ELK分离式日志(2)
目录
一.Filebeat+ELK 部署
开台服务器(192.168.233.50)下载fliebeat:
安装nginx后查看下日志文件:
设置 filebeat 的主配置文件:
关闭logstash,检测文件:
在50节点上启动filebeat:
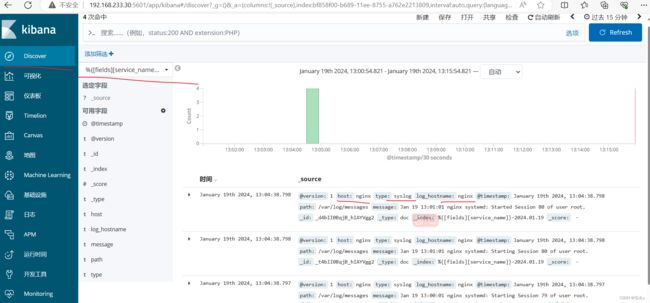
访问页面:
二.zookeeper+kafka群集
1.什么是zookeeper
Zookeeper 工作机制:
Zookeeper 特点:
Zookeeper 应用场景:
Zookeeper 选举机制:
选举Leader规则:
二.安装 部署Zookeeper:
将解压后的目录移动改名,修改配置文件:
拷贝配置好的 Zookeeper 配置文件到其他机器上:
在每个节点上创建数据目录和日志目录:
修改环境变量:
在每个节点的dataDir指定的目录下创建一个 myid 的文件:
编辑编辑在每台配置 Zookeeper 启动脚本:
加权限:
设置开机自启:
查看当前状态:
2.什么是kafka
为什么需要消息队列(MQ):
消息队列的两种模式:
kafak定义:
Kafka 系统架构:
部署 kafka 集群
修改配置文件:
配置 Zookeeper 启动脚本:
Kafka 命令行操作:
Filebeat+Kafka+ELK:
在 Logstash 组件所在节点上新建一个 Logstash 配置文件:
检测下kafka文件:
看下kafka的详细信息:
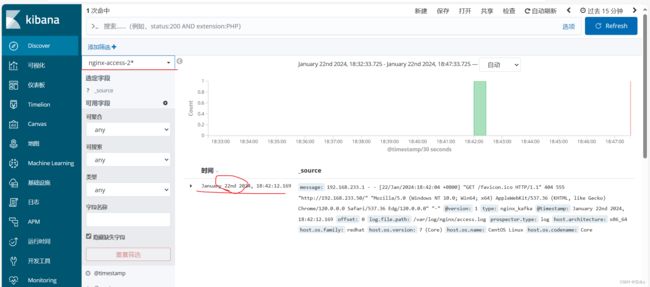
访问kibana:
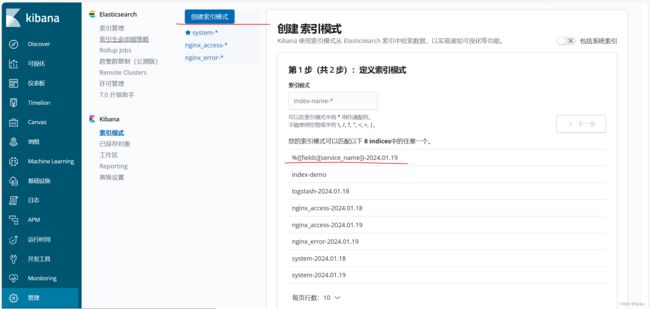
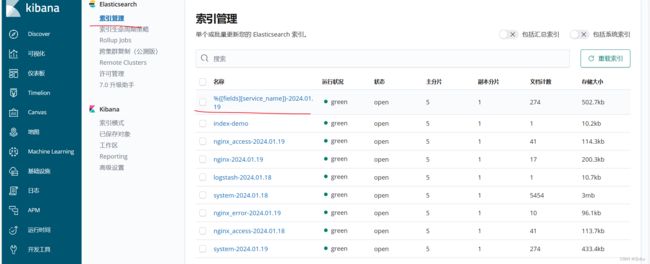
创建成功索引:
创建失败索引:
一.Filebeat+ELK 部署
filebeat的端口号:5044
开台服务器(192.168.233.50)下载fliebeat:
上传软件包 filebeat-6.7.2-linux-x86_64.tar.gz 到/opt目录:
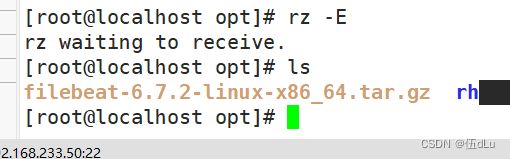
解压:

