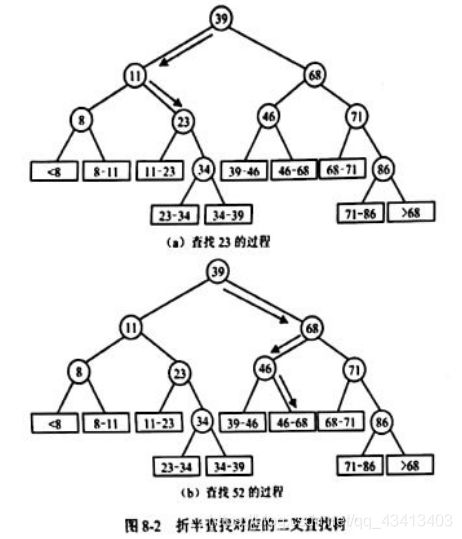
- 折半查找的平均查找长度是多少?
若设n=2h-1。则描述折半查找的扩充二叉树是高度为h的满二叉树,h=log 2 (n+1)上取整。
第一层结点有一个,查找第一层结点要比较一次;
第二层结点有两个,查找第二层结点要比较两次。
第i(1<=i<=h)层结点有2i-1个,查找第i层结点要比较 i 次。……
假定每个元素的查找概率相等,即Pi=1/n。则查找成功的平均查找长度为:
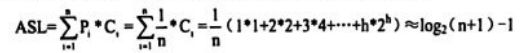
判定树
描述查找过程的二叉树叫判定树。
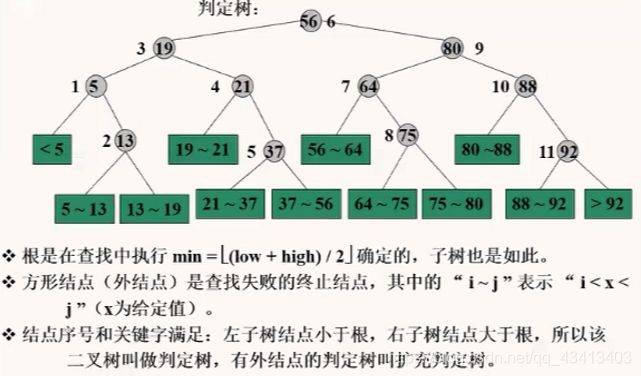
查找不成功是有扩充的判定树,可以得到查找不成功结点的范围。
折半查找法在查找过程中进行的比较次数最多不超过其判定树的深度。
折半查找的其他方法
以有序表表示静态查找表时,除可用折半查找之外,还有斐波那契查找和插值查找。
斐波那契查找
- 当n很大时,这种查找方法叫作黄金分割法,其平均性能比折半查找方法好。但最坏情况时,性能比折半查找方法差。查找成功的平均查找长度也是O(log 2 n)。
- 斐波那契在找也是集于有序表的逐步缩小查找区间的查找方法。该方法的查找区间端点和中向点都与斐波那契数列有关。斐波那契数列的定义为:1,1,2,3,5,8,13,……。即f(1)=1,f(2)=1,f(i)=f(i-1)+f(i-2)(当i>2时)。
- 若有一个具有n个数据元素的有序表,n=f(k)-1,即比某个斐波那契数少1。斐波那契在找的算法思想如下(开始时,查找区间的下限low=0,上限 high=n-1)。
1)如果查找区间长度小于1(low>high),则表示查找失败,返回-1;否则继续以下步骤。
2)根据斐波那契数列求出查找区间中某位置的数据元素下标 mid=f(k-1)-1。
3)区间中间位置的数据元素的关键字 elem[mid]与给定值key进行比较,比较的结果有以下三种可能:
①若elem[mid]== key,则查找成功,报告成功信息并返回其下标mid。
②若 elem[mid] < key,则说明如果数据表中存在要找的数据元素,该数据元素一定在mid的右侧,可把查找区向缩小到数据表的后半部分,得到的子表的长度正好为f(k-2)-1,再继续进行斐波那契查找(转步骤1))。
③若elem[mid] > key,则说明如果数据表中存在要找的数据元素,该数据元素一定在mid的左侧。可把查找区间缩小到数据表的前半部分,得到的子表的长度正好为f(k-1)-1,再继续进行斐波那契查找(转步骤1))。
插值查找
- 插值查找的算法思想同折半查找类似,区别在于求中间位置的公式,其求中间点的公式为:

其中,k为给定值,elem[low]和elem[high]分别为查找区问中具有最小关键字和最大关键字的数据元素,它们分别在查找区间的两端。 - 插值查找的查找方法类似于折半查找,它的查找性能在关键字分布比较均匀的情况下优于折半查找。
静态最优查找树
查找算法 | 静态树表(次优查找树)详细分析
#include 补充:演示之后存在的问题是:由于在构造次优查找树的过程中,没有考察单个关键字的相应权值,则有可能出现被选为根的关键字的权值比它相邻的关键字的权值小。此时应作适当调整:选取邻近的权值较大的关键字作次优查找树的根节点。——可以采用左旋子树或右旋子树(类似于平衡二叉树的旋转)。参考:次优查找树的建立
结论
| 长度n | 顺序查找 | 二分查找 |
|---|---|---|
| 查找方式 | 监视哨(0),从后往前匹配 | 记录查找区间的上下限,mid=(low+high)/2与key比较 |
| 查找成功(等概率p=1/n) | 查找第i个元素,比较(n-i+1)次;ASLss=(n+1)/2 | 第i层结点有2i-1个,查找第i层结点要比较i次;ASLss=log 2 (n+1) -1~O(log 2 n) |
| 查找不成功(等概率p=1/(2n)) | 3/4*(n+1) | ASL=log 2 (n+1) -1 ~ O(log 2 n) |
| 优点 | 算法简单、适应面广,对表的结构或关键字是否有序无任何要求。 | 当n很大时,能够显现时间效率。 |
| 缺点 | 查找效率低,特别是当n较大时,查找效率较低,不宜采用。 | 由于折半查找的表仍是线性表,若经常要进行插入、删除操作,则元素排列费时太多,因此折半查找比较适合于一经建立就很少改动而又需要经常查找的线性表。较少查找而又经常需要改动的线性表可以采用链接存储,使用顺序查找。 |