移动目录到/usr/local:

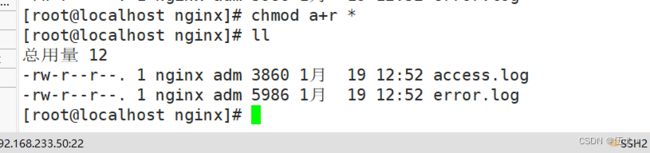
安装nginx后查看下日志文件:

添加权限:
设置 filebeat 的主配置文件:
![]()





在 Logstash(192.168.233.40) 组件所在节点上新建一个 Logstash 配置文件:



关闭logstash,检测文件:

在50节点上启动filebeat:

查看下40节点:
访问页面:




二.zookeeper+kafka群集
1.什么是zookeeper
Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目。
Zookeeper 工作机制:
是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。也就是说 Zookeeper = 文件系统 + 通知机制。
Zookeeper 特点:
(1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
(2)Zookeeper集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
(3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
(4)更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行,即先进先出。
(5)数据更新原子性,一次数据更新要么成功,要么失败。
(6)实时性,在一定时间范围内,Client能读到最新数据。
Zookeeper 应用场景:
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
Zookeeper 选举机制:
第一次leader选举:比较服务器节点的myid,谁的myid最大就获取其它节点的选票,当选票超过服务器节点数量的半数则当选leader,其它节点为follower,即使以后再有其它myid更大的节点加入集群也不会影响之前的选举结果。
非第一次选举:如果是非leader节点故障,替换新的节点继续作follower,与现存的leader节点建立连接并同步数据
如果是leader节点故障,则需要重新选举新的leader,先比较每个存活节点的epoch(参与选举的次数),如由epoch最大的节点则直接当选leader
若epoch有相同的节点,再比较zxid(写操作的事务id),如由zxid最大的节点则直接当选leader
若zxid也有相同的节点,继续比较sid(等同于myid),由sid最大的节点当选leader
选举Leader规则:
SID:服务器ID。用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致。
ZXID:事务ID。ZXID是一个事务ID,用来标识一次服务器状态的变更。
1.EPOCH大的直接胜出
2.EPOCH相同,事务id大的胜出
3.事务id相同(ZXID),服务器id(SID)大的胜出
二.安装 部署Zookeeper:

![]()
将解压后的目录移动改名,修改配置文件:



拷贝配置好的 Zookeeper 配置文件到其他机器上:

查看其他节点:


在每个节点上创建数据目录和日志目录:




修改环境变量:



在每个节点的dataDir指定的目录下创建一个 myid 的文件:
![]()

 在每台配置 Zookeeper 启动脚本:
在每台配置 Zookeeper 启动脚本:

#!/bin/bash
#chkconfig: 2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper'
case $1 in
start)
echo "---------- zookeeper 启动 ------------"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "---------- zookeeper 停止 ------------"
$ZK_HOME/bin/zkServer.sh stop
;;
restart)
echo "---------- zookeeper 重启 ------------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "---------- zookeeper 状态 ------------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
加权限:

设置开机自启:

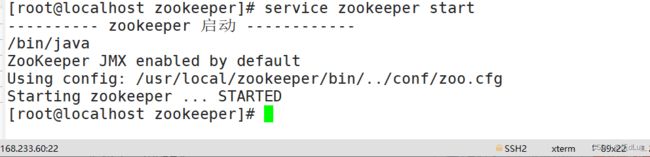

查看当前状态:

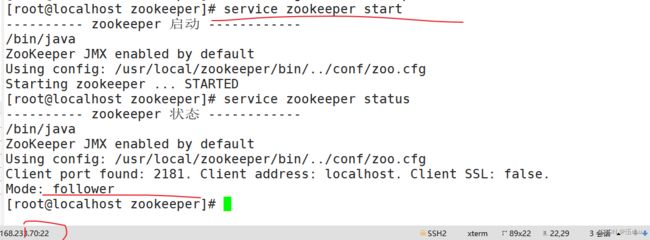

看出来80端口为leader。
2.什么是kafka
为什么需要消息队列(MQ):
主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection 错误,引发雪崩效应。
我们使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。
当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka、Pulsar 等。
消息队列的两种模式:
1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到消息队列中,然后消息消费者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息消费者不可能消费到已经被消费的消息。消息队列支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
2)发布/订阅模式(一对多,又叫观察者模式,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。
发布/订阅模式是定义对象间一种一对多的依赖关系,使得每当一个对象(目标对象)的状态发生改变,则所有依赖于它的对象(观察者对象)都会得到通知并自动更新。
kafak定义:
Kafka 是一个分布式的基于发布/订阅模式的消息队列(MQ,Message Queue),主要应用于大数据领域的实时计算以及日志收集。
Kafka 系统架构:
Broker:一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。类似于数据库的表名或者 ES 的 index,物理上不同 topic 的消息分开存储。
Partition
为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分割为一个或多个 partition,每个 partition 是一个有序的队列。Kafka 只保证 partition 内的记录是有序的,而不保证 topic 中不同 partition 的顺序。
Replica
副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
eader
每个 partition 有多个副本,其中有且仅有一个作为 Leader,Leader 是当前负责数据的读写的 partition。
Follower
Follower 跟随 Leader,所有写请求都通过 Leader 路由,数据变更会广播给所有 Follower,Follower 与 Leader 保持数据同步。Follower 只负责备份,不负责数据的读写。
Producer
生产者即数据的发布者,该角色将消息 push 发布到 Kafka 的 topic 中。
broker 接收到生产者发送的消息后,broker 将该消息追加到当前用于追加数据的 segment 文件中。生产者发送的消息,存储到一个 partition 中,生产者也可以指定数据存储的 partition。
Consumer
消费者可以从 broker 中 pull 拉取数据。消费者可以消费多个 topic 中的数据。
Consumer Group(CG)
消费者组,由多个 consumer 组成。
所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。可为每个消费者指定组名,若不指定组名则属于默认的组。
offset 偏移量
可以唯一的标识一条消息。
偏移量决定读取数据的位置,不会有线程安全的问题,消费者通过偏移量来决定下次读取的消息(即消费位置)。
消息被消费之后,并不被马上删除,这样多个业务就可以重复使用 Kafka 的消息。
Zookeeper
存储管理kafka集群的元数据,生产和消费者动作需要zookeeper 的管理支持,生产者推送数据给kafka需要先通过zookeeper寻找kafka集群节点位,可从zookeeper获取offset上记录上一次消费的位置继续往后消费。
部署 kafka 集群
节点都安装 Kafka:

移动并改名到/usr/local下改名为kafka:

修改配置文件:
先备份:


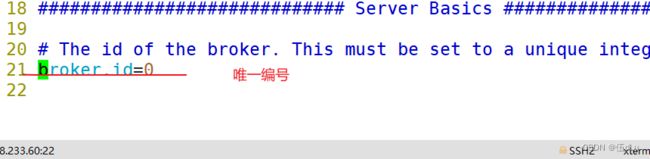
其他节点:

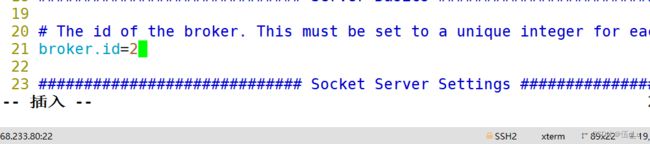

其他节点:




其他节点也是一样配置。
修改环境变量:



配置 Zookeeper 启动脚本:

#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)
echo "---------- Kafka 启动 ------------"
${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)
echo "---------- Kafka 停止 ------------"
${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)
$0 stop
$0 start
;;
status)
echo "---------- Kafka 状态 ------------"
count=$(ps -ef | grep kafka | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
echo "kafka is not running"
else
echo "kafka is running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac

添加权限:

设置开机自启:


Kafka 命令行操作:
在一台服务器上创建topic:
--zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称
kafka-topics.sh --create --zookeeper 192.168.233.60:2181,192.168.233.70:2181,192.168.233.80:2181 --replication-factor 2 --partitions 3 --topic test

查看当前服务器中的所有 topic:
kafka-topics.sh --list --zookeeper 192.168.233.60:2181,192.168.233.70:2181,192.168.233.80:2181

其他节点看看:


查看某个 topic 的详情信息:
kafka-topics.sh --list --zookeeper 192.168.233.60:2181,192.168.233.70:2181,192.168.233.80:2181

发布消息:
kafka-console-producer.sh --broker-list 192.168.233.60:9092,192.168.233.70:9092,192.168.233.80:9092 --topic test

到另一台服务器上看消费消息:
kafka-console-consumer.sh --bootstrap-server 192.168.233.60:9092,192.168.233.70:9092,192.168.233.80:9092 --topic test --from-beginning

Filebeat+Kafka+ELK:
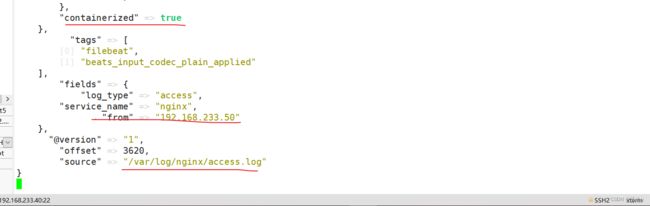
在之前的filebeat节点(192.168.233.50)上修改配置文件:



添加输出到 Kafka 的配置:

在 Logstash 组件所在节点上新建一个 Logstash 配置文件:

input {
kafka { bootstrap_servers => "192.168.233.60:9092,192.168.233.70:9092,192.168.233.80:9092"
topics => "nginx_logs"
type => "nginx_kafka"
codec => "json"
auto_offset_reset => "latest"
decorate_events => true
}}
output {
if "nginx_access" in [tags] {
elasticsearch {
hosts => ["192.168.233.10:9200","192.168.233.20:9200,"192.168.233.30:9200"] index => "nginx-access-%{+YYYY.MM.dd}"
}
}
if "nginx_error" in [tags] {
elasticsearch {
hosts => ["192.168.233.10:9200","192.168.233.20:9200,"192.168.233.30:9200"]
index => "nginx-error-%{+YYYY.MM.dd}"
}
}
}
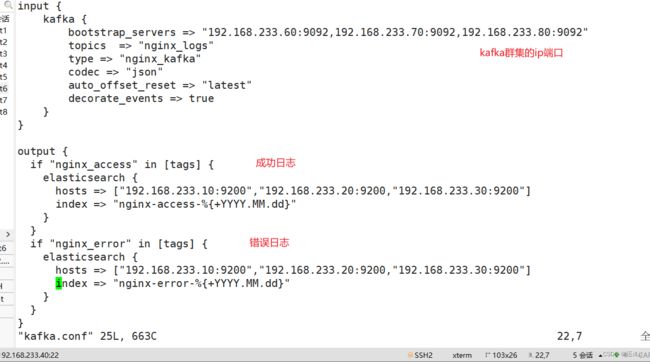

检测下kafka文件:

启动文件:
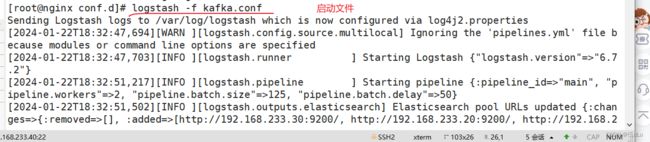

看下kafka的详细信息:

访问kibana:


访问es节点的网页:

创建成功索引:


创建失败索引:

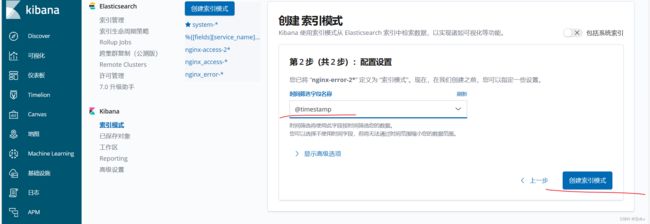
查看索引信息: